







Switch Transformers:核心贡献与MoE的区别
《Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity》是William Fedus、Barret Zoph和Noam Shazeer于2022年发表在《Journal of Machine Learning Research》的一篇重要论文,提出了一种高效的稀疏激活模型——Switch Transformer,旨在以较低的计算成本实现大规模语言模型的训练。本文将从核心贡献、与传统MoE(Mixture of Experts)的区别、数学公式及相关洞见三个方面,面向深入研究大语言模型(LLM)的读者进行介绍。
Paper: https://arxiv.org/pdf/2101.03961
一、核心贡献
Switch Transformer通过稀疏激活和简化的路由机制,显著提升了模型规模和训练效率,同时保持了计算成本的可控性。以下是其核心贡献:
-
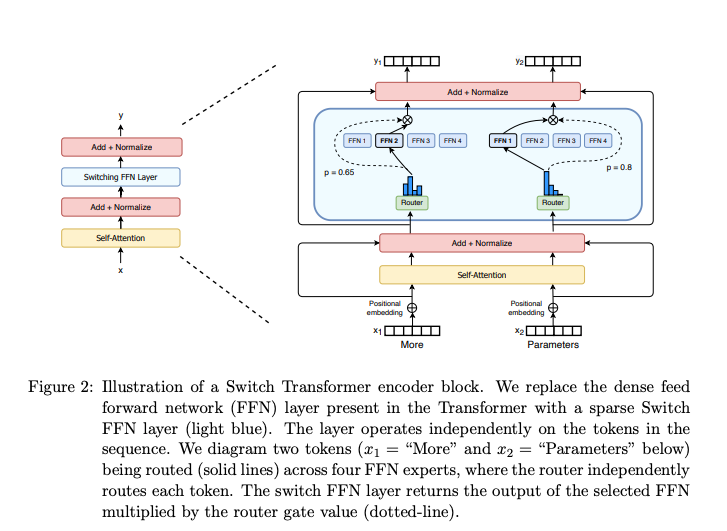
简化MoE路由算法(Switch Layer)
Switch Transformer提出了一种“Switch Layer”,将传统MoE的top-k路由(k>1)简化为只路由到一个专家(k=1)。这不仅降低了路由计算量,还减少了通信开销,同时保持了模型性能。 -
高效的分布式训练与大规模扩展
通过结合数据并行、模型并行和专家并行,Switch Transformer能够在TPU集群上训练高达万亿参数的模型。论文展示了在“Colossal Clean Crawled Corpus”上预训练的模型,相比T5-XXL模型实现了4倍的预训练速度提升。 -
训练稳定性优化
- 选择性精度训练:通过在路由函数中局部使用float32精度(而非全局float32),在保持bfloat16高效性的同时提升了训练稳定性。
- 参数初始化优化:通过降低权重初始化的标准差(从1.0降至0.1),显著减少了训练初期的方差,增强了模型稳定性。
- 专家正则化:在微调阶段引入“专家dropout”,通过对专家层的feed-forward计算施加更高的dropout率(例如0.4),有效缓解了过拟合问题。
-
多语言性能提升
在多语言预训练中,Switch Transformer在mT5-Base的基础上对101种语言均实现了性能提升,其中91%的语言获得了4倍以上的速度提升。 -
模型压缩与蒸馏
通过知识蒸馏,Switch Transformer可以将大型稀疏模型压缩至小规模稠密模型,模型参数量减少高达99%,同时保留30%的稀疏模型质量增益。 -
计算效率与参数规模的解耦
Switch Transformer通过增加专家数量(而非增加每token的FLOPs)来扩展参数规模,验证了参数数量作为独立于计算预算的扩展轴的重要性。这与Kaplan等人(2020)提出的“模型规模、数据量和计算预算呈幂律关系”相呼应。
二、与传统MoE的区别
传统MoE模型(如Shazeer et al., 2017)通过将输入token路由到top-k个专家(通常k≥2)来实现稀疏激活,但Switch Transformer在设计上进行了显著优化。以下是其与传统MoE的主要区别:
-
路由策略:从Top-k到Top-1
- 传统MoE:每个token被路由到top-k个专家(k>1),专家输出通过门控值加权组合。Shazeer等人认为k>1对于非平凡梯度至关重要,以便在训练中比较多个专家。
- Switch Transformer:提出“Switch Layer”,每个token只路由到一个专家(k=1)。论文通过实验验证了k=1不仅不会降低模型质量,还能显著减少路由计算量和通信成本。
- 优势:
- 路由计算复杂度降低:从计算k个专家的加权输出简化为单一专家输出。
- 专家容量需求降低:由于每个token只占用一个专家的容量,专家批大小(expert capacity)可减半。
- 实现简化:减少了分布式系统中跨设备通信的复杂性。
-
专家容量管理
- 传统MoE:需要较高的容量因子(capacity factor)来处理不均匀的token分配,增加了计算和内存开销。
- Switch Transformer:通过容量因子(capacity factor)动态调整专家容量,并引入辅助负载均衡损失(auxiliary load balancing loss)来鼓励均匀路由,降低token丢弃率(dropped tokens)。实验表明,即使在较低容量因子(例如1.0)下,Switch Transformer仍能保持高质量。
-
训练稳定性
- 传统MoE:由于硬性路由决策和低精度格式(如bfloat16)在softmax计算中的不稳定性,训练过程容易出现不稳定。Lepikhin等人(2020)因此全程使用float32。
- Switch Transformer:通过选择性精度(selective precision)在路由函数中局部使用float32,同时在其他部分保留bfloat16,兼顾了稳定性和效率。此外,降低初始化规模和增加专家dropout进一步提升了稳定性。
-
硬件适配性
- 传统MoE:对稀疏矩阵乘法的支持有限,主要依赖稠密矩阵乘法优化,增加了分布式训练的复杂性。
- Switch Transformer:基于Mesh-Tensorflow(MTF)设计,优化了TPU上的分布式训练,通过静态声明的tensor形状和动态路由决策,适配了硬件加速器的特性。
三、数学公式与洞见
Switch Transformer的数学设计围绕路由机制和负载均衡展开,以下是核心公式及其洞见:
1. 路由机制
传统MoE的路由机制如下:
-
门控值计算:
p i ( x ) = e h ( x ) i ∑ j = 1 N e h ( x ) j p_i(x) = \frac{e^{h(x)_i}}{\sum_{j=1}^N e^{h(x)_j}} pi(x)=∑j=1Neh(x)jeh(x)i
其中,( h ( x ) = W r ⋅ x h(x) = W_r \cdot x h(x)=Wr⋅x ) 是路由器权重 ( W r W_r Wr ) 与输入token表示 ( x x x ) 的乘积,( p i ( x ) p_i(x) pi(x) ) 是token ( x x x ) 被路由到专家 ( I I I ) 的概率。 -
输出计算:
y = ∑ i ∈ T p i ( x ) E i ( x ) y = \sum_{i \in \mathcal{T}} p_i(x) E_i(x) y=i∈T∑pi(x)Ei(x)
其中,( T \mathcal{T} T ) 是top-k专家的索引集合,( E i ( x ) E_i(x) Ei(x) ) 是专家 ( i i i ) 的输出。
Switch Transformer的改进:
- Switch Layer将 ( k=1 ),即只选择概率最高的专家:
y = p i ∗ ( x ) E i ∗ ( x ) , i ∗ = argmax i p i ( x ) y = p_{i^*}(x) E_{i^*}(x), \quad i^* = \operatorname{argmax}_i p_i(x) y=pi∗(x)Ei∗(x),i∗=argmaxipi(x) - 洞见:
- 简化梯度计算:传统MoE的top-k路由需要对k个专家的输出进行加权,增加了梯度计算的复杂性。Switch Layer通过单一专家选择,简化了梯度传播路径,降低了计算开销。
- 稀疏性增强:k=1确保每个token仅激活一个专家,最大化了模型的稀疏性,减少了FLOPs浪费。
- 直觉挑战:Shazeer等人(2017)认为k>1对路由函数的非平凡梯度至关重要,但Switch Transformer通过实验证明,单一专家路由在实践中足以捕捉足够的信息,挑战了这一直觉。
2. 负载均衡损失
为了鼓励token均匀分布到各个专家,Switch Transformer引入了辅助负载均衡损失:
loss
=
α
⋅
N
⋅
∑
i
=
1
N
f
i
⋅
P
i
\text{loss} = \alpha \cdot N \cdot \sum_{i=1}^N f_i \cdot P_i
loss=α⋅N⋅i=1∑Nfi⋅Pi
其中:
- ( f i = 1 T ∑ x ∈ B 1 { argmax p ( x ) = i } f_i = \frac{1}{T} \sum_{x \in \mathcal{B}} \mathbf{1}\{\operatorname{argmax} p(x) = i\} fi=T1∑x∈B1{argmaxp(x)=i} ):表示批次 ( B \mathcal{B} B ) 中分配到专家 ( i i i ) 的token比例。
- ( P i = 1 T ∑ x ∈ B p i ( x ) P_i = \frac{1}{T} \sum_{x \in \mathcal{B}} p_i(x) Pi=T1∑x∈Bpi(x) ):表示路由器分配给专家 ( i i i ) 的概率比例。
- ( α \alpha α ):超参数(论文中设为 ( 10^{-2} ))。
- ( N N N ):专家数量,用于归一化损失。
洞见:
- 均匀分布激励:损失函数通过最小化 ( f i f_i fi ) 和 ( P i P_i Pi ) 的点积,鼓励token均匀分布到各个专家,降低某些专家过载或未被充分利用的风险。
- 可微性:尽管 ( f i f_i fi ) 不可微(由于argmax操作),( P i P_i Pi ) 是可微的,允许通过梯度下降优化路由器权重。
- 超参数平衡:( α \alpha α ) 的选择至关重要,过高可能干扰主要损失函数(交叉熵),过低则无法有效均衡负载。论文通过实验确定 ( α = 1 0 − 2 \alpha=10^{-2} α=10−2 ) 是一个稳健的选择。
3. 专家容量
专家容量通过以下公式计算:
expert capacity
=
(
tokens per batch
number of experts
)
×
capacity factor
\text{expert capacity} = \left( \frac{\text{tokens per batch}}{\text{number of experts}} \right) \times \text{capacity factor}
expert capacity=(number of expertstokens per batch)×capacity factor
- capacity factor:控制专家容量的缓冲因子,大于1.0时提供额外容量以处理不均匀路由。
- 洞见:
- 动态容量管理:容量因子平衡了计算效率和token丢弃率(dropped tokens)。较低的容量因子(如1.0)在内存受限场景下更优,而较高的容量因子可减少token丢弃。
- 硬件适配:静态声明的tensor形状结合动态路由决策,使Switch Transformer能够高效利用TPU的稠密矩阵乘法能力。
四、面向LLM研究者的启发
-
稀疏性是未来方向
Switch Transformer通过稀疏激活实现了参数规模与计算效率的解耦,为训练超大规模模型提供了可行路径。研究者应关注如何进一步优化稀疏路由算法,例如探索自适应容量因子或动态专家选择机制。 -
路由简化的潜力
k=1路由的成功表明,复杂的路由策略可能并非必要。未来的研究可以探索其他简化路由方法,例如基于哈希的路由或确定性路由,以进一步降低开销。 -
稳定性与效率的平衡
选择性精度和降低初始化规模的策略为低精度训练提供了新思路。研究者可以尝试在其他稀疏模型中应用类似技术,以兼顾稳定性和计算效率。 -
多语言与泛化能力
Switch Transformer在多语言任务上的优异表现提示,稀疏模型可能在处理多样化数据分布时具有优势。研究者可以进一步探索稀疏模型在低资源语言或跨模态任务中的应用。 -
蒸馏与部署
稀疏模型的高效蒸馏为实际部署提供了可能。未来的研究可以聚焦于优化蒸馏算法,以在更小模型中保留更多稀疏模型的性能。
五、总结
Switch Transformer通过简化的Switch Layer、高效的分布式训练、稳定的训练技术和多语言性能提升,重新定义了稀疏激活模型的潜力。与传统MoE相比,其k=1路由策略显著降低了计算和通信开销,同时通过数学设计的优化(如负载均衡损失和容量管理)确保了高效性和稳定性。对于LLM研究者而言,Switch Transformer不仅提供了万亿参数模型的可行路径,还为稀疏性、路由简化、训练稳定性和模型压缩等方向带来了深刻洞见。
后记
2025年5月3日于上海,在grok 3大模型辅助下完成。

















 92
92

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









