








论文标题:Pose-Appearance Relational Modeling for Video Action Recognition
论文链接:https://ieeexplore.ieee.org/document/9986038/
代码链接:https://github.com/Mona9955/PARNet
作者单位:中科院自动化所(Liang Wang,IEEE Fellow)
欢迎关注微信公众号 CV顶刊顶会 ,严肃且认真的计算机视觉论文前沿报道~

期刊介绍:IEEE Transactions on Image Processing(IEEE TIP)是图像处理领域公认的顶级国际期刊,是中国计算机学会(CCF)推荐的A类期刊,代表了图像处理领域先进的重大进展,要求论文在理论和工程效果上对图像处理及相关领域具有重要推动作用,其最新的影响因子为15.8。
现阶段,视频行为识别的最新研究主要可以分为两大类:基于外观建模的方法和基于姿态建模的方法。前者通常不使用光流估计来模拟较大动作的时序动态,而后者则忽略了当前行为发生场景和物体等视觉上下文信息,这些信息都是动作识别的重要线索。基于这样的研究现状,来自中国科学院自动化研究所的研究团队提出一种姿势外观联合关系建模网络 (Pose- Appearance Relational Network,PARNet) 发表在图像领域顶级期刊IEEE TIP上。 PARNet巧妙的利用了基于外观和基于姿态两种行为识别方法的优势,来提高模型对真实世界视频的鲁棒性。PARNet中包含有三个网络流,即姿态流、外观流和关系流。对于姿势流,作者构建了一个时序多姿势 RNN 模块,通过对 2D 姿态的时序变化进行建模获得动态表示。对于外观流,使用空间外观 CNN 模块来提取视频序列的全局外观表示。对于关系流,构建了一个姿态感知 RNN 模块,通过对动作敏感的视觉上下文信息建模来连接姿势和外观流。通过联合优化三个模块,PARNet 在姿态精确行为数据集(KTH、Penn-Action、UCF11)和具有挑战性的姿势不精确数据集(UCF101、HMDB51、JHMDB)均达到了SOTA性能。展示了PARNet对复杂环境和嘈杂骨架信息的泛化能力,此外,作者在 NTU-RGBD 数据集上,与目前流行的基于 3D 骨架的方法进行性能对比,PARNet也能获得具有竞争力的识别效果。
1.引言
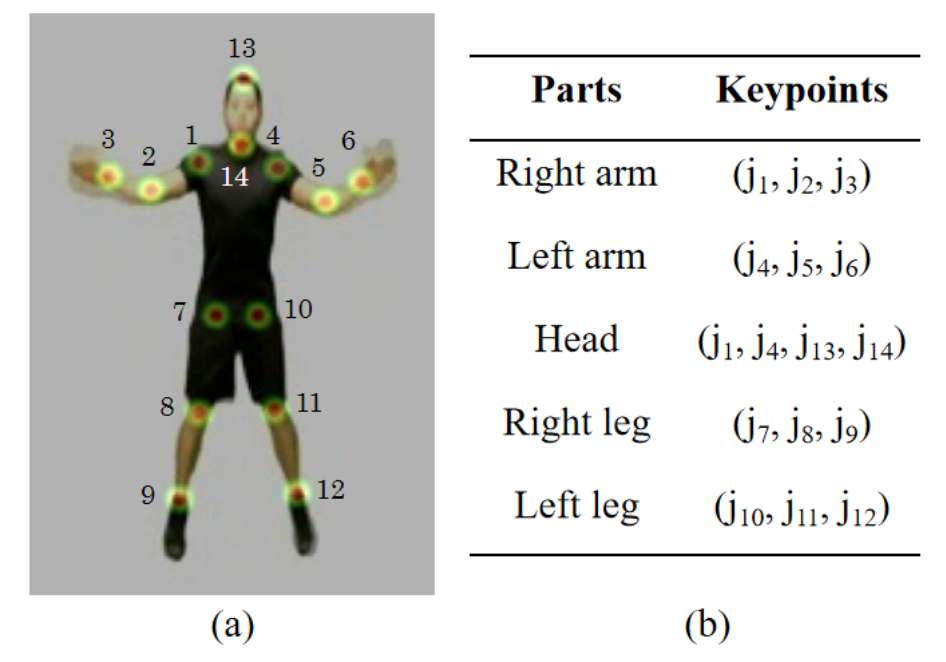
为了有效精确地将视频中人体的姿态信息引入到识别网络中,作者使用预训练的多人场景2D姿态估计器OpenPose[1]进行姿态估计,对于单个人体而言,该姿态估计器可以生成14个关键点(而不是传统方法中使用的 18 个关键点),如下图所示。
下图展示了各种行为识别数据集中的姿态估计示例,其中第一行的估计效果动作清晰、姿势完整。第二行显示了一些困难样本,其中包括拥挤环境、小目标和身体不全导致的失败估计。第三行显示了几个失败案例。不稳定的姿态估计会严重影响基于姿态的行为识别方法的性能。

2.本文方法
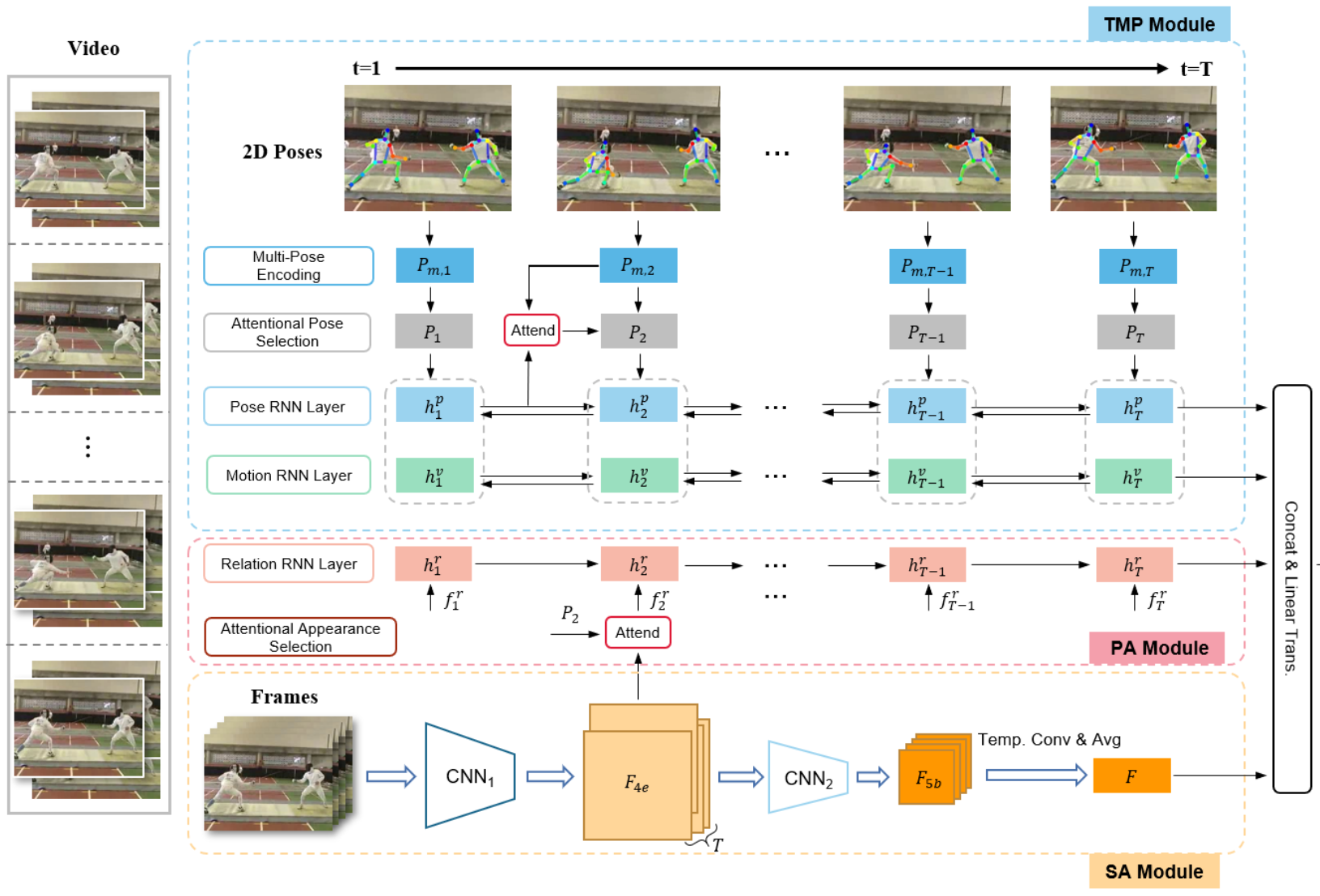
为了应对上述挑战,本文提出了一种姿势外观联合关系建模网络 PARNet,下图为PARNet的整体框架。PARNet由时序多姿态RNN模块(TMP Module)、空间外观模块(Spatial Appearance,SA)和姿态感知RNN模块(Pose-Aware,PA)构成。三个模块分别针对2D姿态的时序建模、视频帧的空间建模以及这两种模态的关系建模而构建。考虑到现实生活中大量的多人动作场景,例如对抗性或合作性的运动(例如拳击和舞蹈),以及背景中有无关人员的活动(例如跳高和人群拥挤的情况),作者将设计重点放在了检测到的多个人体姿态上。PARNet不单独处理视频中的每个人,也不直接将他们聚合在一起,而是能够同时关注多个目标信息,同时忽略不相关的角色。PARNet通过 PA 模块对视频中姿态和外观特征的关系进行建模,在每个迭代步骤中着重捕获动作敏感的外观信息,生成的姿态感知特征可以为 TMP 模块的动态表示提供上下文信息的补充。
2.1 时序注意力LSTM架构(TA-LSTM)
上文提到,PARNet中共包含三个信息处理流,作者使用经典的RNN结构来捕获其中的时序动态,作者首先介绍了使用的TA-LSTM模块,它是 PARNet 中 RNN 层的基本组件,其构成细节如下图所示。
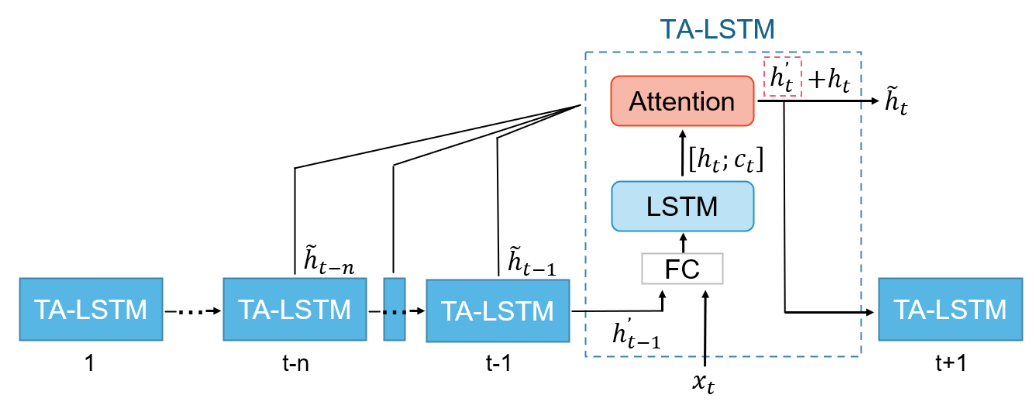
对于时间步 t t t,TA-LSTM接受来自上一个迭代步骤的注意力向量 h t − 1 ′ h_{t-1}^{\prime} ht−1′ 与当前输入 s t s_t st 的拼接向量,随后隐藏状态 h t h_t ht 和 状态变量 c t c_t ct 的计算如下:
x t ′ = W i [ x t ; h t − 1 ′ ] [ i t f t o t c ^ t ] = [ σ σ σ tanh ] W ⋅ [ x t ′ ; h t − 1 ] c t = f t ⊙ c t − 1 + i t ⊙ c ^ t h t = o t ⊙ tanh ( c t ) \begin{aligned} x_{t}^{\prime} & =W_{i}\left[x_{t} ; h_{t-1}^{\prime}\right] \\ {\left[\begin{array}{c} i_{t} \\ f_{t} \\ o_{t} \\ \hat{c}_{t} \end{array}\right] } & =\left[\begin{array}{c} \sigma \\ \sigma \\ \sigma \\ \tanh \end{array}\right] W \cdot\left[x_{t}^{\prime} ; h_{t-1}\right] \\ c_{t} & =f_{t} \odot c_{t-1}+i_{t} \odot \hat{c}_{t} \\ h_{t} & =o_{t} \odot \tanh \left(c_{t}\right) \end{aligned} xt′ itftotc^t ctht=Wi[xt;ht−1′]= σσσtanh W⋅[xt′;ht−1]=ft⊙ct−1+it⊙c^t=ot⊙tanh(ct)
其中 W i W_i Wi, W W W 为全连接层的模型参数, σ \sigma σ 和 ⊙ \odot ⊙ 分别为 sigmoid 激活函数和点积函数。
2.2 时序多姿态RNN模块(TMP Module)
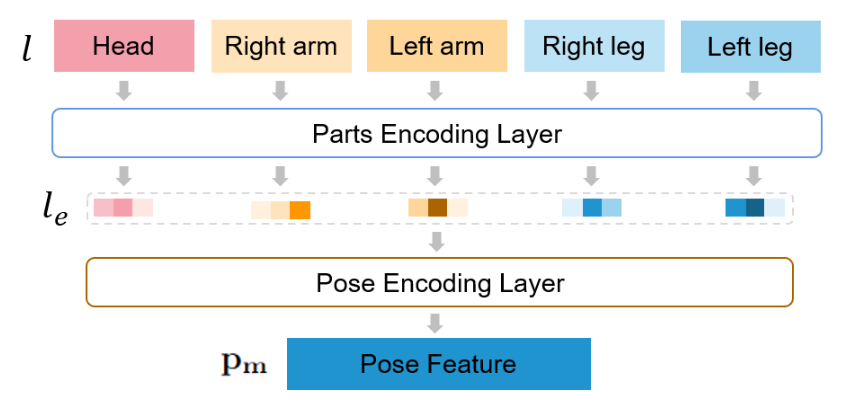
对于姿态流,作者设计了一个可以对多人姿态骨架进行建模的编码层,下图展示了编码层结构,给定姿态关键点的二维坐标作为输入,随后编码层根据身体拓扑结构生成高级姿态特征。首先设置每个帧中的最大人数为 N N N。随后利用数据裁剪和零填充方式将多个人体姿势调整为固定大小 N × K × 2 N × K × 2 N×K×2,其中 K K K 表示是关键点编号,在本文的方法中为 14,2对应于 ( x , y ) (x, y) (x,y) 坐标。对于画面中的每个人,骨架关键点根据语义关系分为五个身体部位,并通过一个多层感知器 (MLP) 进行编码。最后,将编码后的部分特征 l e = { l e i } i = 1 5 l_{e}=\left\{l_{e_{i}}\right\}_{i=1}^{5} le={lei}i=15 拼接起来,通过姿态编码层进行线性变换,得到姿态向量 p m \mathbf{p_m} pm。
随后通过Multi-Pose Attention RNN层进行迭代处理,此时,姿态RNN层作为TA-LSTM的基本单元,在每个迭代步骤中,先前的输出 h ~ t − 1 p \tilde{h}_{t-1}^{p} h~t−1p 用于对当前多人姿态进行注意力选择,随后,姿态融合向量 P t P_t Pt 由以下方式生成:
P t = Attention p ( h ~ t − 1 p , P m , t ) P_{t}=\text { Attention }_{p}\left(\tilde{h}_{t-1}^{p}, P_{m, t}\right) Pt= Attention p(h~t−1p,Pm,t)
2.3 空间外观模块(Spatial Appearance,SA)
对于外观流,作者使用2D CNN从帧序列中提取空间特征。考虑到效率和准确性,采用了 BN-Inception 架构[2]。由于2D CNN 模型的输出包括具有不同分辨率的两阶段特征图,其中位置靠前的卷积层保留了更丰富的空间信息,因此作者将来自inception-4e层的中级特征序列导出到随后的姿态感知RNN模块中。同时,使用来自最后卷积层的高级特征序列 F 5 b ∈ R T × 7 × 7 × 1024 F_{5 b} \in \mathbb{R}^{T \times 7 \times 7 \times 1024} F5b∈RT×7×7×1024 通过以下方式生成全局外观特征 F F F:
F = A v g − pool ( Con v ( v s T F 5 b , W t ) ) F=A v g_{-} \operatorname{pool}\left(\operatorname{Con} v\left(v_{s}^{T} F_{5 b}, W_{t}\right)\right) F=Avg−pool(Conv(vsTF5b,Wt))
2.4 姿态感知RNN模块(Pose-Aware,PA)
PA模块负责对TMP模块和SA模块提取的姿态流和外观流之间的关系进行建模。下图展示了模型再时间步 t t t 时的姿态感知外观注意力选择过程。
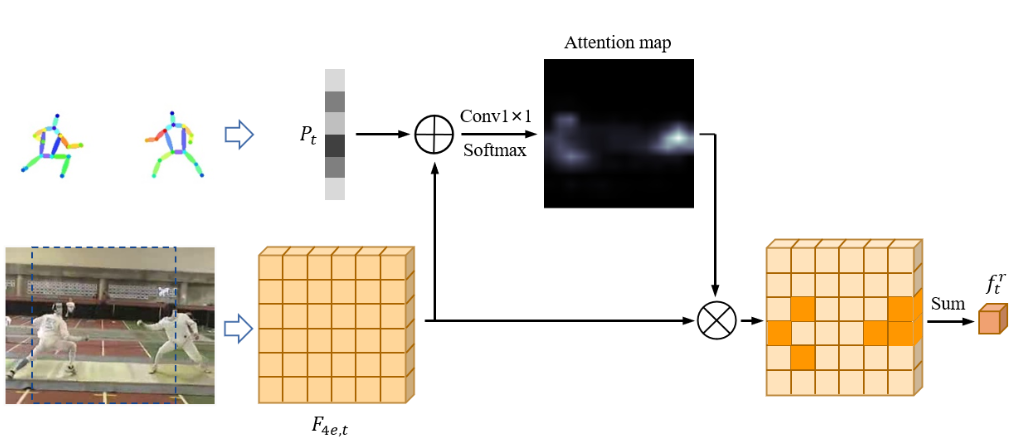
其中姿势融合向量 P t P_t Pt 用来引导SA模块中的中级特征图 F 4 e , t F_{4e,t} F4e,t。其中的 1 × 1 卷积用来生成单通道注意力图,然后通过 softmax 操作对其进行归一化。因此,PA模块可以通过对 F 4 e , t F_{4e,t} F4e,t的元素进行注意力加权求和来获得局部外观特征 f t r f_{t}^{r} ftr,最后通过构建关系RNN层来对局部特征序列 F r = ( f 1 r , ⋯ , f T r ) F_{r}=\left(f_{1}^{r}, \cdots, f_{T}^{r}\right) Fr=(f1r,⋯,fTr) 进行时序演化处理,整个过程可以概括为:
f t r = Attention r ( P t , F 4 e , t ) h ~ t r , S t r = T A − L S T M ( f t r , S t − 1 r ) \begin{aligned} f_{t}^{r} & =\text { Attention }_{r}\left(P_{t}, F_{4 e, t}\right) \\ \tilde{h}_{t}^{r}, S_{t}^{r} & =T A-L S T M\left(f_{t}^{r}, S_{t-1}^{r}\right) \end{aligned} ftrh~tr,Str= Attention r(Pt,F4e,t)=TA−LSTM(ftr,St−1r)
3.实验效果
本文的实验在7个标准的行为识别数据集上进行,其中包括 KTH、Penn-Action、UCF11三种姿势完整数据集,还包括 UCF101、HMDB51 和 JHMDB 三个姿势不完整数据集,以及具有深度骨架信息的 NTU-RGBD 数据集。
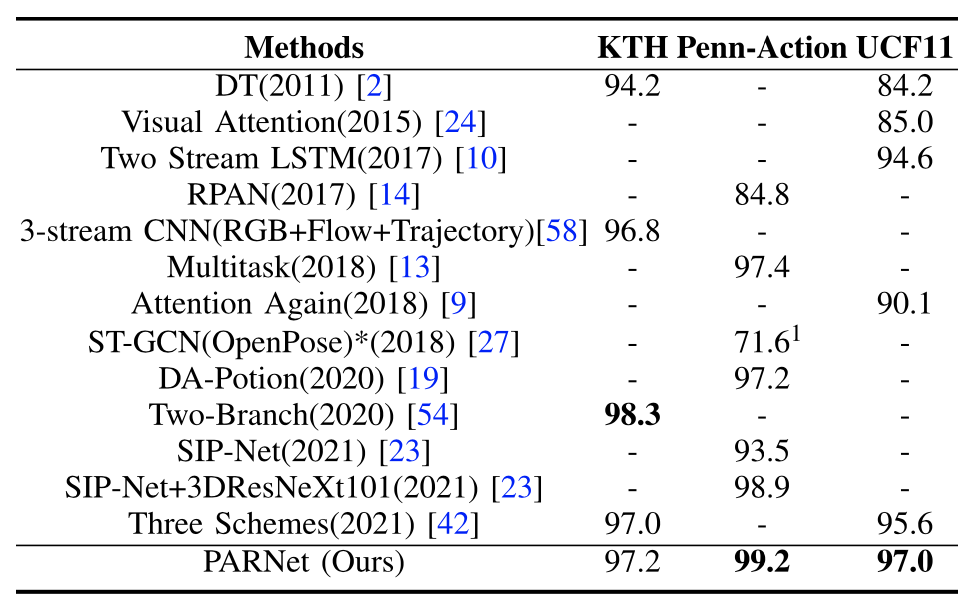
下表展示了本文PARNet在三个姿态完整数据集上的性能对比结果,可以看到,与其他方法相比,PARNet获得了较高的识别准确率。
此外作者对“挥棒球棍”动作进行了可视化分析,从采样视频中选取了6个具有代表性的帧,其中上部分的帧表示了PARNet的多姿态注意力选择过程,下部分的帧展示了具体姿态部分的注意力强度。

4.总结
本文提出了一种姿势外观关系联合建模网络PARNet,用来进行鲁棒的现实场景的行为识别。PARNet同时受益于视频中人体的姿态信息和外观动作信息,并且通过关系建模机制,完成了姿态流和外观流的相互补充。因此,PARNet 对正在进行的动作有较为全面的理解,这显着减少了对视频中特定视觉上下文或动态姿势的识别偏差。此外,作者在7个数据集上进行的广泛实验证明了本文方法的有效性。
参考
[1] Z. Cao, T. Simon, S.-E. Wei, and Y. Sheikh, “Realtime multi-person 2D pose estimation using part affinity fields,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 7291–7299.
[2] S. Ioffe and C. Szegedy, “Batch normalization: Accelerating deep network training by reducing internal covariate shift,” in Proc. Int. Conf. Mach. Learn., Jul. 2015, pp. 448–456.

















 111
111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









