






现实中不是所有的问题都不存在约束,这一章就是讲解存在约束情况下如何求解最优化问题。可行方向法就是无约束下降算法的自然推广,从初始点出发,沿着可行下降方向进行搜索,求出使目标函数下降的可行点。
1.ZoutendijK可行方向法

目标函数是非线性,约束条件是线性的
step1: 可行方向
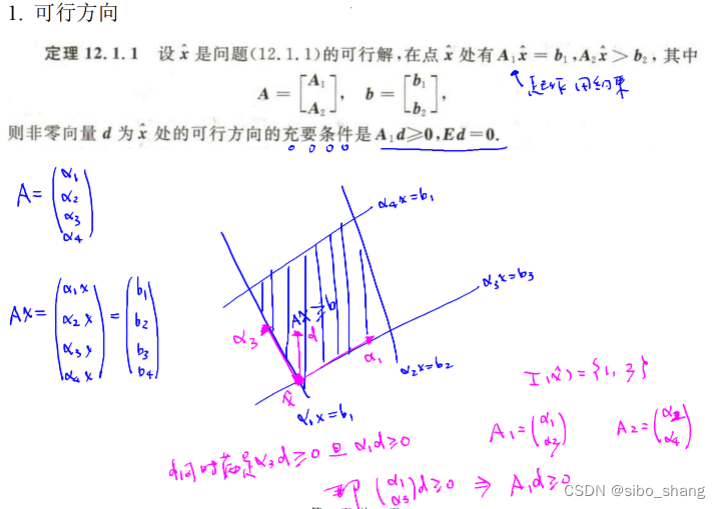
如图所示,假设初始点在1,3约束的边界,那么积极约束就是和
,那么可行方向就应该跟他们两个都成锐角,即内积都大于0.
step2:可行下降方向

再加上下降条件,则要保证该点的梯度值和方向乘积为负,这样问题就转化为一个线性规划问题,即图片右侧。最后的结果如果接近0,则该点就是要找的KT点,如果不是0,则d为可行下降方向。(终止条件)
step3:终止条件

step4:确定步长

这样我们就可以求得步长的最大值,然后进行一维搜索找到最优值。
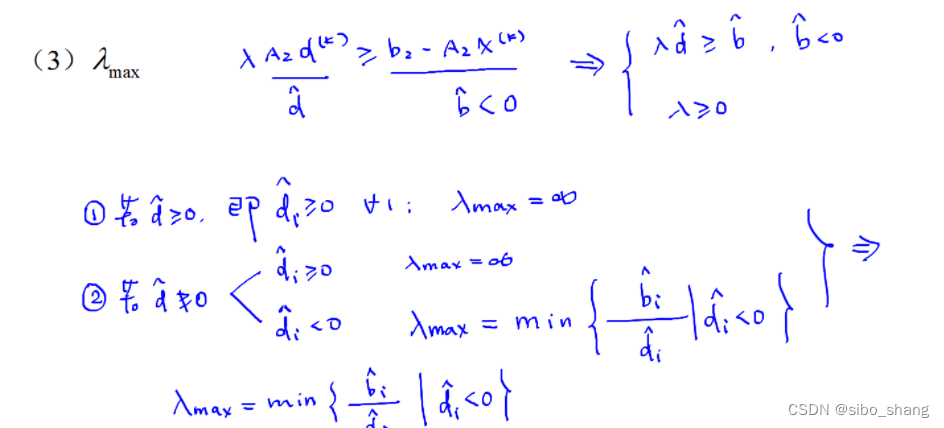
例题与代码:

代码如下:
%-------------------------------------
% Zoutendijk feasible direction method
%-------------------------------------
function [xstar,ystar] = zoutendijk(fun,A,b,E,e)
epsilon = 0.01;
% Initial feasible point 用于获取初始可行点的函数
x = inifeapoi(A,b,E,e);
% Iteration
while 1
% Feasible descent direction
[d,grad] = feadesdir(fun,A,b,E,e,x);
% If it is a K-T point
if abs(grad'*d) <= epsilon
xstar = x;
ystar = fun(xstar);
return;
end
% Line search
lambda = linesearch(fun,A,b,x,d);
% Update
x = x+lambda*d;
end
%-------------------------------------
% Initial feasible point
%-------------------------------------
function x = inifeapoi(A,b,E,e)
%生成一个函数,norm(v)默认计算向量的二范数 f函数计算的是二次型的残差函数
%其目的是为了通过fminsearch寻找满足等式约束的初始点x
f = @(x) 0.5*(norm(E*x-e))^2;
while 1
[~,n] = size(A); %获取矩阵的列数
x = -5+10*rand(n,1); %生成一个每个维度都在[-5,5]的向量
if ~isempty(E)
%fminsearch 函数是一种无约束优化方法,但由于在这里已经通过等式约束限制了搜索空间,因此可以用来寻找初始可行点
%fminsearch 使用无导数法计算无约束的多变量函数的最小值
x = fminsearch(f,x);
end
if all(A*x >= b)
break
end
end
%-------------------------------------
% Feasible descent direction
%-------------------------------------
function [d,grad] = feadesdir(fun,A,b,E,e,x)
epsilon = 0.01;
[~,grad] = fun(x); %获取当前点的梯度
temp = A*x;
A1 = A(temp<=b+epsilon,:); %从约束矩阵中取出满足不等式约束的矩阵(积极约束的点)
f = grad';
Aineq = -A1;
bineq = zeros(length(Aineq(:,1)),1);
if isempty(E)
Aeq = E;
beq = e;
else
Aeq = E;
beq = zeros(length(Aeq(:,1)),1);
end
lb = -1*ones(length(x),1);
ub = ones(length(x),1);
%在这里就将非线性规划转化为线性规划
d = linprog(f,Aineq,bineq,Aeq,beq,lb,ub);
%-------------------------------------
% Line search
%-------------------------------------
function lambda = linesearch(fun,A,b,x,d)
epsilon = 0.01;
temp = A*x;
A1 = A(temp<=b+epsilon,:);
A2 = A(temp>b+epsilon,:);
b1 = b(temp<=b+epsilon);
b2 = b(temp>b+epsilon);
b_hat = b2-A2*x;
d_hat = A2*d;
if all(d_hat>=0)
lambda_max = 10;
else
lambda_max = min(b_hat(d_hat<0)./d_hat(d_hat<0));
end
lineobjfun = @(lambda) fun(x+lambda*d);
lambda = fminbnd(lineobjfun,0,lambda_max);目标函数:
function [y,g] = objfun(x)
y = x(1)^2+x(2)^2-2*x(1)-4*x(2)+6;
g = [2*x(1)-2;2*x(2)-4];主函数:
f = @(x) objfun(x);
A = [-2 1;-1 -1;1 0;0 1];
b = [-1;-2;0;0];
E = [];
e = [];
[xstar,ystar] = zoutendijk(f,A,b,E,e)2.Rosen投影梯度法
有关基础知识,涉及向量组生成的子空间,值空间,核空间(零空间),投影矩阵

基本思想和证明:

其核心还是求可行下降方向。
步骤和代码:

%-------------------------------------
% Rosen gradient projection method
%-------------------------------------
function [xstar,ystar] = rosen(fun,A,b,E,e)
epsilon = 0.01;
% Initial feasible point
x = iniFeaPoi(A,b,E,e);
% Iteration
while 1
% Separate active constraints
A1 = activeCon(A,b,x);
while 1
M = [A1;E];
% Compute gradient project direction
[~,grad] = fun(x);
P = gradProjMat(M,x);
d = -P*grad;
% If d is zero
if norm(d) <= epsilon
% If M is empty,x is a local minimum
if isempty(M)
xstar = x;
ystar = fun(xstar);
return;
else
W = (M*M')^-1*M*grad;
u = W(1:length(A1(:,1)));
% If all u>=0, x is a K-T point
if all(u>=0)
xstar = x;
ystar = fun(xstar);
return;
else
[~,j] = min(u);
A1(j,:) = [];
continue;
end
end
else
break;
end
end
% Line search
lambda = linesearch(fun,A,b,x,d);
% Update
x = x+lambda*d;
end
%-------------------------------------
% Initial feasible point
%-------------------------------------
function x = iniFeaPoi(A,b,E,e)
f = @(x) 0.5*(norm(E*x-e))^2;
while 1
[~,n] = size(A);
x = -5+10*rand(n,1);
if ~isempty(E)
x = fminsearch(f,x);
end
if all(A*x >= b)
break
end
end
x = [0,0]';
%-------------------------------------
% Separate active constraints
%-------------------------------------
function A1 = activeCon(A,b,x)
epsilon = 0.01;
act_idx = A*x<=b+epsilon;
A1 = A(act_idx,:);
%-------------------------------------
% Compute gradient projection matrix
%-------------------------------------
function P = gradProjMat(M,x)
if isempty(M)
P = eye(length(x));
else
P = eye(length(x))-M'*(M*M')^-1*M;
end
%-------------------------------------
% Line search
%-------------------------------------
function lambda = linesearch(fun,A,b,x,d)
epsilon = 0.01;
temp = A*x;
A1 = A(temp<=b+epsilon,:);
A2 = A(temp>b+epsilon,:);
b1 = b(temp<=b+epsilon);
b2 = b(temp>b+epsilon);
b_hat = b2-A2*x;
d_hat = A2*d;
if all(d_hat>=0)
lambda_max = 10;
else
lambda_max = min(b_hat(d_hat<0)./d_hat(d_hat<0));
end
lineobjfun = @(lambda) fun(x+lambda*d);
lambda = fminbnd(lineobjfun,0,lambda_max);目标函数:
function [y,g] = objfun(x)
y = 2*x(1)^2+2*x(2)^2-2*x(1)*x(2)-4*x(1)-6*x(2);
g = [4*x(1)-2*x(2)-4;4*x(2)-2*x(1)-6];主函数:
f = @(x) objfun(x);
A = [-1 -1;-1 -5;1 0;0 1];
b = [-2;-5;0;0];
E = [];
e = [];
[xstar,ystar] = rosen(f,A,b,E,e)3.Frank-Wolfe方法
算法简介与原理:


代码及实现:
%-------------------------------------
% Frank&Wolfe method
%-------------------------------------
function [xstar,ystar] = frank_wolfe(fun,A,b,E,e)
epsilon = 0.01;
% Initial feasible point
x = iniFeaPoi(A,b,E,e);
% Iteration
while 1
% Solve linear programming problem
[~,grad] = fun(x);
f = grad';
Aineq = -A;
bineq = -b;
Aeq = E;
beq = e;
y = linprog(f,Aineq,bineq,Aeq,beq);
% Direction
d = y-x;
if grad'*d >= -epsilon
% x is a K-T point
xstar = x;
ystar = fun(x);
return;
else
% Line search
lambda = linesearch(fun,x,d);
end
% Update
x = x+lambda*d;
end
%-------------------------------------
% Initial feasible point
%-------------------------------------
function x = iniFeaPoi(A,b,E,e)
f = @(x) 0.5*(norm(E*x-e))^2;
while 1
[~,n] = size(A);
x = -5+10*rand(n,1);
if ~isempty(E)
x = fminsearch(f,x);
end
if all(A*x >= b)
break
end
end
x = [0,0]';
%-------------------------------------
% Line search
%-------------------------------------
function lambda = linesearch(fun,x,d)
lineobjfun = @(lambda) fun(x+lambda*d);
lambda = fminbnd(lineobjfun,0,1);目标函数:
function [y,g] = objfun(x)
y = 2*x(1)^2+2*x(2)^2-2*x(1)*x(2)-4*x(1)-6*x(2);
g = [4*x(1)-2*x(2)-4;4*x(2)-2*x(1)-6];主函数:
f = @(x) objfun(x);
A = [-1 -1;-1 -5;1 0;0 1];
b = [-2;-5;0;0];
E = [];
e = [];
[xstar,ystar] = frank_wolfe(f,A,b,E,e)Frank-wolfe 算法是一种可行方向法.使用这种方法,在每次选代中,搜索方向总是指向某个极点,并且当迭代点接近最优解时,搜索方向与目标函数的梯度趋于正交,这样的搜索方向并非最好的下降方向,因此算法收敛较慢.但是,这种方法把求解非线性规划问题转化为求解一系列线性规划,在某些情形下,也能收到较好计算效果,因此在实际应用中仍是一种有用的算法,比如,在研究交通问题时就用到这种方法。
总结:
以上三种方法均适用与约束情况下的非线性最优化问题,他们的核心就是寻找可行方向,第一个方法时将其转换为线性优化问题,第二个是利用投影方向,第三个是将目标函数线性化(泰勒),转换为线性规划问题。他们三个办法都用到了目标函数的梯度。
这篇博客中的内容和代码均来自西南科技大学理学院最优控制与数据智能团队龙强老师的课程,仅作个人学习使用,具体链接:GitHub - QiangLong2017/Optimization-Theory-and-Algorithm: 用于存放《最优化理论与算法》代码与课件


















 2663
2663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









