




一、数据集初识
数据量: 共计16598条数据
数据来源:Video Games Sales
数据字段:
| 字段名 | 含义 |
|---|---|
| Rank | 游戏排名 |
| Name | 游戏名 |
| Platform | 发布平台 |
| Year | 发布年份 |
| Genre | 游戏种类 |
| Publisher | 发行商 |
| NA_Sales | 北美销售量(以million为单位) |
| EU_Sales | 欧洲销售量(以million为单位) |
| JP_Sales | 日本销售量(以million为单位) |
| Other_Sales | 其他地区销售量(以million为单位) |
| Global_Sales | 全球销售总量(以million为单位) |
二、数据读取与预处理
import pandas as pd
import os
import matplotlib.pyplot as plt
import numpy as np
os.chdir('C:/Users/dell/Desktop')
plt.style.use('ggplot') #使用ggplot风格
na_values=['N/A'] #缺失值类型为N/A
df=pd.read_csv('vgsales.csv',na_values=na_values)
df=df.dropna(how='any',axis=0)
三、描述性统计分析
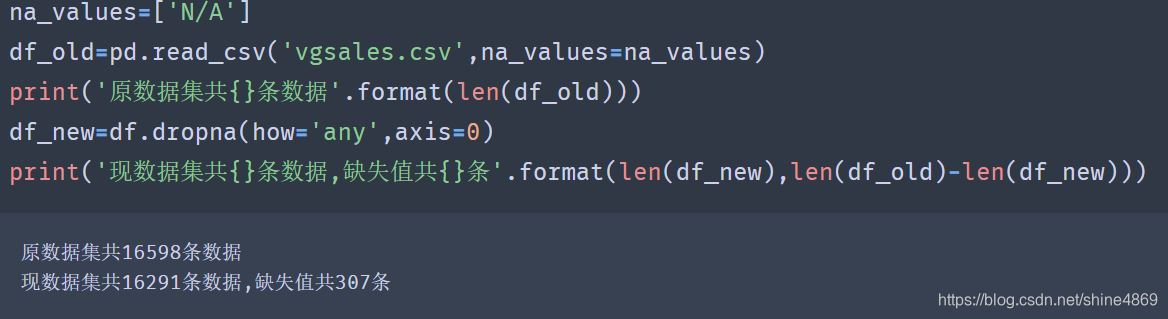
(1) 查看游戏类别、发布平台、发行商类别数
types=pd.DataFrame(df['Genre'].value_counts())
types.plot(kind='bar',alpha=0.6,color='Blue',figsize=(12,8),
legend=False,
title='The counts of all Genres')
a=np.arange(len(df)) #添加数据标签
for index,count in zip(a,types['Genre']):
plt.text(index,count+50,count,ha='center',va='bottom')
plt.show()
从上图来看,动作类游戏最多,其次是运动类游戏。
按照上述方式,我们还可以得到发布平台、发行商的类别数。这里,以各自的前五名进行展示
f,ax=plt.subplots(1,3,figsize=(15,6))
types=pd.DataFrame(df['Genre'].value_counts()[:5])
platform=pd.DataFrame(df['Platform'].value_counts()[:5])
publisher=pd.DataFrame(df['Publisher'].value_counts()[:5])
a=np.arange(len(types))
b=np.arange(len(platform))
c=np.arange(len(publisher))
types.plot(kind='bar',
alpha=0.6,color='Blue',
title='The counts of top 5 types',ax=ax[0])
for index,count in zip(a,types['Genre']):
ax[0].text(index,count+50,count,ha='center',va='center')
platform.plot(kind='bar',
alpha=0.6,color='red',
title='The counts of top 5 Platforms',ax=ax[1])
for index,count in zip(b,platform['Platform']):
ax[1].text(index,count+30,count,ha='center',va='center')
publisher.plot(kind='bar',
alpha=0.6,color='Green',
title='The counts of top 5 Publisher',ax=ax[2])
for index,count in zip(b,publisher['Publisher']):
ax[2].text(index,count+20,count,ha='center',va='center')
plt.show()

发布平台较多的是DS和PS2,发行商较多的是Electirc Arts,Activision
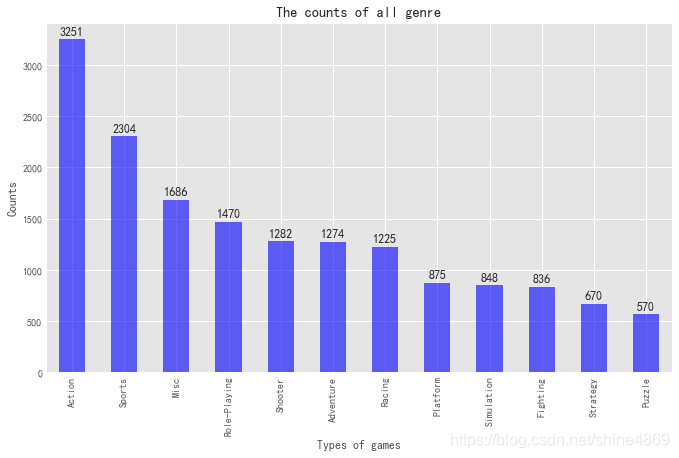
(2) 查看受欢迎的游戏类型、平台、发行商
从类别数量来看,类别数较多的不一定受欢迎。这里,我们以销量为纵轴,看看哪些游戏类型、平台、发行商较受欢迎。为方便展示结果,这里都取前五名演示
f,ax=plt.subplots(1,3,figsize=(15,6))
#分组统计,并按全球销量降序排列,取前五名
types=pd.DataFrame(df.groupby('Genre').
agg({'Global_Sales':np.sum})).
sort_values(by='Global_Sales',
ascending=False)[:5]
platform=pd.DataFrame(df.groupby('Platform').
agg({'Global_Sales':np.sum})).
sort_values(by='Global_Sales',
ascending=False)[:5]
publisher=pd.DataFrame(df.groupby('Publisher').
agg({'Global_Sales':np.sum})).
sort_values(by='Global_Sales',
ascending=False)[:5]
font={
'family':'DejaVu Sans',
'weight':'normal',
'size':12
}
types.plot(kind='bar',
alpha=0.6,color='Blue',
title='The Sales of top 5 Game Genres',
ax=ax[0],legend=False)
ax[0].set_ylabel('Genre_Sales',font)
platform.plot(kind='bar',
alpha=0.6,color='red',
title='The Sales of top 5 Game Platforms',
ax=ax[1],legend=False)
ax[1].set_ylabel('Platform_Sales',font)
publisher.plot(kind='bar',
alpha=0.6,color='Green',
title='The Sales of top 5 Game Publisher',
ax=ax[2],legend=False)
ax[2].set_ylabel('Publisher_Sales',font)
plt.subplots_adjust(wspace=0.3) #调整各个子图横向间距
plt.show()
从销量角度来看,最受欢迎的游戏类型是动作类游戏,最受欢迎的平台为PS2,最受欢迎的发行商为Nintendo
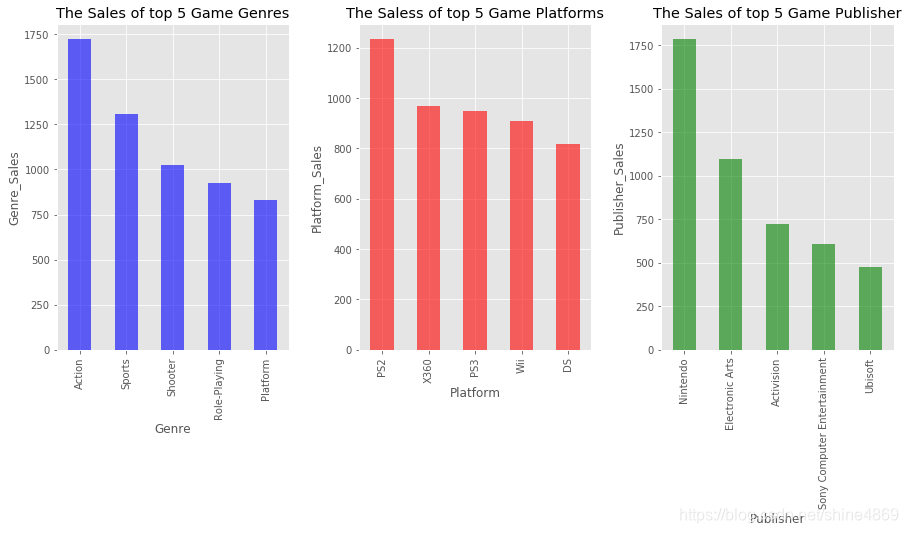
(3) 按地区,查看受欢迎的游戏类型、平台、发行商
data=df.pivot_table(index='Genre',
values=['JP_Sales','EU_Sales',
'NA_Sales','Global_Sales'],
aggfunc=np.sum,)
data['NA_prop']=data['NA_Sales']/data['Global_Sales']
data['JP_prop']=data['JP_Sales']/data['Global_Sales']
data['EU_prop']=data['EU_Sales']/data['Global_Sales']
f,ax=plt.subplots(figsize=(12,8))
index=np.arange(len(data))
minColor = (31/256,78/256,95/256)
midColor = (121/256,168/256,169/256)
maxColor = (170/256,207/256,208/256)
#绘制堆积柱形图
plt.bar(index,data.NA_prop,color=minColor)
plt.bar(
index,data.JP_prop,
bottom=data.NA_prop,
color=midColor
)
plt.bar(
index,data.EU_prop,
bottom=data.NA_prop,
color=maxColor
)
font={
'family':'DejaVu Sans',
'weight':'normal',
'size':12
}
plt.xticks(index,data.index,rotation=90)
plt.title('The Proportion of Different Areas',font)
plt.ylabel('Proportion',font)
plt.legend(['NA_Sales','JP_Sales','EU_Sales'],
loc='upper center',ncol=3,framealpha=0.6)
plt.show()
北美地区各类游戏销量都挺高的呢,日本也只有角色扮演类游戏销售较高。同样的方法,可得到发布平台、发行商的地区销售分布
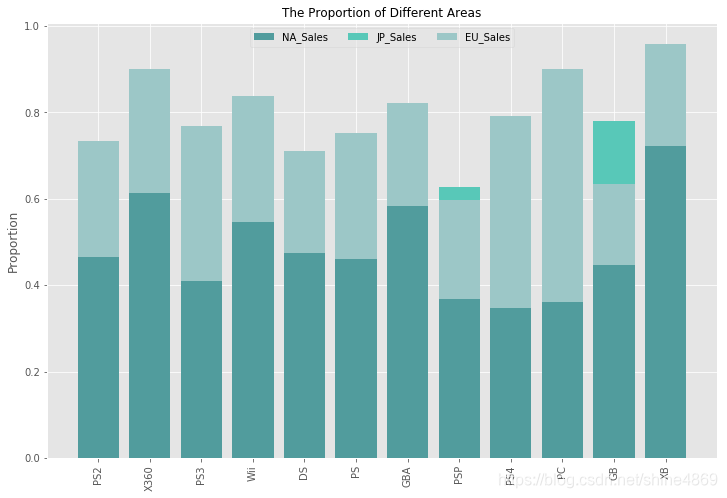
X360、GBA、XB这三个发布平台在北美更受欢迎,PS4,PC这两个平台在欧洲更受欢迎
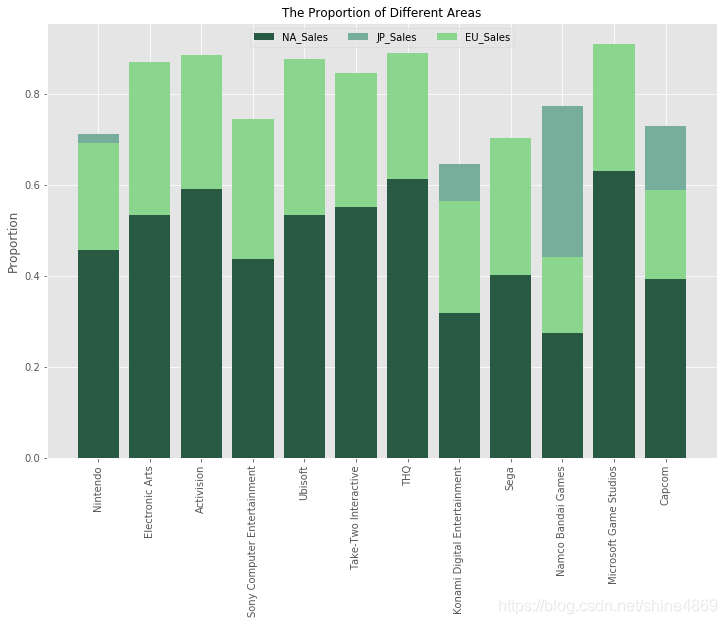
发行商Activision、THQ、Microsoft Game Studios在北美更受欢迎,Namco Bandai Games 在日本更受欢迎
四、时序分析
(1) 全球销量的时序变化
time=df.groupby('Year').agg({'Global_Sales':'sum'})
time.plot(alpha=0.6,figsize=(12,8),
legend=False,color='Blue')
plt.xticks(np.arange(time.index.min(), #调整横轴时间间隔
time.index.max()),
rotation=90)
font1={'family' : 'Times New Roman',
'weight' : 'normal',
'size' : 12,
}
plt.title('The Global_Sales Changing Chart',font1)
plt.ylabel('Global_Sales',font1)
plt.vlines(time.idxmax(),0, #添加垂线
int(time['Global_Sales'].max()),
linestyle='--',color='red')
plt.annotate('The Highest Sales is {} million'. #标注最高销量
format(int(time.Global_Sales.max())),
xy=(time.idxmax(),int(time.Global_Sales.max())),
xytext=(time.idxmax()+1,int(time.Global_Sales.max())+15),
arrowprops=dict(color='red',headwidth=8,headlength=8),
family='fantasy')
plt.show()
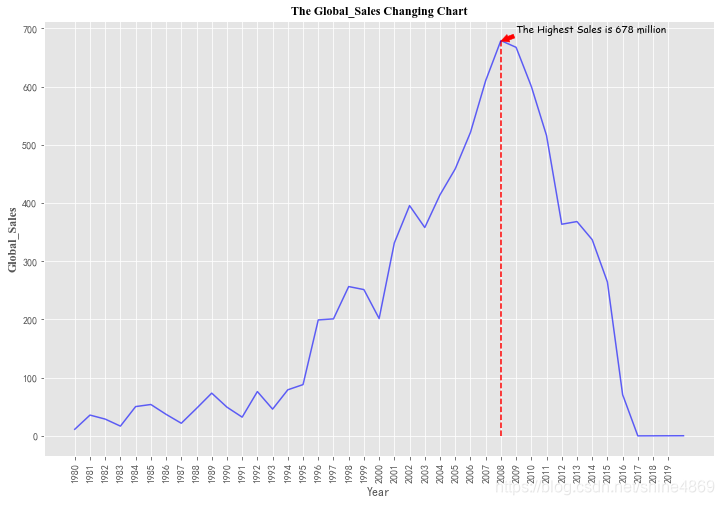
从上图来看,全球游戏销量在2008年总体上呈现出逐渐增大趋势,2008年达到峰值6.78亿销量,之后销量大幅度下滑,电子游戏市场逐渐惨淡。
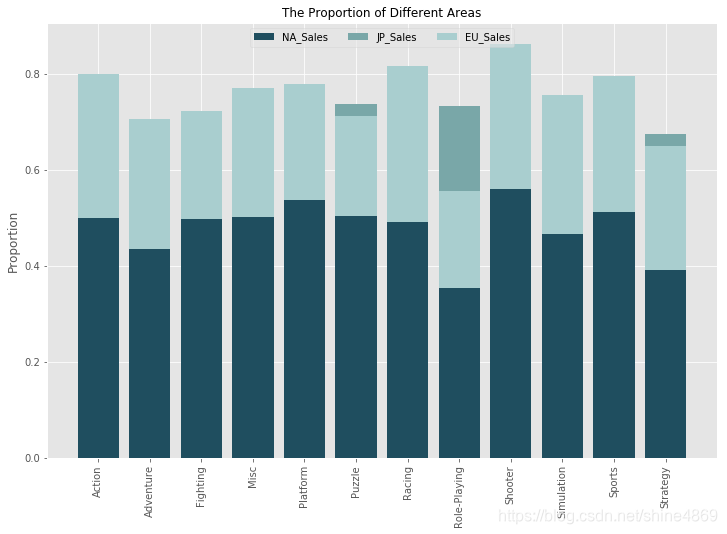
(2) 各地区销量变化(北美、日本、欧洲)
#按年汇总各地数据
data=df.pivot_table(index='Year',
values=['JP_Sales','EU_Sales',
'NA_Sales','Global_Sales'],
aggfunc=np.sum)
#计算比例
data['NA_prop']=data['NA_Sales']/data['Global_Sales']
data['JP_prop']=data['JP_Sales']/data['Global_Sales']
data['EU_prop']=data['EU_Sales']/data['Global_Sales']
f,ax=plt.subplots(figsize=(12,8))
index=np.arange(len(data))
minColor = (117/256,79/256,68/256)
midColor = (236/256,115/256,87/256)
maxColor = (253/256,214/256,146/256)
plt.bar(index,data.NA_prop,color=minColor)
plt.bar(
index,data.JP_prop,
bottom=data.NA_prop, #通过bottom来设置这个柱子距离底部的高度
color=midColor
)
plt.bar(
index,data.EU_prop,
bottom=data.NA_prop, #通过bottom来设置这个柱子距离底部的高度
color=maxColor
)
font={
'family':'DejaVu Sans',
'weight':'normal',
'size':12
}
plt.xticks(index,data.index,rotation=90)
plt.title('The Proportion of Different Areas',font)
plt.ylabel('Proportion',font)
plt.legend(['NA_Sales','JP_Sales','EU_Sales'],loc='upper center',ncol=3,framealpha=0.6)
plt.show()
f,ax=plt.subplots(figsize=(12,8))
plt.bar(index,data.NA_prop,color=minColor)
plt.bar(
index,data.JP_prop,
bottom=data.NA_prop, #通过bottom来设置这个柱子距离底部的高度
color=midColor
)
plt.bar(
index,data.EU_prop,
bottom=data.NA_prop,
color=maxColor
)
font={
'family':'DejaVu Sans',
'weight':'normal',
'size':12
}
plt.xticks(index,data.index,rotation=90)
plt.title('The Proportion of Different Areas',font)
plt.ylabel('Proportion',font)
plt.legend(['NA_Sales','JP_Sales','EU_Sales'],
loc='upper center',ncol=3,framealpha=0.6)
plt.show()
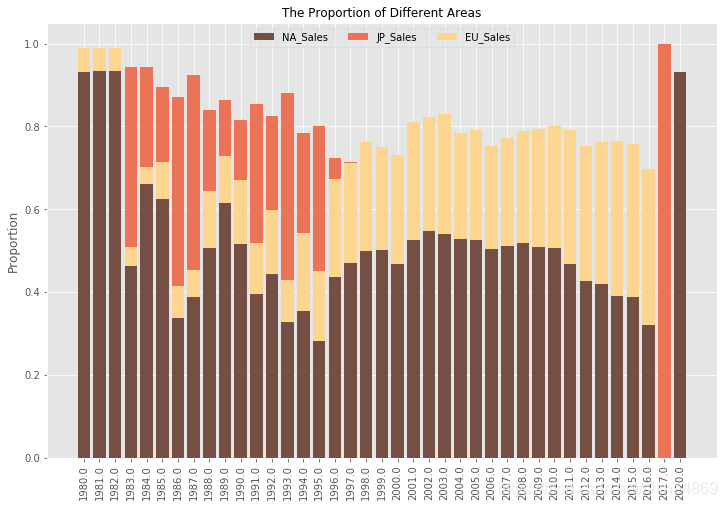
从堆积柱形图来看,全球电子游戏的销售量主要来自于北美地区,在1983-1995年期间,日本地区的电子游戏销售市场占有较大比重,之后就销声匿迹了;随后,欧洲地区电子游戏销售市场于1996年开始,占比逐渐增大。(像2017年、2020年全球电子游戏销量只来自于日本地区和北美地区,感觉最近几年数据并没有统计完全。)
(3) 建模预测
1.保证年份的连续性,剔除2020年的数据,并对序列作差分
new_data=pd.DataFrame(df.groupby('Year').agg({'Global_Sales':np.sum}))
data=data.drop(data.index[38])
从(1)的时序图来看,序列是不平稳的,这里首先做一阶差分,进行平稳性检验并绘制差分后的时序图。
from statsmodels.tsa.stattools import adfuller as ADF
diff_data=data.diff().dropna() #去除NA值
print('一阶差分后序列ADF检验P值为{}'.format(ADF(new_data['Global_Sales'])[1]))
diff_data.plot()

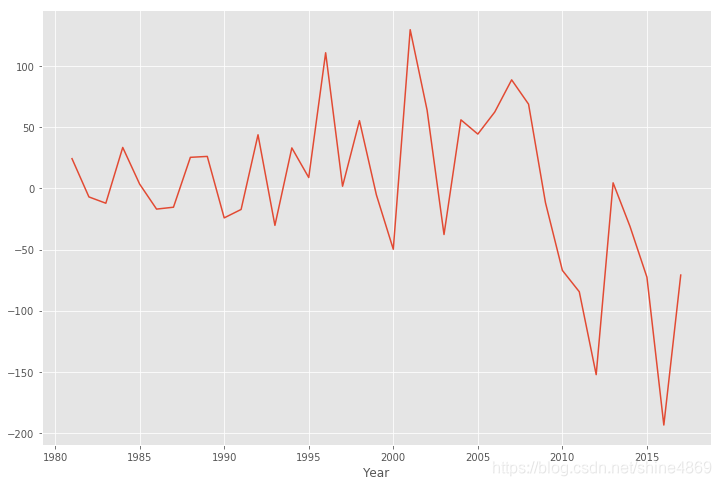
从ADF检验结果来看,P值小于0.05,故有充分理由拒绝原假设,即可认为差分后的序列是平稳的;此外,从差分时序图也可看出,序列大致围绕着0上下波动。
2.绘制ACF、PACF图,进行初步定价
from statsmodels.graphics.tsaplots import plot_acf
from statsmodels.graphics.tsaplots import plot_pacf
plot_acf(new_data,lags=15).show()
plot_pacf(new_data,lags=15).show()
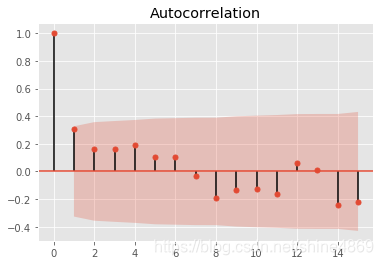
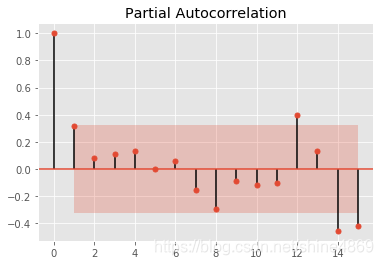
从自相关图和偏自相关相关图可知,都呈现拖尾性,可建立ARMA(1,1)
这里,仅对差分后的序列进行拟合。(实际上应该差分的还原再预测)
from statsmodels.tsa.arima_model import ARMA
model = ARMA(new_data,order=(1,1)).fit()
plt.plot(new_data,label='Origin_diff')
plt.plot(predict_ts,label='Predict_diff')
plt.legend(loc='best')
plt.show()
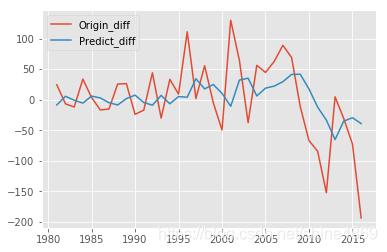
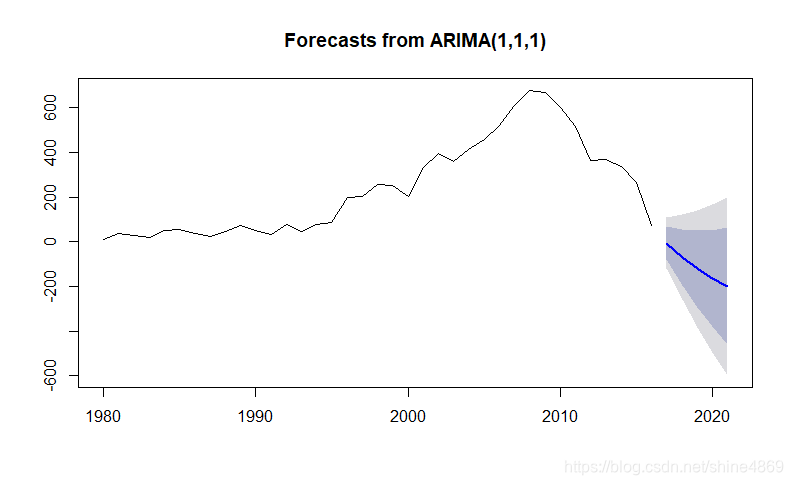
关于ARMA模型的差分还原,网上找了一些教程,最后执行出的结果都是NAN。这里再用R进行预测一下,emm,后面几年销量直接为负了…(可能原数据集最近几年的数据根本没有统计完全,2016年全球销量有70.9million,2017年就只有0.05million了…总感觉数据有点异常)

















 2953
2953

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









