







5 月 23 日,我收到 Nvidia 的一封电子邮件,邀请我参加 NVIDIA 和 LangChain 举办的生成式 AI 代理开发者大赛。
我的第一个想法是时间太短了,而且考虑到我们最近刚生了个孩子,我父母应该会来,我没有时间参加。但后来我又改变了主意,决定编写一些代码并提交。
我花了几天时间思考可以做什么,一个想法一直萦绕在我的脑海里 — — 一个可以让你与本地文件交互的开源生成式搜索引擎。Microsoft Copilot 已经提供了类似的东西,但我认为我可以制作一个开源版本,为了好玩,并分享我在快速编码系统过程中收集的一些经验。
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、系统设计
为了构建本地生成式搜索引擎或助手,我们需要几个组件:
- 一个包含本地文件内容的索引,以及一个信息检索引擎,用于检索给定查询/问题的最相关文档。
- 一种语言模型,使用从本地文档中选择的内容并生成总结性答案
- 用户界面
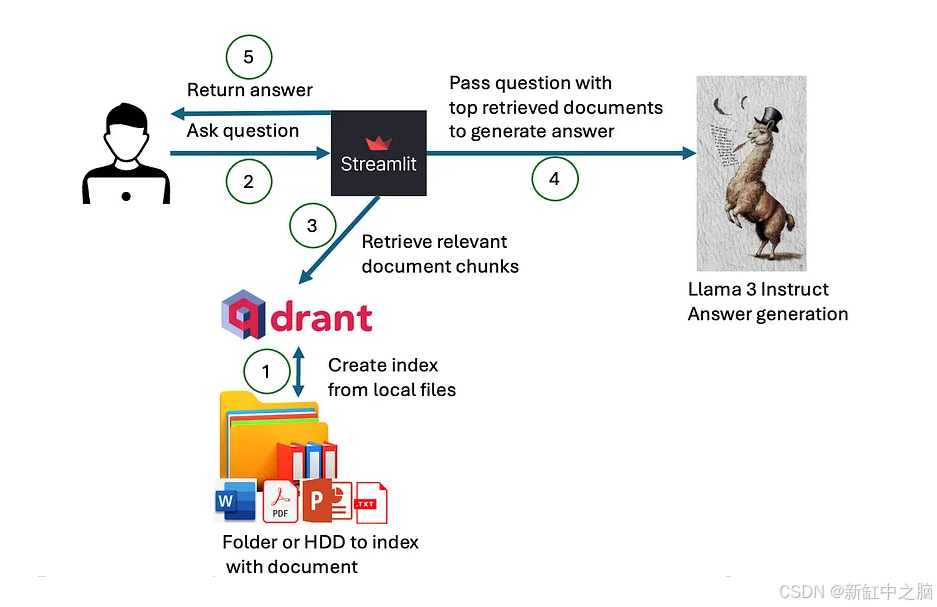
下图显示了组件如何交互:

系统设计和架构。Qdrant 用于向量存储,Streamlit 用于用户界面。Llama 3 可通过 Nvidia NIM API(70B 版本)使用,也可通过 HuggingFace(8B 版本)下载。文档分块使用 Langchain 完成
首先,我们需要将本地文件编入索引,以便查询本地文件的内容。然后,当用户提出问题时,我们将使用创建的索引以及一些不对称段落或文档嵌入来检索可能包含答案的最相关文档。这些文档的内容和问题将传递给已部署的大型语言模型,该模型将使用给定文档的内容来生成答案。在指令提示中,我们将要求大型语言模型也返回对所用文档的引用。最终,所有内容都将在用户界面上可视化给用户。
现在,让我们更详细地了解每个组件。
2、语义索引
我们正在构建一个语义索引,它将根据文件内容和给定查询的相似性为我们提供最相关的文档。要创建这样的索引,我们将使用 Qdrant 作为向量存储。有趣的是,Qdrant 客户端库不需要完整安装 Qdrant 服务器,并且可以对适合工作内存 (RAM) 的文档进行相似性分析。因此,我们需要做的就是 pip install Qdrant 客户端。
我们可以按以下方式初始化 Qdrant(请注意,由于故事流程,hf 参数稍后会定义,但使用 Qdrant 客户端,您已经需要定义正在使用哪种矢量化方法和度量):
from qdrant_client import QdrantClient
from qdrant_client.models import Distance, VectorParams
client = QdrantClient(path="qdrant/")
collection_name = "MyCollection"
if client.collection_exists(collection_name):
client.delete_collection(collection_name)
client.create_collection(collection_name,vectors_config=VectorParams(size=768, distance=Distance.DOT))
qdrant = Qdrant(client, collection_name, hf)为了创建向量索引,我们必须将文档嵌入硬盘。对于嵌入,我们必须选择正确的嵌入方法和正确的向量比较度量。可以使用多种段落、句子或单词嵌入方法,结果各不相同。基于文档创建向量搜索的主要问题是搜索不对称问题。不对称搜索问题在信息检索中很常见,当查询较短而文档较长时就会发生。单词或句子嵌入通常经过微调,以根据大小相似的文档(句子或段落)提供相似度分数。一旦情况并非如此,正确的信息检索可能会失败。
但是,我们可以找到一种可以很好地解决不对称搜索问题的嵌入方法。例如,在 MSMARCO 数据集上微调的模型通常效果很好。MSMARCO 数据集基于 Bing 搜索查询和文档,已由 Microsoft 发布。因此,它非常适合我们正在处理的问题。
对于这个特定的实现,我选择了一个已经微调的模型,称为:
senten 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









