







2021SC@SDUSC
代码位置:ppocr\postprocess\east_postprocess.py
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import numpy as np
from .locality_aware_nms import nms_locality
import cv2
import paddle
import os
import sys
class EASTPostProcess(object):
"""
The post process for EAST.
"""
def __init__(self,
score_thresh=0.8,
cover_thresh=0.1,
nms_thresh=0.2,
**kwargs):
self.score_thresh = score_thresh
self.cover_thresh = cover_thresh
self.nms_thresh = nms_thresh
# c++ la-nms is faster, but only support python 3.5
self.is_python35 = False
if sys.version_info.major == 3 and sys.version_info.minor == 5:
self.is_python35 = True
def restore_rectangle_quad(self, origin, geometry):
"""
Restore rectangle from quadrangle.
"""
# quad
origin_concat = np.concatenate(
(origin, origin, origin, origin), axis=1) # (n, 8)
pred_quads = origin_concat - geometry
pred_quads = pred_quads.reshape((-1, 4, 2)) # (n, 4, 2)
return pred_quads
def detect(self,
score_map,
geo_map,
score_thresh=0.8,
cover_thresh=0.1,
nms_thresh=0.2):
"""
restore text boxes from score map and geo map
"""
score_map = score_map[0]
geo_map = np.swapaxes(geo_map, 1, 0)
geo_map = np.swapaxes(geo_map, 1, 2)
# filter the score map
xy_text = np.argwhere(score_map > score_thresh)
if len(xy_text) == 0:
return []
# sort the text boxes via the y axis
xy_text = xy_text[np.argsort(xy_text[:, 0])]
#restore quad proposals
text_box_restored = self.restore_rectangle_quad(
xy_text[:, ::-1] * 4, geo_map[xy_text[:, 0], xy_text[:, 1], :])
boxes = np.zeros((text_box_restored.shape[0], 9), dtype=np.float32)
boxes[:, :8] = text_box_restored.reshape((-1, 8))
boxes[:, 8] = score_map[xy_text[:, 0], xy_text[:, 1]]
if self.is_python35:
import lanms
boxes = lanms.merge_quadrangle_n9(boxes, nms_thresh)
else:
boxes = nms_locality(boxes.astype(np.float64), nms_thresh)
if boxes.shape[0] == 0:
return []
# Here we filter some low score boxes by the average score map,
# this is different from the orginal paper.
for i, box in enumerate(boxes):
mask = np.zeros_like(score_map, dtype=np.uint8)
cv2.fillPoly(mask, box[:8].reshape(
(-1, 4, 2)).astype(np.int32) // 4, 1)
boxes[i, 8] = cv2.mean(score_map, mask)[0]
boxes = boxes[boxes[:, 8] > cover_thresh]
return boxes
def sort_poly(self, p):
"""
Sort polygons.
"""
min_axis = np.argmin(np.sum(p, axis=1))
p = p[[min_axis, (min_axis + 1) % 4,\
(min_axis + 2) % 4, (min_axis + 3) % 4]]
if abs(p[0, 0] - p[1, 0]) > abs(p[0, 1] - p[1, 1]):
return p
else:
return p[[0, 3, 2, 1]]
def __call__(self, outs_dict, shape_list):
score_list = outs_dict['f_score']
geo_list = outs_dict['f_geo']
if isinstance(score_list, paddle.Tensor):
score_list = score_list.numpy()
geo_list = geo_list.numpy()
img_num = len(shape_list)
dt_boxes_list = []
for ino in range(img_num):
score = score_list[ino]
geo = geo_list[ino]
boxes = self.detect(
score_map=score,
geo_map=geo,
score_thresh=self.score_thresh,
cover_thresh=self.cover_thresh,
nms_thresh=self.nms_thresh)
boxes_norm = []
if len(boxes) > 0:
h, w = score.shape[1:]
src_h, src_w, ratio_h, ratio_w = shape_list[ino]
boxes = boxes[:, :8].reshape((-1, 4, 2))
boxes[:, :, 0] /= ratio_w
boxes[:, :, 1] /= ratio_h
for i_box, box in enumerate(boxes):
box = self.sort_poly(box.astype(np.int32))
if np.linalg.norm(box[0] - box[1]) < 5 \
or np.linalg.norm(box[3] - box[0]) < 5:
continue
boxes_norm.append(box)
dt_boxes_list.append({'points': np.array(boxes_norm)})
return dt_boxes_list
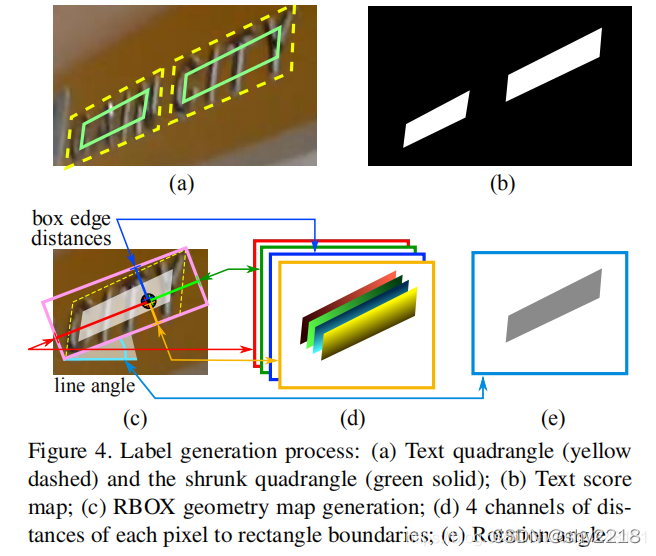
对于一个四边形 Q = {pi|i ∈ {1, 2, 3, 4}},pi = {xi, yi},表示四边形的顺时针方向的四个顶点,从上图可以看到,我们最终要的是(a)中绿色框的部分,即相对于黄色的虚线框缩小一定程度可以得到绿色的框。为了缩小Q,先对于每个顶点pi计算一个长度ri:
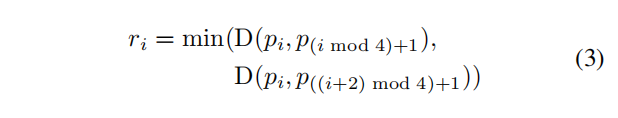
可以看到,上述公式要表达的意思就是该顶点连接的两条边取最短的那一条。缩小Q的过程大致如下:先缩小较长的两条边,然后缩小较短的两条边。对于每两个相对的边,决定谁是更长的一对的方式是比较他们长度的均值。对于每条边 (pi, p(i mod 4)+1),我们通过将其两个端点沿着边向内分别移动0.3ri和0.3r(i mod 4)+1。
geometry map的生成方式如下:首先用一个旋转的矩形,用最小的面积可以覆盖住该文本区域。然后对于每个有正例得分的像素,计算他到四个文本框边界的距离,并且使其作为RBOX的ground truth的4个通道,而对于QUAD ground truth,在其8通道的geometry map上每个正得分像素的值是它的四边形的四个顶点到它的坐标的偏移。
代码实现上有很多细节部分,例如参照了https://github.com/SakuraRiven/EAST这一份工程的代码:
在生成score_map的时候,是基于原图的四分之一大小(因为输出的特征图的大小就是四分之一原图大小),然后在缩小时先缩短较长的两边,假设该边edge1的两个点时v1,v2,对于v1和v2两点各自都连着两条边v1(r1,r2),v2(r2,r3),取和两个点相连的短边(可能是r1和r3,也可能都是r2,这里假设是r1和r3),然后分别将v1和v2两点沿着该边的方向向内移动0.3r1和0.3r3的长度。
在生成geo_map的时候,先每隔1度遍历所有角度(-90,90),找到最小外接矩形和矩形的角度,然后旋转文本框旋转到theta=0的水平状态,这样是为了方便计算d1,d2,d3,d4。
另外还有一个ignore_map,在ICDAR_2015数据集中,有些标签是“###”,这个表示是无法看清的一些文本,该代码中会把这些区域取出来,然后忽略掉这些区域,个人觉得这个也是为了防止误检。

















 4180
4180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









