









解读《On the Representation Collapse of Sparse Mixture of Experts》:解决MoE表示崩塌问题
Sparse Mixture of Experts(SMoE,稀疏专家混合模型)是一种通过条件计算实现模型容量扩展的高效方法,广泛应用于语言模型、图像分类和语音识别等任务。然而,SMoE的路由机制可能导致表示崩塌(representation collapse),从而限制模型的表达能力。《On the Representation Collapse of Sparse Mixture of Experts》一文(NeurIPS 2022)深入分析了这一问题,并提出了一种创新的路由算法(X-MoE),有效缓解表示崩塌并提升模型性能。以下从MoE研究者的视角,总结论文的贡献和方法。
Paper: https://openreview.net/pdf?id=mWaYC6CZf5
核心贡献
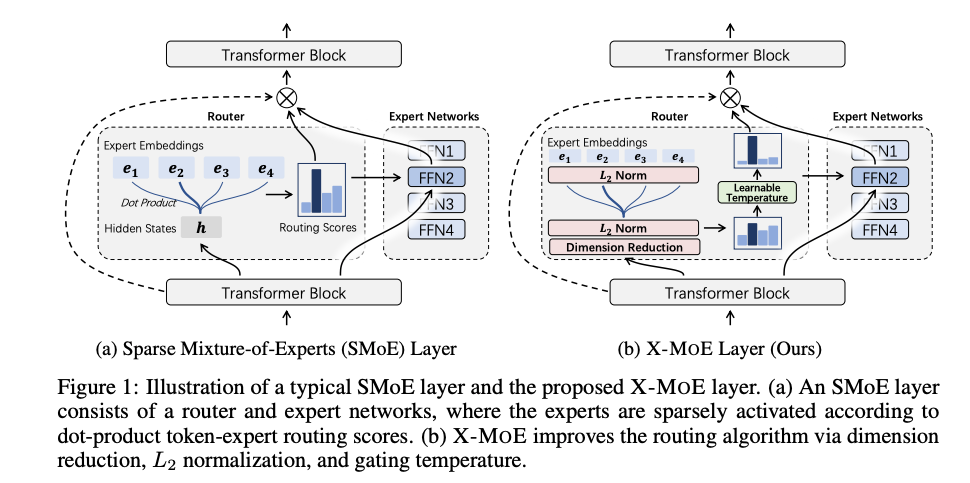
-
揭示SMoE的表示崩塌问题
论文首次系统分析了SMoE模型中的表示崩塌现象。作者指出,传统SMoE的路由机制通过点积相似度将输入token分配给专家,导致token表示倾向于聚集在专家嵌入的线性子空间中。这种聚集使得表示维度从高维( R d \mathbb{R}^d Rd)坍缩到低维( R N \mathbb{R}^N RN, N ≪ d N \ll d N≪d),限制了Transformer的表达能力,特别是在专家分配不均时。 -
提出低维超球面路由算法(X-MoE)
为解决表示崩塌,作者设计了一种新颖的路由算法,通过以下三个关键组件改进SMoE:- 维度降低(Dimension Reduction):将token表示和专家嵌入投影到低维空间,适配MoE路由的低秩特性。
- L 2 L_2 L2归一化( L 2 L_2 L2 Normalization):将token表示和专家嵌入归一化到单位超球面,消除专家嵌入范数的影响,提升表示均匀性。
- 带可学习温度的门控函数(Gating with Learnable Temperature):引入可学习的温度参数 τ \tau τ,动态调整门控函数(softmax或sigmoid),优化专家激活的灵活性。
-
广泛实验验证
论文在跨语言模型预训练和下游任务微调上进行了全面实验,涵盖七个多语言基准(XTREME)。结果显示,X-MoE在语言建模(降低困惑度)和下游任务(如XNLI、MLQA)上均优于基线SMoE和密集模型,验证了方法的有效性。 -
深入分析表示和路由行为
通过可视化(UMAP)和表示崩塌度量(RC),论文展示了X-MoE如何改善表示的均匀性和多样性。此外,作者通过路由波动率(RF)和跨运行一致性(Inter-run Consistency)分析,证明X-MoE在预训练和微调阶段的路由行为更加稳定。
技术细节与方法
1. 表示崩塌的机理
SMoE通过路由器根据token表示 h \boldsymbol{h} h和专家嵌入 e i \boldsymbol{e}_i ei的点积相似度 s i = h ⋅ e i s_i = \boldsymbol{h} \cdot \boldsymbol{e}_i si=h⋅ei分配专家。论文通过雅可比矩阵分析,揭示了梯度更新使token表示向专家嵌入的线性组合靠拢,导致表示坍缩到低维子空间。这种现象在top-1和top-K路由中均存在,尤其当某些专家主导分配时,限制了表示的表达力和区分度。
2. X-MoE路由算法
X-MoE通过以下步骤改进路由机制:
- 维度降低:将高维token表示 h \boldsymbol{h} h和专家嵌入 e i \boldsymbol{e}_i ei通过投影矩阵 W \boldsymbol{W} W映射到低维空间(维度 d c d_c dc,通常远小于模型隐层维度 d d d)。这不仅适配MoE的低秩特性,还降低了计算复杂度。
-
L
2
L_2
L2归一化:路由分数重新定义为:
s i = ( W h ) ⋅ e i ∥ W h ∥ ∥ e i ∥ s_i = \frac{(\boldsymbol{W} \boldsymbol{h}) \cdot \boldsymbol{e}_i}{\|\boldsymbol{W} \boldsymbol{h}\| \|\boldsymbol{e}_i\|} si=∥Wh∥∥ei∥(Wh)⋅ei
归一化确保路由分数仅依赖于向量夹角(余弦相似度),避免因专家嵌入范数差异导致的不均分配。 - 可学习温度:在门控函数中引入可学习的温度参数
τ
\tau
τ,调整激活强度:
g ( s k ) = { exp ( s k / τ ) ∑ j = 1 N exp ( s j / τ ) , softmax gating σ ( s k / τ ) , sigmoid gating g(s_k) = \begin{cases} \frac{\exp(s_k / \tau)}{\sum_{j=1}^N \exp(s_j / \tau)}, & \text{softmax gating} \\ \sigma(s_k / \tau), & \text{sigmoid gating} \end{cases} g(sk)={∑j=1Nexp(sj/τ)exp(sk/τ),σ(sk/τ),softmax gatingsigmoid gating
这使得路由更灵活,适应不同任务需求。
3. 训练与微调策略
- 训练目标:联合优化任务损失(如掩码语言建模损失)和负载均衡损失:
L = L task + α L balance \mathcal{L} = \mathcal{L}_{\text{task}} + \alpha \mathcal{L}^{\text{balance}} L=Ltask+αLbalance
负载均衡损失通过固定温度 τ 0 \tau_0 τ0计算,确保专家利用率均衡。 - 微调策略:在微调阶段冻结路由器和专家网络参数,避免过拟合和路由不一致问题,同时保留负载均衡损失以提升性能。
4. 实验与分析
- 实验设置:使用Transformer编码器(12层,隐层维度768)作为骨干,插入32个专家的SMoE层,预训练数据结合CCNet和Wikipedia(94种语言)。下游任务包括POS、NER、XNLI等。
- 结果:X-MoE在XTREME基准上平均得分65.3(softmax门控),优于SMoE基线(64.1)和密集模型(61.4)。在机器翻译任务(WMT-10)上,X-MoE在8个语言方向的BLEU分数均优于基线。
- 消融研究:维度降低、 L 2 L_2 L2归一化和冻结路由的组合对性能提升至关重要。路由维度实验表明 d c = N / 2 d_c = N/2 dc=N/2或 N / 4 N/4 N/4( N N N为专家数)效果最佳。
- 表示与路由分析:
- 可视化显示X-MoE的token表示分布更均匀,集群区分更清晰。
- 表示崩塌度量(RC)表明X-MoE的RC值更高且呈上升趋势,缓解了崩塌问题。
- 路由波动率(RF)和跨运行一致性分析显示X-MoE的路由更稳定,微调时跨种子的一致性更高。
对MoE研究者的启发
-
关注表示崩塌:论文揭示了SMoE中表示崩塌的普遍性,提示研究者在设计路由算法时需考虑表示空间的多样性。未来的MoE研究可进一步探索如何在高维空间中保持表示的表达力。
-
路由算法优化:X-MoE的低维超球面路由为MoE设计提供了新思路。研究者可尝试其他归一化方法(如L1或球面插值)或动态维度调整策略,进一步优化路由效率和稳定性。
-
跨领域扩展:虽然论文聚焦于语言任务,但作者提到计划将X-MoE应用于视觉和多模态预训练。这提示MoE研究者探索跨领域的路由算法适配性,尤其是在多模态任务中如何平衡不同模态的专家分配。
-
计算效率与环境影响:X-MoE通过稀疏激活降低计算成本,减少碳排放。研究者可进一步优化SMoE的训练效率,如通过动态专家选择或更高效的负载均衡策略。
总结
《On the Representation Collapse of Sparse Mixture of Experts》为MoE研究提供了重要洞见,揭示了表示崩塌问题并提出了X-MoE路由算法,通过维度降低、 L 2 L_2 L2归一化和可学习温度有效缓解这一问题。实验结果和深入分析表明,X-MoE不仅提升了模型性能,还增强了路由一致性和表示多样性。对于MoE研究者而言,这篇论文提供了理论启发和实用方法,值得深入研读并作为进一步优化的起点。
表示崩塌
以下是对论文《On the Representation Collapse of Sparse Mixture of Experts》中 2.2 Representation Collapse of Sparse Mixture-of-Experts 部分的数学公式进行详细解释,包括公式的推导、意义以及得出的结论。解释将以清晰、系统的方式展开,面向对MoE(专家混合模型)和数学推导有一定了解的研究者,同时尽量保持简洁。
2.2 节概述
在这一节中,作者分析了稀疏专家混合模型(SMoE)中表示崩塌(representation collapse)问题的根源,指出传统SMoE的路由机制会导致token表示向专家嵌入的低维子空间聚集,从而限制模型的表达能力。作者通过数学推导(主要是雅可比矩阵和梯度分析)揭示了这一现象的机制,并讨论了其对模型性能的负面影响。以下逐步解析公式及其意义。
数学公式的推导与解释
1. SMoE前向传播公式
SMoE的核心是路由机制,将输入token的隐表示 h ∈ R d \boldsymbol{h} \in \mathbb{R}^d h∈Rd 分配给最匹配的专家。路由分数通过点积计算:
s i = h ⋅ e i s_i = \boldsymbol{h} \cdot \boldsymbol{e}_i si=h⋅ei
其中, e i ∈ R d \boldsymbol{e}_i \in \mathbb{R}^d ei∈Rd 是第 i i i 个专家的嵌入向量, d d d 是模型隐层的维度。路由器基于分数选择专家,通常采用top-1路由(选择分数最高的专家):
k = arg max i s i = arg max i h ⋅ e i k = \arg \max_i s_i = \arg \max_i \boldsymbol{h} \cdot \boldsymbol{e}_i k=argimaxsi=argimaxh⋅ei
SMoE层的输出定义为:
h ′ = f SMoE ( h ) = h + g ( s k ) f k FFN ( h ) \boldsymbol{h}' = f^{\text{SMoE}}(\boldsymbol{h}) = \boldsymbol{h} + g(s_k) f_k^{\text{FFN}}(\boldsymbol{h}) h′=fSMoE(h)=h+g(sk)fkFFN(h)
- 解释:
- h \boldsymbol{h} h 是输入token的隐表示, h ′ \boldsymbol{h}' h′ 是SMoE层的输出。
- f k FFN ( ⋅ ) f_k^{\text{FFN}}(\cdot) fkFFN(⋅) 是第 k k k 个专家的前馈神经网络(FFN)。
-
g
(
s
k
)
g(s_k)
g(sk) 是门控函数,控制专家的激活强度,可能为softmax或sigmoid:
g ( s k ) = { exp ( s k ) ∑ j = 1 N exp ( s j ) , softmax gating σ ( s k ) , sigmoid gating g(s_k) = \begin{cases} \frac{\exp(s_k)}{\sum_{j=1}^N \exp(s_j)}, & \text{softmax gating} \\ \sigma(s_k), & \text{sigmoid gating} \end{cases} g(sk)={∑j=1Nexp(sj)exp(sk),σ(sk),softmax gatingsigmoid gating - 此公式表明,SMoE层的输出是原始表示 h \boldsymbol{h} h 加上选定专家的加权输出。
2. 雅可比矩阵的推导
为了分析表示崩塌,作者通过计算SMoE层输出 h ′ \boldsymbol{h}' h′ 对输入 h \boldsymbol{h} h 的雅可比矩阵(Jacobian matrix)来研究梯度传播的行为。雅可比矩阵描述了 h ′ \boldsymbol{h}' h′ 对 h \boldsymbol{h} h 的偏导数:
J = ∂ h ′ ∂ h \boldsymbol{J} = \frac{\partial \boldsymbol{h}'}{\partial \boldsymbol{h}} J=∂h∂h′
根据前向传播公式(2):
h ′ = h + g ( s k ) f k FFN ( h ) \boldsymbol{h}' = \boldsymbol{h} + g(s_k) f_k^{\text{FFN}}(\boldsymbol{h}) h′=h+g(sk)fkFFN(h)
雅可比矩阵可以分解为两部分:
J = J 1 + J 2 = ( I + S k J FFN ) + ∑ j = 1 N S k ( δ k j − S j ) h FFN e j ⊤ \boldsymbol{J} = \boldsymbol{J}_1 + \boldsymbol{J}_2 = \left( \boldsymbol{I} + S_k \boldsymbol{J}^{\text{FFN}} \right) + \sum_{j=1}^N S_k (\delta_{kj} - S_j) \boldsymbol{h}^{\text{FFN}} \boldsymbol{e}_j^\top J=J1+J2=(I+SkJFFN)+j=1∑NSk(δkj−Sj)hFFNej⊤
- 符号说明:
- S k = g ( s k ) S_k = g(s_k) Sk=g(sk),表示门控函数的输出(softmax或sigmoid)。
- h FFN = f k FFN ( h ) \boldsymbol{h}^{\text{FFN}} = f_k^{\text{FFN}}(\boldsymbol{h}) hFFN=fkFFN(h),是选定专家的输出。
- J FFN = ∂ f k FFN ( h ) ∂ h \boldsymbol{J}^{\text{FFN}} = \frac{\partial f_k^{\text{FFN}}(\boldsymbol{h})}{\partial \boldsymbol{h}} JFFN=∂h∂fkFFN(h),是专家FFN的雅可比矩阵。
- δ k j \delta_{kj} δkj 是Kronecker delta(当 k = j k=j k=j 时为1,否则为0)。
- e j \boldsymbol{e}_j ej 是第 j j j 个专家的嵌入向量。
推导过程:
-
第一项 J 1 = I + S k J FFN \boldsymbol{J}_1 = \boldsymbol{I} + S_k \boldsymbol{J}^{\text{FFN}} J1=I+SkJFFN:
-
h
′
=
h
+
S
k
h
FFN
\boldsymbol{h}' = \boldsymbol{h} + S_k \boldsymbol{h}^{\text{FFN}}
h′=h+SkhFFN,对
h
\boldsymbol{h}
h 求导:
∂ h ′ ∂ h = ∂ h ∂ h + ∂ ( S k h FFN ) ∂ h \frac{\partial \boldsymbol{h}'}{\partial \boldsymbol{h}} = \frac{\partial \boldsymbol{h}}{\partial \boldsymbol{h}} + \frac{\partial (S_k \boldsymbol{h}^{\text{FFN}})}{\partial \boldsymbol{h}} ∂h∂h′=∂h∂h+∂h∂(SkhFFN) - 第一部分 ∂ h ∂ h = I \frac{\partial \boldsymbol{h}}{\partial \boldsymbol{h}} = \boldsymbol{I} ∂h∂h=I(单位矩阵)。
- 第二部分使用乘积法则:
∂ ( S k h FFN ) ∂ h = S k ∂ h FFN ∂ h + h FFN ∂ S k ∂ h \frac{\partial (S_k \boldsymbol{h}^{\text{FFN}})}{\partial \boldsymbol{h}} = S_k \frac{\partial \boldsymbol{h}^{\text{FFN}}}{\partial \boldsymbol{h}} + \boldsymbol{h}^{\text{FFN}} \frac{\partial S_k}{\partial \boldsymbol{h}} ∂h∂(SkhFFN)=Sk∂h∂hFFN+hFFN∂h∂Sk
其中, ∂ h FFN ∂ h = J FFN \frac{\partial \boldsymbol{h}^{\text{FFN}}}{\partial \boldsymbol{h}} = \boldsymbol{J}^{\text{FFN}} ∂h∂hFFN=JFFN,而 ∂ S k ∂ h \frac{\partial S_k}{\partial \boldsymbol{h}} ∂h∂Sk 涉及门控函数的导数(稍后分析)。第一项直接得出 S k J FFN S_k \boldsymbol{J}^{\text{FFN}} SkJFFN。
-
h
′
=
h
+
S
k
h
FFN
\boldsymbol{h}' = \boldsymbol{h} + S_k \boldsymbol{h}^{\text{FFN}}
h′=h+SkhFFN,对
h
\boldsymbol{h}
h 求导:
-
第二项 J 2 = ∑ j = 1 N S k ( δ k j − S j ) h FFN e j ⊤ \boldsymbol{J}_2 = \sum_{j=1}^N S_k (\delta_{kj} - S_j) \boldsymbol{h}^{\text{FFN}} \boldsymbol{e}_j^\top J2=∑j=1NSk(δkj−Sj)hFFNej⊤:
- 门控函数
S
k
=
g
(
s
k
)
S_k = g(s_k)
Sk=g(sk),其中
s
k
=
h
⋅
e
k
s_k = \boldsymbol{h} \cdot \boldsymbol{e}_k
sk=h⋅ek。对于softmax门控,
S
k
=
exp
(
s
k
)
∑
j
exp
(
s
j
)
S_k = \frac{\exp(s_k)}{\sum_j \exp(s_j)}
Sk=∑jexp(sj)exp(sk),其导数为:
∂ S k ∂ h = ∑ j = 1 N ∂ S k ∂ s j ∂ s j ∂ h \frac{\partial S_k}{\partial \boldsymbol{h}} = \sum_{j=1}^N \frac{\partial S_k}{\partial s_j} \frac{\partial s_j}{\partial \boldsymbol{h}} ∂h∂Sk=j=1∑N∂sj∂Sk∂h∂sj
其中, ∂ s j ∂ h = e j \frac{\partial s_j}{\partial \boldsymbol{h}} = \boldsymbol{e}_j ∂h∂sj=ej(因为 s j = h ⋅ e j s_j = \boldsymbol{h} \cdot \boldsymbol{e}_j sj=h⋅ej),而softmax的导数为:
∂ S k ∂ s j = S k ( δ k j − S j ) \frac{\partial S_k}{\partial s_j} = S_k (\delta_{kj} - S_j) ∂sj∂Sk=Sk(δkj−Sj)
因此:
∂ S k ∂ h = ∑ j = 1 N S k ( δ k j − S j ) e j \frac{\partial S_k}{\partial \boldsymbol{h}} = \sum_{j=1}^N S_k (\delta_{kj} - S_j) \boldsymbol{e}_j ∂h∂Sk=j=1∑NSk(δkj−Sj)ej - 结合乘积法则,第二部分的贡献为:
h FFN ∂ S k ∂ h = ∑ j = 1 N S k ( δ k j − S j ) h FFN e j ⊤ \boldsymbol{h}^{\text{FFN}} \frac{\partial S_k}{\partial \boldsymbol{h}} = \sum_{j=1}^N S_k (\delta_{kj} - S_j) \boldsymbol{h}^{\text{FFN}} \boldsymbol{e}_j^\top hFFN∂h∂Sk=j=1∑NSk(δkj−Sj)hFFNej⊤
- 门控函数
S
k
=
g
(
s
k
)
S_k = g(s_k)
Sk=g(sk),其中
s
k
=
h
⋅
e
k
s_k = \boldsymbol{h} \cdot \boldsymbol{e}_k
sk=h⋅ek。对于softmax门控,
S
k
=
exp
(
s
k
)
∑
j
exp
(
s
j
)
S_k = \frac{\exp(s_k)}{\sum_j \exp(s_j)}
Sk=∑jexp(sj)exp(sk),其导数为:
- 意义:
- J 1 \boldsymbol{J}_1 J1 负责优化token表示,结合专家的输出调整 h \boldsymbol{h} h。
- J 2 \boldsymbol{J}_2 J2 影响门控函数的学习,控制专家的激活分数 S k S_k Sk。
3. 梯度分析与表示崩塌
通过反向传播,损失函数 L \mathcal{L} L 对 h \boldsymbol{h} h 的梯度为:
∇ h L = J ⊤ ∇ h ′ L = J 1 ⊤ ∇ h ′ L + J 2 ⊤ ∇ h ′ L \nabla_{\boldsymbol{h}} \mathcal{L} = \boldsymbol{J}^\top \nabla_{\boldsymbol{h}'} \mathcal{L} = \boldsymbol{J}_1^\top \nabla_{\boldsymbol{h}'} \mathcal{L} + \boldsymbol{J}_2^\top \nabla_{\boldsymbol{h}'} \mathcal{L} ∇hL=J⊤∇h′L=J1⊤∇h′L+J2⊤∇h′L
其中, J 2 ⊤ ∇ h ′ L \boldsymbol{J}_2^\top \nabla_{\boldsymbol{h}'} \mathcal{L} J2⊤∇h′L 是关键,展开为:
J 2 ⊤ ∇ h ′ L = ∑ j = 1 N S k ( δ k j − S j ) ( h FFN ⊤ ∇ h ′ L ) e j = ∑ j = 1 N c j e j \boldsymbol{J}_2^\top \nabla_{\boldsymbol{h}'} \mathcal{L} = \sum_{j=1}^N S_k (\delta_{kj} - S_j) (\boldsymbol{h}^{\text{FFN}^\top} \nabla_{\boldsymbol{h}'} \mathcal{L}) \boldsymbol{e}_j = \sum_{j=1}^N c_j \boldsymbol{e}_j J2⊤∇h′L=j=1∑NSk(δkj−Sj)(hFFN⊤∇h′L)ej=j=1∑Ncjej
其中, c j = S k ( δ k j − S j ) ( h FFN ⊤ ∇ h ′ L ) c_j = S_k (\delta_{kj} - S_j) (\boldsymbol{h}^{\text{FFN}^\top} \nabla_{\boldsymbol{h}'} \mathcal{L}) cj=Sk(δkj−Sj)(hFFN⊤∇h′L) 是一个标量系数。
-
推导:
-
J
2
=
∑
j
=
1
N
S
k
(
δ
k
j
−
S
j
)
h
FFN
e
j
⊤
\boldsymbol{J}_2 = \sum_{j=1}^N S_k (\delta_{kj} - S_j) \boldsymbol{h}^{\text{FFN}} \boldsymbol{e}_j^\top
J2=∑j=1NSk(δkj−Sj)hFFNej⊤,其转置为:
J 2 ⊤ = ∑ j = 1 N S k ( δ k j − S j ) e j h FFN ⊤ \boldsymbol{J}_2^\top = \sum_{j=1}^N S_k (\delta_{kj} - S_j) \boldsymbol{e}_j \boldsymbol{h}^{\text{FFN}^\top} J2⊤=j=1∑NSk(δkj−Sj)ejhFFN⊤ - 因此:
J 2 ⊤ ∇ h ′ L = ∑ j = 1 N S k ( δ k j − S j ) e j ( h FFN ⊤ ∇ h ′ L ) \boldsymbol{J}_2^\top \nabla_{\boldsymbol{h}'} \mathcal{L} = \sum_{j=1}^N S_k (\delta_{kj} - S_j) \boldsymbol{e}_j (\boldsymbol{h}^{\text{FFN}^\top} \nabla_{\boldsymbol{h}'} \mathcal{L}) J2⊤∇h′L=j=1∑NSk(δkj−Sj)ej(hFFN⊤∇h′L)
其中, h FFN ⊤ ∇ h ′ L \boldsymbol{h}^{\text{FFN}^\top} \nabla_{\boldsymbol{h}'} \mathcal{L} hFFN⊤∇h′L 是一个标量。
-
J
2
=
∑
j
=
1
N
S
k
(
δ
k
j
−
S
j
)
h
FFN
e
j
⊤
\boldsymbol{J}_2 = \sum_{j=1}^N S_k (\delta_{kj} - S_j) \boldsymbol{h}^{\text{FFN}} \boldsymbol{e}_j^\top
J2=∑j=1NSk(δkj−Sj)hFFNej⊤,其转置为:
-
意义:
- 梯度 ∇ h L \nabla_{\boldsymbol{h}} \mathcal{L} ∇hL 的 J 2 ⊤ \boldsymbol{J}_2^\top J2⊤ 部分表明,token表示 h \boldsymbol{h} h 的更新方向是专家嵌入 e j \boldsymbol{e}_j ej 的线性组合。
- 这意味着 h \boldsymbol{h} h 被“拉向”专家嵌入的子空间,导致表示倾向于聚集在专家嵌入的线性跨度内。
4. Top-K路由的扩展
对于top-K路由(激活分数最高的前 K K K 个专家),前向传播公式为:
h ′ = h + ∑ i = 1 K g ( s k i ) f k i FFN ( h ) \boldsymbol{h}' = \boldsymbol{h} + \sum_{i=1}^K g(s_{k_i}) f_{k_i}^{\text{FFN}}(\boldsymbol{h}) h′=h+i=1∑Kg(ski)fkiFFN(h)
其中, k 1 , k 2 , … , k K = top K ( s i ) k_1, k_2, \ldots, k_K = \text{top } K(s_i) k1,k2,…,kK=top K(si),门控函数为:
g ( s k i ) = exp ( s k i ) ∑ j = 1 K exp ( s k j ) g(s_{k_i}) = \frac{\exp(s_{k_i})}{\sum_{j=1}^K \exp(s_{k_j})} g(ski)=∑j=1Kexp(skj)exp(ski)
类似地, J 2 ⊤ ∇ h ′ L \boldsymbol{J}_2^\top \nabla_{\boldsymbol{h}'} \mathcal{L} J2⊤∇h′L 为:
J 2 ⊤ ∇ h ′ L = ∑ i = 1 K ∑ j = 1 K S k i ( δ k i k j − S k j ) ( h FFN k i ⊤ ∇ h ′ L ) e k j = ∑ j = 1 K c j e k j \boldsymbol{J}_2^\top \nabla_{\boldsymbol{h}'} \mathcal{L} = \sum_{i=1}^K \sum_{j=1}^K S_{k_i} (\delta_{k_i k_j} - S_{k_j}) (\boldsymbol{h}^{\text{FFN}_{k_i}^\top} \nabla_{\boldsymbol{h}'} \mathcal{L}) \boldsymbol{e}_{k_j} = \sum_{j=1}^K c_j \boldsymbol{e}_{k_j} J2⊤∇h′L=i=1∑Kj=1∑KSki(δkikj−Skj)(hFFNki⊤∇h′L)ekj=j=1∑Kcjekj
- 意义:
- top-K路由的梯度更新仍然使 h \boldsymbol{h} h 向 K K K 个专家嵌入的线性组合靠拢,子空间维度最多为 K K K。
公式的意义
-
表示崩塌的机制:
- 公式(5)和(6)表明,梯度更新使token表示 h \boldsymbol{h} h 向专家嵌入 e j \boldsymbol{e}_j ej 的线性子空间靠拢。由于专家数量 N N N(或 K K K)远小于隐层维度 d d d( N ≪ d N \ll d N≪d),表示被限制在一个低维子空间( R N \mathbb{R}^N RN 或 R K \mathbb{R}^K RK),导致从 R d \mathbb{R}^d Rd 到 R N \mathbb{R}^N RN 的表示崩塌。
- 当某些专家主导路由时(例如由于较大的 e j \boldsymbol{e}_j ej 范数),token表示会进一步聚集到这些专家附近,减少表示的多样性和区分度。
-
对模型性能的影响:
- 表示崩塌限制了Transformer的表达能力,因为隐状态无法充分利用高维空间 R d \mathbb{R}^d Rd。
- 聚集的表示可能导致模型难以区分不同token的语义,尤其在多语言或复杂任务中,降低模型的泛化能力。
结论
-
表示崩塌的发现:
- SMoE的路由机制通过梯度更新使token表示 h \boldsymbol{h} h 向专家嵌入 e j \boldsymbol{e}_j ej 的低维子空间靠拢,导致表示崩塌。这种现象在top-1和top-K路由中均存在。
- 崩塌的原因是路由分数的点积机制( s i = h ⋅ e i s_i = \boldsymbol{h} \cdot \boldsymbol{e}_i si=h⋅ei)和梯度更新的线性组合效应。
-
对MoE设计的启发:
- 表示崩塌限制了SMoE的表达能力,特别是在专家分配不均或某些专家主导时。
- 为缓解这一问题,需要改进路由算法,例如通过维度降低、归一化或更灵活的门控机制来增强表示的均匀性和多样性。
-
后续改进方向:
- 论文后续提出X-MoE,通过在低维超球面计算路由分数(结合维度降低和 L 2 L_2 L2 归一化)以及引入可学习温度的门控函数,缓解表示崩塌并提升路由一致性。
总结
2.2节通过雅可比矩阵和梯度分析,揭示了SMoE中表示崩塌的数学机理:token表示被梯度更新拉向专家嵌入的低维子空间,导致表达能力受限。这一发现为优化MoE路由算法提供了理论依据,提示研究者关注表示空间的多样性和路由的稳定性。X-MoE的提出正是基于这一分析,通过改进路由机制有效缓解了表示崩塌问题。
限制在低维子空间
问题背景与核心疑问
你的疑问聚焦于公式(5)和(6):
J 2 ⊤ ∇ h ′ L = ∑ j = 1 N c j e j (公式 5,top-1 路由) \boldsymbol{J}_2^\top \nabla_{\boldsymbol{h}'} \mathcal{L} = \sum_{j=1}^N c_j \boldsymbol{e}_j \quad \text{(公式 5,top-1 路由)} J2⊤∇h′L=j=1∑Ncjej(公式 5,top-1 路由)
J 2 ⊤ ∇ h ′ L = ∑ j = 1 K c j e k j (公式 6,top-K 路由) \boldsymbol{J}_2^\top \nabla_{\boldsymbol{h}'} \mathcal{L} = \sum_{j=1}^K c_j \boldsymbol{e}_{k_j} \quad \text{(公式 6,top-K 路由)} J2⊤∇h′L=j=1∑Kcjekj(公式 6,top-K 路由)
其中, c j = S k ( δ k j − S j ) ( h FFN ⊤ ∇ h ′ L ) c_j = S_k (\delta_{kj} - S_j) (\boldsymbol{h}^{\text{FFN}^\top} \nabla_{\boldsymbol{h}'} \mathcal{L}) cj=Sk(δkj−Sj)(hFFN⊤∇h′L) 是一个标量系数, e j \boldsymbol{e}_j ej 是专家嵌入向量, N N N 是专家总数, K K K 是top-K路由中激活的专家数, h ∈ R d \boldsymbol{h} \in \mathbb{R}^d h∈Rd 是输入token的隐表示, d d d 是隐层维度(通常远大于 N N N 或 K K K)。
你的疑问可以总结为:
- 为什么说 h \boldsymbol{h} h 被限制在低维子空间 R N \mathbb{R}^N RN 或 R K \mathbb{R}^K RK?专家嵌入 e j \boldsymbol{e}_j ej 的线性组合不是仍然在 R d \mathbb{R}^d Rd 中吗?
- 是不是因为 e j \boldsymbol{e}_j ej 前面的系数 c j c_j cj 个数少(只有 N N N 或 K K K 个),导致维度坍缩?
下面我将从数学和直观的角度逐步解答。
解答:低维子空间与表示崩塌
1. 理解“低维子空间”的含义
在数学中,向量空间 R d \mathbb{R}^d Rd 是 d d d 维的,意味着任何向量 h ∈ R d \boldsymbol{h} \in \mathbb{R}^d h∈Rd 可以用 d d d 个线性无关的基向量表示。而子空间是 R d \mathbb{R}^d Rd 的一个子集,其维度小于或等于 d d d。例如,一个 N N N 维子空间由 N N N 个线性无关的向量(如 e 1 , e 2 , … , e N \boldsymbol{e}_1, \boldsymbol{e}_2, \ldots, \boldsymbol{e}_N e1,e2,…,eN)张成(span),任何在这个子空间中的向量都可以表示为这些基向量的线性组合。
在公式(5)和(6)中,梯度 J 2 ⊤ ∇ h ′ L \boldsymbol{J}_2^\top \nabla_{\boldsymbol{h}'} \mathcal{L} J2⊤∇h′L 的形式是:
∑ j = 1 N c j e j (top-1) 或 ∑ j = 1 K c j e k j (top-K) \sum_{j=1}^N c_j \boldsymbol{e}_j \quad \text{(top-1)} \quad \text{或} \quad \sum_{j=1}^K c_j \boldsymbol{e}_{k_j} \quad \text{(top-K)} j=1∑Ncjej(top-1)或j=1∑Kcjekj(top-K)
- 关键点:这里的梯度是一个向量,表示 h \boldsymbol{h} h 的更新方向。更新方向完全由专家嵌入 e j \boldsymbol{e}_j ej 的线性组合构成。
- 张成的子空间:假设 e 1 , e 2 , … , e N \boldsymbol{e}_1, \boldsymbol{e}_2, \ldots, \boldsymbol{e}_N e1,e2,…,eN 是线性无关的(通常在初始化时会尽量保证这一点),它们最多张成一个 N N N 维子空间(如果某些 e j \boldsymbol{e}_j ej 线性相关,维度可能更低)。对于top-K路由,激活的 K K K 个专家嵌入 e k j \boldsymbol{e}_{k_j} ekj 最多张成一个 K K K 维子空间。
- 维度对比:在SMoE中,专家数量 N N N(或 K K K)通常远小于隐层维度 d d d(例如, N = 32 N=32 N=32, d = 768 d=768 d=768)。因此,梯度更新方向被限制在 e j \boldsymbol{e}_j ej 张成的子空间中,其维度远小于 R d \mathbb{R}^d Rd 的完整维度。
直观解释:虽然 e j ∈ R d \boldsymbol{e}_j \in \mathbb{R}^d ej∈Rd(即专家嵌入是 d d d 维向量),但它们的线性组合 ∑ c j e j \sum c_j \boldsymbol{e}_j ∑cjej 只能覆盖由 e j \boldsymbol{e}_j ej 张成的子空间,维度最多为 N N N(或 K K K)。这意味着 h \boldsymbol{h} h 的更新只能沿着这个低维子空间的方向进行,而不是利用整个 R d \mathbb{R}^d Rd 的自由度。
2. 为什么是“低维子空间”?
你的疑问提到“ e j \boldsymbol{e}_j ej 的线性加权不还是在 R d \mathbb{R}^d Rd 中吗?”这是正确的,但需要澄清“子空间”的概念:
- 线性组合的限制:虽然 ∑ c j e j \sum c_j \boldsymbol{e}_j ∑cjej 的结果是一个 R d \mathbb{R}^d Rd 中的向量,但它只能表示由 e 1 , e 2 , … , e N \boldsymbol{e}_1, \boldsymbol{e}_2, \ldots, \boldsymbol{e}_N e1,e2,…,eN 张成的子空间中的点。如果 e j \boldsymbol{e}_j ej 有 N N N 个,且线性无关,子空间的维度是 N N N。即使 e j \boldsymbol{e}_j ej 本身是 d d d 维的,它们的线性组合无法覆盖整个 R d \mathbb{R}^d Rd,除非 N ≥ d N \geq d N≥d(但在MoE中, N ≪ d N \ll d N≪d)。
- 系数个数的作用:你提到的“ e j \boldsymbol{e}_j ej 前面的系数个数少”是一个很好的直觉。系数 c j c_j cj 的个数( N N N 或 K K K)决定了线性组合的自由度。无论 c j c_j cj 取何值, ∑ c j e j \sum c_j \boldsymbol{e}_j ∑cjej 只能表示 N N N 个基向量的组合,因此维度受限于 N N N。
类比:想象 R 3 \mathbb{R}^3 R3(三维空间),你有 N = 2 N=2 N=2 个向量 e 1 = ( 1 , 0 , 0 ) \boldsymbol{e}_1 = (1, 0, 0) e1=(1,0,0) 和 e 2 = ( 0 , 1 , 0 ) \boldsymbol{e}_2 = (0, 1, 0) e2=(0,1,0)。它们的线性组合 c 1 e 1 + c 2 e 2 = ( c 1 , c 2 , 0 ) c_1 \boldsymbol{e}_1 + c_2 \boldsymbol{e}_2 = (c_1, c_2, 0) c1e1+c2e2=(c1,c2,0) 只能形成 x y xy xy 平面(一个二维子空间),无法覆盖整个 R 3 \mathbb{R}^3 R3。在SMoE中, e j \boldsymbol{e}_j ej 的数量 N N N 远小于 d d d,导致类似的现象。
3. 表示崩塌的机制
表示崩塌是指token表示 h \boldsymbol{h} h 的多样性减少,表现为隐状态被“拉向”专家嵌入的低维子空间。公式(5)和(6)揭示了这一过程:
- 梯度更新的影响:梯度 ∇ h L = J 1 ⊤ ∇ h ′ L + J 2 ⊤ ∇ h ′ L \nabla_{\boldsymbol{h}} \mathcal{L} = \boldsymbol{J}_1^\top \nabla_{\boldsymbol{h}'} \mathcal{L} + \boldsymbol{J}_2^\top \nabla_{\boldsymbol{h}'} \mathcal{L} ∇hL=J1⊤∇h′L+J2⊤∇h′L 决定 h \boldsymbol{h} h 的更新方向。其中, J 2 ⊤ ∇ h ′ L = ∑ c j e j \boldsymbol{J}_2^\top \nabla_{\boldsymbol{h}'} \mathcal{L} = \sum c_j \boldsymbol{e}_j J2⊤∇h′L=∑cjej 使 h \boldsymbol{h} h 向 e j \boldsymbol{e}_j ej 的线性子空间靠拢。
- 聚集效应:在训练过程中, h \boldsymbol{h} h 不断通过梯度更新调整。如果路由机制倾向于将多个token分配给同一个专家(例如由于 e j \boldsymbol{e}_j ej 的范数较大),这些token的 h \boldsymbol{h} h 会进一步向该专家的嵌入 e j \boldsymbol{e}_j ej 靠拢,导致表示聚集,失去区分度。
- 维度坍缩:由于更新方向受限于 N N N 维子空间( N ≪ d N \ll d N≪d), h \boldsymbol{h} h 的有效维度从 d d d 降低到最多 N N N,这意味着模型无法充分利用 R d \mathbb{R}^d Rd 的表达能力。这种现象称为“从 R d \mathbb{R}^d Rd 到 R N \mathbb{R}^N RN 的表示崩塌”。
直观解释:假设你有1000维的隐表示,但只有32个专家。梯度更新只能在32个专家嵌入张成的子空间中调整 h \boldsymbol{h} h,相当于把表示压缩到一个32维的“盒子”里。这限制了表示的多样性,尤其当某些专家主导路由时,token表示会趋向于少数几个 e j \boldsymbol{e}_j ej,导致表示“坍缩”。
4. 为什么系数个数少导致问题?
你的直觉“是不是因为 e j \boldsymbol{e}_j ej 前面的系数个数少”非常准确。以下进一步说明:
- 自由度受限:线性组合 ∑ c j e j \sum c_j \boldsymbol{e}_j ∑cjej 中的 c j c_j cj 只有 N N N 个(或top-K中的 K K K 个),这意味着梯度方向的自由度最多为 N N N。相比之下, h ∈ R d \boldsymbol{h} \in \mathbb{R}^d h∈Rd 原本有 d d d 个自由度( d ≫ N d \gg N d≫N)。这种自由度的减少直接导致表示无法探索整个 R d \mathbb{R}^d Rd。
- 专家主导问题:如果某些 e j \boldsymbol{e}_j ej 的范数 ∥ e j ∥ \lVert \boldsymbol{e}_j \rVert ∥ej∥ 较大或路由机制偏向某些专家, c j c_j cj 的值可能使这些专家的贡献占主导,进一步加剧表示向少数几个 e j \boldsymbol{e}_j ej 聚集,减少表示的区分度。
数学视角:假设 e 1 , … , e N \boldsymbol{e}_1, \ldots, \boldsymbol{e}_N e1,…,eN 是线性无关的,它们张成的子空间是:
span ( e 1 , e 2 , … , e N ) = { ∑ j = 1 N c j e j ∣ c j ∈ R } \text{span}(\boldsymbol{e}_1, \boldsymbol{e}_2, \ldots, \boldsymbol{e}_N) = \{ \sum_{j=1}^N c_j \boldsymbol{e}_j \mid c_j \in \mathbb{R} \} span(e1,e2,…,eN)={j=1∑Ncjej∣cj∈R}
这个子空间的维度最多为 N N N,远小于 d d d。梯度更新 h ← h − η ∇ h L \boldsymbol{h} \gets \boldsymbol{h} - \eta \nabla_{\boldsymbol{h}} \mathcal{L} h←h−η∇hL 的 J 2 ⊤ \boldsymbol{J}_2^\top J2⊤ 部分始终在这个子空间内,导致 h \boldsymbol{h} h 逐渐被约束在这个低维空间中。
意义与结论
意义
-
揭示表示崩塌的根源:
- 公式(5)和(6)表明,SMoE的路由机制通过梯度更新将 h \boldsymbol{h} h 限制在专家嵌入的低维子空间中。这是因为梯度方向 ∑ c j e j \sum c_j \boldsymbol{e}_j ∑cjej 只能覆盖由 N N N(或 K K K)个 e j \boldsymbol{e}_j ej 张成的空间,维度远低于 R d \mathbb{R}^d Rd。
- 当某些专家主导路由时,token表示会进一步向这些专家的 e j \boldsymbol{e}_j ej 靠拢,导致表示聚集,丧失多样性。
-
对模型性能的影响:
- 表示崩塌减少了隐状态的表达能力,限制了Transformer在高维空间中捕捉复杂语义的能力。
- 尤其在多语言或复杂任务中,表示的低多样性可能导致模型难以区分不同token的语义,降低泛化性能。
结论
-
低维子空间的限制:
- h \boldsymbol{h} h 被限制在 R N \mathbb{R}^N RN 或 R K \mathbb{R}^K RK 子空间的原因是梯度更新的方向 ∑ c j e j \sum c_j \boldsymbol{e}_j ∑cjej 仅由 N N N(或 K K K)个专家嵌入线性组合构成,自由度受限于专家数量,而非完整的 d d d 维空间。
- 虽然 e j \boldsymbol{e}_j ej 是 d d d 维向量,但它们的线性组合无法覆盖整个 R d \mathbb{R}^d Rd,导致维度坍缩。
-
表示崩塌的后果:
- 表示崩塌使 h \boldsymbol{h} h 的有效维度从 d d d 降低到 N N N(或 K K K),限制了模型的表达能力。
- 当专家分配不均时(某些 e j \boldsymbol{e}_j ej 主导),token表示会聚集到少数专家附近,进一步加剧崩塌。
-
改进方向:
- 为了缓解表示崩塌,需要改进路由机制,例如通过维度降低、归一化(如论文提出的X-MoE)或更灵活的门控函数,增强表示的均匀性和多样性。
直观类比
想象一个图书馆( R d \mathbb{R}^d Rd,高维空间)有1000个书架(维度),但你只有32本书(专家嵌入 e j \boldsymbol{e}_j ej)。无论你如何组合这32本书(线性组合 ∑ c j e j \sum c_j \boldsymbol{e}_j ∑cjej),你只能填充32个书架,剩下的968个书架永远空着。这就是表示崩塌:token表示 h \boldsymbol{h} h 被限制在32维子空间中,无法利用整个1000维空间的表达能力。如果某些书特别“吸引人”(例如 e j \boldsymbol{e}_j ej 范数大),所有读者(token)都挤向这些书,导致表示更加单一。
总结
你的疑问“是不是因为 e j \boldsymbol{e}_j ej 前面的系数个数少”抓住了问题的核心。表示崩塌的根源在于梯度更新方向 ∑ c j e j \sum c_j \boldsymbol{e}_j ∑cjej 受限于 N N N(或 K K K)个专家嵌入的线性组合,维度最多为 N N N 或 K K K,远小于隐层维度 d d d。这导致 h \boldsymbol{h} h 被“困”在低维子空间中,丧失了 R d \mathbb{R}^d Rd 的表达能力。公式(5)和(6)通过数学推导清晰揭示了这一机制,为后续优化(如X-MoE的低维超球面路由)提供了理论依据。
为什么本文的方法work?
为什么在低维超球面(low-dimensional hypersphere)上计算路由分数能够有效缓解表示崩塌(representation collapse)?以下我将详细解释 X-MoE 路由算法的做法、其有效性背后的理论依据,以及如何缓解表示崩塌,面向对 MoE 和数学推导有一定了解的研究者,同时保持清晰和简洁。
3 Methods 概述
在第 3 节中,作者提出了 X-MoE 路由算法,旨在解决 SMoE 中表示崩塌问题。核心思想是将 token 表示和专家嵌入投影到低维空间,并在单位超球面上计算路由分数,同时引入可学习的门控温度参数。算法包含以下三个关键组件:
- 维度降低(Dimension Reduction):将 token 表示 h \boldsymbol{h} h 和专家嵌入 e i \boldsymbol{e}_i ei 投影到低维空间(维度 d c ≪ d d_c \ll d dc≪d)。
- L 2 L_2 L2 归一化( L 2 L_2 L2 Normalization):将投影后的表示和嵌入归一化到单位超球面,路由分数基于余弦相似度计算。
- 带可学习温度的门控函数(Gating with Learnable Temperature):引入可学习参数 τ \tau τ 调整门控函数的激活强度。
这些方法共同作用,缓解表示崩塌,提升路由一致性和模型性能。下面逐一分析这些做法为什么有效,以及其理论依据。
X-MoE 路由算法的做法及有效性
1. 维度降低(Dimension Reduction)
做法:
- 将高维 token 表示 h ∈ R d \boldsymbol{h} \in \mathbb{R}^d h∈Rd 和专家嵌入 e i ∈ R d \boldsymbol{e}_i \in \mathbb{R}^d ei∈Rd 通过投影矩阵 W \boldsymbol{W} W 映射到低维空间 R d c \mathbb{R}^{d_c} Rdc,其中 d c ≪ d d_c \ll d dc≪d(例如, d = 768 d=768 d=768, d c = 16 d_c=16 dc=16)。
- 投影后的表示为 W h \boldsymbol{W} \boldsymbol{h} Wh,专家嵌入为 e i ∈ R d c \boldsymbol{e}_i \in \mathbb{R}^{d_c} ei∈Rdc。
为什么有效:
- 适配 MoE 的低秩特性:
- 第 2.2 节分析表明,表示崩塌源于 token 表示 h \boldsymbol{h} h 被梯度更新拉向专家嵌入 e j \boldsymbol{e}_j ej 张成的低维子空间(维度最多为专家数 N N N)。这表明路由机制本身具有低秩(low-rank)特性,即路由分数 s i = h ⋅ e i s_i = \boldsymbol{h} \cdot \boldsymbol{e}_i si=h⋅ei 并不需要利用完整的 d d d 维空间。
- 维度降低将 h \boldsymbol{h} h 和 e i \boldsymbol{e}_i ei 投影到 d c d_c dc 维空间(通常 d c ≈ N d_c \approx N dc≈N 或略小于 N N N),显式适配这一低秩特性,减少计算冗余,同时保留路由所需的信息。
- 缓解表示崩塌:
- 在高维空间 R d \mathbb{R}^d Rd 中, e j \boldsymbol{e}_j ej 的线性组合受限于 N N N 维子空间,导致表示崩塌。投影到低维空间 R d c \mathbb{R}^{d_c} Rdc( d c ≈ N d_c \approx N dc≈N)后,专家嵌入 e i \boldsymbol{e}_i ei 更容易覆盖整个低维空间(因为 d c d_c dc 和 N N N 接近),从而减少表示被“压缩”到更低维子空间的风险。
- 直观来说,维度降低将问题从“在高维空间中被困于低维子空间”转变为“在适当的低维空间中充分利用维度”,避免了不必要的维度浪费。
理论依据:
- 低秩假设:MoE 的路由机制本质上是一个低秩决策过程,因为专家数量 N N N 远小于隐层维度 d d d。投影到 d c ≈ N d_c \approx N dc≈N 的空间符合这一假设,理论上能保留路由的有效信息,同时降低计算复杂度。
- 表示空间利用:在高维空间中, e j \boldsymbol{e}_j ej 张成的子空间维度远小于 d d d,导致表示崩塌。低维投影使 e i \boldsymbol{e}_i ei 的张成空间更接近 R d c \mathbb{R}^{d_c} Rdc 的完整维度,增强表示的表达能力。
2. L 2 L_2 L2 归一化( L 2 L_2 L2 Normalization)
做法:
- 在低维空间中,将投影后的 token 表示 W h \boldsymbol{W} \boldsymbol{h} Wh 和专家嵌入 e i \boldsymbol{e}_i ei 进行 L 2 L_2 L2 归一化,路由分数定义为:
s i = ( W h ) ⋅ e i ∥ W h ∥ ∥ e i ∥ s_i = \frac{(\boldsymbol{W} \boldsymbol{h}) \cdot \boldsymbol{e}_i}{\|\boldsymbol{W} \boldsymbol{h}\| \|\boldsymbol{e}_i\|} si=∥Wh∥∥ei∥(Wh)⋅ei
- 这等价于计算单位超球面上的余弦相似度,消除了向量范数的影响。
为什么有效:
- 消除范数影响:
- 在传统 SMoE 中,路由分数 s i = h ⋅ e i s_i = \boldsymbol{h} \cdot \boldsymbol{e}_i si=h⋅ei 受向量范数 ∥ h ∥ \lVert \boldsymbol{h} \rVert ∥h∥ 和 ∥ e i ∥ \lVert \boldsymbol{e}_i \rVert ∥ei∥ 的影响。如果某些专家的 ∥ e i ∥ \lVert \boldsymbol{e}_i \rVert ∥ei∥ 较大,它们可能主导路由,导致 token 表示 h \boldsymbol{h} h 向这些专家嵌入靠拢,加剧表示崩塌。
- L 2 L_2 L2 归一化将 W h \boldsymbol{W} \boldsymbol{h} Wh 和 e i \boldsymbol{e}_i ei 投影到单位超球面( ∥ W h ∥ = ∥ e i ∥ = 1 \lVert \boldsymbol{W} \boldsymbol{h} \rVert = \lVert \boldsymbol{e}_i \rVert = 1 ∥Wh∥=∥ei∥=1),路由分数仅取决于向量间的夹角(余弦相似度)。这避免了因范数差异导致的专家分配不均。
- 增强表示均匀性:
- 归一化后的表示分布在单位超球面上,鼓励 token 表示在空间中更均匀分布,减少向少数专家嵌入聚集的趋势。
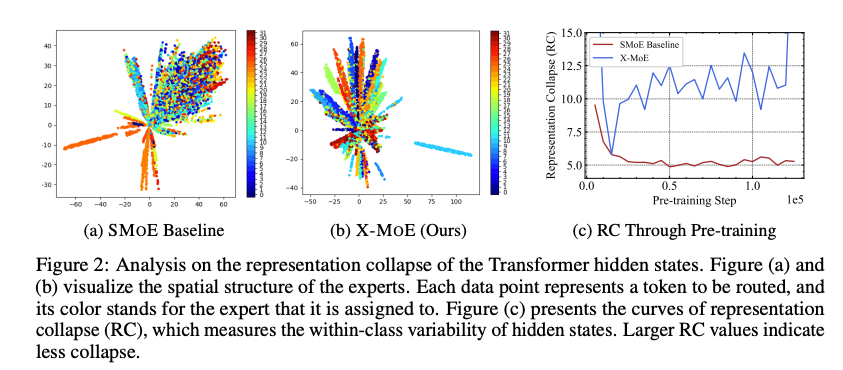
- 图 2b(论文中)的可视化显示,X-MoE 的 token 表示分布更均匀,集群区分更清晰,表明 L 2 L_2 L2 归一化有效缓解了表示崩塌。
- 稳定路由行为:
- 论文指出,未归一化的专家嵌入 e i \boldsymbol{e}_i ei 若范数较小,可能导致路由分配波动(尤其在专家数量多时)。通过初始化 ∥ e i ∥ = 0.1 \lVert \boldsymbol{e}_i \rVert = 0.1 ∥ei∥=0.1 并保持不变,X-MoE 稳定了路由过程中的角度更新,减少了分配波动。
理论依据:
- 几何视角:在单位超球面上,路由分数基于余弦相似度,强调表示的方向性而非大小。这种几何约束鼓励 token 表示分布更均匀,防止表示坍缩到少数专家主导的子空间。
- 信息论视角:归一化减少了路由分数对无关因素(如范数)的依赖,使路由决策更专注于语义相关性,从而提升表示的多样性和区分度。
3. 带可学习温度的门控函数(Gating with Learnable Temperature)
做法:
- 在门控函数中引入可学习温度参数 τ \tau τ,调整路由分数的激活强度:
g ( s k ) = { exp ( s k / τ ) ∑ j = 1 N exp ( s j / τ ) , softmax gating σ ( s k / τ ) , sigmoid gating g(s_k) = \begin{cases} \frac{\exp(s_k / \tau)}{\sum_{j=1}^N \exp(s_j / \tau)}, & \text{softmax gating} \\ \sigma(s_k / \tau), & \text{sigmoid gating} \end{cases} g(sk)={∑j=1Nexp(sj/τ)exp(sk/τ),σ(sk/τ),softmax gatingsigmoid gating
- 由于 L 2 L_2 L2 归一化将路由分数 s k s_k sk 限制在 [ − 1 , 1 ] [-1, 1] [−1,1] 范围内,直接使用可能导致专家激活过于保守。温度 τ \tau τ 动态调节激活的“锐度”。
为什么有效:
- 灵活调整激活:
- L 2 L_2 L2 归一化后的 s k ∈ [ − 1 , 1 ] s_k \in [-1, 1] sk∈[−1,1] 可能使门控函数输出(如 softmax)过于平滑,导致专家激活不足。引入 τ \tau τ 允许模型自适应调整激活强度,例如较小的 τ \tau τ 使 softmax 更“尖锐”,增强专家的选择性。
- 这在不同任务(如预训练和微调)中尤为重要,因为任务特性可能需要不同的路由策略。
- 缓解表示崩塌:
- 可学习温度通过调整 g ( s k ) g(s_k) g(sk) 的分布,间接影响梯度 J 2 ⊤ ∇ h ′ L = ∑ c j e j \boldsymbol{J}_2^\top \nabla_{\boldsymbol{h}'} \mathcal{L} = \sum c_j \boldsymbol{e}_j J2⊤∇h′L=∑cjej 中的系数 c j c_j cj。更灵活的门控函数可以避免某些专家过度主导路由,从而减少 token 表示向少数 e j \boldsymbol{e}_j ej 聚集的趋势。
- 提高路由一致性:
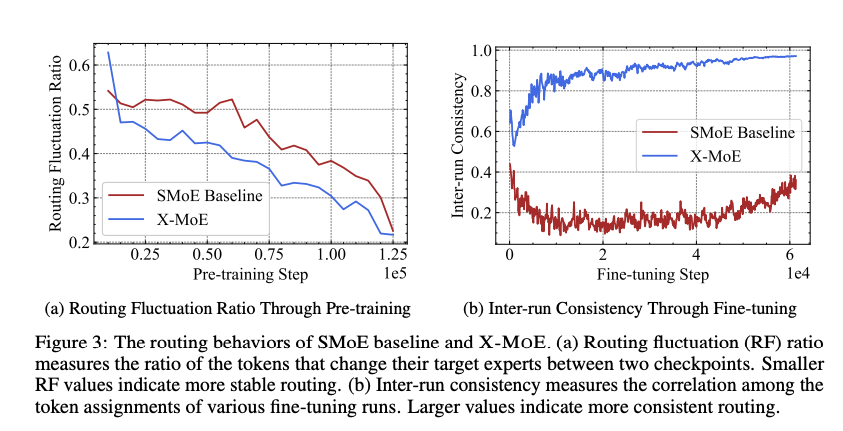
- 温度 τ \tau τ 的可学习性使路由机制能够适应训练过程中的数据分布变化,减少路由波动(如图 3a 所示,X-MoE 的路由波动率 RF 较低)。
理论依据:
- 优化视角:温度 τ \tau τ 类似于 softmax 中的正则化参数,控制路由分数的熵。较低的 τ \tau τ 增加选择性(低熵),较高的 τ \tau τ 增加均匀性(高熵),使路由机制更灵活,适应不同任务需求。
- 梯度分析:门控函数 g ( s k ) g(s_k) g(sk) 影响梯度系数 c j = S k ( δ k j − S j ) ( h FFN ⊤ ∇ h ′ L ) c_j = S_k (\delta_{kj} - S_j) (\boldsymbol{h}^{\text{FFN}^\top} \nabla_{\boldsymbol{h}'} \mathcal{L}) cj=Sk(δkj−Sj)(hFFN⊤∇h′L)。可学习 τ \tau τ 动态调整 S k S_k Sk,优化梯度方向,防止表示过度向某些 e j \boldsymbol{e}_j ej 靠拢。
理论依据:为什么能缓解表示崩塌?
表示崩塌的核心问题是 token 表示 h \boldsymbol{h} h 被梯度更新拉向专家嵌入 e j \boldsymbol{e}_j ej 张成的低维子空间(维度 ≤ N \leq N ≤N),导致表达能力受限。X-MoE 的三个组件从以下方面缓解这一问题:
-
维度降低适配低秩特性:
- 传统 SMoE 在高维空间 R d \mathbb{R}^d Rd 中计算路由分数,但梯度更新受限于 N N N 维子空间( N ≪ d N \ll d N≪d),导致表示崩塌。X-MoE 通过投影到 R d c \mathbb{R}^{d_c} Rdc( d c ≈ N d_c \approx N dc≈N),使路由空间与专家数量匹配,减少维度浪费。
- 理论上, W h \boldsymbol{W} \boldsymbol{h} Wh 和 e i \boldsymbol{e}_i ei 在低维空间中更可能覆盖整个 R d c \mathbb{R}^{d_c} Rdc,避免表示被压缩到更低维的子空间(如 R k \mathbb{R}^k Rk, k < N k < N k<N)。
-
L 2 L_2 L2 归一化增强均匀性:
- 第 2.2 节的公式(5)表明,梯度 ∑ c j e j \sum c_j \boldsymbol{e}_j ∑cjej 使 h \boldsymbol{h} h 向 e j \boldsymbol{e}_j ej 的线性组合靠拢。若某些 e j \boldsymbol{e}_j ej 的范数较大,路由可能偏向这些专家,导致表示聚集。 L 2 L_2 L2 归一化消除范数影响,路由分数仅取决于方向(余弦相似度),鼓励 token 表示在超球面上均匀分布。
- 数学上,归一化后的梯度方向 ∑ c j e j ∥ e j ∥ \sum c_j \frac{\boldsymbol{e}_j}{\lVert \boldsymbol{e}_j \rVert} ∑cj∥ej∥ej 更均匀地分布在 R d c \mathbb{R}^{d_c} Rdc 中,减少表示向少数专家嵌入坍缩的风险。
-
可学习温度优化路由动态:
- 表示崩塌部分源于路由分配不均(某些专家主导)。可学习温度 τ \tau τ 动态调整门控函数的输出 S k S_k Sk,影响梯度系数 c j c_j cj,从而控制专家的激活分布。
- 通过优化 τ \tau τ,模型可以避免过度依赖少数专家,保持路由的多样性,间接缓解表示向特定 e j \boldsymbol{e}_j ej 的聚集。
综合效果:
- 图 2c 的表示崩塌度量(RC)显示,X-MoE 的 RC 值高于 SMoE 基线且呈上升趋势,表明表示崩塌得到缓解。
- 图 2b 的可视化(UMAP)进一步证实,X-MoE 的 token 表示分布更均匀,集群区分更清晰,说明低维超球面路由增强了表示的多样性。
理论支持:
- 几何约束:超球面上的路由分数(余弦相似度)强制表示分布在单位球面上,符合表示学习中均匀性(uniformity)的原则,减少表示坍缩(Papyan et al., 2020; Zhu et al., 2021)。
- 低秩优化:维度降低与 MoE 的低秩特性对齐,理论上优化了路由决策的信息效率,减少表示空间的浪费。
- 动态调整:可学习温度类似于正则化参数,平衡了路由的探索(exploration)和利用(exploitation),防止表示过度集中。
对表示崩塌的具体缓解机制
从第 2.2 节的分析看,表示崩塌源于梯度 J 2 ⊤ ∇ h ′ L = ∑ c j e j \boldsymbol{J}_2^\top \nabla_{\boldsymbol{h}'} \mathcal{L} = \sum c_j \boldsymbol{e}_j J2⊤∇h′L=∑cjej 将 h \boldsymbol{h} h 拉向 N N N 维子空间。X-MoE 的做法如何缓解这一问题?
-
维度降低:
- 投影到 R d c \mathbb{R}^{d_c} Rdc 后,梯度方向 ∑ c j e j \sum c_j \boldsymbol{e}_j ∑cjej 在低维空间中计算, e j \boldsymbol{e}_j ej 更容易覆盖整个 R d c \mathbb{R}^{d_c} Rdc(因为 d c ≈ N d_c \approx N dc≈N)。这减少了表示被压缩到更低维子空间的风险。
- 梯度更新不再局限于高维空间中的低维子空间,而是充分利用低维空间的维度。
-
L 2 L_2 L2 归一化:
- 归一化后的梯度方向 ∑ c j e j ∥ e j ∥ \sum c_j \frac{\boldsymbol{e}_j}{\lVert \boldsymbol{e}_j \rVert} ∑cj∥ej∥ej 分布在单位超球面上,系数 c j c_j cj 仅由余弦相似度和门控函数决定。这防止了因 ∥ e j ∥ \lVert \boldsymbol{e}_j \rVert ∥ej∥ 差异导致的专家主导问题。
- 归一化鼓励 W h \boldsymbol{W} \boldsymbol{h} Wh 和 e j \boldsymbol{e}_j ej 在超球面上均匀分布,减少表示向少数 e j \boldsymbol{e}_j ej 聚集的趋势。
-
可学习温度:
- 温度 τ \tau τ 调整 S k S_k Sk 的分布,间接影响 c j c_j cj 的值,使梯度方向更平衡。避免某些 c j c_j cj 过大(导致 h \boldsymbol{h} h 向特定 e j \boldsymbol{e}_j ej 靠拢),从而保持表示的多样性。
实验验证与结论
-
实验证据:
- 表 3 的消融研究表明,维度降低、 L 2 L_2 L2 归一化和冻结路由的组合共同提升了性能,单独移除任一组件都会降低效果,验证了三者的协同作用。
- 图 2c 的 RC 度量显示,X-MoE 的表示崩塌程度低于 SMoE 基线,且随训练呈上升趋势。
- 图 3a 和 3b 表明,X-MoE 的路由波动率(RF)和跨运行一致性(Inter-run Consistency)优于基线,说明路由更稳定,间接支持表示多样性的提升。
-
结论:
- X-MoE 通过在低维超球面上计算路由分数,结合维度降低、 L 2 L_2 L2 归一化和可学习温度,有效缓解表示崩塌。
- 理论依据包括低秩优化、几何均匀性和动态路由调整,这些机制共同确保 token 表示充分利用低维空间,减少向少数专家嵌入的聚集,增强表达能力。
- 实验结果进一步证实,X-MoE 在跨语言预训练和下游任务上优于基线,证明了其在缓解表示崩塌和提升性能方面的有效性。
总结
X-MoE 路由算法通过维度降低适配 MoE 的低秩特性, L 2 L_2 L2 归一化增强表示均匀性,可学习温度优化路由动态,共同缓解表示崩塌。理论上,这些方法通过约束梯度方向、优化表示分布和平衡专家激活,防止 token 表示被限制在低维子空间或聚集到少数专家嵌入。实验验证了这些机制的有效性,为 MoE 路由设计提供了重要的理论和实践启发。
后记
2025年5月19日于上海,在grok 3大模型辅助下完成。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









