







英文是纯手打的!论文原文的summarizing and paraphrasing。可能会出现难以避免的拼写错误和语法错误,若有发现欢迎评论指正!文章偏向于笔记,谨慎食用
1. 省流版
1.1. 心得
(1)没有心得是最好的心得,所以一阶近似就是和GCN一样嘛。不提供代码说个der
1.2. 论文总结图

2. 论文逐段精读
2.1. Abstract
①HCNN aims at representing high order relationships between data
②Applicable to multi-modal data and performs excellently
2.2. Introduction
①Hypergraph structure in social media:

②Comparison between graph and hypergraph:

2.3. Related Work
2.3.1. Hypergraph learning
①The transductive inference on hypergraph focuses on minimizing the difference between strong connected nodes(有个小问题就是现在如果超图本来就是基于相关性强才构建的...可能那些节点本身就很相似了)
2.3.2. Neural networks on graph
①Introducing related works on spectral and spatial domain
2.4. Hypergraph Neural Networks
2.4.1. Hypergraph learning statement
①They define a hypergraph as , where
is a diagonal matrix that each element denotes a weight of hyper edge
②The incidence matrix can be constructed by:
这里Incidence matrix应该都是不带权的,计算边缘度和顶点度直接加个数就行
③Denoting and
combined with the diagonal
and
respectively
④The vertex label should be smooth (regularized):
where denotes the supervised empirical loss,
denotes the rigularize, and
denotes the classification function
⑤The can be calculated by:
⑥ and
⑦所以可以把写成!!!??:
我没去推诶。
where is positive semi-definite, and usually called the hypergraph Laplacian
2.4.2. Spectral convolution on hypergraph
①Updating the hypergraph:
②Eigen decomposition: where
contains the eigen vectors and
contains eigen values
③Changing the original singal to
, where
is the Fourier base
④Spectral convolution with filer :
where is Fourier coefficients
⑤They use 1 order approximate by Chebyshev of Fourier, then update convolution:
where and
are parameters of filters
⑥They transform them to(这参数可以纯自己设计的啊?):
⑦The convolution will be:
(作者说最开始就是
那还要每一层都加个
啊?感觉最开始加一下就可以了后面再加会不会自环环多了啊。噢,第一层是为了和
叠起来把1/2系数消了是吧)
Thus the final convolution function can be:
where and
2.4.3. Hypergraph neural networks analysis
①Process of HGNN:

②Convolution layer:
([v,f2]=[v,v]×[v,e]×[e,e]×[e,e]×[e,v]×[v,v]×[v,f]×[f,f2])
where denotes the nonlinear activation function
③The details of convolution:

2.4.4. Implementation
①Hypergraph construction: They construct the hypergraph by defining the most similar vertex. For each node, they find nearest neighbors, which means each hyperedge connects
node. And there is finally
nodes and
hyperedges,
②Model for node classification: their classifier is Softmax
2.5. Experiments
2.5.1. Citation network classification
(1)Datasets
①Introducing citation network and visual object datasets
②Details of datasets:
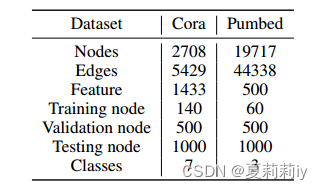
(2)Experimental settings
①Conv layers: 2
②Hidden layer: 16
③Dropout rate: 0.5
④Activation function: ReLU
⑤Optimizer: Adam
⑥Learning rate: 0.001
(3)Results and discussion
①Their results come from the average from 100 runs
②Comparison table:

2.5.2. Visual object classification
(1)Datasets and experimental settings
①Introducing each dataset
②Constructed dataset:
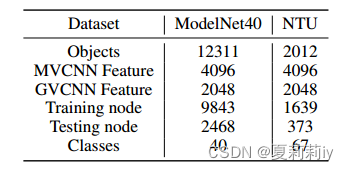
(2)Hypergraph structure construction on visual datasets
①Hypergraph construction and ⭐multi-modal hypergraph construction:

②⭐For multi-modal hypergraph, they generate different for different modality, then concatenate all of them.
(3)Results and discussions
①Comparison table on ModelNet40 dataset:

②Comparison table on NTU dataset:

③Comparison table on ModelNet40:

2.6. Conclusion
①The HGNN is more general
3. Reference List
Feng, Y. et al. (2019) 'Hypergraph Neural Networks', AAAI. doi: http://10.1609/aaai.v33i01.33013558















 2545
2545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









