






一、技术原理与核心差异
1.1 RAG(检索增强生成)
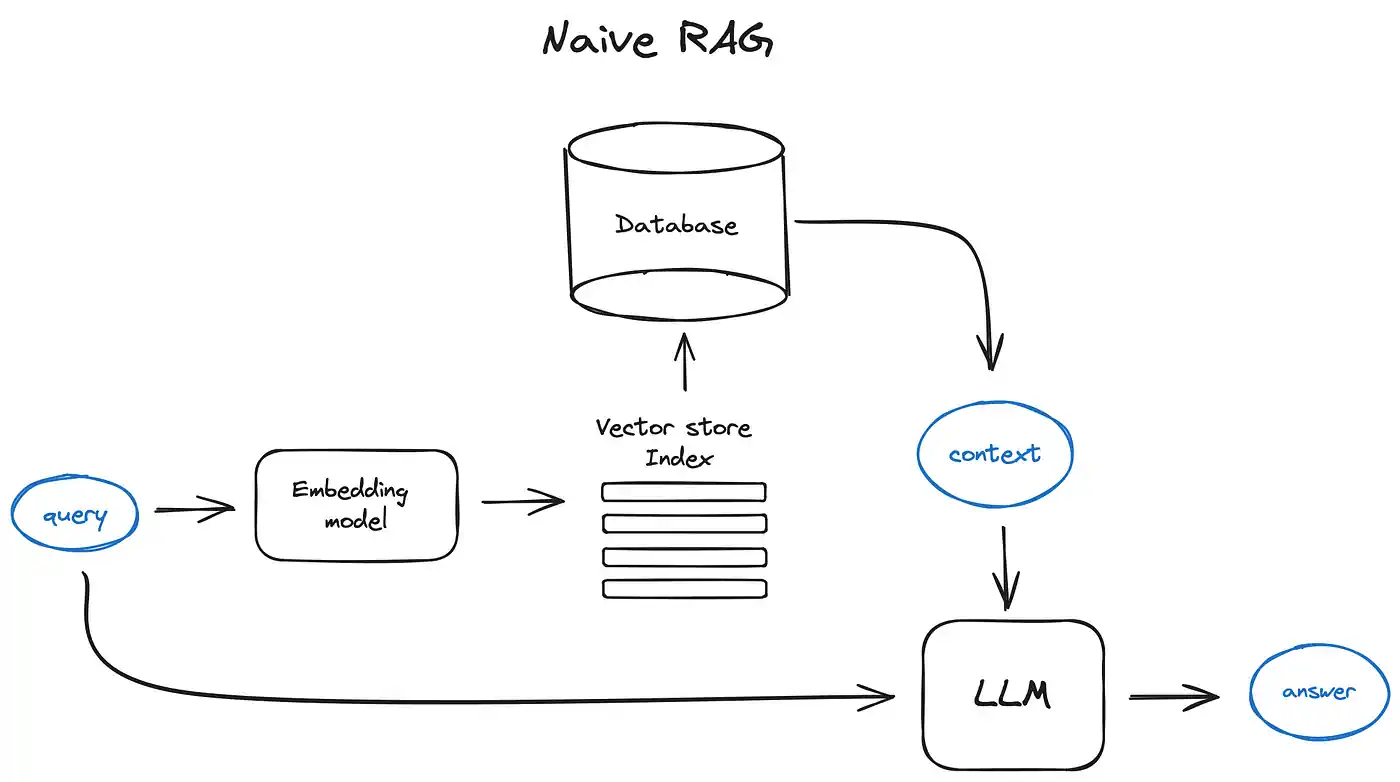
- 原理:将外部知识库与大模型结合,生成时先检索相关信息,再融合生成内容。
- 核心优势:
- 知识实时更新:通过更新知识库即可引入新信息,无需重新训练模型。
- 可控性强:答案可溯源至知识库,减少幻觉问题。
- 适应数据稀疏场景:无需大量标注数据,适合冷启动业务。
- 局限性:
- 依赖检索质量:若知识库结构混乱或检索算法不佳,可能返回无关信息。
- 系统复杂度高:需额外构建检索器、向量数据库等组件。
1.2 微调(Fine-Tuning)
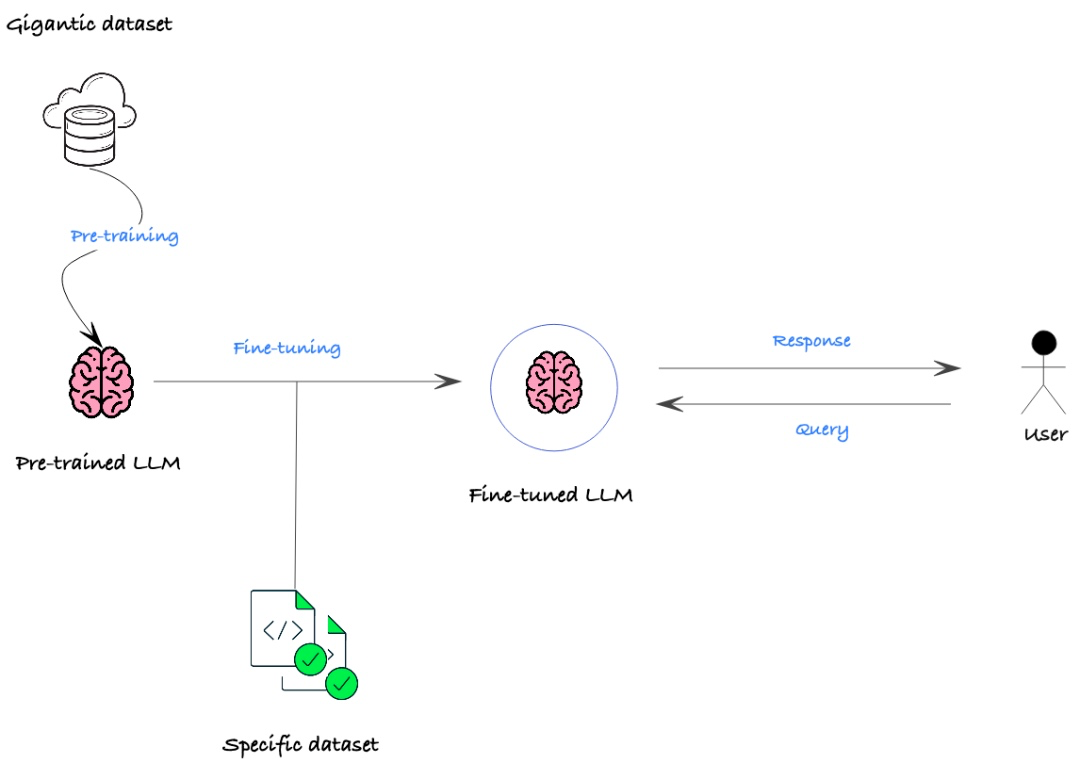
- 原理:基于预训练模型,用特定任务数据调整参数,使其适配新任务。
- 核心优势:
- 任务性能优化:在特定任务上可超越基础模型,如医疗报告生成。
- 输出一致性:风格和质量可控,适合品牌内容生成。
- 局限性:
- 数据要求高:需大量高质量标注数据,标注成本高。
- 更新成本高:每次知识更新需重新训练,周期长。
二、场景对比与选型指南
2.1 适用场景对比
| 维度 | RAG | 微调 |
|---|---|---|
| 数据量 | 数据稀疏或无标注数据 | 数据丰富且标注质量高 |
| 时效性 | 需实时更新知识(如金融、新闻) | 知识相对稳定(如法律条款) |
| 任务类型 | 知识密集型(如专业问答) | 特定任务优化(如客服话术生成) |
| 成本 | 低(维护知识库) | 高(训练资源、时间) |
| 灵活性 | 快速响应业务变化 | 需重新训练才能适应新需求 |
2.2 典型业务场景选型
- RAG 优先场景:
- 金融风控:实时检索市场动态,生成投资建议。
- 医疗咨询:结合最新临床指南,回答患者问题。
- 微调优先场景:
- 法律文书生成:通过训练模型掌握法律条款,生成合同。
- 客服话术优化:提升特定话术的生成质量。
三、混合使用策略与实战案例
3.1 混合策略类型
-
阶段式混合:
- 先 RAG 后微调:先用 RAG 快速生成内容,再用微调优化特定部分。例如,电商场景中用 RAG 生成商品描述,再微调模型统一品牌风格。
- 先微调后 RAG:先用微调让模型掌握领域知识,再用 RAG 补充实时信息。例如,医疗领域先微调模型理解术语,再用 RAG 接入最新研究数据。
-
动态路由:
- 根据问题类型自动选择路径。例如,简单问题调用微调模型快速响应,复杂问题触发 RAG 检索。
-
协同训练:
- RAG 检索结果作为训练数据,动态更新微调模型。例如,法律科技公司用 RAG 检索判例,再用微调模型生成法律分析。
3.2 实战案例
- 案例 1:法律科技公司:
- 策略:微调模型掌握法律条款,RAG 检索最新判例。
- 效果:客户满意度提升 37%,响应速度提高 50%。
- 案例 2:制造业客服:
- 策略:动态路由,简单问题用微调模型,复杂问题用 RAG。
- 效果:平均响应时间从 3 秒降至 1 秒,准确率提升 20%。
四、技术实现与优化技巧
4.1 RAG 技术优化
- 混合检索:结合稀疏检索(BM25)和密集检索(向量搜索),提升准确性和效率。
- 检索增强:使用 HyDE(假设性文档嵌入)生成假设性答案,增强检索相关性。
4.2 微调技术优化
- 参数高效微调:如 LoRA、QLoRA,减少训练资源消耗。
- 增量微调:逐步引入新数据,避免过拟合。
4.3 混合策略实现
- 动态路由架构:
python
def hybrid_inference(query): if is_simple_query(query): return fine_tuned_model(query) else: docs = rag_retrieve(query) return rag_generate(query, docs) - 协同训练流程:
- RAG 生成候选答案。
- 人工标注或用 LLM 评估答案质量。
- 用标注数据微调模型。
- 重复迭代优化。
五、评估与成本分析
5.1 评估指标
- RAG 评估:
- 上下文召回率:检索到的信息覆盖答案关键信息的比例。
- 忠实度:答案是否基于检索内容生成。
- 微调评估:
- 准确率:任务特定指标(如分类准确率、F1 值)。
- 一致性:输出风格是否统一。
5.2 成本对比
| 成本类型 | RAG | 微调 |
|---|---|---|
| 训练成本 | 无 | 高(需 GPU 资源、时间) |
| 维护成本 | 中(知识库更新) | 高(重新训练) |
| 推理成本 | 高(检索开销) | 低(直接调用模型) |
六、总结与建议
6.1 选型决策树
- 第一步:判断数据量。数据稀疏 → RAG;数据丰富 → 微调。
- 第二步:判断时效性。需实时更新 → RAG;知识稳定 → 微调。
- 第三步:判断任务复杂度。复杂任务 → 混合策略;简单任务 → 单一方法。
6.2 企业落地建议
- 中小规模企业:优先采用 RAG,快速验证业务价值。
- 大型企业:关键任务用微调,边缘场景用 RAG,构建混合架构。
- 技术团队:关注参数高效微调和混合检索技术,降低成本。
通过合理选择 RAG、微调或混合策略,企业可在效率、准确性和成本之间找到平衡,推动大模型技术的高效落地。

















 23万+
23万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









