










1. 需求创造好的产品,产品拓宽原始的需求
当前的深度神经网络一般都需要固定的输入图像尺寸(如224*224). 这种需求很明显是人为的,潜在性的弊端会降低识别精度(为了使图像尺寸相同,一定会涉及到图像的比例/非比例放缩,这就引入了尺度误差和形变误差)。何凯明师兄的这项工作主要是讲多分辨率搜索的思想融入到了现有的深度网络中,从而实现了多尺度网络的训练以及识别,进而提升了图像分类和目标检测的精度(核心思想在于生成固定长度Descriptor)。SPP(Spatial Pyramid Pooling,空间金字塔池化)是一种非常有效的多分辨策略,对目标形变非常鲁邦。
2. 从目标检测RCNN入手
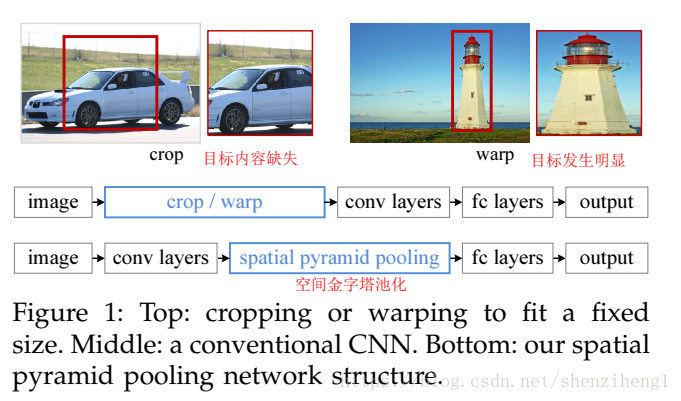
RCNN(Region proposal with Convoluton Neural Network,RCNN)进行目标检测的思路:CNN作为特征提取器,然后进行BoundingBox回归。但是RCNN对于每一个区域候选(Region Proposed)都需要首先将图片放缩(比例/非比例)到固定的尺寸(224*224),然后为每个区域候选提取CNN特征。整个过程是存在一些性能瓶颈:
- 速度瓶颈:重复为每个region proposal提取特征是极其费时的,Selective Search对于每幅图片产生2K左右个region proposal,也就是意味着一幅图片需要经过2K次的完整的CNN计算得到最终的结果。
- 性能瓶颈:对于所有的region proposal防缩到固定的尺寸会导致我们不期望看到的几何形变,而且由于速度瓶颈的存在,不可能采用多尺度或者是大量的数据增强去训练模型。
这里面实际到一个核心问题:大多数基于CNN的分类检测网络为什么需要固定的Descriptor输入呢?
CNN网络可以分解为卷积网络部分以及全连接网络部分。卷积网络的参数主要是卷积核,完全能够适用任意大小的输入,并且能够产生任意大小的输出。但是全连接层网络不同,全连接层部分的参数是神经元对于所有输入的连接权重,也就是说输入尺寸不固定的话,全连接层参数的个数都不能固定。
SPPNet给出的解决方案是,既然只有全连接层需要固定的输入,那么我们在全连接层前加入一个网络层,让他对任意的输入产生固定的输出不就好了吗?一种常见的想法是对于最后一层卷积层的输出pooling一下,但是这个pooling窗口(slide window)的尺寸及步伐(stride)设置为相对值,也就是特征图相对于期望输出固定Descriptor的一个比例值,这样对于任意输入经过这层后都能得到一个固定的输出。SPPnet在这个想法上继续加入SPM的思路,SPM其实在传统的机器学习特征提取中很常用,主要思路就是对于一副图像分成若干尺度的一些块,比如一幅图像分成1份,4份,8份等。然后对于每一块提取特征然后融合在一起,这样就可以兼容多个尺度的特征(所以从本质上讲,这种创新还是源于传统的机器学习:尺度金字塔+特征融合)。SPPNet首次将这种思想应用在CNN中,对于卷积层特征我们首先对他分成不同的尺寸,然后每个尺寸提取一个固定维度的特征,最后拼接这些特征成一个固定维度。上面这个图可以看出SPPnet和RCNN的区别,首先是输入不需要放缩到指定大小。其次是增加了一个空间金字塔池化层,还有最重要的一点是每幅图片只需要提取一次特征。
SPPnet虽然解决了CNN输入任意大小图片的问题,但是还是需要重复为每个region proposal提取特征啊,能不能我们直接根据region proposal定位到他在卷积层特征的位置,然后直接对于这部分特征处理呢?答案是肯定的。
3.SPPNet的网络细节

通过可视化Conv5层特征,发现卷积特征其实保存了空间位置信息(数学推理中更容易发现这点),并且每一个卷积核负责提取不同的特征,比如C图175、55卷积核的特征,其中175负责提取窗口特征,55负责提取圆形的类似于车轮的特征。其实我们也可以通过传统的方法聚集这些特征,例如词袋模型或是空间金字塔的方法。
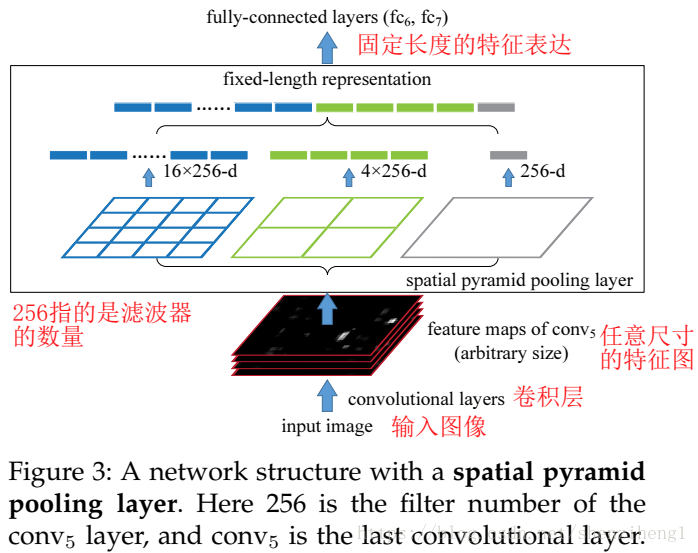
4.关于空间金字塔池化层SPP
空间金字塔池化层是SPPNet的核心,其主要目的是对于任意尺寸的输入产生固定大小的输出。思路是对于任意大小的feature map首先分成16、4、1个块,然后在每个块上最大池化,池化后的特征拼接得到一个固定维度的输出。以满足全连接层的需要。在研究图像分类的时候可以这么干(输入的图像为一整副图像),然而在研究目标检测和跟踪的时候,我们实际输入的应该是region proposal。
SPPNet理论上可以改进任何CNN网络,通过空间金字塔池化,使得CNN的特征不再是单一尺度的。但是SPPNet更适用于处理目标检测问题,首先是网络可以介绍任意大小的输入,也就是说能够很方便地多尺寸训练。其次是空间金字塔池化能够对于任意大小的输入产生固定的输出,这样使得一幅图片的多个region proposal提取一次特征成为可能。
SPPNet的做法是:
1. 首先通过selective search产生一系列的region proposal
2. 然后训练多尺寸识别网络用以提取区域特征,其中处理方法是每个尺寸的最短边大小在尺寸集合中:
![]()
训练的时候通过上面提到的多尺寸训练方法,也就是在每个epoch中首先训练一个尺寸产生一个model,然后加载这个model并训练第二个尺寸,直到训练完所有的尺寸。空间金字塔池化使用的尺度为:1*1,2*2,3*3,6*6,一共是50个bins。
3. 在测试时,每个region proposal选择能使其包含的像素个数最接近224*224的尺寸,提取相应特征。
由于我们的空间金字塔池化可以接受任意大小的输入,因此对于每个region proposal将其映射到feature map上,然后仅对这一块feature map进行空间金字塔池化就可以得到固定维度的特征用以训练CNN了。
4. 训练SVM,BoundingBox回归
5. 该方法的不足之处
和RCNN一样,SPP也需要训练CNN提取特征,然后训练SVM分类这些特征。需要巨大的存储空间,并且分开训练也很复杂。而且selective search的方法提取特征是在CPU上进行的,相对于GPU来说还是比较慢的。Fast RCNN以及Faster RCNN对这个两个问题进行了深入的研究,取得了不错的效果。
6. 参考文献
[1] 论文:He K, Zhang X, Ren S, et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[C]. european conference on computer vision, 2014: 346-361.
[2] 文章:https://zhuanlan.zhihu.com/p/34357444
[3] 源码:http://research.microsoft.com/en-us/um/people/kahe/














 2573
2573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









