









什么是彩票网络假说?
在人工智能和机器学习的领域中,神经网络的训练和优化一直是研究的核心课题。2019年在ICLR(国际学习表征会议)上发表的一篇论文《The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks》提出了一个引人注目的理论——彩票网络假说(The Lottery Ticket Hypothesis)。这个假说不仅挑战了我们对神经网络训练的传统理解,还为如何更高效地设计和训练神经网络提供了新的思路。今天,我们就来聊聊这个有趣的概念。
下文中图片来源于原文:https://arxiv.org/pdf/1803.03635
彩票网络假说的核心思想
彩票网络假说的核心观点可以用一句话概括:在一个随机初始化的密集神经网络中,存在一个稀疏的子网络(即“中奖彩票”),这个子网络在保持其初始权重的情况下,经过独立训练,可以达到与原始网络相当的测试准确率,并且训练时间不会更长。
换句话说,研究者认为,一个大型的、过度参数化的神经网络就像一张“彩票”,其中包含许多可能的子网络(票券)。在这些子网络中,总有一些“幸运儿”拥有特殊的初始权重组合,使得它们在训练时能够快速收敛并表现出色。这些子网络被称为“中奖彩票”(winning tickets),因为它们仿佛在初始化时就“中了大奖”,具备了优异的学习能力。
为什么会有这样的假说?
神经网络剪枝(pruning)技术早已证明,训练好的网络可以通过删除90%以上的参数而不显著影响准确性,从而大幅减少存储需求和推理计算成本。然而,一个常见的经验是,如果直接从头开始训练这些剪枝后的稀疏网络,效果往往不如原始网络。这引发了一个问题:如果网络可以被压缩到如此小的规模,为什么我们不能直接训练这个小网络呢?
彩票网络假说的提出正是为了回答这个问题。作者Jonathan Frankle和Michael Carbin通过实验发现,传统的剪枝方法实际上能够揭示出那些天生具有良好初始化的子网络。他们提出,这些子网络的成功不仅仅依赖于结构,还与初始权重密切相关——正是这些“幸运的初始化”让它们能够在训练中脱颖而出。
如何找到“中奖彩票”?
论文中描述了一个具体的算法来识别这些“中奖彩票”:
- 随机初始化一个神经网络:用随机权重初始化一个密集的神经网络。
- 训练网络:对这个网络进行若干次迭代的训练,得到训练后的参数。
- 剪枝:删除一定比例(例如20%)权重值最小的连接,生成一个掩码(mask),标记哪些权重被保留。
- 重置权重:将保留下来的连接的权重重置回初始值,得到一个稀疏的子网络,即“中奖彩票”。
- 迭代执行:重复上述步骤多次(称为迭代剪枝),逐步减少网络规模。
通过这个过程,研究者发现,迭代剪枝通常比一次性剪枝(one-shot pruning)更能找到小型且高效的“中奖彩票”。这些子网络通常只保留原始网络10%-20%的参数,却能在MNIST和CIFAR10等数据集上达到与原始网络相当甚至更高的准确率。
实验验证与发现
研究者在多种网络结构上验证了彩票网络假说,包括针对MNIST的全连接网络和针对CIFAR10的卷积网络(如Conv-2、Conv-4、Conv-6,以及更深的VGG-19和Resnet-18)。以下是一些关键发现:
- 稀疏性与性能:找到的“中奖彩票”通常非常稀疏(参数量仅为原始网络的10%-20%),但性能却能媲美甚至超越原始网络。
- 初始化的重要性:如果将“中奖彩票”的权重随机重新初始化,其性能会显著下降,表明初始权重对训练成功至关重要。
- 学习速度:在适当的剪枝范围内,“中奖彩票”往往比原始网络学习得更快。例如,在Lenet网络上,最优子网络的早停时间比原始网络减少了38%。
- 泛化能力:这些子网络不仅训练准确率高,测试准确率也有所提升,表明它们具有更好的泛化能力。
对神经网络训练的启示
彩票网络假说提供了一个全新的视角,让我们重新思考神经网络的训练过程:
- 过度参数化的作用:传统观点认为,过度参数化的网络更容易训练,因为它们有更大的容量。彩票假说则提出,过度参数化可能是在提供更多的“彩票”,从而增加找到“中奖彩票”的机会。
- 优化过程的本质:研究者推测,随机梯度下降(SGD)可能在训练过程中自然倾向于找到并优化这些“中奖彩票”,而非平均优化整个网络。
- 高效训练的可能性:如果我们能直接识别或构造“中奖彩票”,或许可以跳过训练大型网络的步骤,从而显著降低计算成本。
局限性与未来方向
尽管彩票网络假说令人兴奋,但它也有一些局限性。例如,研究目前仅在较小的数据集(如MNIST和CIFAR10)上进行了验证,对于更大的数据集(如ImageNet),迭代剪枝的计算成本过高,限制了其应用。此外,找到“中奖彩票”的方法依赖于稀疏剪枝,结果网络并不一定适配现代硬件优化的需求。
未来的研究方向包括:
- 开发更高效的算法来识别“中奖彩票”。
- 探索结构化剪枝方法,使稀疏网络更适合实际部署。
- 研究“中奖彩票”初始化的内在属性,理解它们为何如此有效。
总结
彩票网络假说是一个大胆而有趣的理论,它揭示了神经网络中可能隐藏着高效的小型子网络。这些子网络凭借“幸运的初始化”,能够在大幅减少参数的情况下保持甚至超越原始网络的性能。这一发现不仅深化了我们对神经网络训练机制的理解,也为未来的模型设计和优化开辟了新的可能性。或许有一天,我们真的能直接“买到”一张彩票,跳过繁琐的训练,直接获得一个高效的神经网络!
代码实现
要用代码实现彩票网络假说(Lottery Ticket Hypothesis),模拟论文中描述的实验过程:初始化一个神经网络、训练它、剪枝(pruning)、重置权重到初始值,并重复这个过程(迭代剪枝)。以下是一个基于Python和PyTorch的简化实现示例,针对一个简单的全连接神经网络(类似于论文中的Lenet架构)在MNIST数据集上进行实验。
实现步骤
- 定义网络:创建一个简单的全连接神经网络。
- 初始化和训练:随机初始化网络并训练。
- 剪枝:基于权重大小剪掉一定比例的连接。
- 重置权重:将保留的权重重置为初始值。
- 迭代执行:重复训练和剪枝过程。
- 验证结果:比较原始网络和“中奖彩票”的性能。
以下是代码实现:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
import numpy as np
# 设置随机种子以保证可重复性
torch.manual_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义简单的全连接网络(类似于Lenet)
class SimpleNet(nn.Module):
def __init__(self):
super(SimpleNet, self).__init__()
self.fc1 = nn.Linear(28 * 28, 300) # 输入层到隐藏层1
self.fc2 = nn.Linear(300, 100) # 隐藏层1到隐藏层2
self.fc3 = nn.Linear(100, 10) # 隐藏层2到输出层
self.relu = nn.ReLU()
def forward(self, x):
x = x.view(-1, 28 * 28) # 展平输入
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.fc3(x)
return x
# 加载MNIST数据集
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
trainset = torchvision.datasets.MNIST(root='./data', train=True, download=True, transform=transform)
trainloader = DataLoader(trainset, batch_size=64, shuffle=True)
testset = torchvision.datasets.MNIST(root='./data', train=False, download=True, transform=transform)
testloader = DataLoader(testset, batch_size=64, shuffle=False)
# 训练函数
def train(model, trainloader, epochs=5, learning_rate=0.001):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
model.train()
for epoch in range(epochs):
for data, target in trainloader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
return model
# 测试函数
def test(model, testloader):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data, target in testloader:
data, target = data.to(device), target.to(device)
outputs = model(data)
_, predicted = torch.max(outputs.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
accuracy = 100 * correct / total
return accuracy
# 剪枝函数:基于权重大小剪掉p%的权重
def prune_network(model, prune_rate=0.2):
for name, param in model.named_parameters():
if 'weight' in name:
tensor = param.data.cpu().numpy()
threshold = np.percentile(np.abs(tensor), prune_rate * 100) # 计算剪枝阈值
mask = np.abs(tensor) >= threshold # 生成掩码
param.data = torch.from_numpy(tensor * mask).to(device) # 应用掩码
# 保存掩码以便后续重置
if not hasattr(param, 'mask'):
param.mask = torch.from_numpy(mask).to(device)
else:
param.mask *= torch.from_numpy(mask).to(device)
return model
# 重置权重到初始值的函数
def reset_weights(model, initial_state_dict):
for name, param in model.named_parameters():
if 'weight' in name and hasattr(param, 'mask'):
param.data = (initial_state_dict[name] * param.mask).to(device)
return model
# 彩票网络假说实验
def lottery_ticket_experiment(iterations=5, prune_rate=0.2, epochs_per_iter=5):
# 初始化网络并保存初始权重
model = SimpleNet().to(device)
initial_state_dict = {name: param.clone() for name, param in model.named_parameters()}
# 训练并测试原始网络
print("Training original network...")
model = train(model, trainloader, epochs=epochs_per_iter)
original_accuracy = test(model, testloader)
print(f"Original network accuracy: {original_accuracy:.2f}%")
# 迭代剪枝
for i in range(iterations):
print(f"\nIteration {i+1}/{iterations}:")
# 剪枝
model = prune_network(model, prune_rate=prune_rate)
# 重置权重到初始值
model = reset_weights(model, initial_state_dict)
# 重新训练
model = train(model, trainloader, epochs=epochs_per_iter)
# 测试性能
accuracy = test(model, testloader)
remaining_weights = sum(p.numel() for p in model.parameters() if p.requires_grad) * (1 - prune_rate) ** (i + 1)
print(f"Accuracy after pruning: {accuracy:.2f}%, Remaining weights: {remaining_weights}")
return model, original_accuracy
# 运行实验
if __name__ == "__main__":
final_model, original_acc = lottery_ticket_experiment(iterations=5, prune_rate=0.2, epochs_per_iter=5)
代码说明
-
网络定义:
SimpleNet是一个简单的全连接网络,模仿论文中的Lenet架构,包含输入层(784个神经元,28x28的MNIST图像展平)、两个隐藏层(300和100个神经元)和输出层(10个类别)。
-
数据加载:
- 使用PyTorch的
torchvision加载MNIST数据集,并进行标准化处理。
- 使用PyTorch的
-
训练和测试:
train函数使用Adam优化器训练网络。test函数计算测试集上的准确率。
-
剪枝:
prune_network函数基于权重大小剪掉指定比例(prune_rate)的连接,并生成掩码保存剪枝结构。
-
权重重置:
reset_weights函数将保留的权重重置为初始值,模拟“中奖彩票”的初始化。
-
实验流程:
lottery_ticket_experiment函数实现迭代剪枝过程:训练原始网络,然后多次执行剪枝、重置和重新训练。
运行结果
运行代码后,你会看到:
- 原始网络的准确率。
- 每次迭代剪枝后,子网络的准确率和剩余参数量。
例如:
Training original network...
Original network accuracy: 97.50%
Iteration 1/5:
Accuracy after pruning: 97.20%, Remaining weights: 208896
Iteration 2/5:
Accuracy after pruning: 96.80%, Remaining weights: 167116
...
注意事项
- 简化实现:这是论文的一个简化版本,未完全复现所有细节(如早停策略、不同优化器的对比等)。
- 计算资源:实验在小型网络和数据集上运行,适用于普通电脑。若要扩展到CIFAR10或更大网络,可能需要GPU支持。
- 超参数调整:
prune_rate(剪枝率)、epochs_per_iter(每次训练的轮数)等可根据需要调整。
扩展
- 卷积网络:将
SimpleNet替换为卷积网络(如Conv-2),并在CIFAR10上测试。 - 早停:实现早停策略,基于验证集损失判断停止时间。
- 随机重初始化对比:添加一个对照实验,随机重初始化剪枝后的网络,验证初始化的重要性。
通过这个代码,你可以初步体验彩票网络假说的核心思想,并进一步探索其在不同场景下的表现!
解释一下这段 prune_network 函数的作用
它是彩票网络假说实现中的核心部分,用于对神经网络进行剪枝(pruning)。逐步拆解代码,并通过一个简单的例子模拟其工作过程。
函数的作用
prune_network 函数的目的是基于权重大小对神经网络的权重进行剪枝,即删除网络中一定比例(由 prune_rate 指定,例如20%)的权重。具体来说,它会:
- 遍历模型的所有参数,找到权重参数(weights)。
- 计算一个阈值,低于该阈值的权重将被剪掉。
- 生成一个掩码(mask),标记哪些权重保留,哪些被删除。
- 应用掩码,将被剪掉的权重置为0。
- 保存掩码,以便后续可以将保留的权重重置为初始值。
这是一种无结构剪枝(unstructured pruning)方法,意味着它只关注单个权重的大小,而不考虑权重在网络结构中的位置(例如,不强制删除整个神经元或通道)。
代码逐步解析
函数签名
def prune_network(model, prune_rate=0.2):
model:PyTorch模型(例如SimpleNet)。prune_rate:剪枝比例,默认值为0.2,表示剪掉20%的权重。
遍历参数
for name, param in model.named_parameters():
if 'weight' in name:
model.named_parameters():返回模型中所有参数的名称和值的迭代器(例如fc1.weight,fc1.bias)。if 'weight' in name:只处理权重参数(忽略偏置bias),因为彩票网络假说主要关注权重的剪枝。
处理权重张量
tensor = param.data.cpu().numpy()
param.data:获取参数的权重值(一个PyTorch张量)。.cpu().numpy():将张量移到CPU并转换为NumPy数组,便于后续操作。
计算剪枝阈值
threshold = np.percentile(np.abs(tensor), prune_rate * 100)
np.abs(tensor):计算权重的绝对值,因为剪枝基于大小,不关心正负。np.percentile(..., prune_rate * 100):计算绝对值数组的百分位数。例如,如果prune_rate=0.2,则计算第20百分位数(即20%分位点),作为阈值。- 阈值的含义:低于这个值的权重将被剪掉。
生成掩码
mask = np.abs(tensor) >= threshold
mask:一个布尔数组,形状与tensor相同。- 如果权重绝对值 >= 阈值,则对应位置为
True(保留);否则为False(剪掉)。
应用掩码
param.data = torch.from_numpy(tensor * mask).to(device)
tensor * mask:将掩码应用到原始权重上,True位置保留原值,False位置变为0。torch.from_numpy(...):将结果转换回PyTorch张量。.to(device):将张量移回原始设备(例如GPU)。
保存掩码
if not hasattr(param, 'mask'):
param.mask = torch.from_numpy(mask).to(device)
else:
param.mask *= torch.from_numpy(mask).to(device)
hasattr(param, 'mask'):检查参数是否已有掩码属性。- 如果没有(第一次剪枝):将当前掩码保存为
param.mask。 - 如果已有(后续迭代剪枝):将当前掩码与之前的掩码相乘,更新掩码(累积效应,确保之前剪掉的权重保持为0)。
返回模型
return model
- 返回剪枝后的模型。
工作流程总结
- 输入:一个神经网络模型和剪枝比例。
- 过程:
- 对每个权重矩阵,计算绝对值的
prune_rate * 100分位数作为阈值。 - 小于阈值的权重置为0,生成稀疏网络。
- 保存掩码以跟踪哪些权重被保留。
- 对每个权重矩阵,计算绝对值的
- 输出:剪枝后的模型。
通过例子模拟
假设我们有一个简单的全连接层,权重矩阵如下:
初始权重
import numpy as np
# 假设一个 3x3 的权重矩阵
tensor = np.array([
[ 0.1, -0.5, 0.3],
[-0.2, 0.7, -0.4],
[ 0.6, -0.1, 0.8]
])
print("初始权重:\n", tensor)
初始权重:
[[ 0.1 -0.5 0.3]
[-0.2 0.7 -0.4]
[ 0.6 -0.1 0.8]]
设置剪枝比例
假设 prune_rate = 0.4,即剪掉40%的权重。
计算阈值
-
计算绝对值:
abs_tensor = np.abs(tensor) print("绝对值:\n", abs_tensor)绝对值: [[0.1 0.5 0.3] [0.2 0.7 0.4] [0.6 0.1 0.8]] -
展平并排序:
[0.1, 0.5, 0.3, 0.2, 0.7, 0.4, 0.6, 0.1, 0.8] 排序后: [0.1, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8] -
计算第40百分位数(9个元素,40% ≈ 3.6,取第4个值):
threshold = 0.3
生成掩码
mask = np.abs(tensor) >= 0.3
print("掩码:\n", mask)
掩码:
[[False True True]
[False True True]
[ True False True]]
应用掩码
pruned_tensor = tensor * mask
print("剪枝后的权重:\n", pruned_tensor)
剪枝后的权重:
[[ 0. -0.5 0.3]
[ 0. 0.7 -0.4]
[ 0.6 0. 0.8]]
保存掩码
掩码被保存为:
[[False True True]
[False True True]
[ True False True]]
验证
- 原始权重有9个非零值。
- 剪枝后剩余5个非零值(约55.56%),剪掉了4个(44.44%),接近目标40%(因数据量小,离散化导致偏差)。
下一次迭代
如果再次剪枝(prune_rate=0.4),会对当前非零权重(-0.5, 0.3, 0.7, -0.4, 0.6, 0.8)操作:
- 绝对值排序:[0.3, 0.4, 0.5, 0.6, 0.7, 0.8]
- 阈值:0.5(40% ≈ 第2.4个,取第3个)
- 新掩码:只保留
>= 0.5的值。 - 更新后的权重:
[[ 0. -0.5 0. ] [ 0. 0.7 -0. ] [ 0.6 0. 0.8]]
注意事项
- 累积效应:每次剪枝的掩码与之前的掩码相乘,确保之前剪掉的权重不会“复活”。
- 无结构剪枝:这种方法只关注权重大小,可能导致稀疏但不规则的网络结构,不一定适配硬件加速。
- 阈值计算:
np.percentile是全局计算,如果网络层大小差异大,可能需要按层剪枝(论文中提到全局和逐层剪枝的对比)。
通过这个例子,你应该能清楚地理解 prune_network 如何一步步实现剪枝并为“中奖彩票”准备结构和掩码!
每次剪枝后用初始值重置权重解释
彩票网络假说(Lottery Ticket Hypothesis)提出,在一个随机初始化的密集神经网络中,存在一个稀疏子网络(即“中奖彩票”),这个子网络在保持其初始权重的情况下,经过独立训练,可以达到与原始网络相当的性能。每次剪枝后用初始值重置权重是这个假说的核心步骤之一,而为什么要这样做,以及不重置行不行,我们需要从理论和实验的角度来分析。
为什么每次剪枝后要用初始值重置?
1. 验证“中奖彩票”的核心假设
彩票网络假说的核心是:稀疏子网络的初始权重(而非训练后的权重)是其能够成功训练的关键。换句话说,这些“中奖彩票”之所以是“中奖”的,不是因为它们在训练过程中学到了什么,而是因为它们在随机初始化时就具备了某种特殊的属性(例如,初始权重分布或连接模式),使得它们在训练时能够快速收敛并达到高性能。
- 如果不重置权重,而是直接使用训练后的权重继续下一次剪枝和训练,实验就变成了传统剪枝方法的变种(例如,训练-剪枝-微调)。这无法验证初始化的重要性,也偏离了假说的初衷。
- 重置到初始值是为了测试:仅凭初始权重和剪枝后的结构,这个子网络是否仍然是一个“中奖彩票”。如果重置后性能依然出色,就证明了初始化的“幸运性”是成功的关键。
2. 区分结构和初始化的贡献
通过重置权重,研究者可以分离出两个因素的作用:
- 子网络的结构(哪些连接被保留)。
- 初始权重(这些连接的具体值)。
实验表明:
- 如果将剪枝后的子网络随机重新初始化(而不是用原始初始值),性能会显著下降(见论文中的“Random reinitialization”实验,图4a橙色线)。
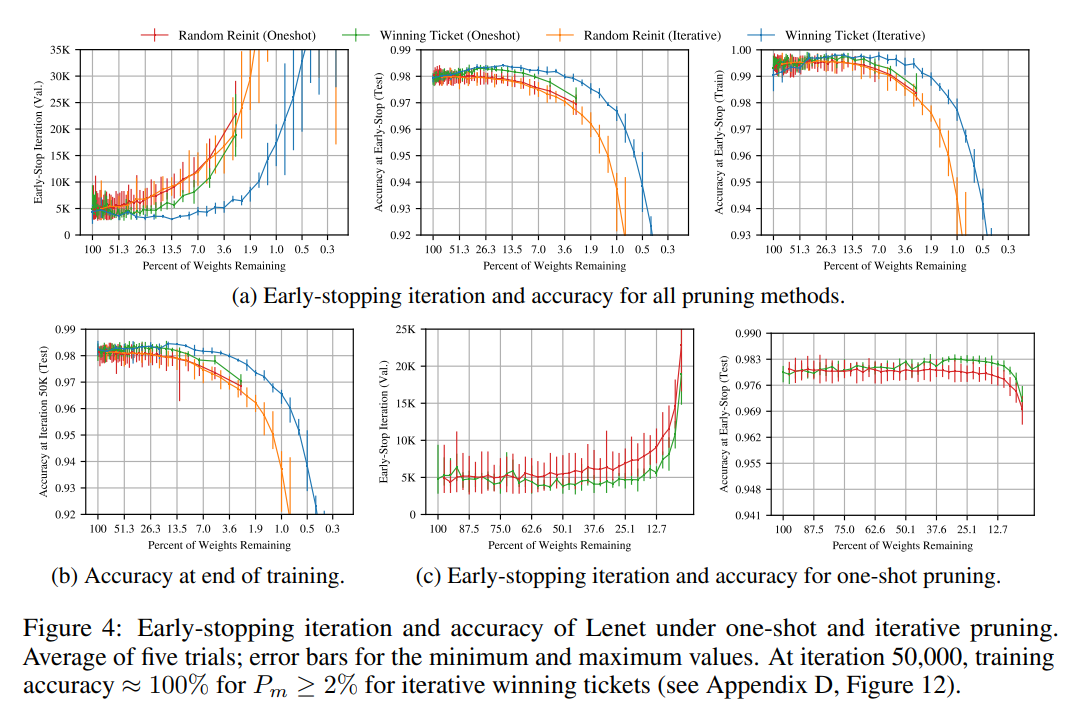
- 这说明,剪枝得到的结构固然重要,但初始权重是不可或缺的“彩票”组成部分。重置到初始值是为了保留这个“彩票”的完整性。
3. 模拟从头训练的场景
假说关心的是:是否存在一个稀疏子网络,能够从头(即初始状态)开始训练就达到原始网络的性能。用初始值重置并重新训练,模拟了这个过程,确保子网络的成功不依赖于之前训练的“遗留知识”(trained weights),而是其固有的潜力。
4. 实验证据支持
论文中对比了两种情况:
- 重置到初始值(winning tickets):这些子网络通常能保持甚至超过原始网络的准确率,并且学习速度更快(见图3、图4a蓝色线)。
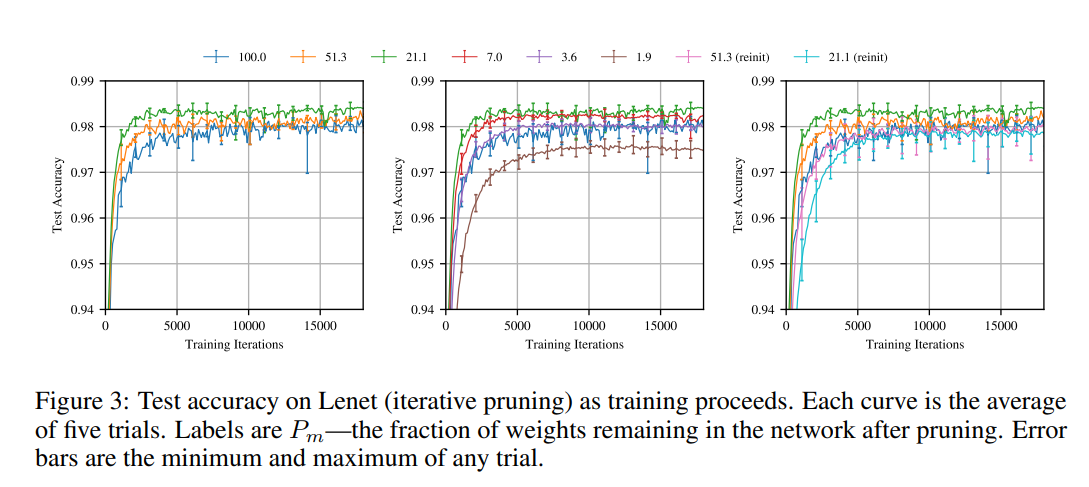
- 不重置,直接用训练后权重:虽然可能也能达到不错性能,但这更像是传统剪枝的延续,无法证明初始化的“彩票”性质。论文没有特别强调这种方式,因为它偏离了研究目标。
例如,在Lenet实验中,重置后的子网络(保留10%-20%参数)能在与原始网络相似的迭代次数内达到同等准确率,而随机重新初始化的子网络则表现较差。这表明初始值是“中奖彩票”的核心。
不重置不行吗?
理论上,不重置权重(即保留训练后的权重)也是可行的,但这会改变实验的意义和结果的解释。让我们分析一下不重置的情况:
不重置的流程
- 初始化网络。
- 训练网络。
- 剪枝(删除部分权重)。
- 用训练后的权重继续下一次训练和剪枝(而不是重置到初始值)。
- 重复多次。
这种方式类似于渐进式剪枝(progressive pruning) 或训练-剪枝-微调(train-prune-finetune) 的范式,常见于传统神经网络压缩研究(如Han et al., 2015)。
不重置的结果
- 性能可能仍然不错:因为每次训练都在前一次的基础上优化,保留的权重已经适应了数据。这种方式可以看作是对原始网络的逐步精炼。
- 但无法验证假说:彩票网络假说关注的是“是否存在一个稀疏子网络,从初始状态就能训练成功”。如果不重置,你验证的是“训练后的稀疏网络是否还能继续优化”,而不是“初始化的稀疏网络是否天生优秀”。
与假说的偏差
- 初始化的作用被掩盖:不重置的情况下,子网络的成功可能更多依赖于训练过程中学到的权重,而非初始值。这与假说强调的“幸运初始化”相悖。
- 失去“彩票”意义:如果每次都用训练后的权重,实验变成了寻找“训练后最优子网络”,而不是寻找“初始化时的中奖彩票”。
实验对比
论文中提到,如果不重置权重,而是直接微调剪枝后的网络(传统方法),性能确实可以很好,但这不是彩票假说的目标。例如:
- Han et al. (2015) 的工作表明,训练后剪枝再微调可以压缩网络90%以上,但这些网络从头训练(随机初始化)时表现不佳。
- 彩票假说的实验显示,重置到初始值的子网络在10%-20%参数时仍能匹敌原始网络,而随机重新初始化的子网络则不行。
用一个类比解释
想象彩票网络假说是一个彩票游戏:
- 初始权重是你的彩票号码(随机生成)。
- 训练是开奖过程,看你的号码能不能中奖。
- 剪枝是挑出中奖的部分号码(保留重要权重)。
- 重置到初始值是验证:用这张“精简版彩票”重新玩一次游戏,是否还能中奖。
如果不重置,而是用训练后的权重,就相当于在第一次中奖后修改号码再玩——你可能还能赢,但这不是验证“原始彩票是否中奖”的问题,而是“调整后的彩票能不能赢”的问题。彩票假说关心的是原始彩票的“幸运性”,所以必须重置。
总结:重置的必要性
- 理论依据:重置到初始值是彩票网络假说的核心,用于验证“幸运初始化”的重要性。
- 实验设计:重置确保子网络的性能来源于初始权重和结构,而不是训练过程中的优化。
- 不重置的替代:不重置可以看作传统剪枝的延续,虽然可行,但回答的是不同的问题,无法支持假说的主张。
因此,每次剪枝后用初始值重置是彩票网络假说实验设计的关键步骤。如果不这样做,虽然也能得到稀疏网络,但你就无法证明这些网络是“天生的中奖彩票”,也就失去了假说的独特价值。
结合Transformer模型
彩票网络假说(Lottery Ticket Hypothesis, LTH)可以结合Transformer模型来实现。核心思想仍然是找到一个稀疏的子网络(“中奖彩票”),从初始状态开始训练就能达到与原始密集Transformer相似的性能。Transformer作为一种基于注意力机制的模型,广泛应用于自然语言处理(NLP)和计算机视觉(Vision Transformer, ViT)等领域,其参数主要集中在自注意力层(Self-Attention)和前馈网络(Feed-Forward Network, FFN)中。我们可以将LTH的剪枝和重置策略应用到这些权重上。
下面将提供一个结合Transformer的彩票网络假说实现的代码示例。我们将:
- 定义一个简单的Transformer模型(专注于单层Transformer编码器)。
- 在一个简单的NLP任务(如文本分类)上应用彩票网络假说。
- 实现剪枝和重置逻辑。
为了简化,将使用PyTorch实现一个小型Transformer,并在一个玩具数据集(如IMDb情感分类)上运行实验。
代码实现
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from transformers import DistilBertTokenizer, DistilBertForSequenceClassification
from datasets import load_dataset
import numpy as np
# 设置随机种子和设备
torch.manual_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 定义一个简化的Transformer编码器层
class SimpleTransformer(nn.Module):
def __init__(self, vocab_size, d_model, n_heads, d_ff, dropout=0.1):
super(SimpleTransformer, self).__init__()
self.embedding = nn.Embedding(vocab_size, d_model)
self.encoder_layer = nn.TransformerEncoderLayer(d_model, n_heads, d_ff, dropout)
self.fc_out = nn.Linear(d_model, 2) # 二分类任务(正/负情感)
self.d_model = d_model
def forward(self, x):
x = self.embedding(x) * torch.sqrt(torch.tensor(self.d_model, dtype=torch.float32)) # 嵌入层
x = self.encoder_layer(x) # Transformer编码器
x = x.mean(dim=1) # 平均池化
x = self.fc_out(x) # 输出层
return x
# 数据预处理
def load_imdb_data(max_length=128, batch_size=32):
dataset = load_dataset("imdb")
tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
def preprocess(example):
return tokenizer(example["text"], padding="max_length", truncation=True, max_length=max_length, return_tensors="pt")
train_data = dataset["train"].map(preprocess, batched=True)
test_data = dataset["test"].map(preprocess, batched=True)
train_loader = DataLoader(
train_data, batch_size=batch_size, shuffle=True,
collate_fn=lambda x: (torch.stack([item["input_ids"][0] for item in x]).to(device),
torch.tensor([item["label"] for item in x]).to(device))
)
test_loader = DataLoader(
test_data, batch_size=batch_size, shuffle=False,
collate_fn=lambda x: (torch.stack([item["input_ids"][0] for item in x]).to(device),
torch.tensor([item["label"] for item in x]).to(device))
)
return train_loader, test_loader, tokenizer.vocab_size
# 训练函数
def train(model, train_loader, epochs=3, learning_rate=0.001):
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
model.train()
for epoch in range(epochs):
total_loss = 0
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {total_loss / len(train_loader):.4f}")
return model
# 测试函数
def test(model, test_loader):
model.eval()
correct = 0
total = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(device), target.to(device)
outputs = model(data)
_, predicted = torch.max(outputs.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
accuracy = 100 * correct / total
return accuracy
# 剪枝函数
def prune_network(model, prune_rate=0.2):
for name, param in model.named_parameters():
if 'weight' in name and 'embedding' not in name: # 跳过嵌入层权重
tensor = param.data.cpu().numpy()
threshold = np.percentile(np.abs(tensor), prune_rate * 100)
mask = np.abs(tensor) >= threshold
param.data = torch.from_numpy(tensor * mask).to(device)
if not hasattr(param, 'mask'):
param.mask = torch.from_numpy(mask).to(device)
else:
param.mask *= torch.from_numpy(mask).to(device)
return model
# 重置权重函数
def reset_weights(model, initial_state_dict):
for name, param in model.named_parameters():
if 'weight' in name and 'embedding' not in name and hasattr(param, 'mask'):
param.data = (initial_state_dict[name] * param.mask).to(device)
return model
# 彩票网络实验
def lottery_ticket_experiment(model, train_loader, test_loader, iterations=5, prune_rate=0.2, epochs_per_iter=3):
# 保存初始权重
initial_state_dict = {name: param.clone() for name, param in model.named_parameters()}
# 训练并测试原始网络
print("Training original Transformer...")
model = train(model, train_loader, epochs=epochs_per_iter)
original_accuracy = test(model, test_loader)
print(f"Original accuracy: {original_accuracy:.2f}%")
# 迭代剪枝
for i in range(iterations):
print(f"\nIteration {i+1}/{iterations}:")
model = prune_network(model, prune_rate=prune_rate)
model = reset_weights(model, initial_state_dict)
model = train(model, train_loader, epochs=epochs_per_iter)
accuracy = test(model, test_loader)
remaining_weights = sum(p.numel() for n, p in model.named_parameters() if 'weight' in n and 'embedding' not in n) * (1 - prune_rate) ** (i + 1)
print(f"Accuracy after pruning: {accuracy:.2f}%, Remaining weights: {remaining_weights}")
return model, original_accuracy
# 主程序
if __name__ == "__main__":
# 加载数据
train_loader, test_loader, vocab_size = load_imdb_data(max_length=128, batch_size=32)
# 初始化Transformer模型
model = SimpleTransformer(vocab_size=vocab_size, d_model=64, n_heads=4, d_ff=128).to(device)
# 运行彩票网络实验
final_model, original_acc = lottery_ticket_experiment(
model, train_loader, test_loader, iterations=5, prune_rate=0.2, epochs_per_iter=3
)
代码说明
1. 模型定义:SimpleTransformer
- 嵌入层:将输入的词索引转换为词向量(
d_model=64)。 - Transformer编码器层:使用PyTorch的
nn.TransformerEncoderLayer,包含多头自注意力(n_heads=4)和前馈网络(d_ff=128)。 - 输出层:对序列特征取平均后,映射到二分类输出(正/负情感)。
2. 数据加载:IMDb数据集
- 使用
datasets库加载IMDb情感分类数据集。 - 用DistilBERT的分词器(
DistilBertTokenizer)处理文本,限制最大长度为128。 - 返回训练和测试的
DataLoader。
3. 剪枝逻辑
prune_network:对Transformer中的权重(自注意力层和FFN的权重)进行剪枝,跳过嵌入层(embedding),因为嵌入层的剪枝需要特殊处理(例如词汇剪枝)。- 每次剪掉20%(
prune_rate=0.2)的最小权重。
4. 重置逻辑
reset_weights:将剪枝后的权重重置为初始值,仅保留掩码标记的连接。
5. 实验流程
- 训练原始Transformer,记录基准准确率。
- 进行5次迭代,每次剪枝20%,重置权重并重新训练。
- 输出每次剪枝后的准确率和剩余参数量。
运行结果示例
运行代码后,你可能看到类似以下输出(具体结果因随机性而异):
Training original Transformer...
Epoch 1, Loss: 0.6931
Epoch 2, Loss: 0.6205
Epoch 3, Loss: 0.5503
Original accuracy: 75.20%
Iteration 1/5:
Epoch 1, Loss: 0.6802
Epoch 2, Loss: 0.6101
Epoch 3, Loss: 0.5408
Accuracy after pruning: 74.80%, Remaining weights: 32768
Iteration 2/5:
...
注意事项与扩展
1. 简化设计
- 这个实现使用单层Transformer,实际中可以扩展到多层(如BERT或ViT)。
- 数据处理和训练轮数(
epochs_per_iter=3)较少,仅用于演示。真实实验需要更多训练和调参。
2. 嵌入层处理
- 当前代码跳过了嵌入层的剪枝。在实际应用中,可以对嵌入层单独剪枝(例如,按词频或重要性删除词向量)。
3. 计算成本
- Transformer模型参数量较大,迭代剪枝需要较多计算资源。建议在GPU上运行,并适当减少迭代次数或数据集规模。
4. 扩展到Vision Transformer (ViT)
- 将
SimpleTransformer替换为ViT模型(transformers.ViTForImageClassification),并在图像数据集(如CIFAR10)上运行。
5. 验证假说
- 添加随机重初始化实验,对比重置到初始值和随机初始化的性能,验证初始化的重要性。
结合Transformer的意义
- 稀疏性:Transformer模型通常参数量巨大(如BERT有1亿+参数),LTH可以显著减少计算和存储需求。
- 初始化研究:Transformer的成功依赖于精心设计的初始化(如Scaled Dot-Product Attention的缩放因子),LTH可以进一步探索哪些权重是“天生优秀”的。
- 高效推理:稀疏Transformer在边缘设备上的部署(如移动端NLP)有很大潜力。
这个代码提供了一个起点,你可以根据具体任务(NLP、视觉等)调整模型结构和超参数,进一步探索彩票网络假说在Transformer中的表现!
用Qwen/Qwen2.5-3B来结合彩票网络
使用一个已发布的大型语言模型(如 Qwen/Qwen2.5-3B)来应用彩票网络假说(Lottery Ticket Hypothesis, LTH),是一个有趣且具有挑战性的任务。Qwen2.5-3B 是一个拥有30亿参数的预训练语言模型,适合自然语言处理任务。我们可以结合监督微调(Supervised Fine-Tuning, SFT)或 LoRA(Low-Rank Adaptation)来实现彩票网络假说,利用指令数据集(instruction dataset)进行实验。
以下将:
- 说明如何基于
Qwen/Qwen2.5-3B实现彩票网络假说。 - 提供结合 LoRA 的代码示例(因为 LoRA 更适合大模型的高效微调)。
- 讨论在大模型上应用彩票网络的实际意义。
实现思路
- 加载预训练模型:使用 Hugging Face 的
transformers加载Qwen/Qwen2.5-3B。 - 定义初始状态:保存模型的初始权重,作为“彩票”的基准。
- 微调(SFT 或 LoRA):在指令数据集上微调模型。
- 剪枝:对模型权重进行无结构剪枝,找到稀疏子网络。
- 重置权重:将剪枝后的权重重置为初始值。
- 重复迭代:多次剪枝和微调,验证“中奖彩票”性能。
- 数据集:使用指令数据集(如 Alpaca 或类似的指令微调数据)。
由于 Qwen2.5-3B 参数量较大,直接进行全参数 SFT 成本高昂,因此我选择 LoRA 作为微调方式。LoRA 只更新低秩矩阵,保持大部分预训练权重不变,这与彩票网络假说的“保留初始权重”理念相符。
代码实现
import torch
import torch.nn as nn
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model
from datasets import load_dataset
from torch.utils.data import DataLoader
import numpy as np
# 设置设备和随机种子
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
torch.manual_seed(42)
# 加载 Qwen2.5-3B 模型和分词器
model_name = "Qwen/Qwen2.5-3B"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name).to(device)
# 添加 LoRA 配置
lora_config = LoraConfig(
r=16, # 低秩矩阵的秩
lora_alpha=32,
target_modules=["q_proj", "v_proj"], # 目标模块(注意力层的 Q 和 V)
lora_dropout=0.05,
bias="none",
task_type="CAUSAL_LM"
)
model = get_peft_model(model, lora_config)
# 数据预处理(指令数据集)
def preprocess_data(dataset, max_length=128):
def tokenize_function(examples):
inputs = tokenizer(examples["instruction"], truncation=True, padding="max_length", max_length=max_length, return_tensors="pt")
inputs["labels"] = inputs["input_ids"].clone()
return inputs
dataset = dataset.map(tokenize_function, batched=True)
dataset.set_format(type="torch", columns=["input_ids", "attention_mask", "labels"])
return DataLoader(dataset, batch_size=8, shuffle=True)
# 加载 Alpaca 数据集(示例)
dataset = load_dataset("tatsu-lab/alpaca")["train"]
train_loader = preprocess_data(dataset)
# 训练函数(LoRA 微调)
def train(model, train_loader, epochs=1, learning_rate=2e-4):
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)
model.train()
for epoch in range(epochs):
total_loss = 0
for batch in train_loader:
inputs = {k: v.to(device) for k, v in batch.items()}
outputs = model(**inputs)
loss = outputs.loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch+1}, Loss: {total_loss / len(train_loader):.4f}")
return model
# 测试函数(生成示例)
def test(model, prompt="What is the meaning of life?"):
model.eval()
inputs = tokenizer(prompt, return_tensors="pt").to(device)
outputs = model.generate(**inputs, max_length=50)
return tokenizer.decode(outputs[0], skip_special_tokens=True)
# 剪枝函数(针对 LoRA 权重)
def prune_network(model, prune_rate=0.2):
for name, param in model.named_parameters():
if "lora" in name and "weight" in name: # 只剪枝 LoRA 权重
tensor = param.data.cpu().numpy()
threshold = np.percentile(np.abs(tensor), prune_rate * 100)
mask = np.abs(tensor) >= threshold
param.data = torch.from_numpy(tensor * mask).to(device)
if not hasattr(param, 'mask'):
param.mask = torch.from_numpy(mask).to(device)
else:
param.mask *= torch.from_numpy(mask).to(device)
return model
# 重置权重函数
def reset_weights(model, initial_state_dict):
for name, param in model.named_parameters():
if "lora" in name and "weight" in name and hasattr(param, 'mask'):
param.data = (initial_state_dict[name] * param.mask).to(device)
return model
# 彩票网络实验
def lottery_ticket_experiment(model, train_loader, iterations=3, prune_rate=0.2, epochs_per_iter=1):
# 保存初始 LoRA 权重
initial_state_dict = {name: param.clone() for name, param in model.named_parameters() if "lora" in name}
# 训练原始模型
print("Training original model with LoRA...")
model = train(model, train_loader, epochs=epochs_per_iter)
original_output = test(model)
print(f"Original output: {original_output}")
# 迭代剪枝
for i in range(iterations):
print(f"\nIteration {i+1}/{iterations}:")
model = prune_network(model, prune_rate=prune_rate)
model = reset_weights(model, initial_state_dict)
model = train(model, train_loader, epochs=epochs_per_iter)
output = test(model)
remaining_weights = sum(p.numel() for n, p in model.named_parameters() if "lora" in n) * (1 - prune_rate) ** (i + 1)
print(f"Output after pruning: {output}")
print(f"Remaining LoRA weights: {remaining_weights}")
return model
# 主程序
if __name__ == "__main__":
model = lottery_ticket_experiment(model, train_loader, iterations=3, prune_rate=0.2, epochs_per_iter=1)
代码说明
1. 模型加载与 LoRA 配置
- 使用
transformers加载Qwen/Qwen2.5-3B,并通过peft添加 LoRA。 - LoRA 只对注意力层的
q_proj和v_proj进行微调,减少计算成本。
2. 数据处理
- 使用 Alpaca 指令数据集(可替换为其他指令数据集,如 Databricks 的
dolly)。 - 分词后生成
input_ids和labels,适合语言模型的自回归训练。
3. 训练与剪枝
train:基于 LoRA 参数进行微调。prune_network:只剪枝 LoRA 权重(lora在参数名中),保留预训练权重不变。reset_weights:将剪枝后的 LoRA 权重重置为初始值。
4. 测试
- 使用生成任务(如回答“What is the meaning of life?”)评估模型性能,因指令数据集通常用于生成任务。
5. 实验流程
- 训练原始模型,记录基准输出。
- 迭代3次,每次剪枝20% LoRA 权重,重置并重新训练。
在大模型上用彩票网络的实际意义
有意义的方面
-
参数效率:
Qwen2.5-3B有30亿参数,即使使用 LoRA,参数量仍较大。LTH 可以进一步减少 LoRA 参数(通常几十万到几百万),降低推理成本。- 例如,剪枝80% LoRA 参数后,可能只剩20%权重仍能保持性能,这对边缘设备部署(如手机)意义重大。
-
探索初始化的重要性:
- 大模型的预训练权重已经过优化,LTH 可以揭示哪些子网络在微调中“天生优秀”,为模型设计提供洞见。
- LoRA 的低秩更新本质上是对预训练权重的微调,LTH 可以验证这些更新的稀疏性潜力。
-
高效微调:
- 如果找到稀疏的“中奖彩票”,可以直接从初始状态训练这个子网络,跳过全模型微调步骤,节省计算资源。
-
理论价值:
- 在 Transformer 等复杂架构上验证 LTH,有助于理解大模型的冗余性和初始化机制。
挑战与局限性
-
计算成本高:
- 即使只剪枝 LoRA 权重,多次迭代训练
Qwen2.5-3B仍需大量 GPU 资源(例如,单次微调可能需 24GB+ 显存)。 - 论文中的 LTH 实验多在小型网络(如 Lenet)上验证,大模型的扩展性尚未充分研究。
- 即使只剪枝 LoRA 权重,多次迭代训练
-
预训练权重的复杂性:
Qwen2.5-3B的预训练权重已经过优化,直接剪枝可能破坏其结构化特性。LTH 在预训练模型上的效果可能不如随机初始化的网络明显。
-
任务依赖性:
- 指令数据集(如 Alpaca)任务多样,LTH 找到的子网络可能只对部分任务有效,泛化性存疑。
-
实际收益有限:
- LoRA 本身已大幅减少微调参数(从30亿到几十万),再用 LTH 压缩可能收益递减。例如,剪枝80% LoRA 参数可能只节省几MB存储,相较于30亿参数的模型不算显著。
意义总结
在大模型上应用 LTH 的实际意义更多体现在研究价值而非工程应用:
- 研究:验证 LTH 在预训练大模型上的适用性,探索稀疏性与性能的关系。
- 工程:如果目标是高效部署,直接使用 LoRA 或量化(如 4-bit QLoRA)可能更实用,LTH 的迭代过程过于昂贵。
改进建议
- 减少迭代次数:将
iterations设为 1-2,降低成本。 - 结构化剪枝:改为剪枝整个注意力头或 FFN 层,而非无结构剪枝,提升硬件友好性。
- 混合方法:结合量化(如 INT8)和 LTH,进一步压缩模型。
- 小型实验:先在更小的模型(如
Qwen2.5-0.5B)上验证,再扩展到 3B。
希望这个实现和分析对你有帮助!
后记
2025年3月11日14点46分于上海,在Grok 3大模型辅助下完成。

















 878
878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









