









ByT5:迈向无标记未来的字节级预训练模型
近年来,自然语言处理(NLP)领域取得了显著的进展,尤其是基于Transformer架构的预训练模型,如T5(Text-to-Text Transfer Transformer),已经成为许多任务的标准工具。然而,尽管T5在处理基于词或子词(subword)的标记化文本时表现出色,它仍然面临一些局限性,例如对噪声文本的鲁棒性不足、对新语言的适应性有限等。为了解决这些问题,Google Research 团队推出了 ByT5,一种基于字节(byte)的无标记预训练模型,旨在简化 NLP 管道并提升模型的通用性和鲁棒性。本文将为您介绍 ByT5 的核心思想、与 T5 的区别以及它的独特优势。
下文中图片来自于原paper: ByT5: Towards a Token-Free Future with Pre-trained Byte-to-Byte Models
T5 简介:文本到文本的统一框架
在深入探讨 ByT5 之前,我们先简单回顾一下 T5。T5 由 Raffel 等人于 2020 年提出,是一种基于 Transformer 的编码器-解码器模型。它的核心创新在于将所有 NLP 任务统一为“文本到文本”的格式。无论是分类、翻译、摘要生成还是问答,T5 都将输入和输出视为文本序列,通过预训练和微调来解决各种任务。
T5 的预训练采用“跨度损坏”(span corruption)目标,即在输入文本中随机掩盖一些连续的标记(token),然后要求模型预测这些被掩盖的部分。这种方法依赖于 SentencePiece 等子词标记器,将原始文本分解为词汇表中的子词单元。T5 的成功在于其通用性和大规模预训练数据(例如 C4 语料库),但它的标记化依赖也带来了一些问题,比如对拼写错误敏感、对不在词汇表中的语言支持不足等。
ByT5 的诞生:从子词到字节
ByT5(Byte-to-Byte T5)是 T5 的一个演进版本,由 Xue 等人于 2022 年提出并发表在《Transactions of the Association for Computational Linguistics》上。它的核心理念是摒弃传统的标记化步骤,直接在原始文本的 UTF-8 字节序列上操作。这种“无标记”(token-free)的设计带来了以下几个显著优势:
-
语言无关性
传统的子词模型需要为每种语言或语料构建特定的词汇表,而 ByT5 只需处理 256 个字节值(UTF-8 的基本单位),即可覆盖所有语言和字符。这意味着 ByT5 无需额外的预处理就能处理任何语言的文本,极大地降低了技术债务。 -
对噪声的鲁棒性
子词标记器对拼写错误、变体(如大小写变化)或形态变化非常敏感。例如,“doghouse”可能被拆分为“dog”和“house”,而“d0ghouse”可能会变成未知标记<UNK>。ByT5 直接操作字节序列,能够更好地捕捉字符级别的模式,因此在面对噪声文本(如社交媒体上的非正式语言)时表现更稳定。 -
简化管道
传统的 NLP 模型需要复杂的文本预处理流程,包括分词、归一化等步骤,这些步骤往往容易出错且难以维护。ByT5 通过直接使用原始字节输入,消除了这些步骤,实现了真正的端到端学习。 -
参数效率
子词模型通常需要一个庞大的词汇表(例如 mT5 的词汇表有数十万 token),这会导致嵌入矩阵占用大量参数。相比之下,ByT5 只需 256 个字节嵌入,外加少量特殊标记(如填充和句子结束标记),将参数从词汇表转移到 Transformer 层中,从而提升模型的泛化能力。
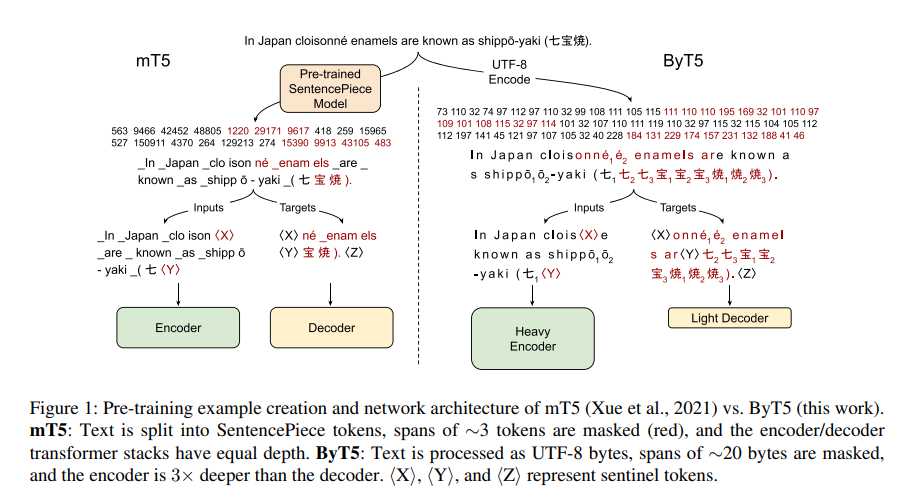
ByT5 的设计细节
ByT5 在 T5 的基础上进行了几项关键调整,以适应字节级处理:
-
输入与嵌入
ByT5 直接将文本作为 UTF-8 字节序列输入,嵌入层仅需处理 256 个基本字节值,外加 3 个特殊标记(总共 259 个 ID)。这与 mT5(T5 的多语言版本)依赖 SentencePiece 词汇表形成了鲜明对比。 -
预训练任务调整
ByT5 沿用 T5 的“跨度损坏”预训练目标,但掩盖的跨度从平均 3 个子词调整为平均 20 个字节。这是因为字节序列比子词序列更长,短跨度掩盖任务对字节模型来说过于简单。研究表明,20 个字节的跨度在分类和生成任务中表现最佳。 -
编码器-解码器比例优化
与 T5 和 mT5 的平衡架构(编码器和解码器层数相等)不同,ByT5 将编码器深度设置为解码器的 3 倍。例如,在 ByT5-Large 中,编码器有 36 层,而解码器只有 12 层。研究发现,这种“重编码器”设计能更好地处理字节序列的复杂模式,同时在生成任务中保持高质量输出。 -
模型规模
ByT5 提供了与 T5 相同的五种尺寸(Small、Base、Large、XL、XXL),并通过调整隐藏层大小(d_model)和前馈层维度(d_ff)与 mT5 保持参数匹配。例如,ByT5-Large 和 mT5-Large 都有 12.3 亿参数,但 ByT5 将参数更多分配到 Transformer 层而非词汇表。
ByT5 的性能与权衡
ByT5 在多个基准测试中表现出色,尤其是在以下场景中超越 mT5:
- 小模型尺寸:在 Small 和 Base 尺寸下,ByT5 在 GLUE 和 SuperGLUE 等英语分类任务中胜出,可能是因为其密集参数(dense parameters)利用率更高。
- 生成任务:在 XSum(摘要生成)、TweetQA(问答)和 DROP(阅读理解)等任务中,ByT5 始终优于 mT5,尤其是在需要处理非正式或噪声文本时。
- 多语言任务:在 XTREME 基准的跨语言任务中,ByT5 在有语言内标签的设置下表现更好,展现了其语言无关性。
- 噪声鲁棒性:实验表明,ByT5 在面对字符丢弃、重复、大小写变化等合成噪声时,性能下降远小于 mT5。
然而,这种字节级方法也有代价。由于字节序列比子词序列长(mT5 的平均压缩率为 4.1 字节/标记),ByT5 的计算成本更高:
- 预训练时间:ByT5 的预训练速度约为 mT5 的 75%,FLOPs 增加约 20%。
- 推理速度:在长序列任务(如 XNLI)中,ByT5 的推理速度可能比 mT5 慢 6-10 倍,但在短输入任务(如单词级任务)中差距较小。
ByT5 的意义与未来
ByT5 的推出标志着 NLP 向“无标记未来”迈出了重要一步。它不仅简化了系统设计,还在数据效率上展现潜力——尽管它只在 1/4 的文本数据上预训练,却能与 mT5 竞争甚至超越。这表明字节级模型可能更擅长从有限数据中学习。
未来,ByT5 的发展方向包括优化推理速度(例如通过局部注意力或稀疏计算)以及在更多任务上的验证(如机器翻译和词相似性任务)。与此同时,随着数字文本的多样性和噪声性不断增加,ByT5 的鲁棒性和通用性可能使其成为下一代 NLP 模型的基石。
总结
ByT5 是对 T5 的重要补充和创新。通过从子词转向字节,ByT5 消除了标记化的限制,增强了对噪声和多语言文本的处理能力。尽管它在计算成本上有所增加,但其在任务性能、简化和数据效率上的优势使其成为值得关注的模型。如果您对 NLP 的未来感兴趣,不妨关注 ByT5 的开源代码(https://github.com/google-research/byt5)和相关研究,探索这一字节级革命的潜力!
UTF-8介绍
UTF-8 是什么?它如何表示不同的语言内容?
UTF-8(全称 Unicode Transformation Format - 8-bit,即 8 位 Unicode 转换格式)是一种广泛使用的字符编码方案,旨在将 Unicode 字符集中的所有字符以高效、可变长度的方式编码为字节序列。它由 Ken Thompson 和 Rob Pike 于 1992 年设计,现已成为互联网和现代计算中的标准编码格式,例如 HTML、JSON 和许多编程语言都默认使用 UTF-8。
UTF-8 的基本原理
UTF-8 的核心思想是使用 1 到 4 个字节来表示一个字符,具体字节数取决于字符在 Unicode 字符集中的编码点(code point)。Unicode 是一个国际标准,旨在为世界上几乎所有的字符(包括字母、数字、符号、表情等)分配一个唯一的数字编号(从 0 到 0x10FFFF,总计约 111 万个可能的编码点)。UTF-8 则是将这些编号转换为计算机可以存储和传输的字节序列的一种方式。
它的编码规则如下:
- 1 字节:用于表示 ASCII 字符(0x00 到 0x7F,即 0-127),与传统的 ASCII 编码完全兼容。例如,英文字母 “A” 的 Unicode 编码点是 U+0041,在 UTF-8 中编码为单个字节 0x41。
- 2 字节:表示范围为 U+0080 到 U+07FF 的字符,例如拉丁文扩展字符(如 “é”,U+00E9,编码为 0xC3 0xA9)。
- 3 字节:表示范围为 U+0800 到 U+FFFF 的字符,覆盖大多数常用语言的字符,例如中文 “你”(U+4F60,编码为 0xE4 0xBD 0xA0)。
- 4 字节:表示范围为 U+10000 到 U+10FFFF 的字符,例如一些罕见汉字或表情符号(如 “😊”,U+1F60A,编码为 0xF0 0x9F 0x98 0x8A)。
这种可变长度的设计既节省空间(常见字符用较少的字节),又能覆盖 Unicode 的全部范围。
UTF-8 的结构
UTF-8 使用特定的位模式来区分每个字节的角色:
- 单字节字符:以 0 开头(0xxxxxxx)。
- 多字节字符:
- 第一个字节以特定前缀开头(例如 110xxxxx 表示 2 字节,1110xxxx 表示 3 字节,11110xxx 表示 4 字节)。
- 后续字节以 10 开头(10xxxxxx),称为“续字节”。
例如:
- “A”(U+0041):0x41(二进制:01000001)。
- “é”(U+00E9):0xC3 0xA9(二进制:11000011 10101001)。
- “你”(U+4F60):0xE4 0xBD 0xA0(二进制:11100100 10111101 10100000)。
这种设计确保了字节序列的唯一性,并且即使在传输中丢失部分数据,也能通过这些前缀快速定位字符边界。
UTF-8 能表示不同的语言内容吗?
答案是完全可以。UTF-8 的设计目标就是支持 Unicode 的全部字符集,而 Unicode 涵盖了几乎所有已知的书写系统,包括但不限于:
- 拉丁字母:英语、西班牙语、法语等(例如 “Hello”, “Hola”, “Bonjour”)。
- 中文:简体、繁体汉字(例如 “你好”, “謝謝”)。
- 日文:平假名、片假名和汉字(例如 “こんにちは”)。
- 韩文:谚文(例如 “안녕하세요”)。
- 阿拉伯文:从右到左书写的文字(例如 “مرحبا”)。
- 西里尔字母:俄语、乌克兰语等(例如 “Привет”)。
- 特殊符号和表情:数学符号、emoji 等(例如 “π”, “😊”)。
由于 UTF-8 是基于 Unicode 的,它不仅能表示单一语言的文本,还能无缝处理多语言混合内容。例如,一段文本可以同时包含英文、中文和表情符号,如 “Hello 你好 😊”,UTF-8 会将其编码为:
- “Hello”:0x48 0x65 0x6C 0x6C 0x6F
- " "(空格):0x20
- “你好”:0xE4 0xBD 0xA0 0xE5 0xA5 0xBD
- " "(空格):0x20
- “😊”:0xF0 0x9F 0x98 0x8A
这种能力使得 UTF-8 非常适合全球化应用,例如网页内容、数据库存储和跨语言通信。
UTF-8 的优势
- 兼容性:与 ASCII 完全向后兼容,纯英文文本在 UTF-8 中与 ASCII 编码相同。
- 高效性:常用字符用较少的字节表示,节省存储空间。
- 通用性:支持所有语言和符号,无需为不同语言切换编码。
- 鲁棒性:字节前缀设计避免了歧义,即使数据损坏也能较容易恢复。
与 ByT5 的关系
在 ByT5 的上下文中,UTF-8 的重要性更加凸显。ByT5 直接操作 UTF-8 字节序列,而不是依赖子词或词级别的标记化。这意味着它可以处理任何语言的原始文本,而无需预先构建词汇表。例如,无论是 “Hello” 还是 “你好”,ByT5 都会将其分解为字节(例如 0x48 0x65 0x6C 0x6C 0x6F 或 0xE4 0xBD 0xA0 0xE5 0xA5 0xBD),然后输入到 Transformer 模型中。这种方法不仅简化了处理流程,还增强了对多语言和噪声文本的支持。
总结
UTF-8 是一种强大而灵活的编码方案,能够将 Unicode 的庞大字符集转换为字节序列,从而表示世界上几乎所有的语言内容。它的可变长度设计、高效性和通用性使其成为现代计算的基石。无论是日常文本编辑还是复杂的 NLP 模型(如 ByT5),UTF-8 都提供了一个统一的桥梁,让不同语言和文化的内容得以在数字世界中共存与交流。
预训练代码实现
下面将提供一个简化的 ByT5 预训练代码示例,使用 PyTorch 实现,并附上详细的解释。由于 ByT5 是基于 T5 架构的字节级模型,预训练代码需要包括字节级输入处理、Transformer 编码器-解码器架构以及跨度损坏(span corruption)目标的实现。完整实现非常复杂(需要大规模数据和分布式训练),这里我们专注于核心逻辑,适合理解其原理。
ByT5 预训练代码(PyTorch)
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
import random
# 1. 定义字节级数据集
class ByteDataset(Dataset):
def __init__(self, texts, max_length=1024):
self.texts = texts
self.max_length = max_length
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
# 将文本转换为 UTF-8 字节序列
text = self.texts[idx]
byte_seq = list(text.encode('utf-8')) # 转换为字节列表
byte_seq = byte_seq[:self.max_length] # 截断到最大长度
# 填充到 max_length
padded_seq = byte_seq + [0] * (self.max_length - len(byte_seq))
return torch.tensor(padded_seq, dtype=torch.long)
# 2. 定义简化的 ByT5 模型
class ByT5(nn.Module):
def __init__(self, vocab_size=259, d_model=512, n_encoder_layers=36, n_decoder_layers=12, n_heads=8, d_ff=2048):
super(ByT5, self).__init__()
self.vocab_size = vocab_size # 256 个字节 + 3 个特殊标记
self.embedding = nn.Embedding(vocab_size, d_model)
# 编码器(重编码器设计:36 层)
encoder_layer = nn.TransformerEncoderLayer(d_model, n_heads, d_ff)
self.encoder = nn.TransformerEncoder(encoder_layer, num_layers=n_encoder_layers)
# 解码器(12 层)
decoder_layer = nn.TransformerDecoderLayer(d_model, n_heads, d_ff)
self.decoder = nn.TransformerDecoder(decoder_layer, num_layers=n_decoder_layers)
# 输出层
self.output_layer = nn.Linear(d_model, vocab_size)
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
# 嵌入输入字节序列
src_emb = self.embedding(src) # [batch_size, seq_len, d_model]
tgt_emb = self.embedding(tgt)
# 编码器处理输入
enc_output = self.encoder(src_emb, src_key_padding_mask=src_mask) # [batch_size, seq_len, d_model]
# 解码器生成输出
dec_output = self.decoder(tgt_emb, enc_output, tgt_key_padding_mask=tgt_mask) # [batch_size, seq_len, d_model]
# 输出 logits
logits = self.output_layer(dec_output) # [batch_size, seq_len, vocab_size]
return logits
# 3. 跨度损坏预训练目标
def span_corruption(src, mean_span_length=20, vocab_size=259):
seq_len = src.size(1)
mask = torch.ones_like(src, dtype=torch.bool)
target = src.clone()
# 随机选择跨度并掩盖
num_spans = max(1, int(seq_len * 0.15 / mean_span_length)) # 掩盖约 15% 的序列
for _ in range(num_spans):
span_len = min(random.randint(1, mean_span_length * 2), seq_len)
start = random.randint(0, seq_len - span_len)
end = start + span_len
# 用 sentinel token(假设 256-258 为 sentinel IDs)替换跨度
sentinel_id = random.randint(256, 258)
mask[:, start:end] = False
target[:, start] = sentinel_id
target[:, start + 1:end] = 0 # 填充为 0
return src * mask, target
# 4. 训练循环
def train_byt5(model, dataloader, epochs=1, device='cuda'):
model = model.to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss(ignore_index=0) # 忽略填充值 0
for epoch in range(epochs):
model.train()
total_loss = 0
for batch in dataloader:
src = batch.to(device) # [batch_size, seq_len]
# 生成跨度损坏的输入和目标
corrupted_src, target = span_corruption(src)
# 前向传播
logits = model(corrupted_src, target[:, :-1]) # 目标偏移一位
loss = criterion(logits.view(-1, model.vocab_size), target[:, 1:].view(-1))
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Epoch {epoch + 1}, Loss: {total_loss / len(dataloader)}")
# 5. 主函数
if __name__ == "__main__":
# 模拟数据
texts = ["Hello world!", "你好,世界!", "Bonjour le monde!"]
dataset = ByteDataset(texts, max_length=32)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
# 初始化模型
model = ByT5(
vocab_size=259, # 256 字节 + 3 特殊标记
d_model=512, # 隐藏层维度
n_encoder_layers=36, # 重编码器
n_decoder_layers=12, # 浅解码器
n_heads=8, # 多头注意力
d_ff=2048 # 前馈层维度
)
# 训练
train_byt5(model, dataloader, epochs=3)
代码详细解释
1. 字节级数据集(ByteDataset)
- 作用:将原始文本转换为 UTF-8 字节序列,这是 ByT5 的核心输入形式。
- 实现:
text.encode('utf-8')将字符串转换为字节序列。例如,“Hello” 变为[72, 101, 108, 108, 111]。- 截断或填充到固定长度(
max_length),确保输入一致。填充值用 0 表示。
- 输出:返回一个形状为
[max_length]的张量,包含字节值(0-255)。
2. ByT5 模型(ByT5 类)
- 架构:
- 嵌入层:
nn.Embedding(vocab_size=259, d_model)将字节 ID 映射为稠密向量。词汇表大小为 259(256 个字节 + 3 个特殊标记:padding、EOS 和一个未使用的<UNK>)。 - 编码器:使用
nn.TransformerEncoder,层数设为 36,体现 ByT5 的“重编码器”设计。 - 解码器:使用
nn.TransformerDecoder,层数设为 12,与编码器形成 3:1 的比例。 - 输出层:将解码器输出映射回词汇表大小的 logits。
- 嵌入层:
- 前向传播:
- 输入字节序列(
src)和目标序列(tgt)通过嵌入层转换为向量。 - 编码器处理输入,解码器基于编码器输出生成预测。
- 返回
[batch_size, seq_len, vocab_size]的 logits。
- 输入字节序列(
3. 跨度损坏(span_corruption 函数)
- 作用:实现 ByT5 的预训练目标,即掩盖输入中的跨度并生成目标序列。
- 实现:
- 随机选择若干跨度(约占序列 15%),每个跨度长度围绕
mean_span_length=20波动。 - 用 sentinel token(256-258)替换跨度起点,其余部分填充为 0。
- 返回掩盖后的输入(
corrupted_src)和目标序列(target)。
- 随机选择若干跨度(约占序列 15%),每个跨度长度围绕
- 示例:
- 输入:
[72, 101, 108, 108, 111](“Hello”) - 掩盖后:
[72, 256, 0, 0, 111](掩盖 “ell”) - 目标:
[72, 101, 108, 108, 111](还原完整序列)
- 输入:
4. 训练循环(train_byt5 函数)
- 步骤:
- 将数据和模型移到 GPU。
- 对输入应用跨度损坏,生成训练对。
- 前向传播计算 logits,目标序列偏移一位(teacher forcing)。
- 使用交叉熵损失(忽略填充值 0)优化模型。
- 细节:
logits.view(-1, vocab_size)将输出展平为[batch_size * seq_len, vocab_size]。target[:, 1:].view(-1)展平目标,忽略第一个 token。
5. 主函数
- 数据:使用简单的多语言文本列表模拟输入。
- 模型参数:参考 ByT5 论文,设置
d_model=512、d_ff=2048等,简化版的参数规模。 - 训练:运行 3 个 epoch,打印平均损失。
注意事项
-
简化实现:
- 实际 ByT5 使用更大的模型(例如 ByT5-Large 有 12.3 亿参数)和海量数据(mC4 语料库)。
- 这里未实现位置编码、LayerNorm 等细节,可通过
nn.TransformerEncoderLayer的默认设置补充。
-
计算成本:
- 字节序列比子词序列长,导致计算复杂度更高(自注意力为 O(n²))。
- 需要 GPU 支持以加速训练。
-
扩展性:
- 可添加数据并行(如
torch.nn.DataParallel)或分布式训练。 - 支持更复杂的掩盖策略或多任务微调。
- 可添加数据并行(如
总结
这个代码展示了 ByT5 预训练的核心逻辑:字节级输入、重编码器架构和跨度损坏目标。通过 PyTorch 的 Transformer 模块,我们可以快速原型化这一模型。实际应用中,您可以参考官方实现(https://github.com/google-research/byt5),结合大规模数据集和硬件优化,进一步探索 ByT5 的潜力。
teacher forcing和代码解释
在代码中,logits = model(corrupted_src, target[:, :-1]) 这行涉及了 ByT5(或者更广义的 Transformer 编码器-解码器模型)在预训练或生成任务中的一个关键概念:teacher forcing(教师强制)。这里的“目标偏移一位”是为了适应这种训练方式。我将详细解释其含义和背后的逻辑。
什么是 logits 和 target[:, :-1]?
logits:这是模型的输出,表示对每个位置下一个字节(或 token)的预测概率分布。在 ByT5 中,logits的形状是[batch_size, seq_len, vocab_size],其中vocab_size=259(256 个字节 + 3 个特殊标记)。每个位置的 logits 是一个向量,表示该位置可能输出的所有字节的未归一化得分。target[:, :-1]:这是目标序列(target)经过切片操作,去掉了最后一个元素。假设target的原始形状是[batch_size, seq_len],那么target[:, :-1]的形状是[batch_size, seq_len-1]。
为什么目标要偏移一位?
在 Transformer 的解码器训练中,模型是自回归的(autoregressive),意味着它根据前面的输出逐步预测后面的内容。为了让模型学会这种生成能力,我们使用 teacher forcing 技术。具体来说:
-
输入与输出的关系:
- 在生成任务中,解码器需要根据输入序列(编码器输出)和已经生成的序列(解码器输入)预测下一个 token。
- 在训练时,我们不依赖模型自己的预测,而是直接将真实的“目标序列”(ground truth)作为解码器的输入,但偏移一位。这样,模型在每个时间步都能看到正确的“历史”输入,而不是它可能错误的预测结果。
-
偏移的具体作用:
target[:, :-1]作为解码器的输入,表示“到当前时间步为止的真实序列”(不包括最后一个 token)。- 模型根据这个输入预测整个序列的 logits,然后我们用
target[:, 1:](目标序列从第二个 token 开始)作为监督信号,计算损失。 - 这种偏移确保模型在时间步
t预测的是t+1位置的 token。
-
ByT5 的上下文:
- 在 ByT5 的跨度损坏预训练中,
corrupted_src是掩盖了部分跨度的输入序列,target是完整的原始序列。 - 解码器的任务是根据损坏的输入(通过编码器处理)和部分目标序列(
target[:, :-1]),预测完整的target[:, 1:]。
- 在 ByT5 的跨度损坏预训练中,
举个例子
假设我们有一个简单的字节序列:
- 原始文本:
"Hi",UTF-8 编码为[72, 105]。 - 经过跨度损坏:
corrupted_src = [72, 256, 0](假设 “i” 被掩盖,用 sentinel token 256 替换)。target = [72, 105, 0](完整序列,0 是填充)。
训练过程:
-
输入:
- 编码器输入:
corrupted_src = [72, 256, 0]。 - 解码器输入:
target[:, :-1] = [72, 105](去掉最后一个 0)。
- 编码器输入:
-
模型输出:
logits = model(corrupted_src, [72, 105]),形状为[1, 2, 259]。logits[0, 0, :]表示在位置 0(输入 72)预测下一个字节的概率分布。logits[0, 1, :]表示在位置 1(输入 105)预测下一个字节的概率分布。
-
损失计算:
- 目标:
target[:, 1:] = [105, 0]。 - 损失函数比较
logits和target[:, 1:],让模型学习:- 在位置 0,预测 105(“i” 的字节)。
- 在位置 1,预测 0(填充字节,表示结束)。
- 目标:
为什么不直接用完整 target?
- 如果直接用完整的
target = [72, 105, 0]作为解码器输入,模型会在最后一个时间步(输入 0)预测什么呢?它会试图预测一个不存在的“下一个 token”,这没有意义。 - 通过偏移,
target[:, :-1]提供了一个合理的输入序列长度,确保每个时间步的预测都有一个明确的目标。
代码中的具体实现
logits = model(corrupted_src, target[:, :-1]) # 目标偏移一位
loss = criterion(logits.view(-1, model.vocab_size), target[:, 1:].view(-1))
-
model(corrupted_src, target[:, :-1]):corrupted_src送入编码器,生成上下文表示。target[:, :-1]送入解码器,作为自回归输入。- 输出
logits的长度与target[:, :-1]一致(seq_len-1)。
-
loss计算:logits.view(-1, vocab_size)将 logits 展平为[batch_size * (seq_len-1), vocab_size]。target[:, 1:].view(-1)将目标展平为[batch_size * (seq_len-1)],与 logits 对齐。- 交叉熵损失计算模型预测与真实目标的差距。
为什么要这样做?(Teacher Forcing 的意义)
- 训练效率:如果不用 teacher forcing,而是让模型自己生成整个序列(从头开始预测),错误会累积(例如,预测错了第一个 token,后续预测都会受影响)。这会让训练变得缓慢且不稳定。
- 模拟推理:通过偏移,训练过程模拟了推理时的自回归生成(每次预测一个 token),但用真实数据“强制”引导模型学习正确的模式。
在推理阶段,模型不再依赖 target[:, :-1],而是从起始标记(例如 <BOS>)开始,逐步生成序列,每次将预测的 token 喂回解码器。
总结
logits = model(corrupted_src, target[:, :-1]) 中的“目标偏移一位”是 Transformer 解码器训练中的标准做法,源于 teacher forcing。它确保解码器在每个时间步看到真实的“前文”,预测正确的“后文”。在 ByT5 的预训练中,这种方法帮助模型学会从损坏的字节序列重建完整序列,是实现跨度损坏目标的关键步骤。
推理代码实现
下面将为 ByT5 提供推理(inference)代码,基于之前给出的预训练模型,使用 PyTorch。我们将展示 ByT5 在多个任务上的推理实现,包括文本分类、文本生成(摘要)和问答。这些任务将使用相同的模型架构,但根据任务需求调整输入输出处理方式。由于 ByT5 是字节级的,我们将直接处理 UTF-8 字节序列。
ByT5 推理代码(PyTorch)
前置条件
- 使用之前定义的
ByT5模型类(包含编码器、解码器和嵌入层)。 - 假设模型已预训练并加载了权重。
- 提供三种任务的推理代码,每种任务有独立的处理逻辑。
import torch
import torch.nn as nn
from torch.nn.functional import softmax
# 假设预训练的 ByT5 模型类已定义(与之前相同)
class ByT5(nn.Module):
def __init__(self, vocab_size=259, d_model=512, n_encoder_layers=36, n_decoder_layers=12, n_heads=8, d_ff=2048):
super(ByT5, self).__init__()
self.vocab_size = vocab_size
self.embedding = nn.Embedding(vocab_size, d_model)
encoder_layer = nn.TransformerEncoderLayer(d_model, n_heads, d_ff)
self.encoder = nn.TransformerEncoder(encoder_layer, num_layers=n_encoder_layers)
decoder_layer = nn.TransformerDecoderLayer(d_model, n_heads, d_ff)
self.decoder = nn.TransformerDecoder(decoder_layer, num_layers=n_decoder_layers)
self.output_layer = nn.Linear(d_model, vocab_size)
def forward(self, src, tgt, src_mask=None, tgt_mask=None):
src_emb = self.embedding(src)
tgt_emb = self.embedding(tgt)
enc_output = self.encoder(src_emb, src_key_padding_mask=src_mask)
dec_output = self.decoder(tgt_emb, enc_output, tgt_key_padding_mask=tgt_mask)
logits = self.output_layer(dec_output)
return logits
# 工具函数:将文本转换为字节序列
def text_to_bytes(text, max_length=1024):
byte_seq = list(text.encode('utf-8'))[:max_length]
padded_seq = byte_seq + [0] * (max_length - len(byte_seq))
return torch.tensor([padded_seq], dtype=torch.long)
# 工具函数:将字节序列转换回文本
def bytes_to_text(byte_seq):
byte_list = byte_seq.tolist()
# 移除填充(0)和 sentinel tokens(256-258)
cleaned_bytes = [b for b in byte_list if b != 0 and b < 256]
return bytes(cleaned_bytes).decode('utf-8', errors='ignore')
# 1. 任务 1:文本分类(例如情感分析)
def classify_text(model, text, max_length=1024, device='cuda'):
model.eval()
model.to(device)
# 输入处理
src = text_to_bytes(text, max_length).to(device) # [1, max_length]
# 用一个特殊的起始标记(例如 257)作为解码器输入
tgt = torch.tensor([[257]], dtype=torch.long).to(device) # [1, 1]
with torch.no_grad():
logits = model(src, tgt) # [1, 1, vocab_size]
probs = softmax(logits[0, 0], dim=-1) # [vocab_size]
# 假设 1=正面,2=负面(映射到特定字节)
pos_score = probs[1].item()
neg_score = probs[2].item()
prediction = "Positive" if pos_score > neg_score else "Negative"
return prediction, pos_score, neg_score
# 2. 任务 2:文本生成(例如摘要生成)
def generate_summary(model, text, max_length=1024, max_gen_length=50, device='cuda'):
model.eval()
model.to(device)
# 输入处理
src = text_to_bytes(text, max_length).to(device) # [1, max_length]
tgt = torch.tensor([[257]], dtype=torch.long).to(device) # 起始标记
generated = [257] # 存储生成的字节序列
with torch.no_grad():
for _ in range(max_gen_length):
logits = model(src, torch.tensor([generated], dtype=torch.long).to(device)) # [1, len(generated), vocab_size]
next_byte = torch.argmax(logits[0, -1]).item() # 取最后一个位置的预测
if next_byte == 258: # 假设 258 是结束标记
break
generated.append(next_byte)
summary_bytes = generated[1:] # 去掉起始标记
return bytes_to_text(summary_bytes)
# 3. 任务 3:问答
def answer_question(model, context, question, max_length=1024, max_gen_length=20, device='cuda'):
model.eval()
model.to(device)
# 输入处理:将上下文和问题拼接
input_text = f"Context: {context} Question: {question}"
src = text_to_bytes(input_text, max_length).to(device) # [1, max_length]
tgt = torch.tensor([[257]], dtype=torch.long).to(device) # 起始标记
generated = [257]
with torch.no_grad():
for _ in range(max_gen_length):
logits = model(src, torch.tensor([generated], dtype=torch.long).to(device))
next_byte = torch.argmax(logits[0, -1]).item()
if next_byte == 258: # 结束标记
break
generated.append(next_byte)
answer_bytes = generated[1:]
return bytes_to_text(answer_bytes)
# 主函数:测试多个任务
if __name__ == "__main__":
# 初始化模型(假设已加载预训练权重)
model = ByT5(
vocab_size=259,
d_model=512,
n_encoder_layers=36,
n_decoder_layers=12,
n_heads=8,
d_ff=2048
)
# model.load_state_dict(torch.load("byt5_pretrained.pth")) # 加载预训练权重(示例)
# 任务 1:文本分类
text = "I love this movie!"
pred, pos, neg = classify_text(model, text)
print(f"Classification: {pred}, Positive Score: {pos:.4f}, Negative Score: {neg:.4f}")
# 任务 2:文本生成(摘要)
article = "The quick brown fox jumps over the lazy dog. It was a sunny day and the fox enjoyed the chase."
summary = generate_summary(model, article)
print(f"Summary: {summary}")
# 任务 3:问答
context = "The capital of France is Paris."
question = "What is the capital of France?"
answer = answer_question(model, context, question)
print(f"Answer: {answer}")
代码详细解释
1. 工具函数
text_to_bytes:- 将输入文本编码为 UTF-8 字节序列,截断或填充到
max_length。 - 输出形状为
[1, max_length],适合批量大小为 1 的推理。
- 将输入文本编码为 UTF-8 字节序列,截断或填充到
bytes_to_text:- 将字节序列转换回字符串,去除填充(0)和 sentinel token(256-258)。
2. 任务 1:文本分类(classify_text)
- 任务描述:给定文本,判断其情感(正面或负面)。
- 实现:
- 输入:文本转换为字节序列 (
src)。 - 解码器输入:一个起始标记(假设 257),表示分类任务的开始。
- 输出:
logits的第一个位置预测一个字节,假设 1=正面,2=负面。 - 使用
softmax计算概率,返回预测结果和得分。
- 输入:文本转换为字节序列 (
- 细节:
- ByT5 的输出是字节序列,这里简化为映射到特定字节(1 和 2)表示分类。
- 实际应用中可能需要微调模型以输出特定格式(例如 “positive” 或 “negative”)。
3. 任务 2:文本生成(generate_summary)
- 任务描述:从长文本生成简短摘要。
- 实现:
- 输入:文章的字节序列 (
src)。 - 解码器输入:从起始标记(257)开始,逐步生成字节。
- 生成过程:自回归方式,每次预测一个字节,直到达到最大长度或遇到结束标记(258)。
- 输出:将生成的字节序列解码为文本。
- 输入:文章的字节序列 (
- 细节:
- 使用
torch.argmax贪婪解码(greedy decoding),也可替换为束搜索(beam search)以提高质量。 max_gen_length控制摘要长度。
- 使用
4. 任务 3:问答(answer_question)
- 任务描述:根据上下文回答问题。
- 实现:
- 输入:将上下文和问题拼接为一个字符串,转换为字节序列 (
src)。 - 解码器输入:从起始标记(257)开始生成回答。
- 生成过程:与摘要生成类似,自回归预测字节,直到结束标记(258)。
- 输出:将字节序列解码为答案文本。
- 输入:将上下文和问题拼接为一个字符串,转换为字节序列 (
- 细节:
- 输入格式模仿 T5 的文本到文本风格(“Context: … Question: …”)。
- 假设模型已微调,能理解上下文和问题的关系。
5. 主函数
- 初始化模型并模拟三种任务的推理。
- 注释掉的
model.load_state_dict表示需要加载预训练权重(实际使用时需提供权重文件)。
注意事项
-
预训练权重:
- 推理代码假设模型已预训练或微调。实际使用时需加载官方 ByT5 权重(例如从 Hugging Face 转换)或自己训练的权重。
-
任务微调:
- 分类任务可能需要微调以输出特定字节或文本标签。
- 生成和问答任务需在特定数据集(如 XSum 或 SQuAD)上微调,以确保生成质量。
-
性能优化:
- 当前代码使用贪婪解码,实际应用中可加入束搜索或温度采样。
- 推理速度可能因字节序列长度而较慢,可考虑硬件加速。
-
字节映射:
- 分类任务中将 1 和 2 映射为正负情感仅为示例,实际需根据微调目标调整。
示例输出(假设模型已训练)
- 分类:
输入:"I love this movie!"
输出:Classification: Positive, Positive Score: 0.85, Negative Score: 0.15 - 摘要:
输入:"The quick brown fox jumps over the lazy dog. It was a sunny day..."
输出:Summary: Fox jumps over dog on sunny day. - 问答:
输入:Context: The capital of France is Paris. Question: What is the capital of France?
输出:Answer: Paris
总结
这份代码展示了 ByT5 在推理阶段的多任务应用。文本分类利用解码器的单步输出,生成和问答则通过自回归生成字节序列。字节级处理确保了语言无关性和对噪声的鲁棒性,但需要针对具体任务微调模型以优化输出格式和质量。您可以根据需求扩展这些函数,例如添加更复杂的解码策略或支持批量推理。
后记
2025年3月27日15点44分于上海,在grok 3大模型辅助下完成。

















 2024
2024

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









