








现在我们都知道Geoffrey Hinton的胶囊网络(Capsule Network)震动了整个人工智能领域,它将卷积神经网络(CNN)的极限推到一个新的水平。 网上已经有很多的帖子、文章和研究论文在探讨胶囊网络理论,以及它如何做的比传统的CNN更好。因此我不打算介绍这方面的内容,而是尝试使用谷歌的Colaboratory工具在TensorFlow上实现CpNet。
你可以通过下面的几个链接了解CpNet的理论部分:
现在我们开始写代码。
开始之前,你可以参考我的CoLab Notebook执行以下代码:
CoLab网址:https://goo.gl/43Jvju
现在克隆github上的仓库并安装依赖库。 然后,我们从仓库中取出MNIST数据集,并将其移至父目录:
!git clone https://github.com/bourdakos1/capsule-networks.git
!pip install -r capsule-networks / requirements.txt
!touch capsule-networks / __ init__.py
!mv capsule-networks capsule
!mv capsule / data / ./data/
!ls现在让我们导入所有的模块:
import os
import tensorflow as tf
from tqdm import tqdm
from capsule.config import cfg
from capsule.utils import load_mnist
from capsule.capsNet import CapsNet初始化
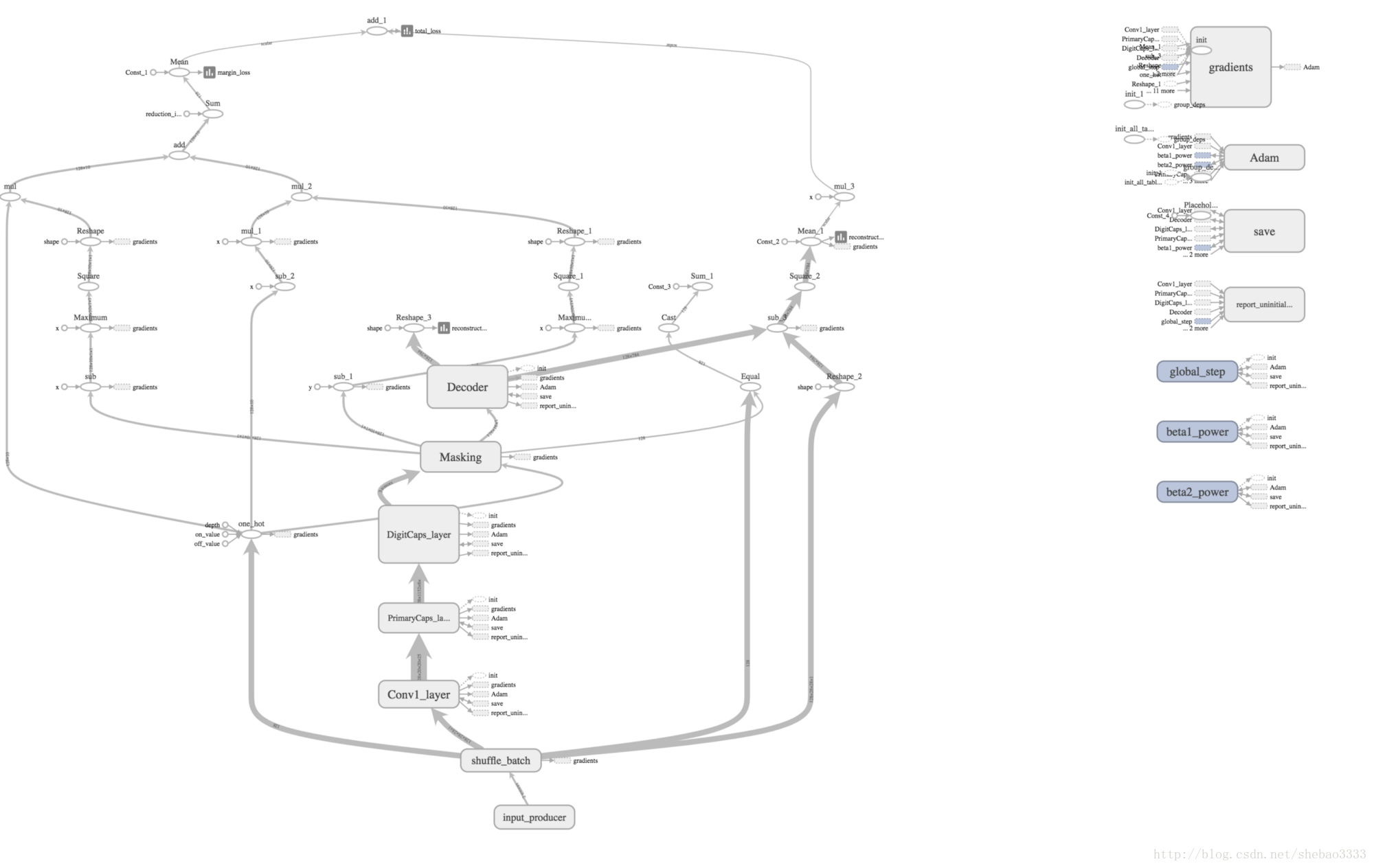
capsNet = CapsNet(is_training = cfg.is_training)这就是胶囊网络(CpNet)在Tensorboard图上的样子:
训练
tf.logging.info('Graph loaded')
sv = tf.train.Supervisor(graph = capsNet.graph,
logdir = cfg.logdir,
save_model_secs = 0)
path = cfg.results +'/accuracy.csv'
if not os.path.exists(cfg.results):
os.mkdir(cfg.results)
elif os.path.exists(path):
os.remove(path)
fd_results = open(path,'w')
fd_results.write('step, test_acc\n') 现在创建TF会话(session)并开始执行。
默认情况下,模型将被训练50个epoch,批次大小为128。 你可以尝试不同的超参数组合:
with sv.managed_session() as sess:
num_batch = int(60000 / cfg.batch_size)
num_test_batch = 10000 // cfg.batch_size
teX, teY = load_mnist(cfg.dataset, False)
for epoch in range(cfg.epoch):
if sv.should_stop():
break
for step in tqdm(range(num_batch), total=num_batch, ncols=70, leave=False, unit='b'):
global_step = sess.run(capsNet.global_step)
sess.run(capsNet.train_op)
if step % cfg.train_sum_freq == 0:
_, summary_str = sess.run([capsNet.train_op, capsNet.train_summary])
sv.summary_writer.add_summary(summary_str, global_step)
if (global_step + 1) % cfg.test_sum_freq == 0:
test_acc = 0
for i in range(num_test_batch):
start = i * cfg.batch_size
end = start + cfg.batch_size
test_acc += sess.run(capsNet.batch_accuracy, {capsNet.X: teX[start:end], capsNet.labels: teY[start:end]})
test_acc = test_acc / (cfg.batch_size * num_test_batch)
fd_results.write(str(global_step + 1) + ',' + str(test_acc) + '\n')
fd_results.flush()
if epoch % cfg.save_freq == 0:
sv.saver.save(sess, cfg.logdir + '/model_epoch_%04d_step_%02d' % (epoch, global_step))
fd_results.close()
tf.logging.info('Training done')
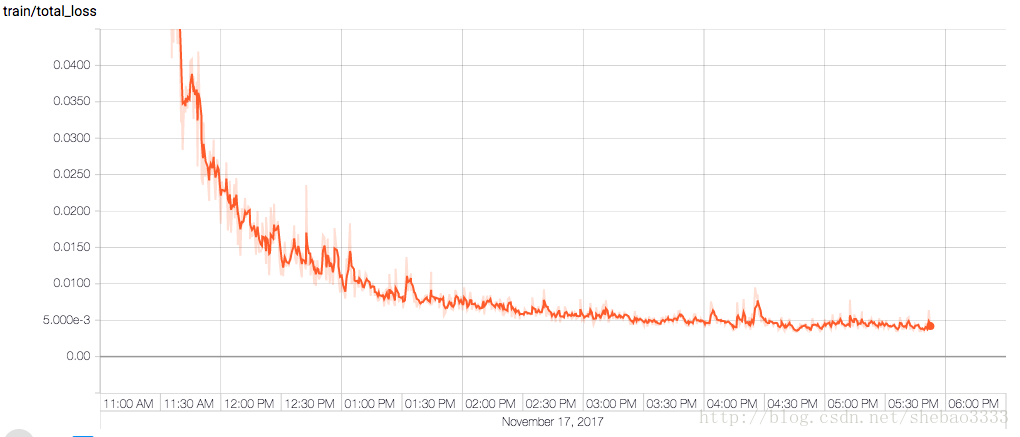
在NVIDIA TitanXp卡上运行50个
epoch,花了大约6个小时。
但经过训练的网络效果惊人,总损失(total loss)达到了不可思议的0.0038874。
下载训练好的模型
CpNet模型网址: https://goo.gl/DN7SS3

















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









