







前言
本人主办公是轻薄本,之前训练都是借电脑,花700组装了台模型训练电脑,记录哈模型训练教程。
手把手带你用 YOLOv5 搭建一个属于自己的目标检测项目。
准备条件
安装 Anaconda 并熟悉基本命令:本项目主要基于 Conda 环境进行配置与管理
可以参考yolov5训练自己的数据集-----anaconda安装以及pycharm中环境配置-CSDN博客
一、下载源码
方法一:从官网直接下载(推荐)
打开 YOLOv5 的 GitHub 官方页面。
点击页面上的 “Code” 按钮,选择 “Download ZIP” 直接下载。
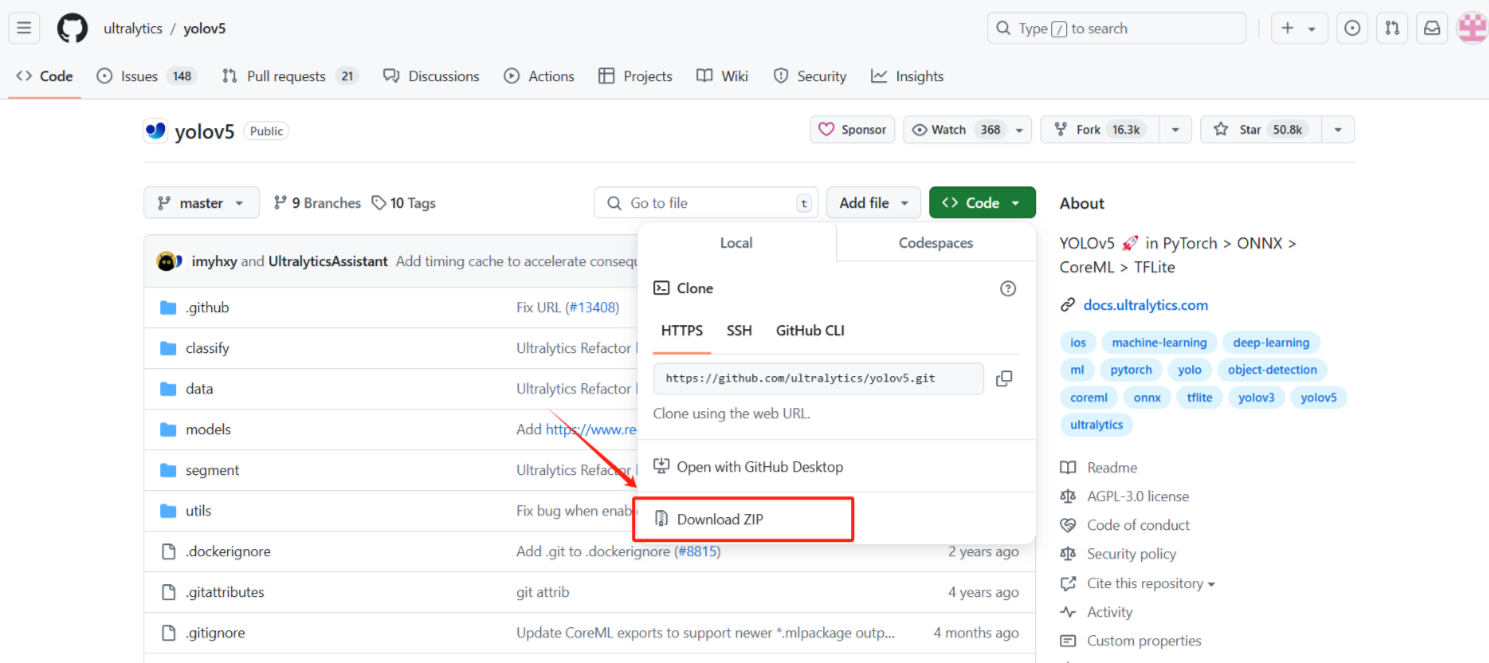
下载完后,建议将压缩包解压到 D 盘或 E 盘等非系统盘,以免因系统权限问题引发错误。
方法二:通过 Git 克隆源码(适合有基础的用户)
打开终端或命令提示符,输入以下命令将 YOLOv5 源码克隆到本地:
git clone https://github.com/ultralytics/yolov5下载完成后,进入 yolov5 文件夹:
cd yolov5增加一点:
安装git:
Git 详细安装教程(详解 Git 安装过程的每一个步骤)_git安装-CSDN博客
二、环境配置
1.本人使用pycharm激活
参考我另外一篇环境配置
yolov5训练自己的数据集-----anaconda安装以及pycharm中环境配置-CSDN博客
增加一个变动
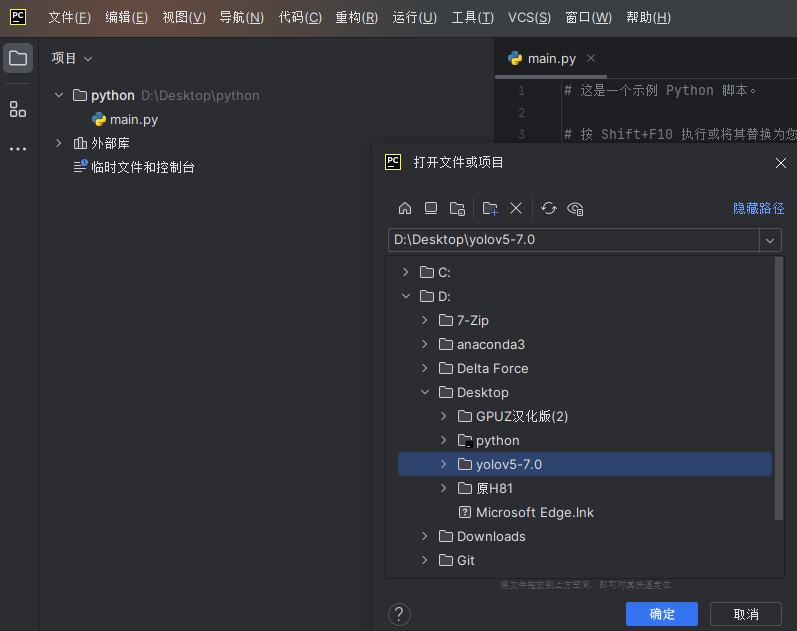
用pycharm打开yolov5源码
2.配置Pytorch环境
YOLOv5可以在GPU或CPU环境下运行,但推荐在GPU上运行以加快训练速度。
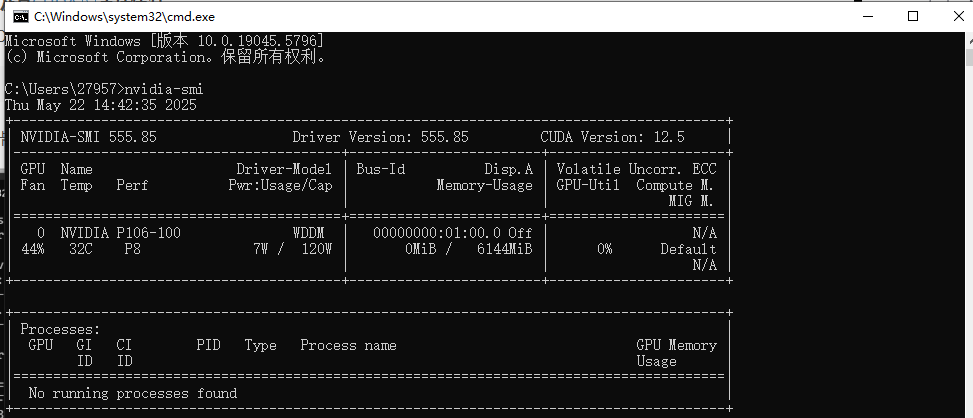
nvidia-smi是NVIDIA驱动自带的命令行工具,可以查看显卡的CUDA支持情况和驱动信息。打开命令提示符(或CMD),输入:
nvidia-smi
方式一:使用Conda安装(推荐)
-
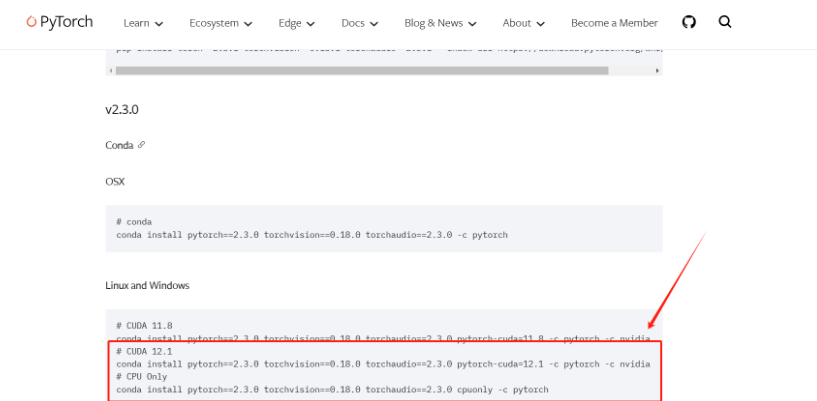
打开 Previous PyTorch Versions | PyTorch 官网,选择<= CUDA Version 的Conda命令并复制(若不支持GPU则选择 CPU 的Conda命令)。
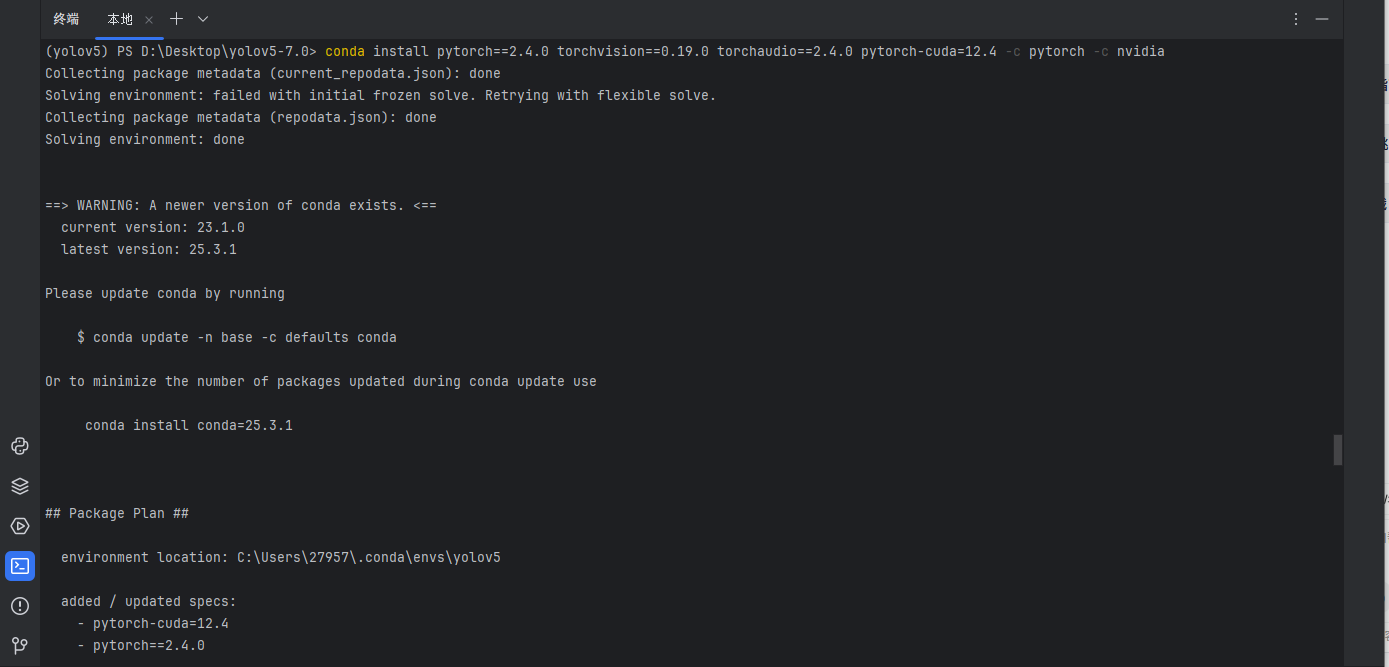
-
在终端中执行对应的安装命令,以安装PyTorch和CUDA / CPU支持。
-
安装完成后,可以在终端中输入
conda list pytorch检查安装情况:(本教程仅展示CUDA版本的安装结果)
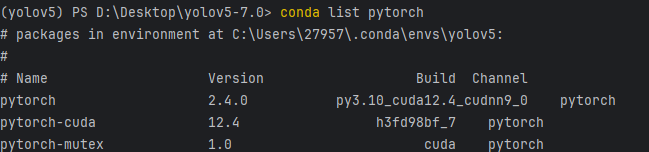
我使用方式1
方式二:使用Pip安装
打开 Previous PyTorch Versions | PyTorch 官网,选择<= CUDA Version 的Pip命令并复制(若不支持GPU则选择 CPU 的Pip命令)。
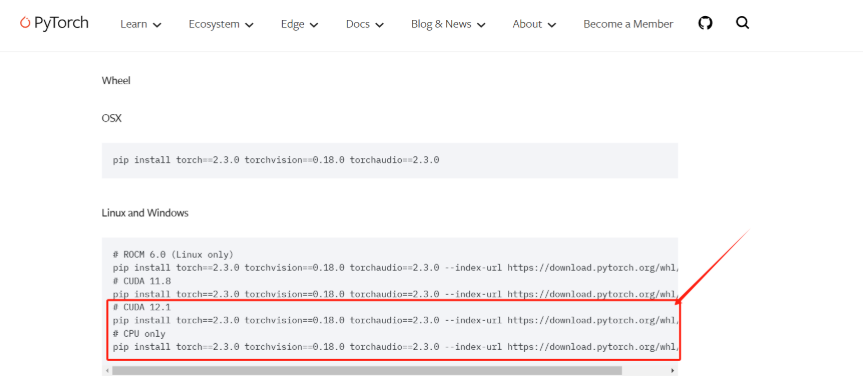
在终端中执行对应的安装命令,以安装PyTorch和CUDA / CPU支持。
安装完成后,可以在终端中输入pip list检查安装情况。
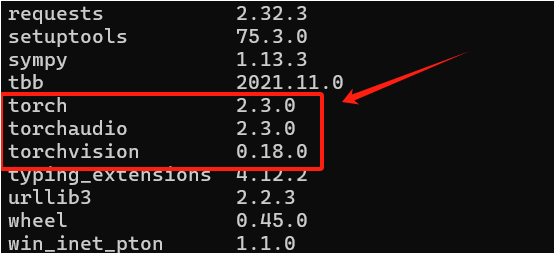
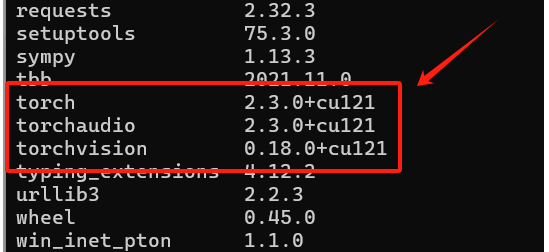
torch 2.3.0:核心库(版本2.3.0),用于构建和训练神经网络。
torchaudio 2.3.0:音频处理库(版本2.3.0),为音频数据的加载、预处理和增强提供了工具
torchvision 0.18.0:计算机视觉库(版本0.18.0),包含了常用的图像数据集、数据增强和预训练模型。
下载安装CUDA支持的torch + torchvision + torchaudio (仅GPU版本需要)。
打开网址 https://download.pytorch.org/whl/torch_stable.html
选择与上面对应版本的torch并下载至本地
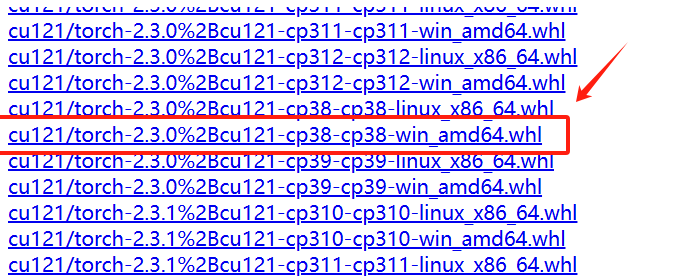
cu121:表示此安装包支持 CUDA 12.1,也就是说,这个版本的 PyTorch 可以利用带有 CUDA 12.1 的 NVIDIA GPU 进行计算加速。
torch-2.3.0+cu121:说明这是 PyTorch 2.3.0 版本的安装包,并且这个版本支持 CUDA 12.1。在 PyTorch 中,不同 CUDA 版本对应不同的 GPU 支持,确保安装的 PyTorch 版本兼容设备的 CUDA 版本很重要。
cp38-cp38:表示该安装包是针对 Python 3.8(“cp38”代表 CPython 3.8)的版本。这里的 cp38-cp38 意味着此包适用于 Python 3.8 的 CPython 解释器(CPython 是 Python 的标准实现)。
win_amd64:表示该安装包适用于 Windows 操作系统,并支持 64位架构(AMD64)。如果您的系统是 Windows 64 位,这个包是兼容的。
在终端中输入以下命令以安装指定的 .whl 文件(请将路径替换为您下载的 .whl 文件的实际保存位置)
pip install D:\torch_gpu\torch-2.3.0+cu121-cp38-cp38-win_amd64.whltorchvision与torchaudio安装方式同理
安装完毕后再次在终端中输入pip list检查安装情况,如果输出结果中显示类似以下内容,则表明安装成功
yolov5依赖安装
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
三、数据集准备
推荐一个我自己用的工具
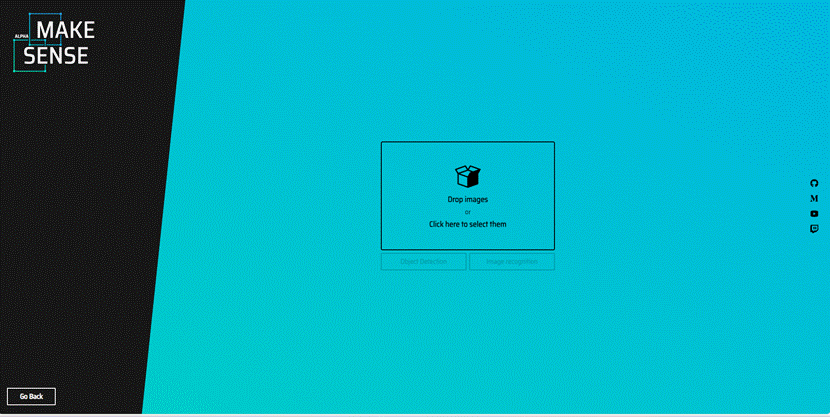
点Drop images选择图片
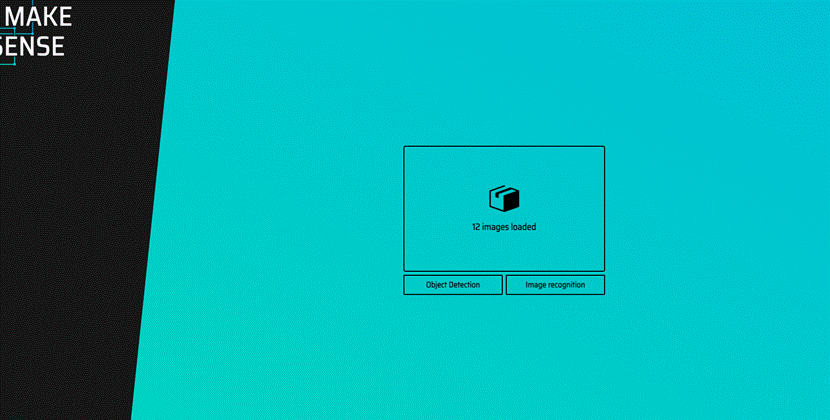
选择object
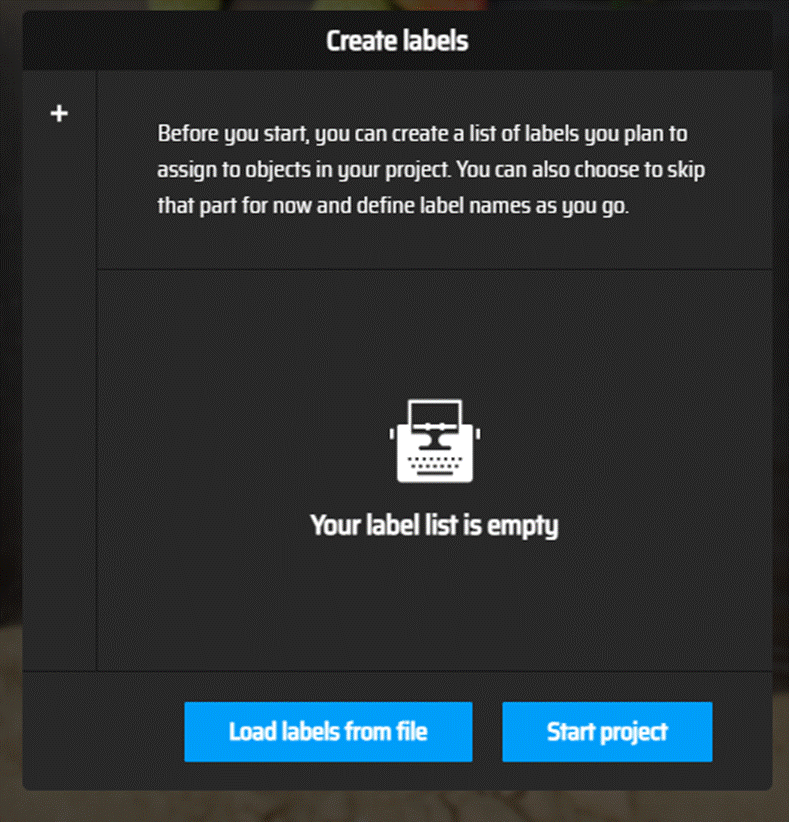
这里可以自己建立标签(点击+就能创建)和导入标签(load labels)
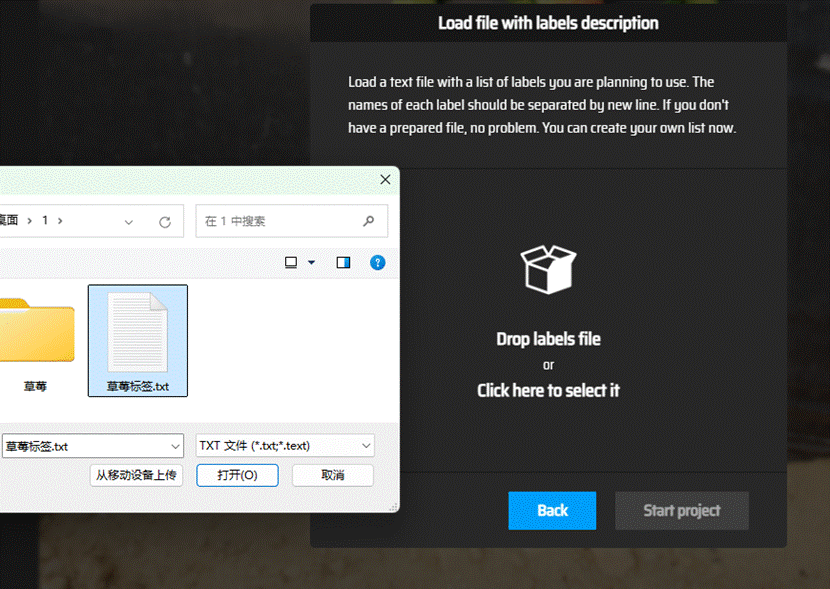
导入标签
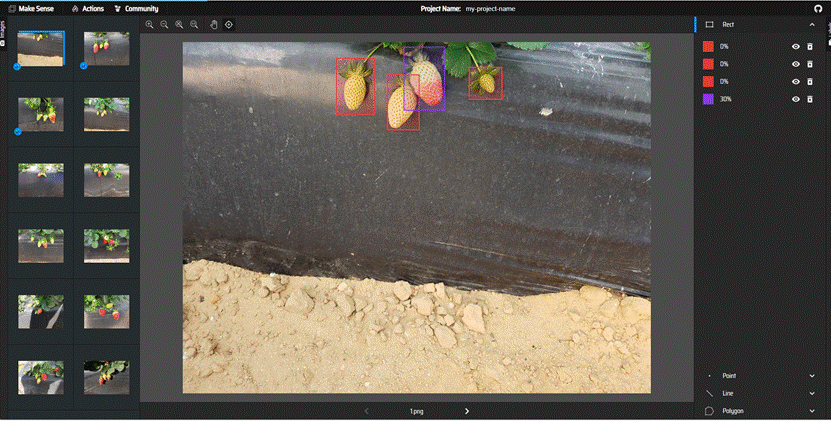
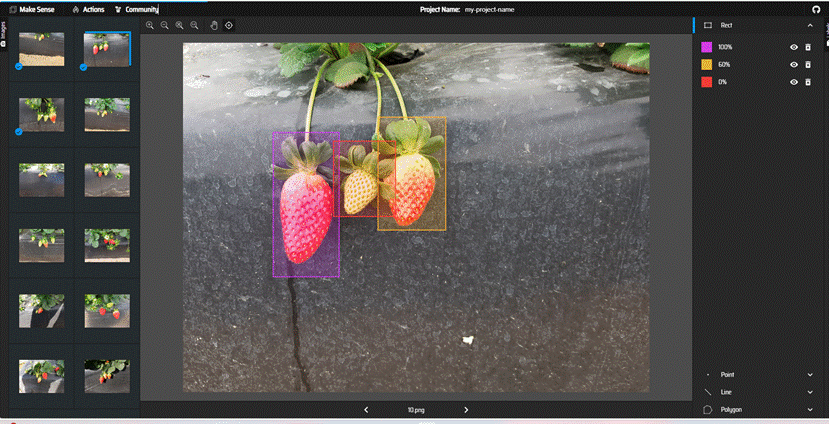
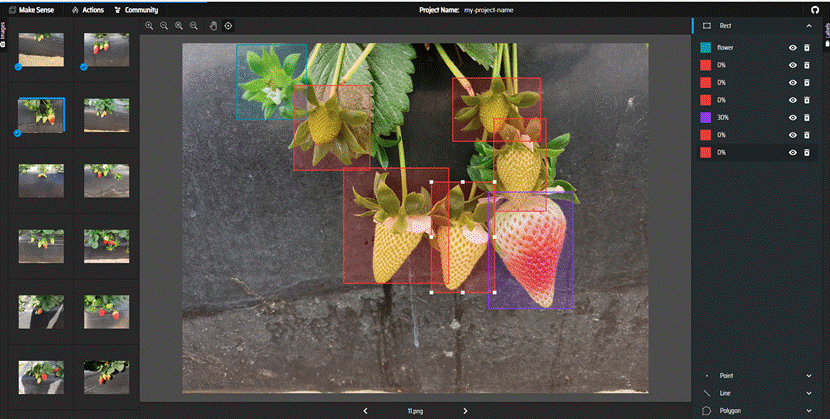
保存文件:

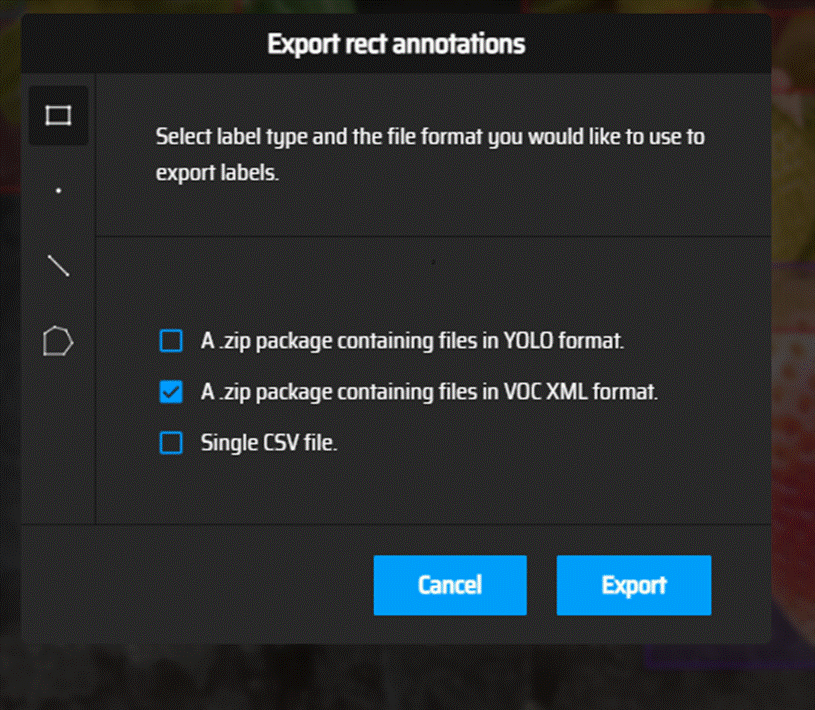
根据自己需要保存。我自己yolov5用xml,yolov8用了YOLO。
文件准备
-
在 yolov5 根目录下创建一个文件夹 VOCData。
-
在 VOCData 文件夹内创建以下两个子文件夹,并存放数据:
- images:存放待标注的图像文件(JPG格式)。
- Annotations:存放标注后的文件(采用 XML 格式)。、
-
VOCData/ ├── images/ # 存放图像文件 ├── Annotations/ # 存放标注文件 -
在 VOCData 目录下创建程序
split_train_val.py并运行(划分训练集、验证集、测试集) -
# coding:utf-8 # 本代表无需做任何修改,可直接运行 import os import random import argparse parser = argparse.ArgumentParser() #xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下 parser.add_argument('--xml_path', default='Annotations', type=str, help='input xml label path') #数据集的划分,地址选择自己数据下的ImageSets/Main parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path') opt = parser.parse_args() trainval_percent = 1.0 # 训练集和验证集所占比例。 这里没有划分测试集 train_percent = 0.9 # 训练集所占比例,可自己进行调整 xmlfilepath = opt.xml_path txtsavepath = opt.txt_path total_xml = os.listdir(xmlfilepath) if not os.path.exists(txtsavepath): os.makedirs(txtsavepath) num = len(total_xml) list_index = range(num) tv = int(num * trainval_percent) tr = int(tv * train_percent) trainval = random.sample(list_index, tv) train = random.sample(trainval, tr) file_trainval = open(txtsavepath + '/trainval.txt', 'w') file_test = open(txtsavepath + '/test.txt', 'w') file_train = open(txtsavepath + '/train.txt', 'w') file_val = open(txtsavepath + '/val.txt', 'w') for i in list_index: name = total_xml[i][:-4] + '\n' if i in trainval: file_trainval.write(name) if i in train: file_train.write(name) else: file_val.write(name) else: file_test.write(name) file_trainval.close() file_train.close() file_val.close() file_test.close()运行完成后,将生成 ImageSets/Main 文件夹,并在该文件夹下生成包含测试集、训练集和验证集的文本文件,用于存放各数据集中图片的文件名(不包含 `.jpg` 后缀)。 由于默认未分配测试集,因此测试集文件为空。 如需分配测试集,可通过修改代码中的第 14 和 15 行来调整数据集划分比例。 - 在 VOCData 目录下创建程序
xml_to_yolo.py并运行(XML 格式转换为 YOLO 格式) -
# -*- coding: utf-8 -*- import xml.etree.ElementTree as ET import os from os import getcwd sets = ['train', 'val', 'test'] classes = ["light", "post"] # 改成您自定义数据集的类别 abs_path = os.getcwd() print(abs_path) # 请将本代码中的所有绝对路径替换为您的本地路径 def convert(size, box): dw = 1. / (size[0]) dh = 1. / (size[1]) x = (box[0] + box[1]) / 2.0 - 1 y = (box[2] + box[3]) / 2.0 - 1 w = box[1] - box[0] h = box[3] - box[2] x = x * dw w = w * dw y = y * dh h = h * dh return x, y, w, h def convert_annotation(image_id): in_file = open('D:/yolov5/VOCData/Annotations/%s.xml' % (image_id), encoding='UTF-8') # 需要修改 out_file = open('D:/yolov5/VOCData/labels/%s.txt' % (image_id), 'w') # 需要修改 tree = ET.parse(in_file) root = tree.getroot() size = root.find('size') w = int(size.find('width').text) h = int(size.find('height').text) for obj in root.iter('object'): difficult = obj.find('difficult').text # difficult = obj.find('Difficult').text cls = obj.find('name').text if cls not in classes or int(difficult) == 1: continue cls_id = classes.index(cls) xmlbox = obj.find('bndbox') b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) b1, b2, b3, b4 = b if b2 > w: b2 = w if b4 > h: b4 = h b = (b1, b2, b3, b4) bb = convert((w, h), b) out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') wd = getcwd() for image_set in sets: if not os.path.exists('D:/yolov5/VOCData/labels/'): # 需要修改 os.makedirs('D:/yolov5/VOCData/labels/') # 需要修改 image_ids = open('D:/yolov5/VOCData/ImageSets/Main/%s.txt' % (image_set)).read().strip().split() # 需要修改 if not os.path.exists('D:/yolov5/VOCData/dataSet_path/'): # 需要修改 os.makedirs('D:/yolov5/VOCData/dataSet_path/') # 需要修改 list_file = open('dataSet_path/%s.txt' % (image_set), 'w') # 这行路径不需更改,这是相对路径 for image_id in image_ids: list_file.write('D:/yolov5/VOCData/images/%s.jpg\n' % (image_id)) # 需要修改 convert_annotation(image_id) list_file.close()运行后将生成 labels 文件夹和 dataSet_path 文件夹: labels 文件夹中包含每个图像对应的标注文件。每个图像对应一个 .txt 文件,每行记录一个目标的信息,格式为 class, x_center, y_center, width, height,即 YOLO 格式。 dataSet_path 文件夹包含三个数据集的 .txt 文件,例如 train.txt 文件包含训练集图像的路径,每行表示一个图像的位置路径。 - 在 yolov5 根目录下的 data 文件夹中创建一个名为
myvoc.yaml的文件(准备配置文件) -
# 需要将下面两个绝对路径替换为您的本地路径 train: D:/yolov5/VOCData/dataSet_path/train.txt val: D:/yolov5/VOCData/dataSet_path/val.txt # 您自定义数据集类别的数量 nc: 2 # 您自定义数据集的类别,注意这里的内容及顺序需要与xml_to_yolo.py代码中classes列表内容相同 names: ["light", "post"] - 在 yolov5 根目录下创建一个文件夹 weights ,打开 YOLOv5 官方 GitHub,下滑找到预训练权重,点击下载至
weights文件夹(下载预训练权重)
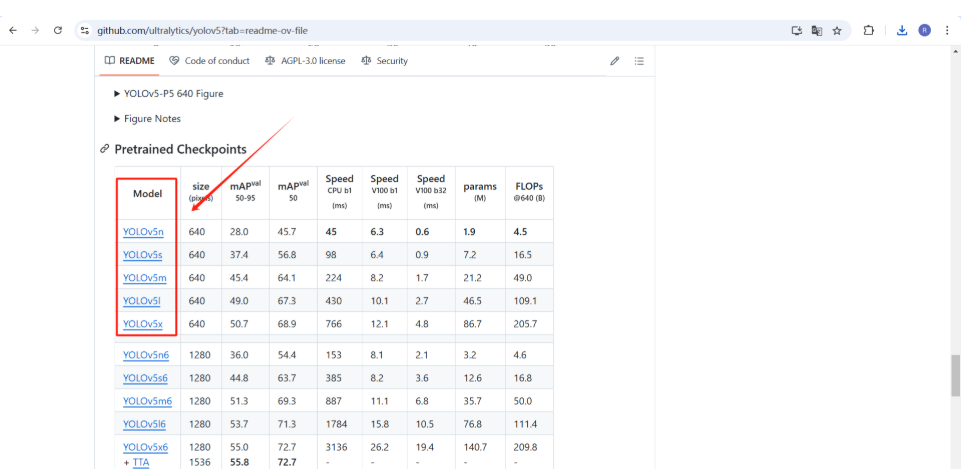
weights/
├── yolov5n.pt
├── yolov5s.pt
├── yolov5m.pt
├── ...
四、模型训练
pycharm打开train.py的433行
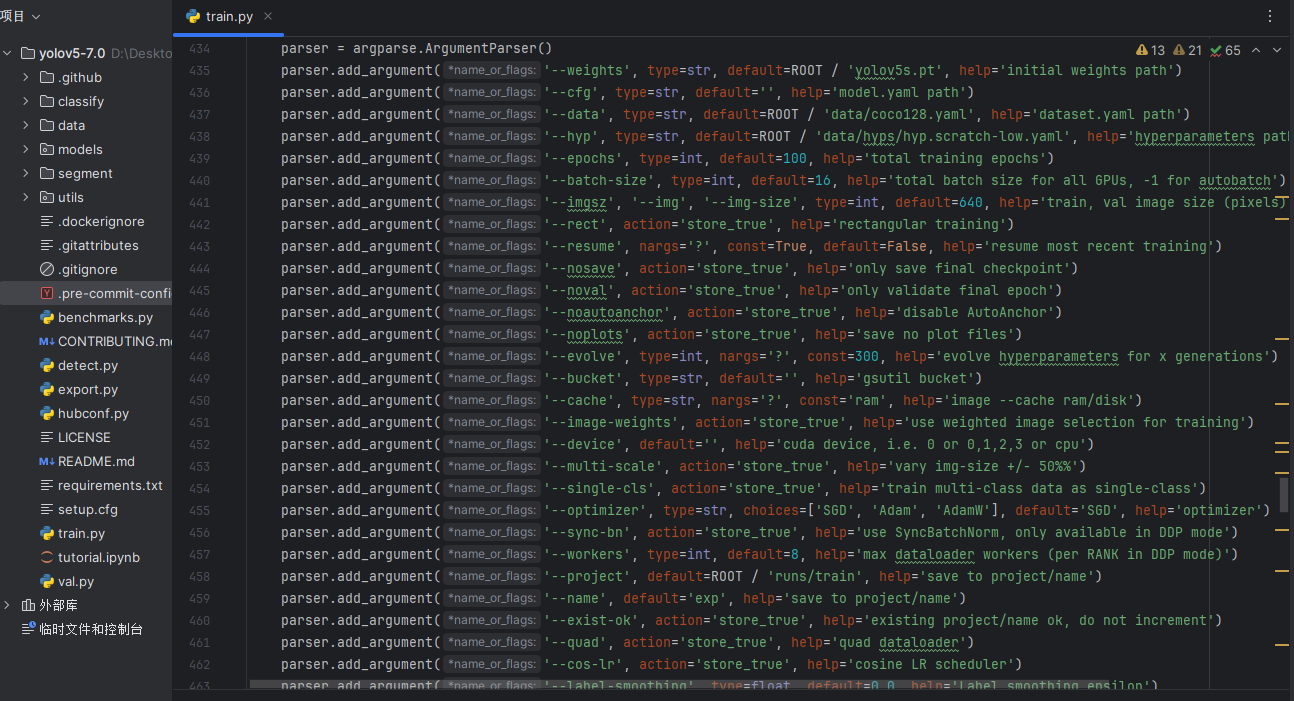
参数说明如下(注意epochs及device):
--weights:指定预训练模型权重文件的路径。
--cfg:模型配置文件的路径,定义网络结构。
--data:数据集配置文件的路径。
--epochs:训练的轮数,即模型将完整遍历数据集的次数(例如:200)。
--batch-size:批次大小,即每次训练中处理的图片数量(例如:8)。
--img:输入图像的尺寸,指定训练时图像的宽和高(例如:640)。
--device:指定使用的设备,输入 cpu 表示在 CPU 上进行训练;输入数字如 0, 1, 2, 3 则表示对应的 GPU 编号。例如:
--device 0 表示使用默认第一个 GPU;
--device 0,1 表示同时使用第一个和第二个 GPU(适合多 GPU 训练)。
当有多个 GPU 时,可以通过 nvidia-smi 命令查看每个 GPU 的编号
修改为:
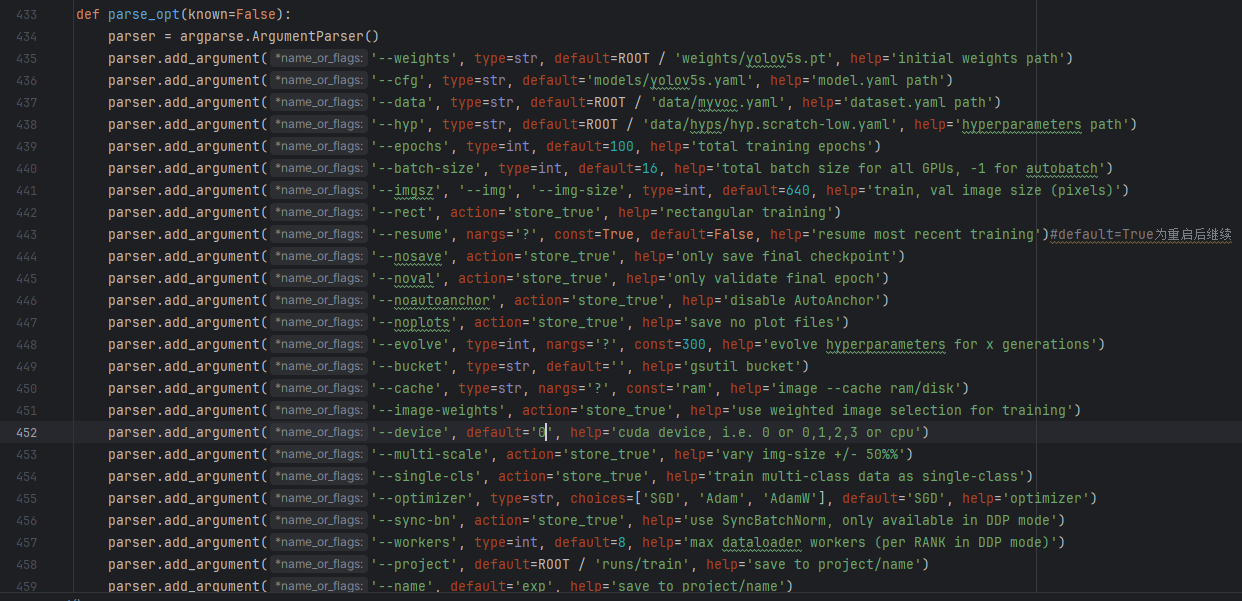 点击运行,就开始训练了
点击运行,就开始训练了
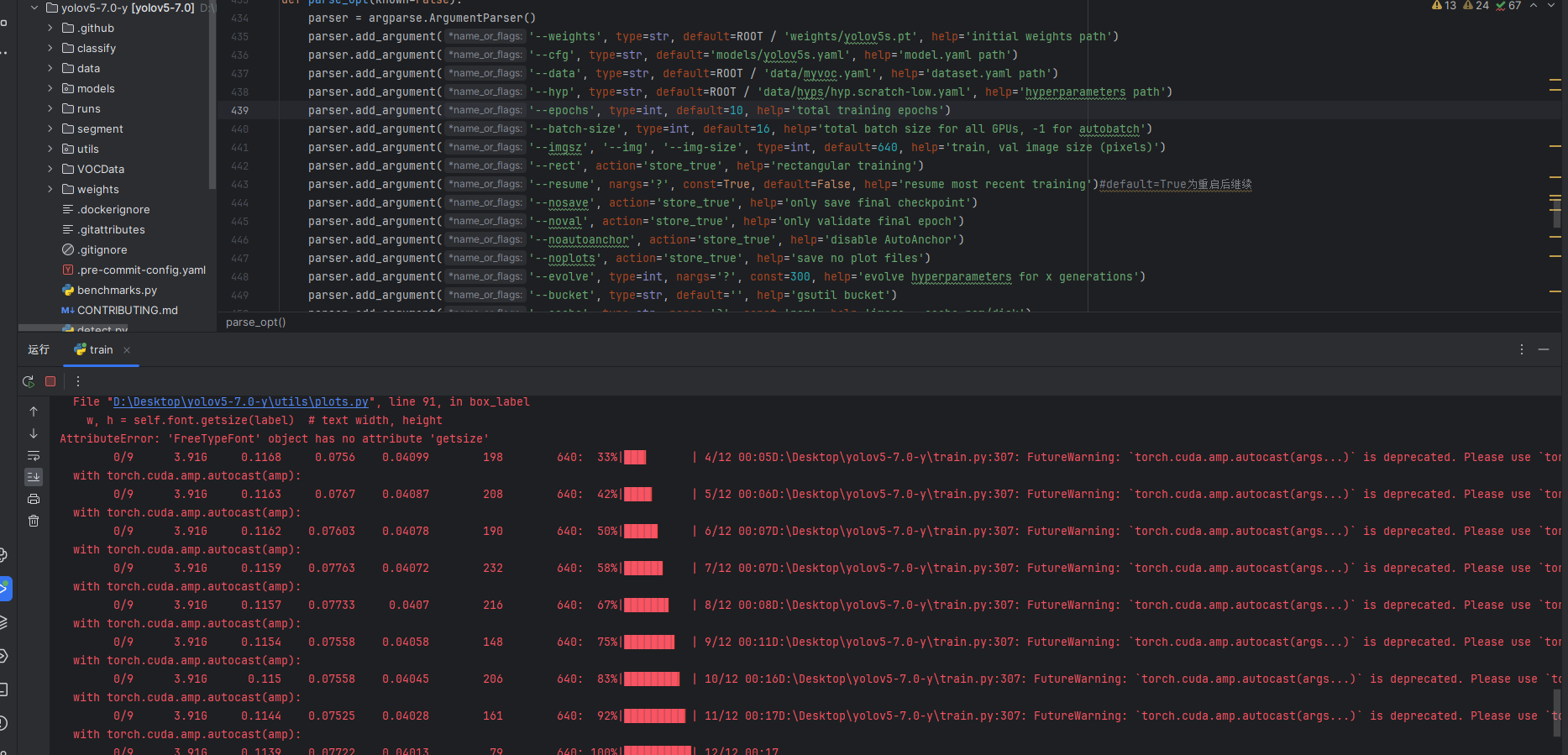
训练完成后,训练结果会自动保存在runs/train/目录下。
五、验证测试
使用YOLOv5的detect.py脚本进行推理测试:
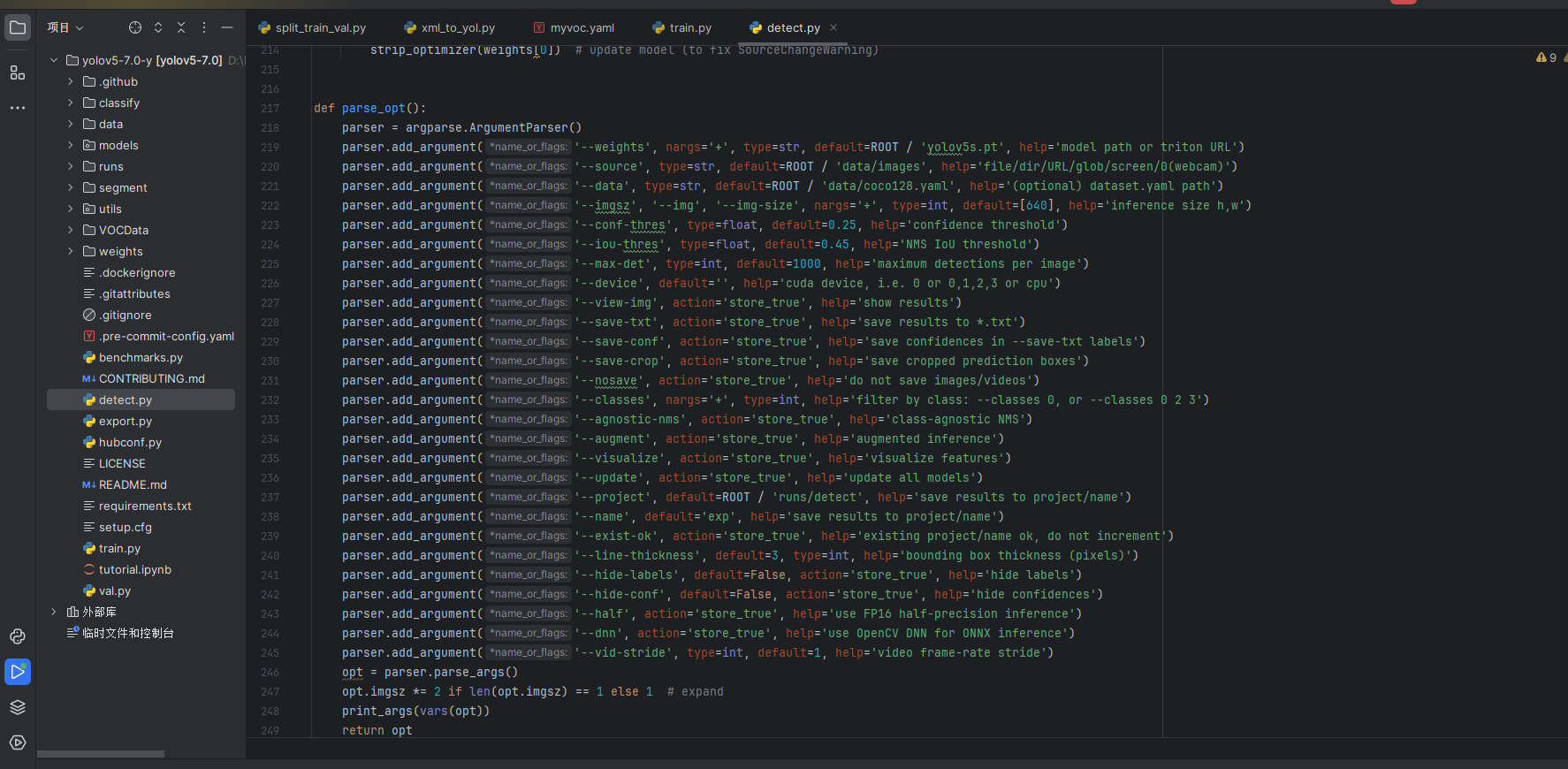
--weights:训练生成的模型权重路径。
--source 参数指定推理的输入源,支持以下几种格式:
单张图片:/path/to/image.jpg
文件夹(多张图片):/path/to/images/
视频文件:/path/to/video.mp4
摄像头:使用 0 表示默认摄像头
网络流:支持 RTSP/HTTP URL,例如 rtsp://username:password@ip_address:port
运行后,YOLOv5会在runs/detect目录中保存带有预测框的图片,便于观察检测效果。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









