






什么是spaCy?
spaCy 是一个免费的开源库,用于 Python 中的高级自然语言处理(NLP)。
如果您正在处理大量文本,您最终会想了解更多有关它的信息。例如,它是关于什么的?这些词在上下文中是什么意思?谁在对谁做什么?提到了哪些公司和产品?哪些文本彼此相似?
spaCy 专为生产使用而设计,可帮助您构建处理和“理解”大量文本的应用程序。它可用于构建信息提取或自然语言理解 系统,或为深度学习预处理文本。
spaCy 不是什么
- spaCy 不是平台或“API”。与平台不同,spaCy 不提供软件即服务或 Web 应用程序。它是一个旨在帮助您构建 NLP 应用程序的开源库,而不是一个消耗性服务。
- spaCy 不是开箱即用的聊天机器人引擎。虽然 spaCy 可用于为会话应用程序提供动力,但它并非专为聊天机器人设计,仅提供底层文本处理功能。
- spaCy 不是研究软件。它建立在最新研究的基础上,但它旨在完成任务。这导致了与NLTK或 CoreNLP 完全不同的设计决策,后者是作为教学和研究平台而创建的。主要区别在于 spaCy 是集成的和固执己见的。spaCy 试图避免要求用户在提供等效功能的多个算法之间进行选择。保持菜单小,可以让 spaCy 提供更好的性能和开发人员体验。
- spaCy 不是一家公司。它是一个开源库。我们公司发布的 spaCy 和其他软件叫做 Explosion。
特征
在文档中,您会提到 spaCy 的特性和功能。其中一些涉及语言概念,而另一些则与更通用的机器学习功能有关。
| 姓名 | 描述 |
|---|---|
| Tokenization | 将文本分割成单词、标点符号等。 |
| 词性(POS)标记 | 将单词类型分配给标记,例如动词或名词。 |
| 依赖解析 | 分配句法依赖标签,描述各个标记之间的关系,如主语或宾语。 |
| 词形还原 | 分配单词的基本形式。例如,“was”的引理是“be”,“rats”的引理是“rat”。 |
| 句子边界检测(SBD) | 查找和分割单个句子。 |
| 命名实体识别(NER) | 标记命名为“真实世界”的对象,如人员、公司或位置。 |
| 实体链接(EL) | 将文本实体消歧为知识库中的唯一标识符。 |
| 相似 | 比较单词、文本跨度和文档以及它们之间的相似程度。 |
| 文本分类 | 将类别或标签分配给整个文档或文档的一部分。 |
| 基于规则的匹配 | 类似于正则表达式,根据其文本和语言注释查找标记序列。 |
| 训练 | 更新和改进统计模型的预测。 |
| 序列化 | 将对象保存到文件或字节串。 |
统计模型
虽然 spaCy 的一些功能独立工作,但其他功能需要 加载经过训练的管道,这使 spaCy 能够预测 语言注释——例如,一个词是动词还是名词。经过训练的管道可以由多个组件组成,这些组件使用在标记数据上训练的统计模型。spaCy 目前为各种语言提供训练有素的管道,可以作为单独的 Python 模块安装。管道包的大小、速度、内存使用、准确性和它们包含的数据可能不同。您选择的包始终取决于您的用例和您正在使用的文本。对于通用用例,小的默认包总是一个好的开始。它们通常包括以下组件:
- 词性标注器、依赖解析器和命名实体识别器的二进制权重,用于预测上下文中的这些注释。
- 词汇表中的词条,即单词及其与上下文无关的属性,如形状或拼写。
- 数据文件,如词形还原规则和查找表。
- 词向量,即词的多维含义表示,可让您确定它们彼此之间的相似程度。
- 配置选项,例如要使用的语言和处理管道设置和模型实现,以在加载管道时将 spaCy 置于正确状态。
语言注释
spaCy 提供多种语言注释,让您深入了解文本的语法结构。这包括词的类型,如词性,以及这些词是如何相互关联的。例如,如果您正在分析文本,名词是句子的主语还是宾语 - 或者“google”是用作动词还是指特定的网站或公司,都会产生巨大的差异。语境。
加载管道
$ python -m spacy download en_core_web_sm
>>> import spacy
>>> nlp = spacy.load("en_core_web_sm")下载并安装经过训练的管道后,您可以通过以下方式加载它spacy.load. 这将返回一个 Language对象,其中包含处理文本所需的所有组件和数据。我们通常称之为nlp。在文本字符串上调用nlp对象将返回处理后的Doc:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for token in doc:
print(token.text, token.pos_, token.dep_)即使 aDoc已被处理——例如,被分割成单个单词并被注释——它仍然包含原始文本的所有信息,如空白字符。您始终可以将标记的偏移量获取到原始字符串中,或者通过连接标记及其尾随空格来重建原始字符串。这样,在使用 spaCy 处理文本时,您将永远不会丢失任何信息。
代币化Tokenization代币化
在处理过程中,spaCy 首先对文本进行标记,即将文本分割成单词、标点符号等。这是通过应用特定于每种语言的规则来完成的。例如,句末的标点符号应该分开——而“UK”应该保持一个标记。每个Doc都由单独的令牌组成,我们可以迭代它们:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for token in doc:
print(token.text)| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| Apple | is | looking | at | buying | U.K. | startup | for | $ | 1 | billion |
首先,原始文本按空格字符分割,类似于 text.split(' '). 然后,分词器从左到右处理文本。在每个子字符串上,它执行两项检查:
-
子字符串是否与标记器异常规则匹配?例如,“don't”不包含空格,但应该分成两个标记,“do”和“n't”,而“UK”应该始终保留一个标记。
-
前缀、后缀或中缀可以拆分吗?例如逗号、句点、连字符或引号等标点符号。
如果匹配,则应用规则并且标记器继续其循环,从新拆分的子字符串开始。这样,spaCy 可以拆分复杂的嵌套标记,例如缩写和多个标点符号的组合。
- 标记器异常:在应用标点规则时将字符串拆分为多个标记或防止拆分标记的特殊情况规则。
- 前缀:开头的字符,例如
$,(,“,¿. - 后缀:结尾的字符,例如
km,),”,!. - 中缀:中间的字符,例如
-,--,/,….
虽然标点符号规则通常很笼统,但标记器异常在很大程度上取决于个别语言的具体情况。这就是为什么每种 可用语言都有自己的子类,例如 Englishor German,它们加载到硬编码数据和异常规则列表中。
词性标签和依赖关系 需求模型
标记化后,spaCy 可以解析和标记给定的Doc. 这就是经过训练的管道及其统计模型的用武之地,这使 spaCy 能够 预测哪个标签或标签最有可能适用于这种情况。一个经过训练的组件包括二进制数据,这些数据是通过向系统展示足够多的示例来生成的,以便系统做出泛化整个语言的预测——例如,英语中“the”后面的单词很可能是名词。
语言注释可用作 Token属性. 与许多 NLP 库一样,spaCy 将所有字符串编码为哈希值,以减少内存使用并提高效率。因此,要获得属性的可读字符串表示,我们需要在_其名称中添加下划线:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for token in doc:
print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)| TEXT | LEMMA | POS | TAG | DEP | SHAPE | ALPHA | STOP |
|---|---|---|---|---|---|---|---|
| Apple | apple | PROPN | NNP | nsubj | Xxxxx | True | False |
| is | be | AUX | VBZ | aux | xx | True | True |
| looking | look | VERB | VBG | ROOT | xxxx | True | False |
| at | at | ADP | IN | prep | xx | True | True |
| buying | buy | VERB | VBG | pcomp | xxxx | True | False |
| U.K. | u.k. | PROPN | NNP | compound | X.X. | False | False |
| startup | startup | NOUN | NN | dobj | xxxx | True | False |
| for | for | ADP | IN | prep | xxx | True | True |
| $ | $ | SYM | $ | quantmod | $ | False | False |
| 1 | 1 | NUM | CD | compound | d | False | False |
| billion | billion | NUM | CD | pobj | xxxx | True | False |
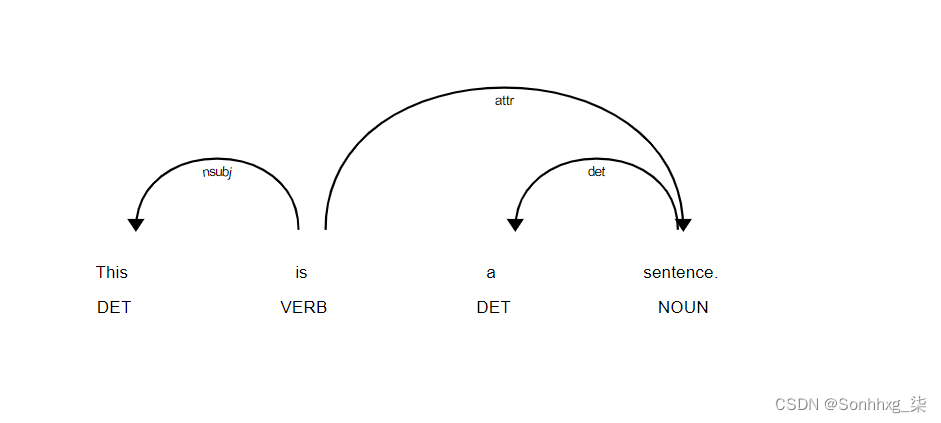
使用 spaCy 的内置displaCy 可视化器,我们的示例语句及其依赖项如下所示:
命名实体 需求模型
命名实体是分配了名称的“现实世界对象”——例如,人、国家、产品或书名。spaCy 可以通过向模型询问预测来识别文档中各种类型的命名实体。因为模型是统计的,并且很大程度上依赖于他们训练的例子,所以这并不总是完美的,以后可能需要一些调整,具体取决于您的用例。
命名实体可用作entsa 的属性Doc:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for ent in doc.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_)| TEXT | START | END | LABEL | DESCRIPTION |
|---|---|---|---|---|
| Apple | 0 | 5 | ORG | Companies, agencies, institutions. |
| U.K. | 27 | 31 | GPE | Geopolitical entity, i.e. countries, cities, states. |
| $1 billion | 44 | 54 | MONEY | Monetary values, including unit. |
使用 spaCy 的内置displaCy 可视化器,我们的例句及其命名实体如下所示: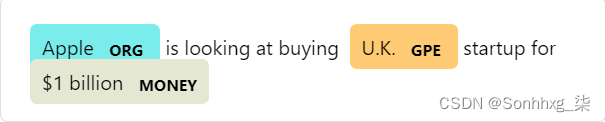
词向量和相似度 需求模型
相似性是通过比较词向量或“词嵌入”,一个词的多维意义表示来确定的。词向量可以使用类似 word2vec的算法生成,通常如下所示:
array([2.02280000e-01, -7.66180009e-02, 3.70319992e-01,
3.28450017e-02, -4.19569999e-01, 7.20689967e-02,
-3.74760002e-01, 5.74599989e-02, -1.24009997e-02,
5.29489994e-01, -5.23800015e-01, -1.97710007e-01,
-3.41470003e-01, 5.33169985e-01, -2.53309999e-02,
1.73800007e-01, 1.67720005e-01, 8.39839995e-01,
5.51070012e-02, 1.05470002e-01, 3.78719985e-01,
2.42750004e-01, 1.47449998e-02, 5.59509993e-01,
1.25210002e-01, -6.75960004e-01, 3.58420014e-01,
# ... and so on ...
3.66849989e-01, 2.52470002e-03, -6.40089989e-01,
-2.97650009e-01, 7.89430022e-01, 3.31680000e-01,
-1.19659996e+00, -4.71559986e-02, 5.31750023e-01], dtype=float32)重要的提示
为了使它们紧凑和快速,spaCy 的小型管道包(所有以 结尾的包sm)不附带词向量,并且只包含上下文敏感的张量。这意味着您仍然可以使用这些similarity() 方法来比较文档、跨度和标记——但结果不会那么好,并且单个标记不会分配任何向量。所以为了使用 真实的词向量,你需要下载一个更大的管道包:
- python -m spacy download en_core_web_sm
+ python -m spacy download en_core_web_lg带有内置词向量的管道包使它们可以作为Token.vector属性。 Doc.vector和Span.vector将默认为其标记向量的平均值。您还可以检查一个标记是否分配了一个向量,并获得 L2 范数,该范数可用于对向量进行归一化。
import spacy
nlp = spacy.load("en_core_web_md")
tokens = nlp("dog cat banana afskfsd")
for token in tokens:
print(token.text, token.has_vector, token.vector_norm, token.is_oov)“狗”、“猫”和“香蕉”这些词在英语中都很常见,所以它们是管道词汇的一部分,并带有一个向量。另一方面,“afskfsd”这个词不太常见,也没有词汇表——所以它的向量表示由 300 个维度组成0,这意味着它实际上不存在。如果您的应用程序将受益于具有更多向量的大型词汇表,则应考虑使用较大的管道包之一或加载完整的向量包,例如, en_core_web_lg,其中包括685k 个唯一向量。
spaCy 能够比较两个对象,并预测它们的相似程度。预测相似性对于构建推荐系统或标记重复项很有用。例如,您可以建议与他们当前正在查看的内容相似的用户内容,或者如果支持票与已经存在的票非常相似,则将其标记为重复。
每个Doc,Span,Token和 Lexeme附带一个.similarity 方法,可让您将其与另一个对象进行比较,并确定相似度。当然相似性总是主观的——两个词、跨度或文档是否相似实际上取决于你如何看待它。spaCy 的相似性实现通常假设一个非常通用的相似性定义。
import spacy
nlp = spacy.load("en_core_web_md") # make sure to use larger package!
doc1 = nlp("I like salty fries and hamburgers.")
doc2 = nlp("Fast food tastes very good.")
# Similarity of two documents
print(doc1, "<->", doc2, doc1.similarity(doc2))
# Similarity of tokens and spans
french_fries = doc1[2:4]
burgers = doc1[5]
print(french_fries, "<->", burgers, french_fries.similarity(burgers))从相似性结果中可以期待什么
计算相似度分数在许多情况下可能会有所帮助,但保持对它可以提供的信息的现实期望也很重要。单词可以通过多种方式相互关联,因此单个“相似性”分数将始终是不同信号的混合,并且在不同数据上训练的向量可能会产生非常不同的结果,这可能对您的目的没有用处。以下是一些需要牢记的重要注意事项:
- 相似性没有客观的定义。“我喜欢汉堡”和“我喜欢意大利面”是否相似取决于您的应用程序。两者都谈论食物偏好,这使得它们非常相似 - 但如果你正在分析食物的提及,这些句子是非常不同的,因为它们谈论的食物非常不同。
- 的相似性Doc和Spanobjects 默认为标记向量的平均值。这意味着“快餐”的向量是“快餐”和“食物”向量的平均值,它不一定代表“快餐”这个短语。
- 向量平均是指多个token的向量对单词的顺序不敏感。两个用不同措词表达相同含义的文档将返回比两个恰好包含相同单词但表达不同含义的文档更低的相似度分数。
管道
当您调用nlp文本时,spaCy 首先标记文本以生成Doc 对象。然后Doc在几个不同的步骤中处理 - 这也称为处理管道。训练过的流水线使用的 流水线通常包括标注器、词形还原器、解析器和实体识别器。每个管道组件返回处理Doc后的 ,然后将其传递给下一个组件。

| NAME | COMPONENT | CREATES | DESCRIPTION |
|---|---|---|---|
| tokenizer | Tokenizer | Doc | Segment text into tokens. |
| PROCESSING PIPELINE | |||
| tagger | Tagger | Token.tag | Assign part-of-speech tags. |
| parser | DependencyParser | Token.head, Token.dep, Doc.sents, Doc.noun_chunks | Assign dependency labels. |
| ner | EntityRecognizer | Doc.ents, Token.ent_iob, Token.ent_type | Detect and label named entities. |
| lemmatizer | Lemmatizer | Token.lemma | Assign base forms. |
| textcat | TextCategorizer | Doc.cats | Assign document labels. |
| custom | custom components | Doc._.xxx, Token._.xxx, Span._.xxx | Assign custom attributes, methods or properties. |
处理管道的能力始终取决于组件、它们的模型以及它们的训练方式。例如,用于命名实体识别的管道需要包含经过训练的命名实体识别器组件,该组件具有统计模型和权重,使其能够预测实体标签。这就是每个管道在config中指定其组件及其设置的原因:
[nlp]
pipeline = ["tok2vec", "tagger", "parser", "ner"]管道组件的顺序是否重要?
标记器或解析器等统计组件通常是独立的,彼此之间不共享任何数据。例如,命名实体识别器不使用标记器和解析器设置的任何特征,等等。这意味着您可以交换它们,或从管道中删除单个组件而不影响其他组件。然而,组件可能共享一个“token-to-vector”组件,例如Tok2Vec或者Transformer. 您可以在嵌入层的文档中阅读更多相关信息 。
自定义组件也可能依赖于其他组件设置的注释。例如,自定义词形还原器可能需要分配词性标记,因此只有在标记器之后添加它才会起作用。解析器将尊重预定义的句子边界,因此如果管道中的前一个组件设置它们,它的依赖预测可能会不同。同样,如果您添加 EntityRuler在统计实体识别器之前或之后:如果在之前添加,实体识别器在进行预测时会考虑现有实体。这 EntityLinker,它将命名实体解析为知识库 ID,应该在前面有一个管道组件,该组件可以识别实体,例如EntityRecognizer.
为什么分词器特别?
标记器是一个“特殊”组件,不是常规管道的一部分。它也没有出现在nlp.pipe_names. 原因是实际上只能有一个分词器,而所有其他管道组件接受 aDoc 并返回它,分词器接受一串文本并将其转换为 Doc. 不过,您仍然可以自定义标记器。是可写的,因此您可以从头开始nlp.tokenizer创建自己的 类,甚至可以将其替换为 完全自定义的函数。Tokenizer
建筑学
spaCy 中的核心数据结构是Language类Vocab和Doc目的。该类Language用于处理文本并将其转换为Doc对象。它通常存储为一个名为nlp. 该Doc对象拥有标记序列及其所有注释。通过将字符串、词向量和词汇属性集中在 中Vocab,我们避免了存储这些数据的多个副本。这可以节省内存,并确保有单一的事实来源。
文本注释也被设计成允许单一的事实来源:Doc 对象拥有数据,并且Span和Token是 指向它的观点。该Doc对象由 Tokenizer,然后由管道的组件就地修改。Language对象协调这些组件。它获取原始文本并通过管道发送,返回一个带注释的文档。它还协调训练和序列化。
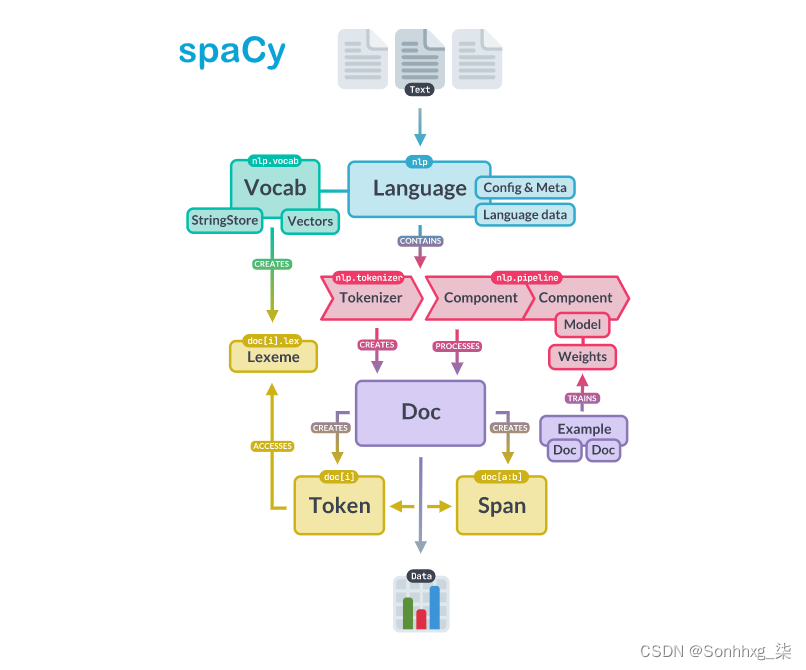
容器对象
| 姓名 | 描述 |
|---|---|
| Doc | 用于访问语言注释的容器。 |
| DocBin | Doc用于高效二进制序列化的对象集合。也用于训练数据。 |
| Example | 训练注释的集合,包含两个Doc对象:参考数据和预测。 |
| Language | 将文本转换为Doc对象的处理类。不同的语言实现了它们自己的子类。该变量通常称为nlp。 |
| Lexeme | 词汇表中的一个条目。它是一种没有上下文的单词类型,而不是单词标记。因此它没有词性标签、依赖解析等。 |
| Span | 对象的切片Doc。 |
| SpanGroup | 属于 的跨度的命名集合Doc。 |
| Token | 一个单独的标记——即一个单词、标点符号、空格等。 |
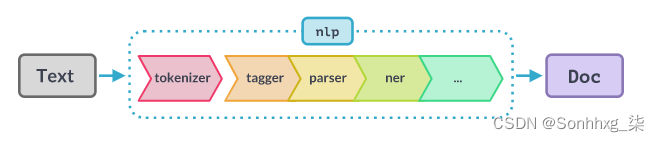
处理管道
处理管道由一个或多个按顺序调用的管道组件组成。Doc标记器在组件之前运行。可以使用添加管道组件Language.add_pipe. 它们可以包含统计模型和经过训练的权重,或者仅对Doc. spaCy 为不同的语言处理任务提供了一系列内置组件,还允许添加 自定义组件。
| 姓名 | 描述 |
|---|---|
| AttributeRuler | 使用匹配器规则设置令牌属性。 |
| DependencyParser | 预测句法依赖。 |
| EditTreeLemmatizer | 预测单词的基本形式。 |
| EntityLinker | 将命名实体与知识库中的节点消除歧义。 |
| EntityRecognizer | 预测命名实体,例如人或产品。 |
| EntityRuler | 将实体范围添加到Doc使用基于令牌的规则或完全匹配的短语中。 |
| Lemmatizer | 使用规则和查找来确定单词的基本形式。 |
| Morphologizer | 预测形态特征和粗粒度词性标签。 |
| SentenceRecognizer | 预测句子边界。 |
| Sentencizer | 实现不需要依赖解析的基于规则的句子边界检测。 |
| Tagger | 预测词性标签。 |
| TextCategorizer | 预测整个文档的类别或标签。 |
| Tok2Vec | 应用“token-to-vector”模型并设置其输出。 |
| Tokenizer | 分割原始文本并Doc从单词中创建对象。 |
| TrainablePipe | 所有可训练管道组件都继承自的类。 |
| Transformer | 使用变压器模型并设置其输出。 |
| 其他功能 | 自动将某些内容应用于Doc,例如合并令牌范围。 |
火柴
匹配器帮助您查找和提取信息Doc基于描述您正在寻找的序列的匹配模式的对象。匹配器对 a 进行操作,Doc并允许您访问context中匹配的标记。
| 姓名 | 描述 |
|---|---|
| DependencyMatcher | 使用Semgrex 运算符基于依赖树匹配标记序列。 |
| Matcher | 基于模式规则匹配标记序列,类似于正则表达式。 |
| PhraseMatcher | 基于短语匹配标记序列。 |
其他类
| 姓名 | 描述 |
|---|---|
| Corpus | 用于管理训练和评估数据的注释语料库的类。 |
| KnowledgeBase | 用于实体链接的知识库的实体和别名的存储。 |
| Lookups | 方便访问大型查找表和字典的容器。 |
| MorphAnalysis | 形态学分析。 |
| Morphology | 存储形态分析并将它们映射到哈希值和从哈希值映射。 |
| Scorer | 计算评估分数。 |
| StringStore | 将字符串映射到哈希值和从哈希值映射。 |
| Vectors | 以字符串为键的矢量数据的容器类。 |
| Vocab | 存储字符串并允许您访问的共享词汇表Lexeme对象。 |
词汇、哈希和词位
只要有可能,spaCy 就会尝试将数据存储在一个词汇表中,即 Vocab,将由多个文档共享。为了节省内存,spaCy 还将所有字符串编码为哈希值——例如,“coffee”具有哈希值3197928453018144401。像“ORG”这样的实体标签和像“VERB”这样的词性标签也被编码。在内部,spaCy 只在哈希值中“说话”。
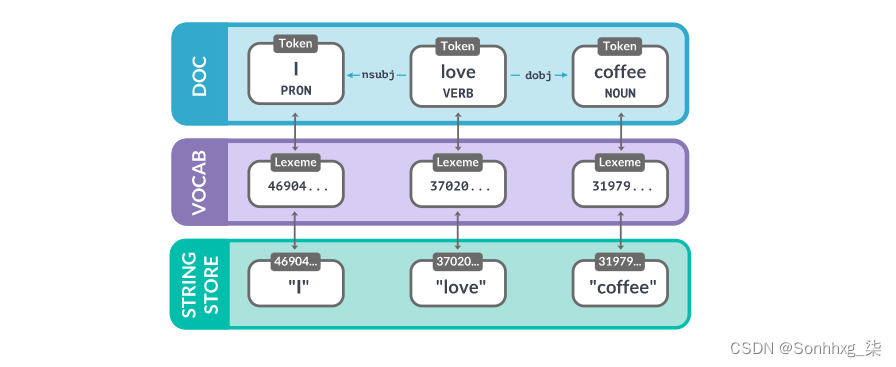
- Token :上下文中的单词、标点符号等,包括其属性、标签和依赖关系。
- Lexeme:没有上下文的“单词类型”。包括单词形状和标志,例如,如果它是小写字母、数字或标点符号。
- Doc:上下文中已处理的令牌容器。
- 词汇:词汇的集合。
- StringStore:将哈希值映射到字符串的字典,例如
3197928453018144401→ “coffee”。
如果您在各种不同的上下文中处理大量包含单词“coffee”的文档,那么每次存储确切的字符串“coffee”会占用太多空间。因此,spaCy 对字符串进行哈希处理并将其存储在 StringStore. 您可以将StringStore视为一个 双向工作的查找表——您可以查找一个字符串以获取其哈希值,或查找一个哈希值以获取其字符串:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("I love coffee")
print(doc.vocab.strings["coffee"]) # 3197928453018144401
print(doc.vocab.strings[3197928453018144401]) # 'coffee'现在所有字符串都已编码,词汇表中的条目不需要包含单词 text本身。StringStore相反,他们可以通过它的哈希值来查找它 。词汇表中的每个条目,也称为 Lexeme, 包含一个单词的上下文无关信息。例如,无论“love”在某些上下文中用作动词还是名词,它的拼写以及是否由字母字符组成都不会改变。它的哈希值也将始终相同。
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("I love coffee")
for word in doc:
lexeme = doc.vocab[word.text]
print(lexeme.text, lexeme.orth, lexeme.shape_, lexeme.prefix_, lexeme.suffix_,
lexeme.is_alpha, lexeme.is_digit, lexeme.is_title, lexeme.lang_)- Text:词位的原始文本。
- Orth:词位的哈希值。
- 形状:词位的抽象词形状。
- Prefix:默认情况下,单词字符串的第一个字母。
- 后缀:默认情况下,单词字符串的最后三个字母。
- 是 alpha:词位是否由字母字符组成?
- 是数字:词位是否由数字组成?
| TEXT | ORTH | SHAPE | PREFIX | SUFFIX | IS_ALPHA | IS_DIGIT |
|---|---|---|---|---|---|---|
| I | 4690420944186131903 | X | I | I | True | False |
| love | 3702023516439754181 | xxxx | l | ove | True | False |
| coffee | 3197928453018144401 | xxxx | c | fee | True | False |
单词到哈希的映射不依赖于任何状态。为了确保每个值都是唯一的,spaCy 使用 散列函数根据单词 string计算散列。这也意味着“咖啡”的哈希值将始终相同,无论您使用哪个管道或如何配置 spaCy。
但是,哈希值无法反转,也无法解析 3197928453018144401回“咖啡”。spaCy 所能做的就是在词汇表中查找。这就是为什么您总是需要确保您创建的所有对象都可以访问相同的词汇表。如果他们不这样做,spaCy 可能无法找到它需要的字符串。
import spacy
from spacy.tokens import Doc
from spacy.vocab import Vocab
nlp = spacy.load("en_core_web_sm")
doc = nlp("I love coffee") # Original Doc
print(doc.vocab.strings["coffee"]) # 3197928453018144401
print(doc.vocab.strings[3197928453018144401]) # 'coffee' 👍
empty_doc = Doc(Vocab()) # New Doc with empty Vocab
# empty_doc.vocab.strings[3197928453018144401] will raise an error :(
empty_doc.vocab.strings.add("coffee") # Add "coffee" and generate hash
print(empty_doc.vocab.strings[3197928453018144401]) # 'coffee' 👍
new_doc = Doc(doc.vocab) # Create new doc with first doc's vocab
print(new_doc.vocab.strings[3197928453018144401]) # 'coffee' 👍如果词汇表不包含 for 的字符串3197928453018144401,则 spaCy 将引发错误。您可以手动重新添加“咖啡”,但这仅在您确实知道文档包含该单词时才有效。为防止出现此问题,spaCy 还会Vocab在您保存Doc或nlp对象时导出。这将为您提供对象及其编码注释,以及解码它的“密钥”。
序列化
如果您一直在修改管道、词汇、向量和实体,或者对组件模型进行了更新,您最终会希望保存您的进度——例如,您的nlp对象中的所有内容。这意味着您必须将其内容和结构转换为可以保存的格式,例如文件或字节字符串。这个过程称为序列化。spaCy 带有内置的序列化方法并支持 Pickle 协议。
所有容器类,即Language (nlp), Doc,Vocab和StringStore 有以下方法可用:
| METHOD | RETURNS | EXAMPLE |
|---|---|---|
to_bytes | bytes | data = nlp.to_bytes() |
from_bytes | object | nlp.from_bytes(data) |
to_disk | - | nlp.to_disk("/path") |
from_disk | object | nlp.from_disk("/path") |
📖保存和加载
要了解有关如何保存和加载您自己的管道的更多信息,请参阅保存和加载的使用指南。
训练
spaCy 的标注器、解析器、文本分类器和许多其他组件由统计模型提供支持。这些组件做出的每个“决定”——例如,分配哪个词性标签,或者一个词是否是一个命名实体——都是 基于模型当前权重值的预测。权重值是根据模型在训练期间看到的示例估计的。要训练模型,您首先需要训练数据——文本示例,以及您希望模型预测的标签。这可以是词性标签、命名实体或任何其他信息。
训练是一个迭代过程,其中将模型的预测与参考注释进行比较,以估计损失的梯度。然后使用损失的梯度通过反向传播计算权重的梯度。梯度指示应如何更改权重值,以便模型的预测随着时间的推移变得更类似于参考标签。

- 训练数据:示例及其注释。
- 文本:模型应为其预测标签的输入文本。
- 标签:模型应该预测的标签。
- 梯度:数值变化的方向和速率。最小化权重梯度应该会导致预测更接近训练数据上的参考标签。
在训练模型时,我们不仅希望它记住我们的示例——我们希望它提出一个可以在未见数据中泛化的理论。毕竟,我们不只是希望模型知道这里的“亚马逊”这个实例是一家公司——我们希望它知道“亚马逊”在这样的上下文中很可能是一家公司。这就是为什么训练数据应该始终代表我们要处理的数据。一个在 Wikipedia 上训练的模型,其中第一人称的句子极为罕见,很可能在 Twitter 上表现不佳。同样,在浪漫小说上训练的模型可能在法律文本上表现不佳。
这也意味着,为了了解模型的执行情况,以及它是否在学习正确的东西,您不仅需要训练数据,还需要评估数据。如果你只用训练过的数据来测试模型,你将不知道它的泛化能力有多好。如果你想从头开始训练一个模型,你通常需要至少几百个例子来训练和评估。
训练配置和生命周期
训练配置文件包括用于训练管道的所有设置和超参数。无需在命令行上提供大量参数,您只需将config.cfg文件传递给spacy train. 这也使得在您选择的框架中编写的自定义模型和架构的集成变得容易。管道在训练和运行时config.cfg都被认为是“单一事实来源” 。
📖训练配置系统
有关 spaCy配置系统以及如何使用它来自定义管道组件、组件模型、训练设置和超参数的更多详细信息,请参阅训练配置使用指南。
可训练组件
斯帕西的Pipe类可帮助您实现自己的可训练组件,这些组件具有自己的模型实例,对Doc 对象进行预测并且可以使用更新spacy train. 这使您可以将完全自定义的机器学习组件插入到可以通过单个训练配置进行配置的管道中。
[components.my_component]
factory = "my_component"
[components.my_component.model]
@architectures = "my_model.v1"
width = 128
📖自定义可训练组件
要了解有关如何实现您自己的模型架构并使用它们为自定义可训练组件提供动力的更多信息,请参阅可训练组件 API和实现可训练组件的层和架构的使用指南 。
语言数据
每种语言都是不同的——通常充满了例外和特殊情况,尤其是在最常见的单词中。其中一些例外是跨语言共享的,而另一些则是完全特定的——通常非常具体,需要硬编码。这 lang模块包含所有特定于语言的数据,以简单的 Python 文件组织。这使得数据易于更新和扩展。
目录根目录中的共享语言数据包括可以跨语言通用的规则——例如,基本标点符号、表情符号、表情符号和单字母缩写的规则。子模块中的单个语言数据包含仅与特定语言相关的规则。它还负责将所有组件放在一起并创建 Language子类——例如,English或German。这些值在Language.Defaults.
from spacy.lang.en import English
from spacy.lang.de import German
nlp_en = English() # Includes English data
nlp_de = German() # Includes German data| 姓名 | 描述 |
|---|---|
| 停用词 stop_words.py | 一种语言中最常用的词列表,这些词通常有助于过滤掉,例如“and”或“I”。匹配的令牌将返回True.is_stop |
| 分词器异常 tokenizer_exceptions.py | 标记器的特殊情况规则,例如“can't”之类的缩写和带有标点符号的缩写,例如“UK”。 |
| 标点规则 punctuation.py | 用于拆分标记的正则表达式,例如标点符号或表情符号等特殊字符。包括前缀、后缀和中缀的规则。 |
| 字符类 char_classes.py | 要在正则表达式中使用的字符类,例如拉丁字符、引号、连字符或图标。 |
| 词法属性 lex_attrs.py | 用于在标记上设置词汇属性的自定义函数,例如like_num,其中包括特定于语言的单词,如“十”或“一百”。 |
| 语法迭代器 syntax_iterators.py | Doc根据语法计算对象视图的函数。目前,仅用于名词 chunks。 |
| 词形还原器 lemmatizer.py spacy-lookups-data | 自定义 lemmatizer 实现和 lemmatization 表。 |















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









