







本文对CS231中的Training Neural Networks的权重更新部分进行记录
权重的初始化在深度神经网络中起着比较大的重要,算是一个trick,但在实际应用上确是个大杀器。
1. 如果一开始把网络中的权重初始化为0,会发生什么?
因为权重初始为0, 由于网络中的神经元的更新机制完全相同,由于网络的对称性,会产生各个layer中产生相同的梯度更新,导致所有的权重最后值相同,收敛会出现问题。
所以在初始化参数的时候,一个重要的设置原则就是破坏不同单元的对称性质。
2. 一个简单的方法,初始化一个比较小的值
高斯初始化,给权重较小的值。这种更新方式在小网络中很常见,然而当网络deep的时候,会出现梯度弥散的情况

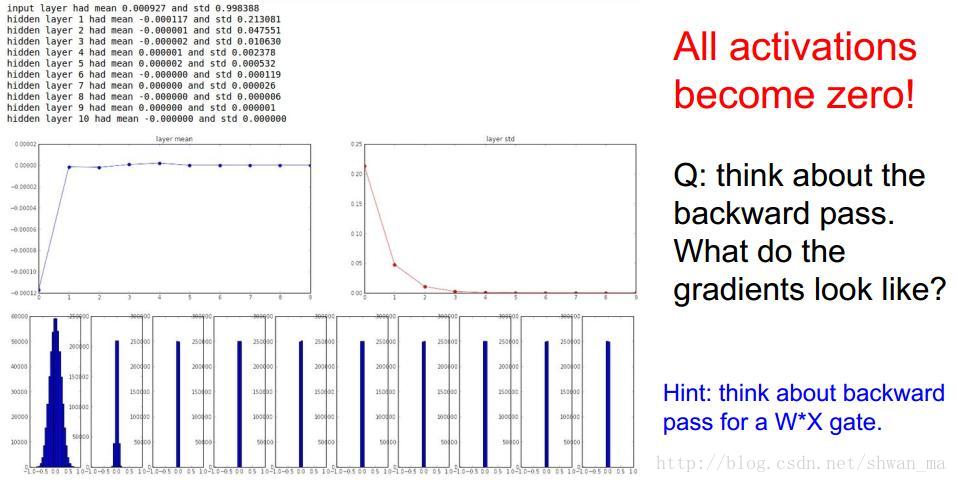
从图上可以发现,第一层的output分布正常,之后的layer中逐渐趋于0。这很好理解(0.9^30 = 0.04), 在前向网络中,W*X,会导致神经元不被激活。
但是如果把权重初始成一个比较大的值,如
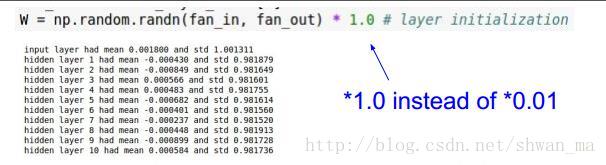
则会造成前向传播时,神经元要么被抑制,要么被饱和。
梯度更新时,也会出现梯度弥散
3. Xaiver更新方法
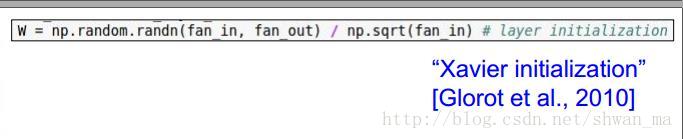
这个方法在以tanh为激活函数中,很work
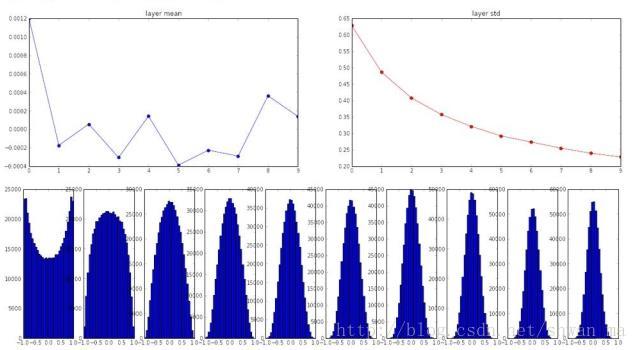
每一层的输出基本满足高斯分布,梯度更新时,收敛速度较好
然而这种方法没有考虑以relu为激活函数的情况
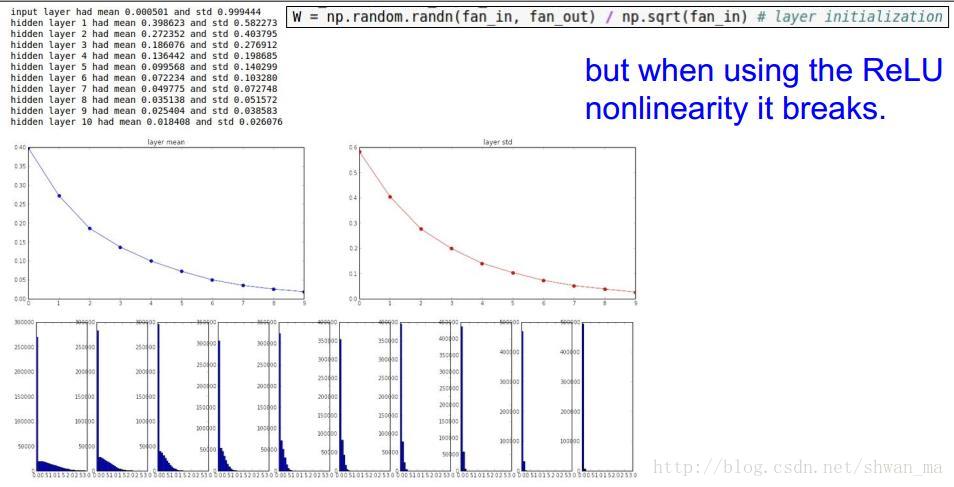
4. He更新方法
由于Relu激活函数的特性,他在x的负半轴中是不激活的,所以应该在方差中考虑仅取一半,He et.al 2015指出以下初始方式:

仅仅在分母增加了 1/2。
此时,在每个layer中还是能看清楚输出分布的:
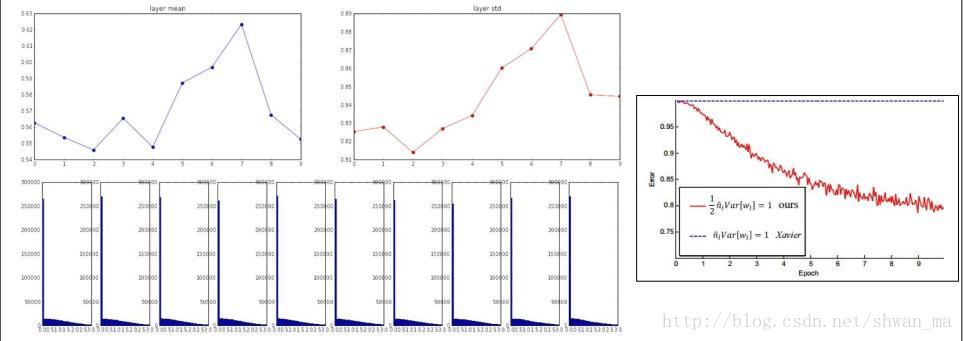
事实上,如果权值初始化有问题的话,可以在激活函数前加入Batch Normalization Layer。
由于我也是初学,有错误欢迎各位指正
以上















 1122
1122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









