






目录
前言:
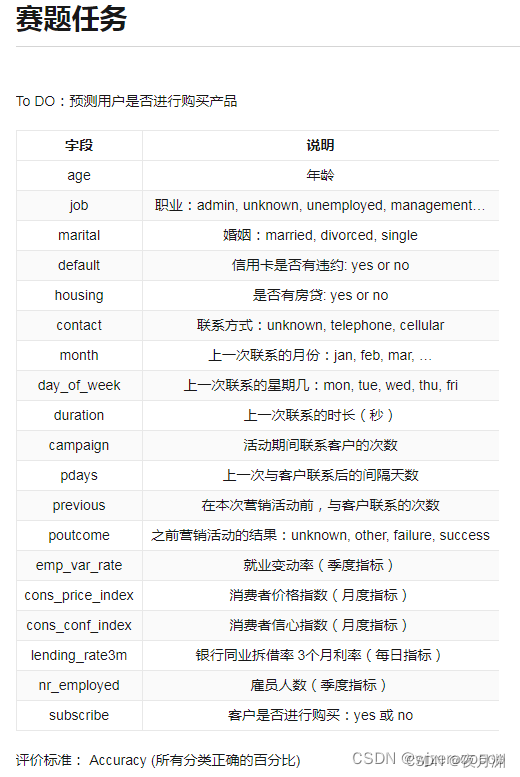
本赛题以银行产品认购预测为背景,旨在预测客户是否会购买银行的产品。在与客户沟通的过程中,记录了联系次数、上一次联系时长和时间间隔,同时在银行系统中保存了客户的基本信息,包括年龄、职业、婚姻状况、是否违约以及是否有房贷等。此外还统计了当前市场的情况,例如就业和消费信息以及银行同业拆借利率等。
一、背景【教学赛】金融数据分析赛题1:银行客户认购产品预测-天池大赛-阿里云天池
本赛题以银行产品认购预测为背景,旨在预测客户是否会购买银行的产品。在与客户沟通的过程中,记录了联系次数、上一次联系时长和时间间隔,同时在银行系统中保存了客户的基本信息,包括年龄、职业、婚姻状况、是否违约以及是否有房贷等。此外还统计了当前市场的情况,例如就业和消费信息以及银行同业拆借利率等。
用户购买预测是数字化营销领域中的重要应用场景,通过这道赛题,鼓励学习者利用营销活动信息,为企业提供销售策略,也为消费者提供更适合的商品推荐
比赛链接:https://tianchi.aliyun.com/competition/entrance/531993/forum
二、数据探索
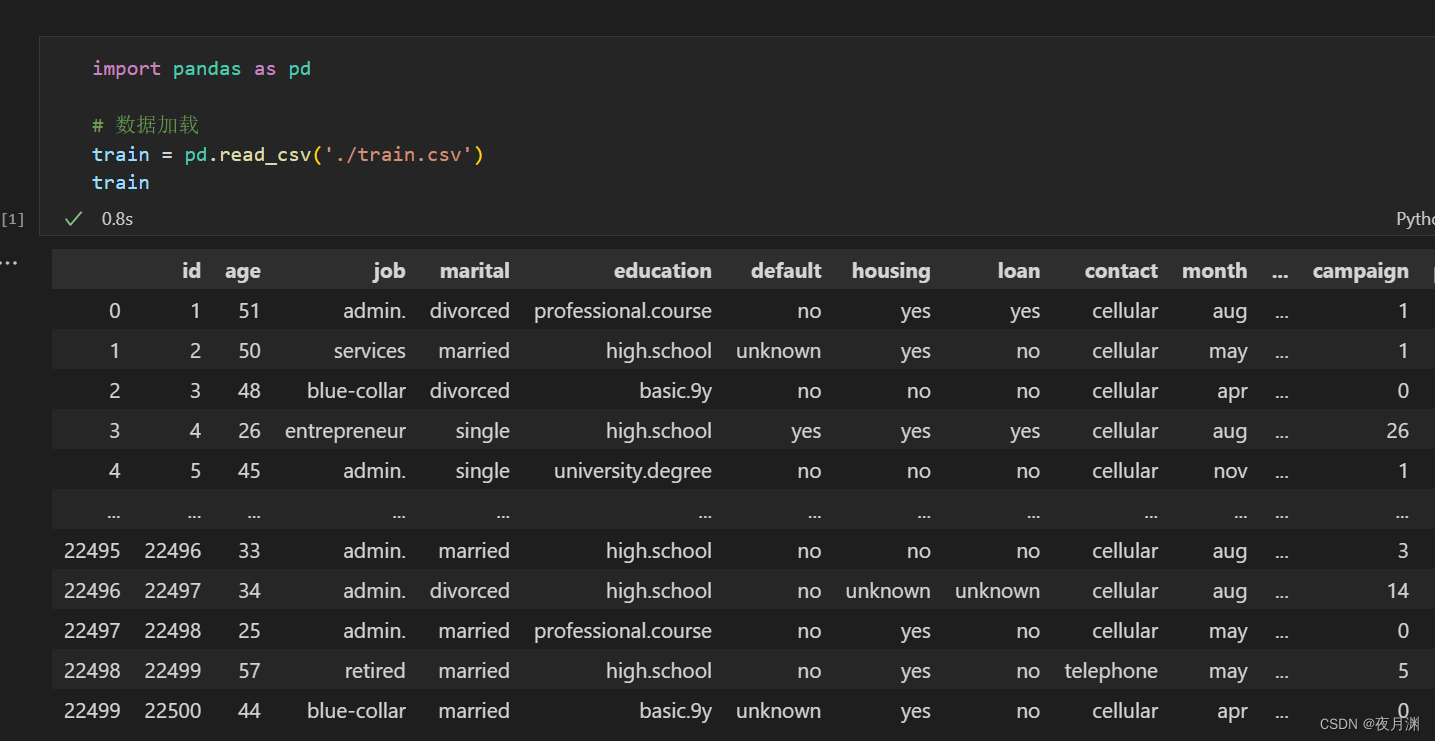
加载后数据出来
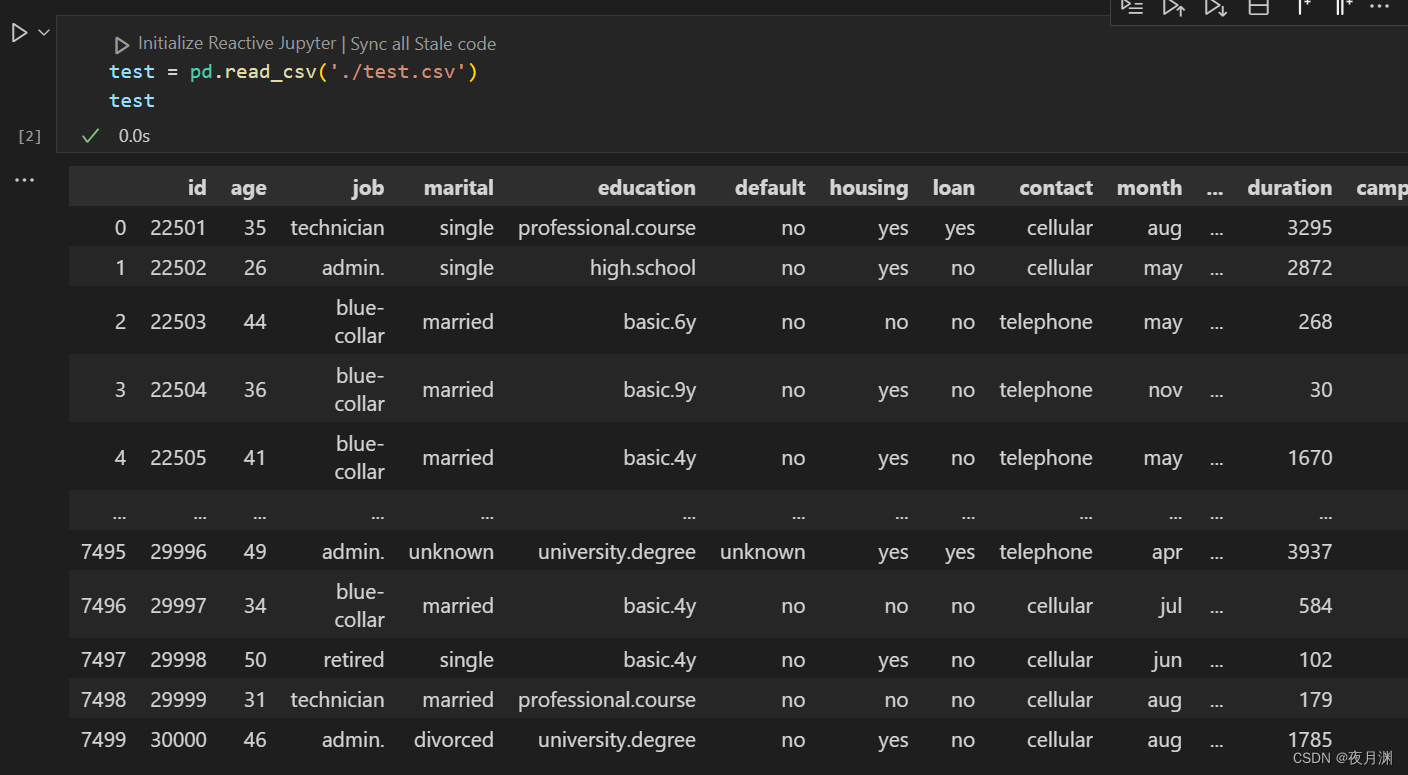

三、数据图像
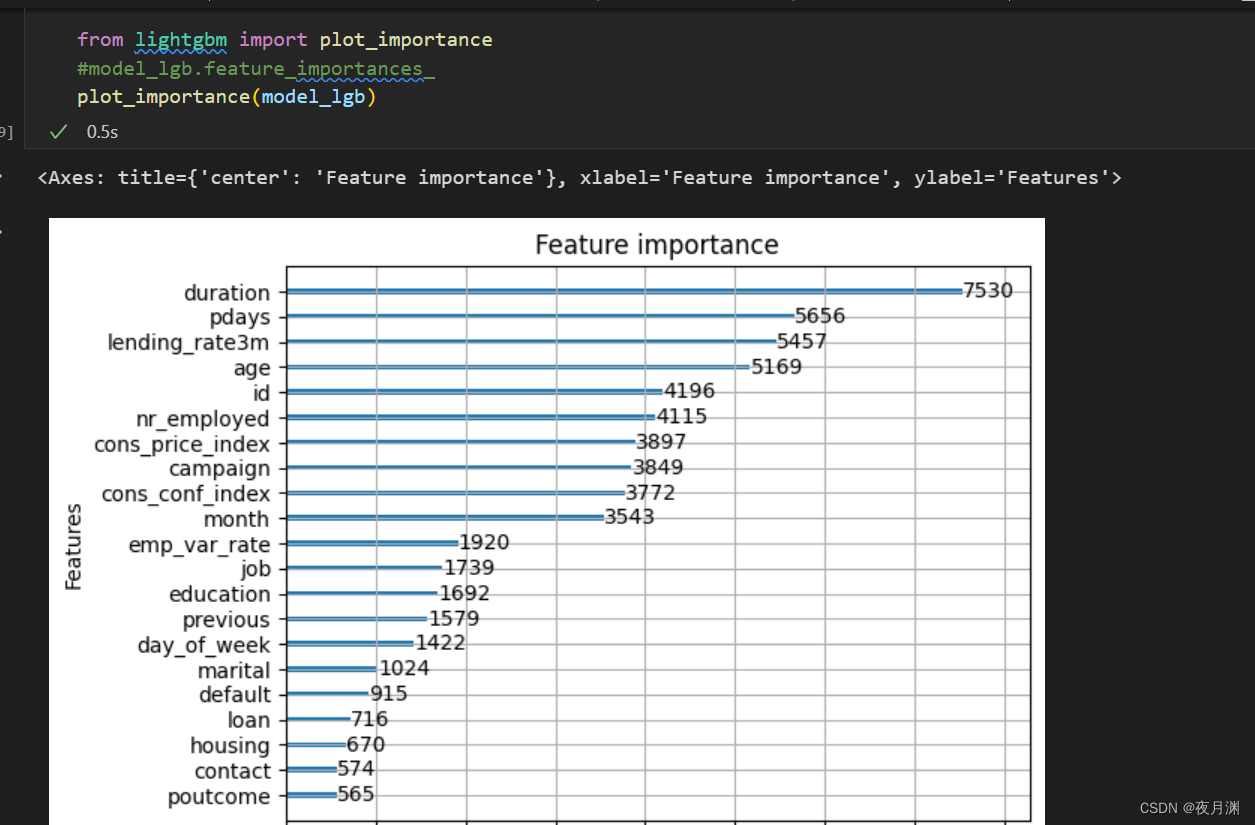
四、结果输出
从这里可以方便的看数据出来的结果

把数据保存并转为了csv文件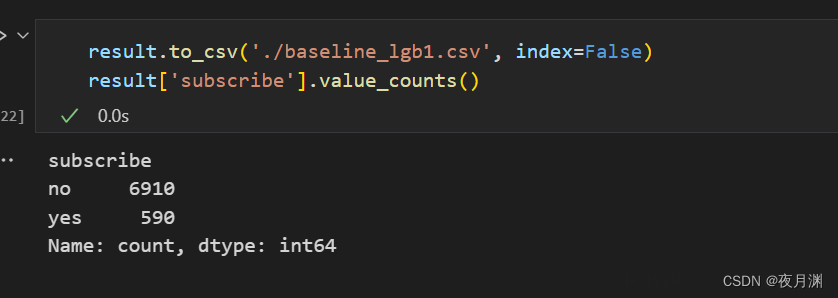
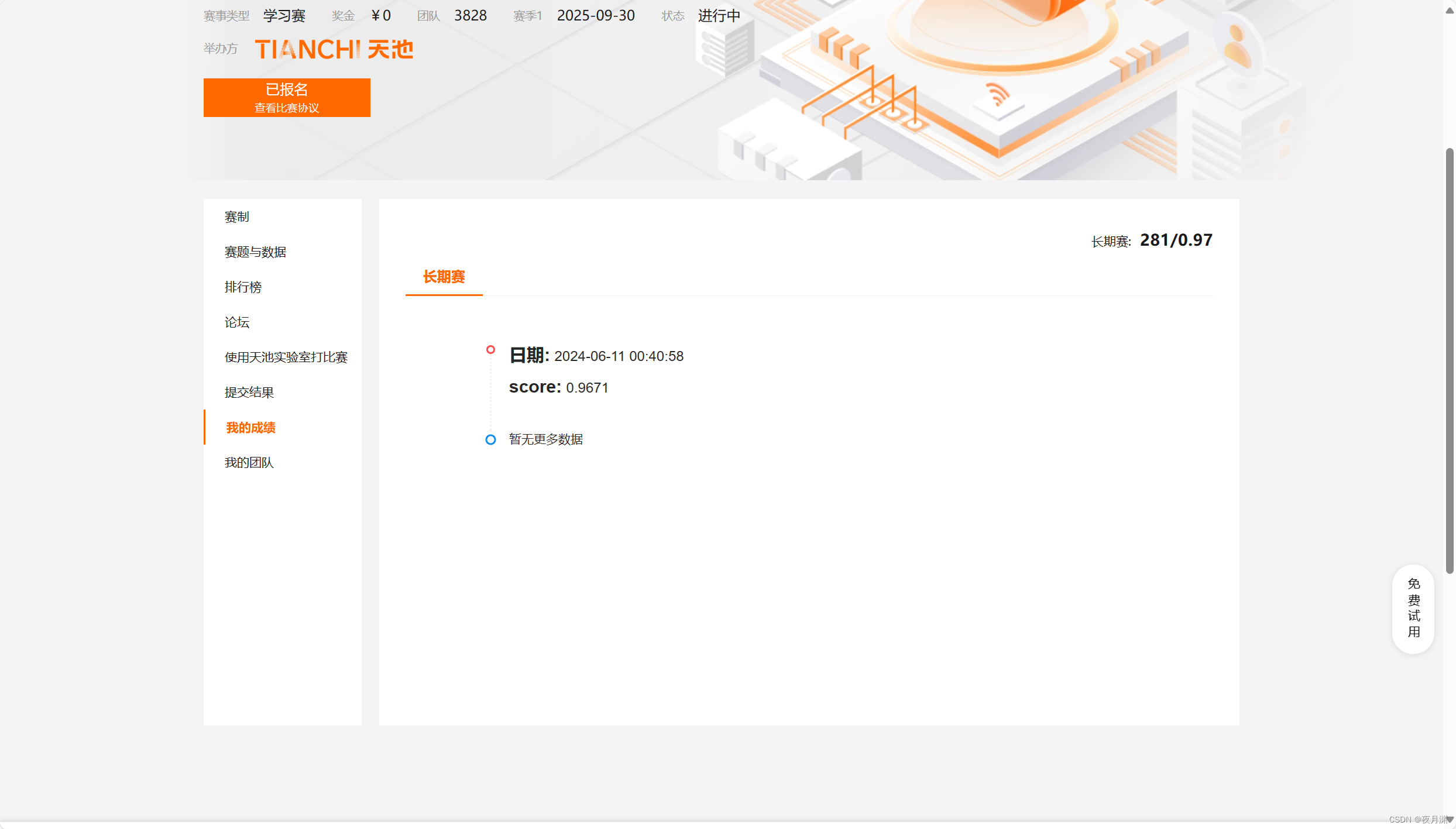
五、最终成绩
代码:
import pandas as pd
# 数据加载
train = pd.read_csv('./train.csv')
train
test = pd.read_csv('./test.csv')
test
# 训练集、测试集合并
df =pd.concat([train, test], axis=0)
df
cat_columns = df.select_dtypes(include='O').columns
df[cat_columns]
from sklearn.preprocessing import LabelEncoder
job_le = LabelEncoder()
df['job'] = job_le.fit_transform(df['job'])
df['job'].value_counts()
df['marital'].value_counts()
df['marital'] = df['marital'].map({'unknown': 0, 'single': 1, 'married': 2, 'divorced': 3})
df['marital'].value_counts()
df['education'].value_counts()
df['education'].value_counts()
df['education'] = df['education'].map({'unknown': 0, 'illiterate': 1, 'basic.4y': 2, 'basic.6y': 3,\
'basic.9y': 4, 'high.school': 5, 'university.degree': 6, 'professional.course': 7})
df['education'].value_counts()
#housing loan contact month day_of_week poutcome
df['housing'].value_counts()
df['housing'] = df['housing'].map({'unknown': 0, 'no': 1, 'yes': 2})
df['housing'].value_counts()
df['loan'] = df['loan'].map({'unknown': 0, 'no': 1, 'yes': 2})
df['loan'].value_counts()
df['contact'] = df['contact'].map({'cellular': 0, 'telephone': 1})
df['contact'].value_counts()
# mon: 0, tue: 1, wed: 2, thu: 3, fri: 4
df['day_of_week'].value_counts()
df['day_of_week'] = df['day_of_week'].map({'mon': 0, 'tue': 1, 'wed': 2, 'thu': 3, 'fri': 4})
df['day_of_week'].value_counts()
df['poutcome'] = df['poutcome'].map({'nonexistent': 0, 'failure': 1, 'success': 2})
df['poutcome'].value_counts()
df['default'].value_counts()
df['default'] = df['default'].map({'unknown': 0, 'no': 1, 'yes': 2})
df['default'].value_counts()
#df[cat_columns]
df['month'] = df['month'].map({'mar': 3, 'apr': 4, 'may': 5, 'jun': 6, 'jul': 7, 'aug': 8, \
'sep': 9, 'oct': 10, 'nov': 11, 'dec': 12})
df['month'].value_counts()
df[cat_columns]
df['subscribe'] = df['subscribe'].map({'no': 0, 'yes': 1})
df['subscribe'].value_counts()
# 切分数据集
train = df[df['subscribe'].notnull()]
test = df[df['subscribe'].isnull()]
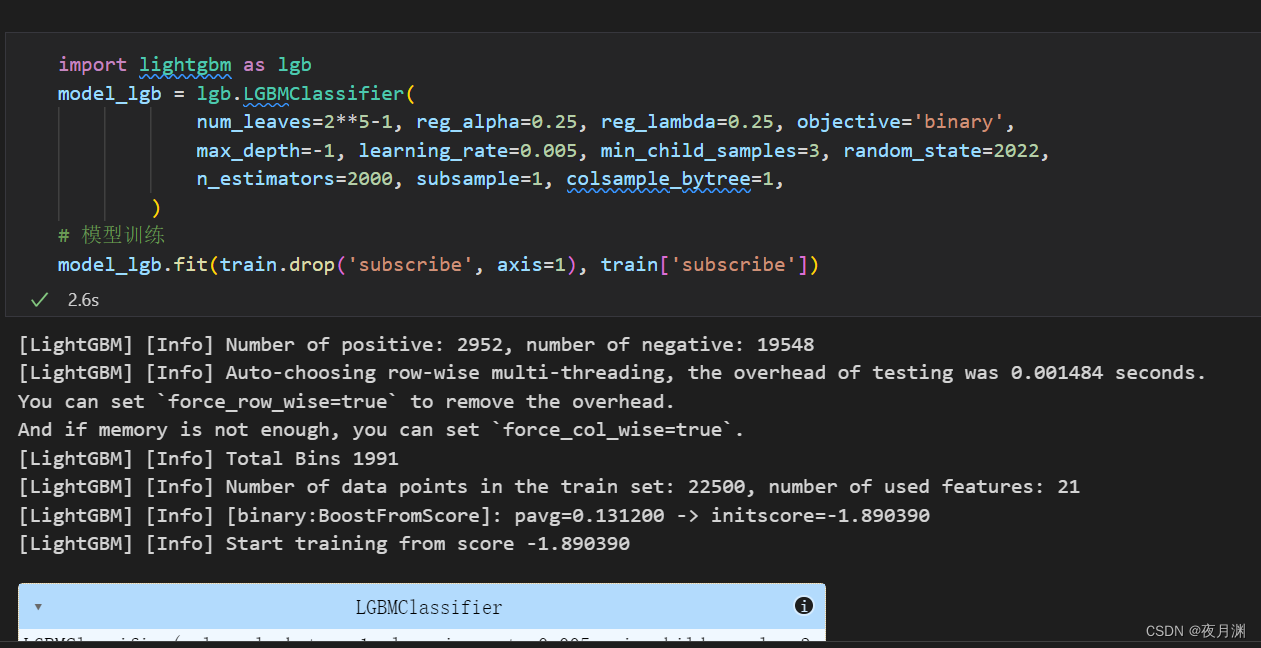
import lightgbm as lgb
model_lgb = lgb.LGBMClassifier(
num_leaves=2**5-1, reg_alpha=0.25, reg_lambda=0.25, objective='binary',
max_depth=-1, learning_rate=0.005, min_child_samples=3, random_state=2022,
n_estimators=2000, subsample=1, colsample_bytree=1,
)
# 模型训练
model_lgb.fit(train.drop('subscribe', axis=1), train['subscribe'])
from lightgbm import plot_importance
#model_lgb.feature_importances_
plot_importance(model_lgb)
y_pred = model_lgb.predict(test.drop('subscribe', axis=1))
y_pred
#sum(y_pred)
result = pd.read_csv('./submission.csv')
subscribe_map ={1: 'yes', 0: 'no'}
result['subscribe'] = [subscribe_map[x] for x in y_pred]
result
result.to_csv('./baseline_lgb1.csv', index=False)
result['subscribe'].value_counts()
总结
1. 类似违约、欺诈的这种案例样本,负样本的比例都是相对较少的,模型在正样本的表现都是不错的,但识别负样本的效果往往一般, 所以实际项目中如何提升模型识别负样本的精度及召回率才是重点,毕竟大部分项目负样本才是我们关心的。
2. 就本赛事的结果Accuracy,由于样本不平衡,即使所有样本都为正,Accuracy也能有0.92,但这种模型本身不具备识别负样本的能力,所以还得结合precision、recall等指标参考。
3. 实际项目中不要依赖于一个算法,可以综合多个算法的结果进行比较来对负样本进行预测筛查,然后结合原始数据的特征及业务经验对负样本进行再次筛选。















 4175
4175

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









