







 超级会员免费看
超级会员免费看
Tokenizer
诸如GPT-3/4以及LlaMA/LlaMA2大语言模型都采用了token的作为模型的输入输出,其输入是文本,然后将文本转为token(正整数),然后从一串token(对应于文本)预测下一个token。
进入OpenAI官网提供的tokenizer可以看到GPT-3tokenizer采用的方法。这里以Hello World为例说明。
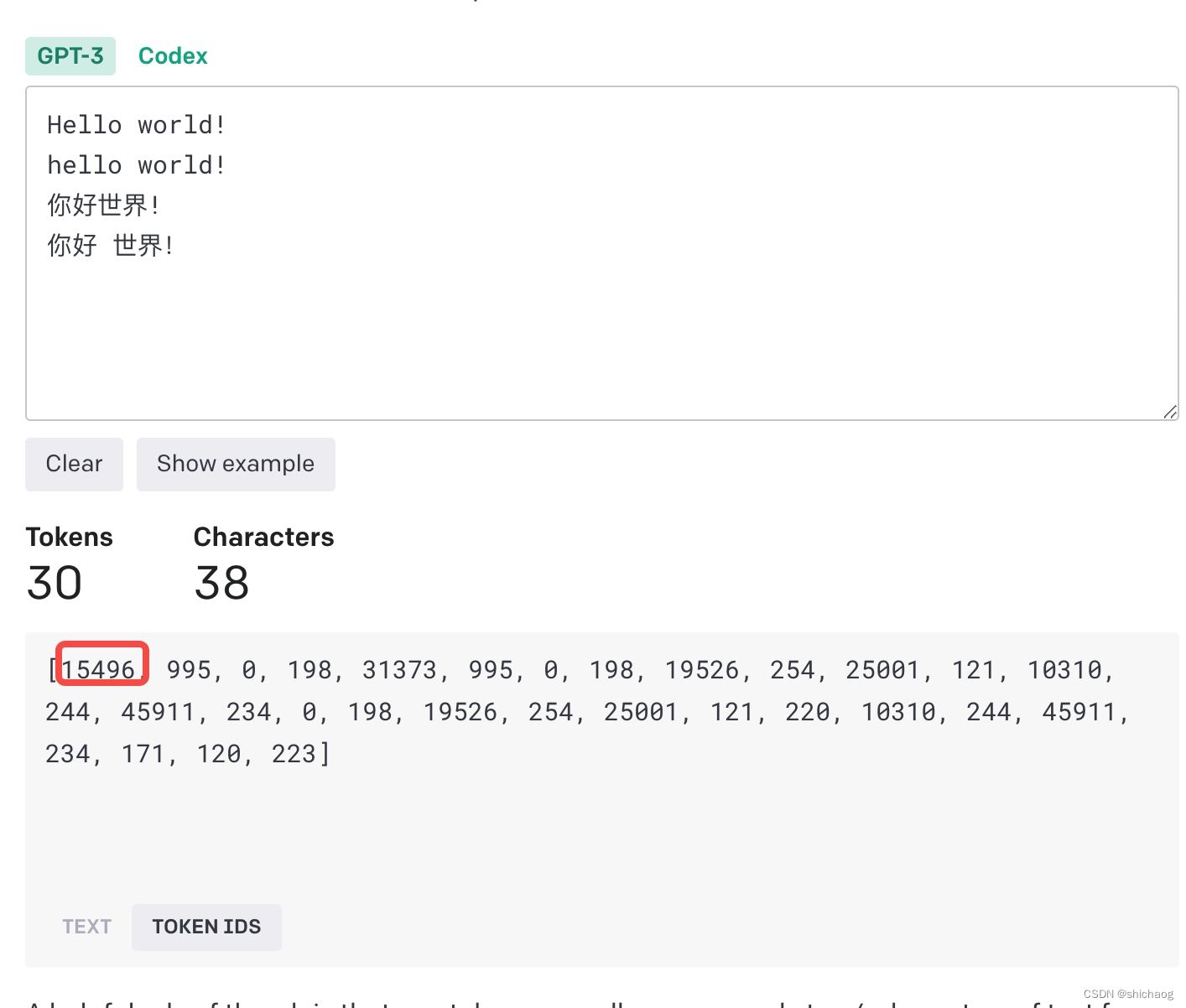
总共30个token,英文单词一般会用单独的token表示,大小写也会区分不同的token,如Hello和hello,另外有一些由空格前导的单词也会单独编码,这会使得编码整个句子效率更高(这将省去每个空格的编码),对于中文token化,会使用两到三个ID(正整数表示),比如上面的中英文的!。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1978
1978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











