







文章目录
前言
本文主要介绍虚拟存储基本原理。
Terminology
| Term | Description |
|---|---|
| PR | placement and routing,布局和布线 |
| TLB | Translation Look-aside Buffers,翻译后备缓冲区 |
| LRU | Least Recently Used,最近最少使用 |
1. 为什么需要虚拟存储?
在虚拟存储还未出现以前,如果CPU上同时运行2个及以上的进程(process),在运行进程前需要在内存(DRAM)中为每个进程分配固定的空间,如果进程间的地址空间存在重叠,同时运行时会出现内存数据被覆盖的情况,导致进程运行错误,所以每个进程的地址空间都是独立且独占的。
| DRAM地址空间 | range 0 | range 1 | range 2 |
|---|---|---|---|
| 进程 | process 0 | process 1 | process 2 |
进程的内存地址空间固定带来很多缺点:
- 由于DRAM的容量无法做到很大(像硬盘一样几百个G或者几个T),那么CPU上可以运行的进程一定是有限的
- 增加了编程者的难度,编写程序时还需要考虑DRAM的空间分配
- 每个进程看到的空间可能会很小,限制了大型应用软件的出现、运行
- …
如果操作系统可以动态分配地址空间呢?
- 页:将DRAM的地址空间按照4KB为粒度,划分为(内存容量/ 4KB)个页,之所以是4KB是因为早期DRAM容量为MB级别,粒度如果过大会导致内存的使用率降低,粒度如果太小,调度会很麻烦,也是体系结构设计的trade off
- 现代处理器页:现在DRAM都是GB级别,现代处理器大多都支持8/16/32KB的页,同时还向下兼容4KB页
- 页管理:OS负责“页”的管理,包括申请、释放
- 页申请:进程启动,申请地址空间,OS分配多个页以满足进程的内存需求
- 页释放:进程结束,释放地址空间,OS收回已分配的页,可用于其他进程的地址申请
2. 怎样实现虚拟存储?
进程此时申请到的地址空间是连续的吗?
- 从进程的视角看,地址空间是连续的。
- 从OS/DRAM的视角看,地址空间是离散的。
| DRAM地址空间 / 时间 | page 0 | page 1 | page 2 | page 3 | page 4 | page 5 |
|---|---|---|---|---|---|---|
| T0 | process 0 | process 0 | idle | idle | idle | idle |
| T1 | release | process 0 | idle | idle | idle | idle |
| T2 | idle | process 0 | idle | idle | idle | idle |
| T3 | process 1 | process 0 | process 1 | process 1 | idle | idle |
| T4 | process 1 | process 0 | release | process 1 | idle | idle |
| T5 | process 1 | process 0 | idle | process 1 | idle | idle |
| T6 | process 1 | process 0 | process 2 | process 1 | process 2 | process 2 |
各时间点,process x和OS的操作:
- T0 :process 0 向OS申请内存,OS将page 0/1分配给process 0
- T1 :process 0 不再需要page 0,向OS申请释放
- T2 :OS接收process 0的释放申请,page 0处于idle
- T3:process 1向OS申请内存,OS将page 0/2/3分配给process 1
- T4:process 1 不再需要page 2,向OS申请释放
- T5 :OS接收process 1的释放申请,page 2处于idle
- T6:process 2向OS申请内存,OS将page 2/4/5分配给process 1
可以看到process申请到的内存(DRAM空间)并不一定是连续的,如果让程序员在离散的地址空间上进行编程,那就是给他的键盘加了一把锁,限制和约束太多,对程序员十分不友好,哪CPU怎样让process看到的内存是连续的呢?
引入虚拟地址(VA,virtual address),DRAM空间被成为物理地址(PA,physical address)
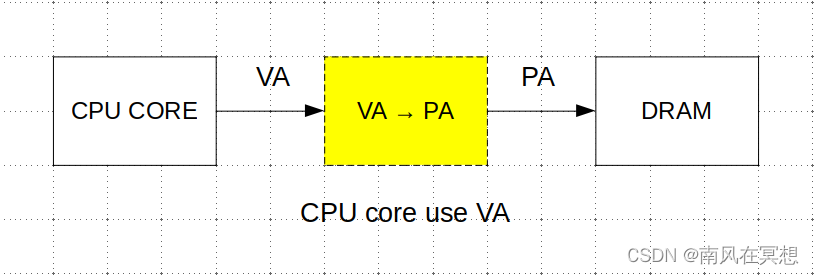
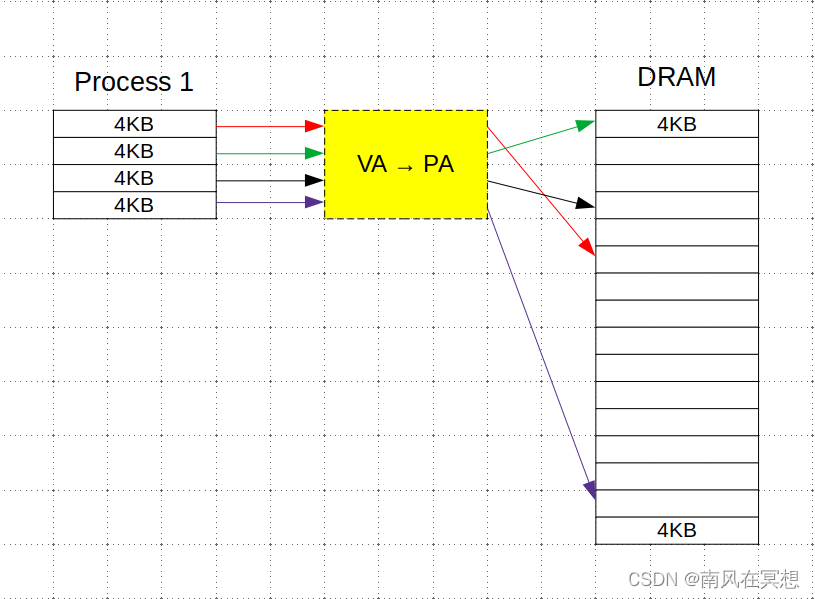
如果存在一个模块可以完成VA -> PA的映射,将连续的VA映射到离散的PA(对应DRAM中离散的4K page)上,则OS可以给CPU CORE的进程分配连续的VA,对于程序员来说,可编程的地址空间就是一片连续的地址。
- Process 1看到的是连续的16KB VA
- VA -> PA转换模块,根据OS在分配内存地址之前准备好的VA->PA映射关系,将VA地址映射到对应的PA
- PA地址,可能不是连续的
- 如果Process 1需要更多的内存空间,只要内存有空闲的page,OS在Process 1申请的时候,都可以分配给Process 1,可以看出每个线程此时的编程地址空间都是整个DRAM——“统一编程地址空间”
如果在CPU CORE和DRAM之间增加VA -> PA的转换模块,接下来还需要思考这几个问题:
- 如何实现虚实地址转换?
- 多进程是否需要多个该模块?
- 该模块的微结构是怎样的?对CPU的性能有什么影响?
3. 虚实地址转换与页表
后续仅讨论内存的页(page)大小为4KB的情况,暂不考虑8/16/64KB或者更大的情况
上一节说到“OS在给进程分配虚拟地址空间时会提前准备好VA->PA的映射关系”,这个映射关系被称之为页表(Page Table),页表通常是64bit,完成VA到PA转换的模块被称为MMU(Memory Management Unit,内存管理单元)。
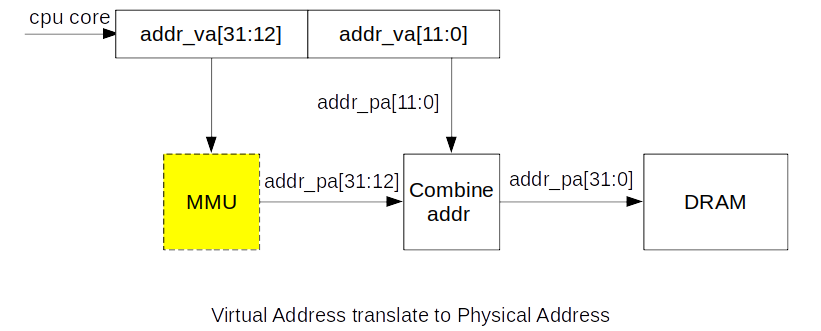
考虑以下场景,CPU CORE发出一笔访存请求,访问地址VA为addr_va,地址位宽为32bit,经过MMU映射后的地址为addr_pa,地址位宽为32bit。
- CPU CORE发出32bit VA地址,低12bit不需要参与映射,属于页内地址,页内虚拟地址和物理地址相等
- 高20bit需要经过MMU映射,产生20bit物理地址,再和低12bit页内地址组合,产生完整的32bit物理地址,用于访问内存
- addr_va[31:12]翻译为addr_pa[31:12]依赖于MMU缓存的页表,下面看一下是如何将虚拟地址翻译为物理地址。
3.1 LoongArch页表格式

- E,存在位,1bit
- ASID,地址空间标识,10bit
- G,全局标志位,1bit
- PS,页大小,6bit
- VPPN,虚双页号,19bit
- V0/1,页有效位,1bit
- D0/1,页脏位,1bit
- MAT0/1,页存储访问类型,2bit
- PLV0/1,页特权等级,2bit
- PPN0/1,页物理页号,PALEN-12 bit
3.2 虚实地址翻译
LoongArch继承自MIPS架构,一个页表可以翻译2个4KB,分为奇偶页,提高页表使用效率。
- 假设PALEN为32bit
- 如果页表有效
- 如果addr_va[31:21] == VPPN,addr_va[20]=0,使用偶数页PPN0进行翻译,得到addr_pa[31:20] = PPN0,完成翻译
- 如果addr_va[31:21] == VPPN,addr_va[20]=1,使用奇数页PPN1进行翻译,得到addr_pa[31:20] = PPN1,完成翻译
根据页表,VA翻译为PA实际上是一个比较简单的过程
除了考虑正确性,还会考虑MMU对CPU CORE性能的影响,不能因为引入MMU而导致CPU CORE性能下降。
4. 多级页表
如果PA一直是32bit,那么最大地址空间为4GB,如果一个页表的大小为64bit,只需要在内存中分配8MB的地址空间存放页表,即可以访问所有的物理地址,当然多线程需要的空间可能会大一些,但是仍然是MB级别。
随着计算机的发展,32bit PA无法满足实际需求,内存容量一般都大于4GB,服务器所需内存甚至可以达到数百GB。AMD率先推出了64bit CPU,最大地址空间为(2 ^ 32) * 4GB = (2 ^ 22) * 4TB,实际上64bit在未来很长一段时间都不会被用完。如果一直使用一级页表映射,不同位宽的PA所需存放页表的地址空间如下:
- PA位宽为40bit,需要2GB空间存放页表,如果内存只有16GB,则需要花费1/8的空间存放页表,这显然是不合理的
- PA位宽为42bit,需要4GB空间存放页表
- …
| PA位宽(bit) | 存放页表所需内存(MB) |
|---|---|
| 32 | 8 |
| 34 | 32 |
| 36 | 128 |
| 38 | 512 |
| 40 | 2048 |
| 41 | 4096 |
为了解决随着PA位宽增加,一级页表所需内存也指数级增加的问题,引入了多级页表的设计,LoongArch多级页表的思路如下:
- VA被划分为5个部分,Segment Selector用于合法性检查,包括地址是否为非法地址等;Level1/2/3为3段页表地址;Page Offset为页内偏移,PA[11:0] = VA[11:0]
- 每一级页表都有VPPN和PPN
- va_leval_1 + Page_table_base_addr -> va_level_1_addr,va_level_1_addr和页表的VPPN比较,如果相等则输出页表内的PPN,如果L1 page table不存在一项页表的VPPN和va_level_1_addr相等,则需要到DRAM中读回对应的Level 1 Page table
- Level 2和Level 1过程相同
- Level 3为末级页表,如果L3 page table存在一项页表的VPPN和va_level_3_addr相等,则使用该页表的PPN作为addr_pa[PALEN-1:12]
- 再将addr_pa[PALEN-1:12]和addr_va[11:0]拼接,得到完整的PA即可访问DRAM
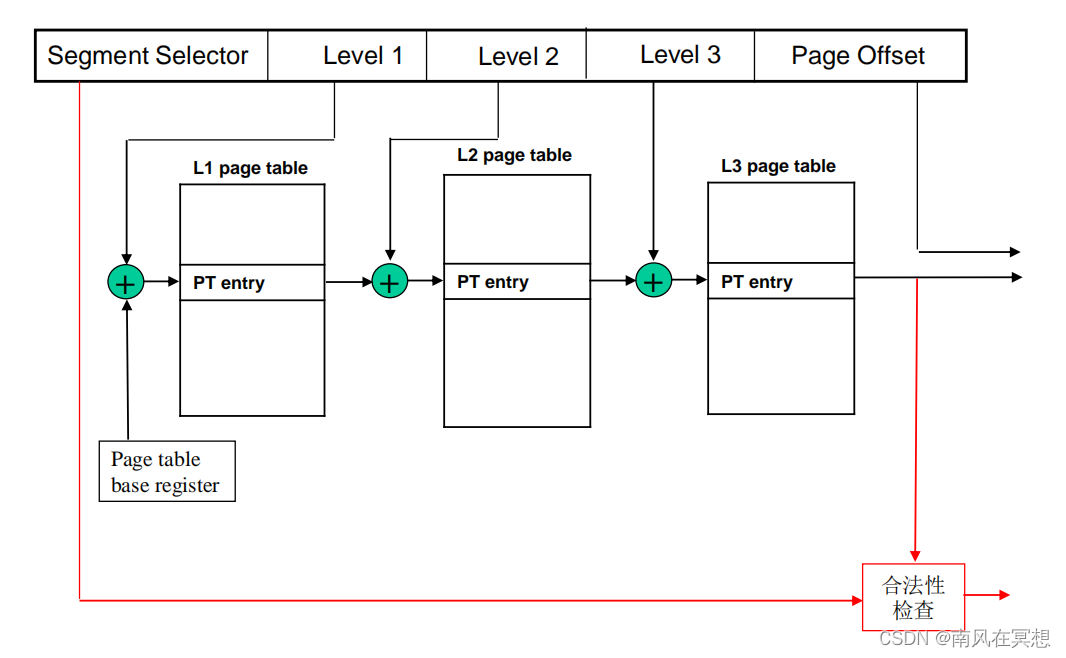
那么多级页表对内存容量的需求是多少呢?假设PALEN为42,Level 1/2/3均分30bit
- Level 1/2/3分别有 2 ^ 10个页表,即1024 * 8B,共需要24KB的地址空间存放3级页表
- 即使存在多线程,假设线程数为1024,每个线程都有一套完整、独立的3级页表,所需要的内存地址空间为24MB
- 相比较单级页表,存放页表所需的内存空间被极大地压缩。
5. TLB
5.1 如何在MMU中存放页表?
现在我们知道OS会在内存中分配一片地址空间,专门用于存放线程的页表。前文说到,引入MMU不能降低CPU CORE的性能,怎样保证性能不降低呢?直观上最好的办法就是MMU拥有全部的页表,CPU CORE需要时就可以很快获取,访存不会因为MMU没有页表而阻塞。那我们来简单计算一下存放这些页表所需要的SRAM。
假设每个进程都需要一套完整、独立的3级页表,PALEN为42bit,Level 1/2/3位宽分别为10bit,3级页表所需空间为24KB。
| 进程数量 | 存放页表所需SRAM的容量(KB) |
|---|---|
| 1 | 24 |
| 2 | 48 |
| 4 | 96 |
| 8 | 192 |
| 16 | 384 |
| 32 | 768 |
参考AMD的处理器的L1 cache容量,猜测L1 cache容量是L1 Data cache和L1 Instruction cache之和,在TSMC 4nm工艺下,最大也没超过1MB,cache存储数据都是使用SRAM,而SRAM会占据CPU 50%以上的PR面积。
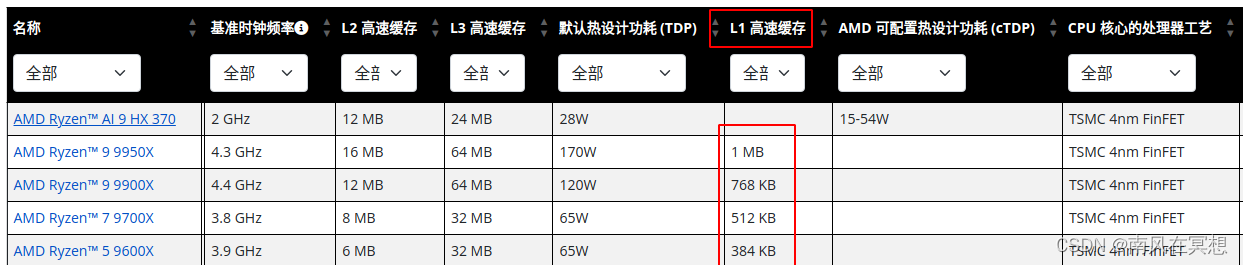
显然如果我们期望将页表全部存放在MMU中,如果最大支持32线程,则需要768KB的SRAM,这会导致很多缺点:
- CPU 的面积会增加很多,存放页表的SRAM和D/I Cache SRAM一样大
- 最大支持的线程数受限,取决于存放页表的SRAM容量,程序员显然是无法接受的,处理器也是很难使用的。
5.2 分析CPU CORE访存特性
- 单个进程:虽然单个进程可以使用DRAM的全部空间,实际上没有哪个应用程序会真的申请这么大的地址空间,比如chrome,同一时刻也就占据了数百MB的内存,而且这些内存在VA上大概率是连续的。
- 多个进程:只考虑单核(假设不支持多线程),进程之间时分复用CPU CORE,进程之间的VA大概率是不相关的。
单个进程VA大概率是连续,该进程发出的访存行为在空间和时间上是有相关性的。
多个进行的VA大概率是独立不相关的。
访存行为在空间和时间上是有相关性的,让我们很容易就想起cache的特性。
- cache line支持被替换
- 针对不同的访问行为,可以使用不同的替换算法提高命中率
- 支持预取
是否可以使用cache缓存页表呢?没错,那些计算机体系结构的工程师们就是这么干的。
5.3 使用cache缓存页表的问题
既然不将所有的页表都缓存在MMU,而是使用cache缓存有限的页表,那么cache的容量该如何确定呢?需要考虑以下几点:
- 如果cache中不存在所需页表,MMU需要从DRAM读回对应页表,延迟通常为200ns
- 页表在cache中不能频繁miss,如果页表miss,考虑到现代处理器的工作频率大概是3GHz左右,换算为cycle为600左右,流水线因为页表miss需要暂停600 cycle是CPU不可以接受的
- 进程切换时,页表最好也不要频繁miss;通常在使用电脑时期望暂时不使用的进程图标缩到最小,使用时可以立即使用的体验最好,如果MMU的页表miss,需要从DRAM获取,就会导致CPU CORE流水线暂停,表现在使用上就是电脑卡顿。
我们将问题具体化:
- 如果cache中没有所需
- 如何使用cache缓存单进程的多级页表?如何降低页表的miss rate?
- cache容量需要多大才可以保证进程切换页表不频繁miss?
- cache的替换算法如何选择?
5.4 TLB
5.4.1 缓存单进程的多级页表
Level 1/2/3页表其实是不同的。
CPU CORE发出的访存addr_va[41:0]
- Level 1 页表会用VPPN和addr_va[41:32]比较,输出l1_addr_va[41:12]
- Level 2 页表会用VPPN和l1_addr_va[31:22]比较,输出l2_addr_va[41:12]
- Level 3 页表会用VPPN和l2_addr_va[21:12]比较,输出addr_pa[41:12]
- 1张Level 1页表可以覆盖4GB空间,1张Level 2页表可以覆盖4MB空间,1张Level 3页表可以覆盖4KB空间。
- 那么这就意味着如果期望覆盖128MB的地址空间,需要1张Level 1页表,32张Level 2页表,1024张Level 3页表(Level 3页表只比较10bit的va,最多也只有1024张),那么如果单个进程申请128MB的内存,实际上大约只需要9KB的空间
- 如果进程的访问还具有一定的相关性,可以使用cache 预取功能,将页表提前预取回来,可以很好的掩盖访问DRAM的latency,而且实际上不需要9KB的容量,只要cache中有效页表的消耗时间大于访问DRAM的latency就可以实现CPU不因为页表miss而断流。
假设访存DRAM的latency还是上文提到的600 cycle,在600cycle内CPU最多发出600个访存请求,CPU cache line通常为64B,故最多访问600*64B的数据量,即37.5KB。
如果访存连续性很好,需要Level 1/2页表各一张,Level 3页表10张,每个页表8B,需要96B SRAM存放页表。
当然上述考虑的是很理想的模型,包括访存延迟、访存连续性和替换算法都很理想。
如果访存延迟扩大2倍,访存范围存在跳跃,访存范围扩大5倍,替换算法导致cache容量增加2倍,共增加20倍的容量,即需要1.875KB的cache容量就可以满足单个进程的需求。
5.4.2 缓存多个进程的页表
上节得到相对极限的情况下需要1.875KB的可以保证单个进程的页表不miss。假设同时打开32个进程,而且替换算法会将很久不使用的进程的页表替换掉(LRU),那么32*1.875KB=60KB,TLB拥有60KB的容量应该就可以保证这32个线程切换时不会因为页表miss而卡顿。
总结
本文从为何需要虚拟存储讲起,引出了将内存划分为“页”并动态分配的想法,思考了动态分配地址的初步方案,介绍了LoongArch的页表格式并以一个例子介绍了虚实地址转换,至此已经将虚拟存储基本原理介绍完。
后续讨论了多级页表的必要性,介绍多级页表的虚实地址转换。首先讨论了增加MMU对CPU CORE性能的影响,根据现代处理器的规格否定了将页表全部存储在片内的设计,进一步分析CPU CORE的访存特性,发现单进程访存在时间和空间上存在相关性,思考使用cache存储页表的可能性以及设计难点,分析在不损失CPU性能的情况下的最小cache容量。
End
参考
[1] 计算机体系结构——存储管理,胡伟武
[2] AMD 处理器规格















 544
544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









