










1.简介
在机器人领域,构建通用模型面临的最大挑战之一是“异构性”问题,即需要为每个机器人、任务和环境收集特定的数据,而学习到的策略往往无法泛化到这些特定设置之外。
为了解决这一难题,由AI领域的领军人物何恺明带领的MIT和Meta FAIR团队提出了一种名为异构预训练Transformer(HPT)的模型。HPT通过预训练一个大型、可共享的神经网络主干来学习与任务和机器人形态无关的共享表示,这意味着可以在策略模型中集成一个可扩展的Transformer,从而避免了从头开始训练的需要。
这项创新研究已被NeurIPS 2024接收为Spotlight。在真实环境中,搭载HPT的机器人能够自主执行复杂任务,如向柴犬投食,甚至在狗粮洒落一地时,也能用抹布将其收拾干净。在模拟环境中,HPT架构进一步提升了机器人任务操作的精准度。
通过利用大规模多硬件真实世界机器人数据集以及模拟数据,HPT在多个模拟器基准测试和现实世界设置中的表现超过了多个基线,并在未见任务上提升了超过20%的微调策略性能。这项工作不仅展示了在机器人学习中处理异构数据的潜力,还通过开源代码和权重,为未来的研究提供了一个有价值的资源。

代码地址:GitHub - liruiw/HPT: Heterogeneous Pre-trained Transformer (HPT) as Scalable Policy Learner.
权重地址:https://huggingface.co/liruiw/hpt-base
论文地址:https://arxiv.org/abs/2409.20537
项目地址:Scaling Proprioceptive-Visual Learning with Heterogeneous Pre-trained Transformer
演示视频(没有版权,请自行跳转查看):
https://liruiw.github.io/hpt/media/figures/hpt_new.mp4(真实机器人)
https://liruiw.github.io/hpt/media/figures/sim_video.mp4(仿真实验)
2.论文详解
什么是异构性:不同的机器人是硬件在不同环境下的不同物理体现。每个实施例都可以包括不同的自由度、末端执行器、运动控制器和为特定应用构建的工作空间配置。机器人中另一个常见的异质性是视觉异质性。机器人通常配备不同的摄像头传感器,安装在不同的地方(例如手腕和/或第三人称),每个机器人的视觉外观因环境和任务而有很大差异。
这篇文章想解决什么问题:大规模机器人数据中存在的异质性(如不同的机器人硬件和不同的环境)构成了重大挑战。目前该领域的一个核心问题是如何利用异构机器人数据来预训练机器人基础模型。
模型架构
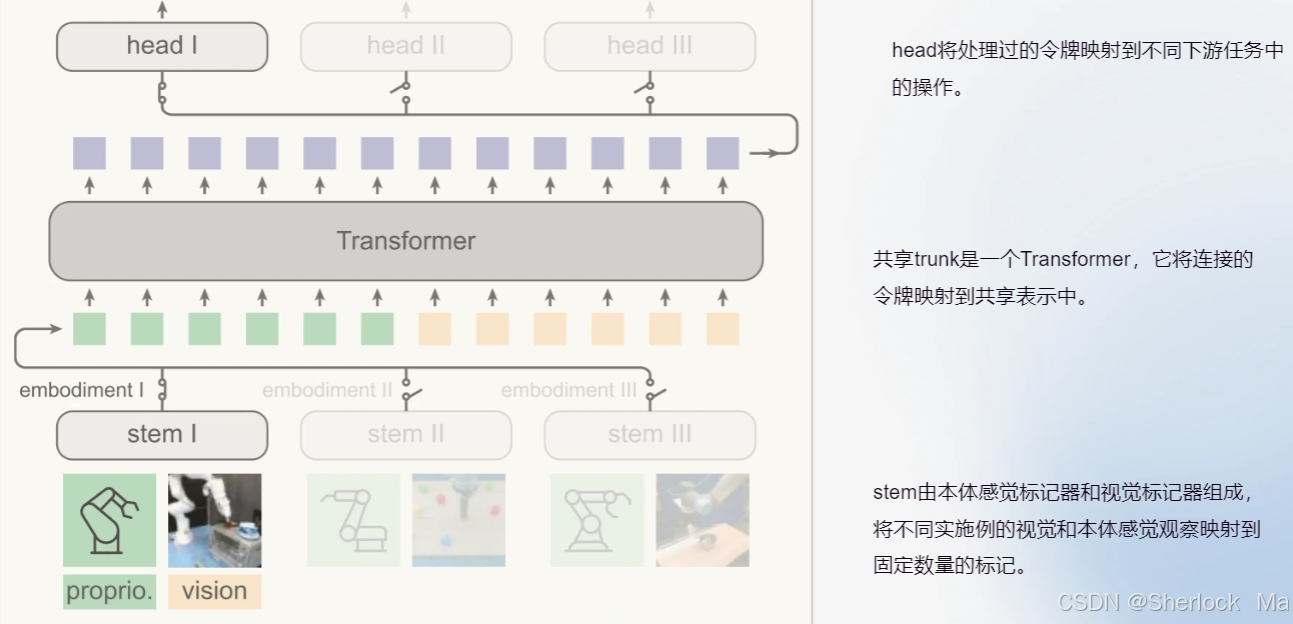
HPT被模块化为stem、trunk和head。
- stem:由proprioception tokenizer和vision tokenizer组成的stem将不同实施例的视觉信息和本体感官信息映射到固定数量(例如16个)的token,即映射到transformer的理解空间。
- trunk:共享trunk是一个Transformer,它将来自stem输入的token进行处理。
- head:head将处理过的token映射到不同下游任务中的动作。
对于一个具体实施例,一个stem/head对被激活(用开关表示)。trunk是共享的,并利用监督学习在动作标记的数据上被预训练,然后被转移到新的实施例。该程序最多可扩展到52个数据集和1B个参数。
stem训练
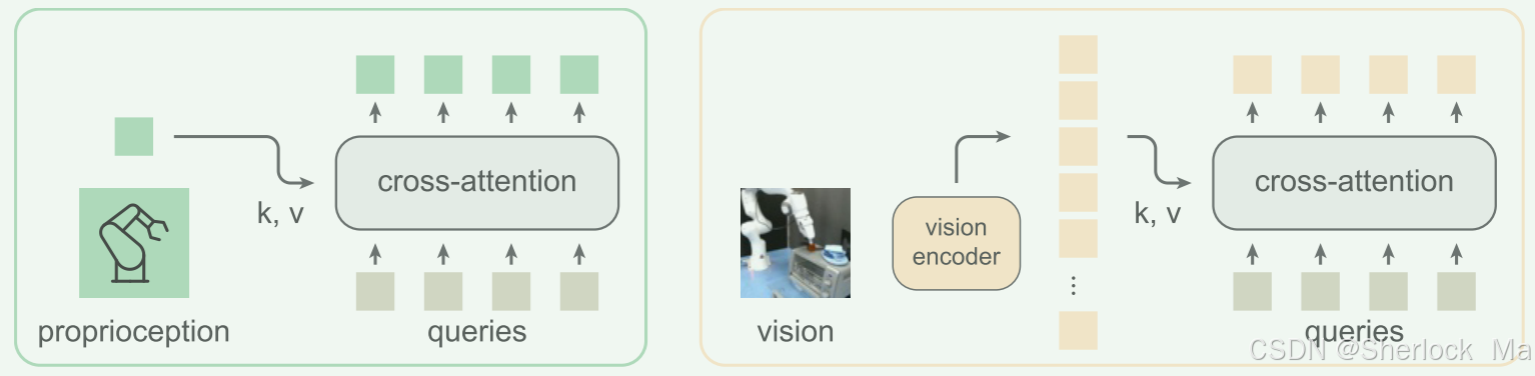
在HPT stem中
- proprioceptive tokenizer使用MLP将本体感受信息映射到一个token,然后由16个可学习的query进行cross-attention运算,得到新的16个token。
- vision tokenizer使用预先训练的编码器,并类似地使用注意力机制将视觉特征映射到16个固定token中。
总的来说,该架构可以灵活地处理输入序列,而不增加token的大小。
损失函数
行为克隆损失(Behavior Cloning Loss),它用于在HPT(Heterogeneous Pre-trained Transformers)模型的预训练阶段指导模型学习。行为克隆是一种监督学习方法,通过最小化模型预测动作和真实动作之间的差异来训练模型。具体来说,损失函数定义如下:
在这个公式中:
- θ 表示模型参数,包括特定于数据集 k 的 stem 和 head 参数,以及所有数据集共享的 trunk 参数。
- K 是数据集的总数。
- L 是损失函数,用于计算模型输出和真实动作之间的差异。
是第 k 个数据集,包含一系列的轨迹,每个轨迹由观测和动作对组成。
损失函数 LL 通常采用Huber损失(Huber Loss),这是一种结合了L1损失和L2损失的特点,对异常值具有鲁棒性。Huber损失定义如下:
其中:
- x 是模型预测的动作。
是真实动作。
- δ 是一个预设的阈值,用于平衡平方损失和绝对损失。
通过最小化这个损失函数,HPT模型能够学习如何根据输入的观测数据(包括视觉和本体感知信息)预测出正确的动作。这种方法使得模型能够在多种不同的机器人硬件和任务中泛化,从而提高了模型的适用性和灵活性。
论文剩余的部分,包括实验等等内容就不多介绍了,感兴趣的同学请自行查看。
3.代码详解
环境配置
运行下面的命令安装
pip install -e .安装旧版本的Mujoco,这个库安装起来实在费劲,不知道他们为什么要使用旧版本的库。
mkdir ~/.mujoco
cd ~/.mujoco
wget https://mujoco.org/download/mujoco210-linux-x86_64.tar.gz -O mujoco210.tar.gz --no-check-certificate
tar -xvzf mujoco210.tar.gz
# add the following line to ~/.bashrc if needed
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:${HOME}/.mujoco/mujoco210/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib/nvidia
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/lib64
export MUJOCO_GL=egl权重(请自行选择适当的权重,我这里以base为例):https://huggingface.co/liruiw
文件结构:
├── ...
├── HPT
| ├── data # cached datasets
| ├── output # trained models and figures
| ├── env # environment wrappers
| ├── hpt # model training and dataset source code
| | ├── models # network models
| | ├── datasets # dataset related
| | ├── run # transfer learning main loop
| | ├── run_eval # evaluation main loop
| | └── ...
| ├── experiments # training configs
| | ├── configs # modular configs
└── ...训练
run.py
使用hpt/run.py进行训练
run.py里面包含两个函数,其中run()是训练的主函数,而init_policy 函数的主要功能是初始化策略模型并加载预训练模型(如果存在)。
init_policy的主要步骤如下,就不把代码放上来了:
- 检查预训练模型是否存在:
- 如果存在本地预训练模型,则加载配置文件并实例化策略模型。
- 如果预训练模型路径包含 "hf",则从云中加载预训练模型。
- 如果没有预训练模型,则从头开始训练。
- 更新网络维度:根据数据集和策略模型更新网络的输入和输出维度。
- 初始化领域特定部分:
- 初始化领域特定的 stem 和 head。
- 加载数据集的归一化器并初始化 head。
- 添加编码器:
- 如果配置中指定了微调编码器,则初始化图像编码器。
- 完成模块初始化:
- 如果存在预训练模型,加载 trunk 部分;如果配置中指定了冻结 trunk,则冻结 trunk 部分。
- 打印模型统计信息:打印模型的统计信息并将模型移动到指定设备。
run()的主要步骤如下:
- 初始化运行:配置Wandb实验跟踪,设置随机种子。
- 设置数据集:创建训练和验证数据集的DataLoader。
- 初始化策略:根据配置加载预训练模型或从头开始训练。
- 优化器和学习率调度器:配置优化器和学习率调度器。
- 杂项设置:保存配置,计算参数数量,设置模型保存路径。
- 训练和测试循环:进行训练和周期性的测试,记录训练和测试损失,保存模型。
- 结束日志:关闭进度条和Wandb实验。
@hydra.main(config_path="../experiments/configs", config_name="config", version_base="1.2")
def run(cfg):
# initialize run
date = cfg.output_dir.split("/")[1]
run = wandb.init( # Wandb初始化
project="hpt-transfer",
tags=[cfg.wb_tag],
name=f"{date}_{cfg.script_name}",
config=OmegaConf.to_container(cfg, resolve=True),
reinit=False,
save_code=False,
resume="allow",
)
utils.set_seed(cfg.seed)
print(f"train policy models with pretrained: { cfg.train.pretrained_dir}!")
print("wandb url:", wandb.run.get_url())
# setup dataset
device = "cuda"
domain_list = [d.strip() for d in cfg.domains.split(",")] # 解析领域列表,选择第一个领域。
domain = domain_list[0]
dataset = hydra.utils.instantiate( # 创建训练和测试的DataLoader。
cfg.dataset, dataset_name=domain, env_rollout_fn=cfg.dataset_generator_func, **cfg.dataset
)
val_dataset = dataset.get_validation_dataset()
train_loader = data.DataLoader(dataset, **cfg.dataloader)
test_loader = data.DataLoader(val_dataset, **cfg.val_dataloader)
# init policy 根据配置加载预训练模型或从头开始训练
policy = init_policy(cfg, dataset, domain, device)
# optimizer and scheduler
opt = utils.get_optimizer(cfg.optimizer, policy, cfg.optimizer_misc)
cfg.lr_scheduler.T_max = int(cfg.train.total_iters)
sch = utils.get_scheduler(cfg.lr_scheduler, optimizer=opt)
sch = WarmupLR(sch, init_lr=0, num_warmup=cfg.warmup_lr.step, warmup_strategy="linear")
# misc
utils.save_args_hydra(cfg.output_dir, cfg) # 保存配置到指定路径
epoch_size = len(train_loader)
n_parameters = sum(p.numel() for p in policy.parameters() if p.requires_grad)
cfg.total_num_traj = dataset.replay_buffer.n_episodes
policy_path = os.path.join(cfg.output_dir, "model.pth")
print(f"Epoch size: {epoch_size} Traj: {cfg.total_num_traj} Train: {len(dataset)} Test: {len(val_dataset)}")
# train / test loop
pbar = trange(MAX_EPOCHS, position=0) # 使用tqdm创建进度条。
for epoch in pbar:
train_stats = train_test.train(cfg.log_interval, policy, device, train_loader, opt, sch, epoch)
train_steps = (epoch + 1) * len(train_loader)
if epoch % TEST_FREQ == 0:
test_loss = train_test.test(policy, device, test_loader, epoch)
wandb.log({"validate/epoch": epoch, f"validate/{domain}_test_loss": test_loss})
if "loss" in train_stats:
print(f"Steps: {train_steps}. Train loss: {train_stats['loss']:.4f}. Test loss: {test_loss:.4f}")
policy.save(policy_path)
if train_steps > cfg.train.total_iters:
break
# log and finish
print("model saved to :", policy_path)
utils.save_args_hydra(cfg.output_dir, cfg)
pbar.close()
run.finish()
wandb.finish()train_test.py
这里面主要的函数是train()和test(),分别是训练和评估的主函数。
我们先来看train(),它的主要步骤如下:
- 初始化:设置模型为训练模式,记录开始时间,获取数据加载器的大小,并创建进度条。
- 数据处理:遍历数据加载器,将数据移动到指定设备并转换为浮点类型。
- 前向传播:计算损失值。
- 反向传播:清零梯度,计算梯度,更新模型参数,并调整学习率。
- 日志记录:记录训练步骤、时间、损失值等统计信息,并更新进度条显示。
- 返回结果:返回包含平均统计信息的字典。
def train(
log_interval, model, device, train_loader, optimizer, scheduler, epoch, log_name="train",
):
model.train()
start_time = time.time()
epoch_size = len(train_loader)
pbar = tqdm(train_loader, position=1, leave=True)
# randomly sample a dataloader with inverse probability square root to the number of data
for batch_idx, batch in enumerate(pbar):
batch["data"] = dict_apply(batch["data"], lambda x: x.to(device, non_blocking=True).float()) # 将数据移动到指定设备并转换为浮点类型。
data_time = time.time() - start_time
start_time = time.time()
domain_loss = model.compute_loss(batch) # 计算损失值
optimizer.zero_grad()
domain_loss.backward()
optimizer.step()
scheduler.step()
train_step = len(train_loader) * epoch + batch_idx
step_time = time.time() - start_time
start_time = time.time()
log_stat(info_log, train_step, log_interval, log_name, batch["domain"][0],
domain_loss, model, optimizer, step_time, data_time, epoch) # 记录统计信息
pbar.set_description( # 更新进度条显示
f"Epoch: {epoch} {train_step} Step: {batch_idx}/{epoch_size} Time: {step_time:.3f}"
f"{data_time:.3f} Loss: {info_log[batch['domain'][0] + '_loss'][-1]:.3f} Grad: {info_log['max_gradient'][-1]:.3f}"
)
return {k: np.mean(v) for k, v in info_log.items() if len(v) > 1} # 返回包含平均统计信息的字典。接着是test(),它的主要步骤如下:
- 初始化:设置模型为评估模式,初始化测试损失和样本数。
- 进度条:使用 tqdm 创建一个进度条来显示测试过程。
- 数据处理:对每个批次的数据进行设备迁移和类型转换。
- 计算损失:调用模型的 compute_loss 方法计算损失。
- 日志记录:更新测试损失和样本数,并在进度条中显示当前的损失值。
- 返回结果:返回平均测试损失。
@torch.no_grad()
def test(model, device, test_loader, epoch):
"""
Evaluate imitation losses on the test sets.
Args:
model (torch.nn.Module): The model to be evaluated.
device (torch.device): The device to run the evaluation on.
test_loader (torch.utils.data.DataLoader): The data loader for the test set.
epoch (int): The current epoch number.
Returns:
float: The average test loss.
"""
model.eval()
test_loss, num_examples = 0, 0
pbar = tqdm(test_loader, position=2, leave=False) # 初始化测试损失和样本数
for batch_idx, batch in enumerate(pbar):
batch["data"] = dict_apply(batch["data"], lambda x: x.to(device, non_blocking=True).float())
loss = model.compute_loss(batch) # 计算损失
# logging
test_loss += loss.item() # 更新测试损失和样本数
num_examples += 1
pbar.set_description( # 更新进度
f"Test Epoch: {epoch} Step: {batch_idx} Domain: {batch['domain'][0]} Loss: {test_loss / (num_examples + 1):.3f}"
)
return test_loss / (num_examples + 1)policy.py
train()和test()函数都会进入policy.py来计算损失,下面是相关代码
这段代码定义了Policy类中的compute_loss方法,用于计算训练过程中前向传播的损失。
- 设置训练模式:将self.train_mode设置为True,表示模型处于训练模式。
- 提取数据:从batch中提取domain和data。
- 前向特征提取:调用self.forward_features方法,传入domain和data,获取特征 features。
- 归一化标签:如果domain在self.normalizer中存在,则对data["action"]进行归一化处理。
- 计算损失:调用self.heads[domain].compute_loss方法,传入features和data,计算并返回损失值loss。
def compute_loss(self, batch):
"""Compute the loss for the training loop forward pass.
"""
self.train_mode = True
domain, data = batch["domain"][0], batch["data"]
features = self.forward_features(domain, data) # 调用 self.forward_features 方法,传入 domain 和 data,获取特征 features。
# normalize the labels
if domain in self.normalizer: # 如果 domain 在 self.normalizer 中存在,则对 data["action"] 进行归一化处理。
data["action"] = self.normalizer[domain]["action"].normalize(data["action"])
# head pass
loss = self.heads[domain].compute_loss(features, data)
return loss而上述代码调用的compute_loss()在policy_head.py里面的PolicyHead类进行定义。
def compute_loss(self, x: torch.Tensor, data: dict):
self.target_action = data["action"] # 从输入数据 data 中提取目标动作 target_action 并存储在 self.target_action 中。
self.pred_action = self(x).view(self.target_action.shape) # 通过调用当前对象的前向传播方法 self(x) 生成预测动作,并将其形状调整为目标动作的形状
return LOSS(self.pred_action, self.target_action) # l1_loss这段代码定义了一个 compute_loss 方法,用于计算预测动作与目标动作之间的损失。具体步骤如下:
- 获取目标动作:从输入数据 data 中提取目标动作 target_action。
- 生成预测动作:通过调用当前对象的前向传播方法 self(x) 生成预测动作,并将其形状调整为目标动作的形状。
- 计算损失:使用预定义的损失函数 LOSS 计算预测动作与目标动作之间的损失,并返回该损失值。
模型结构
stem
PolicyStem()定义了模型的stem部分,其中:
- init_cross_attn()初始化了可学习的Query(代码中的self.tokens)和cross_attention()
- compute_latent()是用于训练的部分,stem_feat是K和V,而stem_tokens是可学习的Q,通过transformer.py里面定义的CrossAttention.forward()计算
class PolicyStem(nn.Module):
"""policy stem"""
def __init__(self, **kwargs):
super().__init__()
def init_cross_attn(self, stem_spec, modality: str):
""" initialize cross attention module and the learnable tokens """
token_num = getattr(stem_spec.crossattn_latent, modality) # 获取令牌数量
self.tokens = nn.Parameter( # 可学习的Query:生成一个形状为 (1, token_num, stem_spec.modality_embed_dim) 的随机张量,并乘以 INIT_CONST,然后将其包装为 nn.Parameter
torch.randn(1, token_num, stem_spec.modality_embed_dim) * INIT_CONST
)
self.cross_attention = CrossAttention( # 初始化跨模态注意力机制,传入嵌入维度、注意力头数、每个头的维度和dropout概率
stem_spec.modality_embed_dim,
heads=stem_spec.crossattn_heads,
dim_head=stem_spec.crossattn_dim_head,
dropout=stem_spec.crossattn_modality_dropout,
)
...
def compute_latent(self, x: torch.Tensor) -> torch.Tensor:
stem_feat = self(x) # KV:将输入张量 x 通过模型的前向传播得到 stem_feat
stem_feat = stem_feat.reshape(stem_feat.shape[0], -1, stem_feat.shape[-1]) # (32, 147, 128) 将其重塑为 [batch_size, -1, feature_dim] 的形状。
# Replicating tokens for each item in the batch and computing cross-attention
stem_tokens = self.tokens.repeat(len(stem_feat), 1, 1) # Q:(32, 16, 128) 为每个批次中的项目复制令牌,并初始化 stem_tokens。
stem_tokens = self.cross_attention(stem_tokens, stem_feat) # (32, 16, 128) 使用交叉注意力机制更新 stem_tokens(Q)。
return stem_tokens在transformer.py里面定义的CrossAttention,其中forward()就是普通的交叉注意力,这里不多解释了。
class CrossAttention(nn.Module):
"""
CrossAttention module used in the Perceiver IO model.
Args:
query_dim (int): The dimension of the query input.
heads (int, optional): The number of attention heads. Defaults to 8.
dim_head (int, optional): The dimension of each attention head. Defaults to 64.
dropout (float, optional): The dropout probability. Defaults to 0.0.
"""
def __init__(self, query_dim: int, heads: int = 8, dim_head: int = 64, dropout: float = 0.0):
super().__init__()
inner_dim = dim_head * heads
context_dim = query_dim
self.scale = dim_head**-0.5
self.heads = heads
self.to_q = nn.Linear(query_dim, inner_dim, bias=False)
self.to_kv = nn.Linear(context_dim, inner_dim * 2, bias=False)
self.to_out = nn.Linear(inner_dim, query_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x: torch.Tensor, context: torch.Tensor,
mask: Optional[torch.Tensor] = None) -> torch.Tensor:
"""
Forward pass of the CrossAttention module.
Args:
x (torch.Tensor): The query input tensor.
context (torch.Tensor): The context input tensor.
mask (torch.Tensor, optional): The attention mask tensor. Defaults to None.
Returns:
torch.Tensor: The output tensor.
"""
h = self.heads
q = self.to_q(x)
k, v = self.to_kv(context).chunk(2, dim=-1)
q, k, v = map(lambda t: rearrange(t, "b n (h d) -> (b h) n d", h=h), (q, k, v)) # 重排 q, k, v 以适应多头注意力
sim = einsum("b i d, b j d -> b i j", q, k) * self.scale # 计算相似度矩阵 sim=QK
if mask is not None: # 应用掩码到 sim
# fill in the masks with negative values
mask = rearrange(mask, "b ... -> b (...)")
max_neg_value = -torch.finfo(sim.dtype).max
mask = repeat(mask, "b j -> (b h) () j", h=h)
sim.masked_fill_(~mask, max_neg_value)
# attention, what we cannot get enough of
attn = sim.softmax(dim=-1) # 计算注意力权重 attn
# dropout
attn = self.dropout(attn)
out = einsum("b i j, b j d -> b i d", attn, v) # softmax(QK) * V
out = rearrange(out, "(b h) n d -> b n (h d)", h=h) # 重新排列输出
return self.to_out(out)transformer
其定义在transformer.py里面的SimpleTransformer类,就是自己写了一个简易的transformer模型,这里不多解释了。
class SimpleTransformer(nn.Module):
def __init__(
self,
attn_target: Callable,
embed_dim: int,
num_blocks: int,
block: Callable = BlockWithMasking,
pre_transformer_layer: Optional[Callable] = None,
post_transformer_layer: Optional[Callable] = None,
drop_path_rate: float = 0.0,
drop_path_type: str = "progressive",
norm_layer: Callable = _LAYER_NORM,
mlp_ratio: int = 4,
ffn_dropout_rate: float = 0.0,
layer_scale_type: Optional[str] = None, # from cait; possible values are None, "per_channel", "scalar"
layer_scale_init_value: float = 1e-4, # from cait; float
weight_init_style: str = "pytorch", # possible values jax or pytorch
):
"""
Simple Transformer with the following features
1. Supports masked attention
2. Supports DropPath
3. Supports LayerScale
4. Supports Dropout in Attention and FFN
5. Makes few assumptions about the input except that it is a Tensor
"""
super().__init__()
self.pre_transformer_layer = pre_transformer_layer
if drop_path_type == "progressive": #如果 drop_path_type 是 "progressive",则计算渐进式的 DropPath 率。
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, num_blocks)]
elif drop_path_type == "uniform": # 如果 drop_path_type 是 "uniform",则设置均匀的 DropPath 率。
dpr = [drop_path_rate for i in range(num_blocks)]
else:
raise ValueError(f"Unknown drop_path_type: {drop_path_type}")
self.blocks = nn.Sequential( # 构建多个 Transformer 块
*[
block(
dim=embed_dim,
attn_target=attn_target,
mlp_ratio=mlp_ratio,
ffn_dropout_rate=ffn_dropout_rate,
drop_path=dpr[i],
norm_layer=norm_layer,
layer_scale_type=layer_scale_type,
layer_scale_init_value=layer_scale_init_value,
)
for i in range(num_blocks)
]
)
self.post_transformer_layer = post_transformer_layer # 设置后变换层
self.weight_init_style = weight_init_style # 权重初始化
self.apply(self._init_weights)
def forward(
self,
tokens: torch.Tensor,
attn_mask: torch.Tensor = None,
use_checkpoint: bool = False,
checkpoint_every_n: int = 1,
checkpoint_blk_ids: Optional[List[int]] = None,
):
"""
Inputs
- tokens: data of shape N x L x D (or L x N x D depending on the attention implementation)
- attn: mask of shape L x L
Output
- x: data of shape N x L x D (or L x N x D depending on the attention implementation)
"""
if self.pre_transformer_layer: # 如果有预处理层,对 tokens 进行预处理。
tokens = self.pre_transformer_layer(tokens)
if use_checkpoint and checkpoint_blk_ids is None:
checkpoint_blk_ids = [blk_id for blk_id in range(len(self.blocks)) if blk_id % checkpoint_every_n == 0]
if checkpoint_blk_ids:
checkpoint_blk_ids = set(checkpoint_blk_ids)
for blk_id, blk in enumerate(self.blocks):
if use_checkpoint and blk_id in checkpoint_blk_ids: # 如果启用检查点且当前块在 checkpoint_blk_ids 中,使用检查点进行前向传播;否则,直接前向传播。
tokens = checkpoint.checkpoint(blk, tokens, attn_mask, use_reentrant=False)
else:
tokens = blk(tokens, attn_mask=attn_mask)
if self.post_transformer_layer: # 如果有后处理层,对 tokens 进行后处理。
tokens = self.post_transformer_layer(tokens)
return tokens
def _init_weights(self, m): # 初始化模型中的权重
if isinstance(m, nn.Linear):
if self.weight_init_style == "jax":
# Based on MAE and official Jax ViT implementation
torch.nn.init.xavier_uniform_(m.weight)
elif self.weight_init_style == "pytorch":
# PyTorch ViT uses trunc_normal_
trunc_normal_(m.weight, std=0.02)
elif self.weight_init_style == "allzero":
# PyTorch ViT uses trunc_normal_
torch.nn.init.constant_(m.weight, 0)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, (nn.LayerNorm)):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)head
head的定义在policy_head.py,有很多种,这里只看一种。这个定义方式其实和stem差不多,都是使用可学习的Query+CrossAttention去学习。
class TransformerDecoder(PolicyHead):
def __init__(
self,
input_dim: int = 10,
output_dim: int = 10,
crossattn_modality_dropout: float = 0.1,
crossattn_heads: int = 8,
crossattn_dim_head: int = 64,
action_horizon: int = 4,
) -> None:
"""
Transformer decoder similar to ACT or Detr head.
This version uses cross attention and does not require retraining the trunk.
"""
super().__init__()
token_num = action_horizon
self.tokens = nn.Parameter(
torch.randn(1, token_num, output_dim) * INIT_CONST
)
self.cross_attention = CrossAttention(
input_dim,
heads=crossattn_heads,
dim_head=crossattn_dim_head,
dropout=crossattn_modality_dropout,
)
embed_dim = crossattn_dim_head * crossattn_heads
self.mlp = nn.Sequential(nn.Linear(input_dim, embed_dim), nn.SiLU(), nn.Linear(embed_dim, output_dim))
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
Args:
x: (B, token_len, input_dim)
"""
context = self.mlp(x)
context = context.reshape(context.shape[0], -1, context.shape[-1])
# Replicating tokens for each item in the batch and computing cross-attention
queries = self.tokens.repeat(len(context), 1, 1)
out = self.cross_attention(queries, context).view(len(x), -1) # 使用交叉注意力机制计算 queries 和 context 之间的关系,得到输出 out。
return out4.总结
在真实环境中,HPT加持下的机器人本体,能够自主向柴犬投食。

而且, 即便是洒了一地狗粮,机器人也能用抹布,将其收到一起。

在这篇博客中,我们探讨了机器人学习领域的一项突破性研究——异构预训练Transformer(HPT)模型。HPT模型由MIT和Meta FAIR的团队共同开发,旨在解决机器人学习中的一个核心挑战:异构性。传统的机器人学习模型往往需要针对特定的硬件、任务和环境收集大量数据,而HPT通过预训练一个大型、可共享的神经网络主干,学习与任务和机器人形态无关的共享表示。这种创新的方法允许模型在不同的机器人硬件和任务之间进行迁移和泛化,减少了对特定任务数据的依赖。HPT模型在真实世界和模拟环境中都展现出了卓越的性能,证明了其在机器人领域的广泛应用潜力。这项研究不仅推动了机器人技术的边界,也为未来机器人的智能化和自主化铺平了道路。
随着HPT模型的问世,机器人的学习和适应能力迈入了一个新时代。如果你对机器人技术、人工智能和自动化的未来充满好奇,那么请继续关注我们的博客。我们将深入探讨HPT模型的技术细节、应用案例和行业影响,以及它如何塑造我们的工作和生活。不要错过这个革命性技术的最新动态,让我们一起见证机器人如何变得更加智能和自主。订阅我们的博客,成为这个变革的一部分!
亲爱的读者,如果您对HPT模型的创新突破和它为视频交互带来的无限可能感到兴奋,那么请不要犹豫,动动手指,给我们一个关注和点赞吧!您的每一次互动都是我们继续探索和分享前沿技术动力的源泉。加入我们,一起见证人工智能技术如何塑造我们的数字世界,让每一次观看都成为一次全新的发现之旅。感谢您的支持,让我们共同期待更多令人激动的更新!

















 3903
3903

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









