








🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
一次你有一个漂亮的模型,可以做出惊人的预测,你会用它做什么?好吧,你需要把它投入生产!这可能就像在一批数据上运行模型一样简单,并且可能编写一个每晚运行该模型的脚本。但是,它通常涉及更多。您的基础架构的各个部分可能需要在实时数据上使用此模型,在这种情况下,您可能希望将模型包装在 Web 服务中:这样,您的基础架构的任何部分都可以使用简单的 REST API 随时查询您的模型(或其他协议),正如我们在第 2 章中讨论的那样. 但随着时间的推移,您需要定期根据新数据重新训练模型并将更新版本推送到生产环境。您必须处理模型版本控制,从一个模型优雅地过渡到下一个模型,在出现问题时可能回滚到以前的模型,也许并行运行多个不同的模型来执行A/B 实验。1如果您的产品成功,您的服务可能会开始获得每秒有大量查询(QPS),它必须向上扩展以支持负载。正如我们将在本章中看到的那样,扩展您的服务的一个很好的解决方案是使用 TF Serving,无论是在您自己的硬件基础设施上还是通过诸如 Google Cloud AI Platform 之类的云服务。它将负责高效地为您的模型提供服务、处理优雅的模型转换等等。如果您使用云平台,您还将获得许多额外的功能,例如强大的监控工具。
此外,如果您有大量训练数据和计算密集型模型,那么训练时间可能会非常长。如果您的产品需要快速适应变化,那么长时间的训练可能会大有裨益(例如,考虑一个宣传上周新闻的新闻推荐系统)。也许更重要的是,长时间的培训会阻止你尝试新的想法。在机器学习中(就像在许多其他领域一样),很难提前知道哪些想法会奏效,所以你应该尽可能多地尝试,尽可能快。加速训练的一种方法是使用硬件加速器,例如 GPU 或 TPU。为了更快,您可以在多台机器上训练模型,每台机器都配备多个硬件加速器。TensorFlow 的简单正如我们将看到的,强大的分发策略 API 使这很容易。
在本章中,我们将了解如何部署模型,首先部署到 TF Serving,然后部署到 Google Cloud AI Platform。我们还将快速了解如何将模型部署到移动应用程序、嵌入式设备和 Web 应用程序。最后,我们将讨论如何使用 GPU 加速计算,以及如何使用 Distribution Strategies API 在多个设备和服务器上训练模型。有很多话题要讨论,所以让我们开始吧!
服务于 TensorFlow 模型
一次你已经训练了一个 TensorFlow 模型,你可以轻松地在任何 Python 代码中使用它:如果它是一个 tf.keras 模型,只需调用它的predict()方法!但是随着您的基础设施的增长,最好将您的模型包装在一个小型服务中,该服务的唯一作用是进行预测并让基础设施的其余部分查询它(例如,通过 REST 或 gRPC API)。2这将您的模型与基础架构的其余部分解耦,从而可以轻松切换模型版本或根据需要扩展服务(独立于基础架构的其余部分),执行 A/B 实验,并确保您的所有软件组件都依赖在相同的模型版本上。它还简化了测试和开发等等。您可以使用任何您想要的技术(例如,使用 Flask 库)创建自己的微服务,但是当您只能使用 TF Serving 时,为什么还要重新发明轮子呢?
使用 TensorFlow 服务
TF Serving 是一个非常高效、经过实战考验的模型服务器,它是用 C++ 编写的。它可以承受高负载,为模型的多个版本提供服务,并监视模型存储库以自动部署最新版本等等(见图 19-1)。

图 19-1。TF Serving 可以服务多个模型并自动部署每个模型的最新版本
因此,假设您已经使用 tf.keras 训练了一个 MNIST 模型,并且您希望将其部署到 TF Serving。您要做的第一件事是导出此模型到 TensorFlow 的SavedModel 格式。
导出 SavedModel
TensorFlow 提供了一个简单的tf.saved_model.save()函数来将模型导出为 SavedModel 格式。您需要做的就是给它模型,指定其名称和版本号,该函数将保存模型的计算图及其权重:
model = keras.models.Sequential([...])
model.compile([...])
history = model.fit([...])
model_version = "0001"
model_name = "my_mnist_model"
model_path = os.path.join(model_name, model_version)
tf.saved_model.save(model, model_path)或者,您可以只使用模型的save()方法 ( model.save(model_path)):只要文件的扩展名不是.h5,模型将使用 SavedModel 格式而不是 HDF5 格式保存。
在您导出的最终模型中包含所有预处理层通常是一个好主意,这样一旦部署到生产环境中,它就可以以其自然形式摄取数据。这避免了必须在使用模型的应用程序中单独处理预处理。将模型中的预处理步骤捆绑在一起还可以更轻松地稍后更新它们,并限制模型与其所需的预处理步骤之间不匹配的风险。
警告
由于 SavedModel 保存计算图,因此它只能与完全基于 TensorFlow 操作的模型一起使用,不包括
tf.py_function()操作(包装任意 Python 代码)。它还排除了动态 tf.keras 模型(参见附录 G),因为这些模型无法转换为计算图。需要使用其他工具(例如,Flask)来提供动态模型。
SavedModel 代表模型的一个版本。它存储为一个目录,其中包含一个saved_model.pb文件,该文件定义了计算图(表示为序列化协议缓冲区),以及一个包含变量值的变量子目录。对于包含大量权重的模型,这些变量值可能会被拆分到多个文件中。SavedModel 还包括一个assets子目录,其中可能包含其他数据,例如词汇文件、类名或此模型的一些示例实例。目录结构如下(在本例中,我们不使用资产):
my_mnist_model
└── 0001
├── assets
├── saved_model.pb
└── variables
├── variables.data-00000-of-00001
└── variables.index
如您所料,您可以使用该tf.saved_model.load()函数加载 SavedModel。但是,返回的对象不是 Keras 模型:它表示 SavedModel,包括其计算图和变量值。您可以像函数一样使用它,它会进行预测(确保将输入作为适当类型的张量传递):
saved_model = tf.saved_model.load(model_path)
y_pred = saved_model(tf.constant(X_new, dtype=tf.float32))或者,您可以使用以下函数将此 SavedModel 直接加载到 Keras 模型keras.models.load_model():
model = keras.models.load_model(model_path)
y_pred = model.predict(tf.constant(X_new, dtype=tf.float32))TensorFlow 还附带了一个小型saved_model_cli命令行工具来检查 SavedModels:
$ export ML_PATH="$HOME/ml" # point to this project, wherever it is $ cd $ML_PATH$ saved_model_cli show --dir my_mnist_model/0001 --allMetaGraphDef with tag-set: 'serve' contains the following SignatureDefs: signature_def['__saved_model_init_op']: [...] signature_def['serving_default']: The given SavedModel SignatureDef contains the following input(s): inputs['flatten_input'] tensor_info: dtype: DT_FLOAT shape: (-1, 28, 28) name: serving_default_flatten_input:0 The given SavedModel SignatureDef contains the following output(s): outputs['dense_1'] tensor_info: dtype: DT_FLOAT shape: (-1, 10) name: StatefulPartitionedCall:0 Method name is: tensorflow/serving/predict 一个SavedModel包含一个或多个元图。元图是一个计算图加上一些函数签名定义(包括它们的输入和输出名称、类型和形状)。每个元图由一组标签标识。例如,您可能希望拥有一个包含完整计算图的元图,包括训练操作("train"例如,这个可能被标记为操作(这个元图可能被标记"serve", "gpu")。但是,当您将 tf.keras 模型传递给tf.saved_model.save()函数时,默认情况下,该函数会保存一个更简单的 SavedModel:它保存一个已标记的元图"serve",其中包含两个签名定义,一个初始化函数(称为__saved_model_init_op,您无需担心)和一个默认服务函数(称为serving_default)。保存一个 tf.keras 模型时,默认服务函数对应模型的call()函数,这当然是做预测的。
该saved_model_cli工具还可用于进行预测(用于测试,而不是真正用于生产)。假设您有一个 NumPy 数组 ( X_new),其中包含您要对其进行预测的三幅手写数字图像。您首先需要将它们导出为 NumPy 的npy格式:
np.save("my_mnist_tests.npy",X_new)接下来,使用如下saved_model_cli命令:
$ saved_model_cli run --dir my_mnist_model/0001 --tag_set serve \ --signature_def serving_default\ --inputs flatten_input=my_mnist_tests.npy[...] Result for output key dense_1: [[1.1739199e-04 1.1239604e-07 6.0210604e-04 [...] 3.9471846e-04] [1.2294615e-03 2.9207937e-05 9.8599273e-01 [...] 1.1113169e-07] [6.4066830e-05 9.6359509e-01 9.0598064e-03 [...] 4.2495009e-04]] 该工具的输出包含 3 个实例中每个实例的 10 个类别概率。伟大的!现在您有了一个可以工作的 SavedModel,下一步是安装 TF Serving。
安装 TensorFlow 服务
安装 TF Serving 的方法有很多:使用 Docker 镜像,3使用系统的包管理器,从源代码安装等等。让我们使用 TensorFlow 团队强烈推荐的 Docker 选项,因为它安装简单,不会弄乱您的系统,并且提供高性能。您首先需要安装Docker。然后下载官方的 TF Serving Docker 镜像:
$ docker pull tensorflow/serving现在你可以创建一个 Docker 容器来运行这个镜像:
$ docker run -it --rm -p 8500:8500 -p 8501:8501 \ -v "$ML_PATH/my_mnist_model:/models/my_mnist_model" \ -e MODEL_NAME=my_mnist_model \ tensorflow/serving[...] 2019-06-01 [...] loaded servable version {name: my_mnist_model version: 1} 2019-06-01 [...] Running gRPC ModelServer at 0.0.0.0:8500 ... 2019-06-01 [...] Exporting HTTP/REST API at:localhost:8501 ... [evhttp_server.cc : 237] RAW: Entering the event loop ... 而已!TF 服务正在运行。它加载了我们的 MNIST 模型(版本 1),并通过 gRPC(在端口 8500 上)和 REST(在端口 8501 上)为其提供服务。以下是所有命令行选项的含义:
-it
使容器具有交互性(因此您可以按 Ctrl-C 停止它)并显示服务器的输出。
--rm
当你停止容器时删除它(不需要用中断的容器弄乱你的机器)。但是,它不会删除图像。
-p 8500:8500
使 Docker 引擎将主机的 TCP 端口 8500 转发到容器的 TCP 端口 8500。默认情况下,TF Serving 使用此端口来服务 gRPC API。
-p 8501:8501
将主机的 TCP 端口 8501 转发到容器的 TCP 端口 8501。默认情况下,TF Serving 使用此端口来服务 REST API。
-v "$ML_PATH/my_mnist_model:/models/my_mnist_model"
使主机的$ML_PATH/my_mnist_model目录在路径/models/mnist_model对容器可用。在 Windows 上,您可能需要在主机路径中替换/为\(但不是在容器路径中)。
-e MODEL_NAME=my_mnist_model
设置容器的MODEL_NAME环境变量,以便 TF Serving 知道要服务的模型。默认情况下,它将在/models目录中查找模型,并自动提供找到的最新版本。
tensorflow/serving
这是要运行的映像的名称。
现在让我们回到 Python 并查询这个服务器,首先使用 REST API,然后使用 gRPC API。
通过 REST API 查询 TF Serving
让我们从创建查询开始。它必须包含您要调用的函数签名的名称,当然还有输入数据:
import json
input_data_json = json.dumps({
"signature_name": "serving_default",
"instances": X_new.tolist(),
})请注意,JSON 格式 100% 基于文本,因此X_new必须将 NumPy 数组转换为 Python 列表,然后格式化为 JSON:
>>> input_data_json'{"signature_name": "serving_default", "instances": [[[0.0, 0.0, 0.0, [...]0.3294117647058824, 0.725490196078431, [...very long], 0.0, 0.0, 0.0, 0.0]]]}'现在让我们通过发送 HTTP POST 请求将输入数据发送到 TF Serving。这可以使用requests库轻松完成(它不是 Python 标准库的一部分,因此您需要先安装它,例如使用 pip):
import requests
SERVER_URL = 'http://localhost:8501/v1/models/my_mnist_model:predict'
response = requests.post(SERVER_URL, data=input_data_json)
response.raise_for_status() # raise an exception in case of error
response = response.json()响应是包含单个"predictions"键的字典。对应的值是预测列表。这个列表是一个 Python 列表,所以让我们将它转换为 NumPy 数组,并将它包含的浮点数四舍五入到小数点后第二位:
>>> y_proba = np.array(response["predictions"])
>>> y_proba.round(2)
array([[0. , 0. , 0. , 0. , 0. , 0. , 0. , 1. , 0. , 0. ],
[0. , 0. , 0.99, 0.01, 0. , 0. , 0. , 0. , 0. , 0. ],
[0. , 0.96, 0.01, 0. , 0. , 0. , 0. , 0.01, 0.01, 0. ]])万岁,我们有预测!该模型对第一个图像是 7 的置信度接近 100%,对第二个图像是 2 的置信度为 99%,对第三个图像的置信度为 1 的置信度为 96%。
REST API 很好很简单,在输入和输出数据不太大的情况下效果很好。此外,几乎任何客户端应用程序都可以在没有额外依赖项的情况下进行 REST 查询,而其他协议并不总是那么容易获得。但是,它基于 JSON,它是基于文本的并且相当冗长。例如,我们必须将 NumPy 数组转换为 Python 列表,并且每个浮点数最终都表示为一个字符串。这是非常低效的,无论是在序列化/反序列化时间(将所有浮点数转换为字符串并返回)和有效负载大小方面:许多浮点数最终使用超过 15 个字符表示,转换为 32 位超过 120 位-位浮动!在传输大型 NumPy 数组时,这将导致高延迟和带宽使用。4所以让我们改用 gRPC。
小费
当传输大量数据时,最好使用 gRPC API(如果客户端支持),因为它基于紧凑的二进制格式和高效的通信协议(基于 HTTP/2 框架)。
通过 gRPC API 查询 TF Serving
gRPC API 需要一个序列化的PredictRequest协议缓冲区作为输入,它输出一个序列化的PredictResponse协议缓冲区。这些 protobuf 是tensorflow-serving-api库的一部分,您必须安装(例如,使用 pip)。首先,让我们创建请求:
rom tensorflow_serving.apis.predict_pb2 import PredictRequest
request = PredictRequest()
request.model_spec.name = model_name
request.model_spec.signature_name = "serving_default"
input_name = model.input_names[0]
request.inputs[input_name].CopyFrom(tf.make_tensor_proto(X_new))这段代码创建了一个PredictRequest协议缓冲区并填写了必填字段,包括模型名称(之前定义的)、我们要调用的函数的签名名称,最后是输入数据,以Tensor协议缓冲区的形式。该tf.make_tensor_proto()函数根据给定的张量或 NumPy 数组创建一个Tensor协议缓冲区,在本例中为X_new.
接下来,我们将向服务器发送请求并获得其响应(为此,您需要grpcio库,您可以使用 pip 安装它):
import grpc
from tensorflow_serving.apis import prediction_service_pb2_grpc
channel = grpc.insecure_channel('localhost:8500')
predict_service = prediction_service_pb2_grpc.PredictionServiceStub(channel)
response = predict_service.Predict(request, timeout=10.0)代码非常简单:在导入之后,我们在 TCP 端口 8500 上创建一个到localhost的 gRPC 通信通道,然后我们在这个通道上创建一个 gRPC 服务并使用它来发送请求,超时时间为 10 秒(不是调用是同步的:它将阻塞直到收到响应或超时期限到期)。在此示例中,通道是不安全的(无加密、无身份验证),但 gRPC 和 TensorFlow Serving 也支持基于 SSL/TLS 的安全通道。
接下来,让我们将PredictResponse协议缓冲区转换为张量:
output_name = model.output_names[0]
outputs_proto = response.outputs[output_name]
y_proba = tf.make_ndarray(outputs_proto)如果您运行此代码并打印y_proba.numpy().round(2),您将获得与之前完全相同的估计类别概率。仅此而已:只需几行代码,您现在就可以使用 REST 或 gRPC 远程访问您的 TensorFlow 模型。
部署新模型版本
现在让我们创建一个新的模型版本并将 SavedModel 导出到my_mnist_model/0002目录,就像之前一样:
model = keras.models.Sequential([...])
model.compile([...])
history = model.fit([...])
model_version = "0002"
model_name = "my_mnist_model"
model_path = os.path.join(model_name, model_version)
tf.saved_model.save(model, model_path)TensorFlow Serving 会定期检查新模型版本(延迟是可配置的)。如果找到,它将自动优雅地处理转换:默认情况下,它将使用以前的模型版本回答待处理的请求(如果有),同时使用新版本处理新请求。5一旦每个待处理的请求得到答复,之前的模型版本就会被卸载。您可以在 TensorFlow Serving 日志中看到这一点:
[...]
reserved resources to load servable {name: my_mnist_model version: 2}
[...]
Reading SavedModel from: /models/my_mnist_model/0002
Reading meta graph with tags { serve }
Successfully loaded servable version {name: my_mnist_model version: 2}
Quiescing servable version {name: my_mnist_model version: 1}
Done quiescing servable version {name: my_mnist_model version: 1}
Unloading servable version {name: my_mnist_model version: 1}这种方法提供了平滑的过渡,但它可能会使用过多的 RAM(尤其是 GPU RAM,它通常是最有限的)。在这种情况下,您可以配置 TF Serving 以便它使用以前的模型版本处理所有挂起的请求,并在加载和使用新模型版本之前将其卸载。此配置将避免同时加载两个模型版本,但服务会在短时间内不可用。
如您所见,TF Serving 使部署新模型变得非常简单。此外,如果您发现版本 2 没有像您预期的那样工作,那么回滚到版本 1 就像删除my_mnist_model/0002目录一样简单。
小费
TF Serving 的另一个重要功能是它的自动批处理功能,您可以
--enable_batching在启动时使用该选项来激活它。当 TF Serving 在短时间内(延迟可配置)接收到多个请求时,会在使用模型之前自动将它们批处理在一起。这通过利用 GPU 的强大功能提供了显着的性能提升。一旦模型返回预测,TF Serving 就会将每个预测分派给正确的客户端。您可以通过增加批处理延迟来换取更大的吞吐量(请参阅--batching_parameters_file选项)。
如果您希望每秒获得许多查询,您将希望在多台服务器上部署 TF Serving 并对查询进行负载平衡(参见图 19-2)。这将需要在这些服务器上部署和管理许多 TF Serving 容器。解决这个问题的一种方法是使用Kubernetes等工具,这是一个开源系统,用于简化跨多个服务器的容器编排。如果您不想购买、维护和升级所有硬件基础设施,您将需要在云平台上使用虚拟机,例如 Amazon AWS、Microsoft Azure、Google Cloud Platform、IBM Cloud、阿里云、Oracle Cloud 或其他一些平台即服务 (PaaS)。管理所有虚拟机、处理容器编排(即使在 Kubernetes 的帮助下)、负责 TF Serving 配置、调优和监控——所有这些都可以是一项全职工作。幸运的是,一些服务提供商可以为您处理这一切。在本章中,我们将使用 Google Cloud AI Platform,因为它是当今唯一具有 TPU 的平台,它支持 TensorFlow 2,它提供了一套不错的 AI 服务(例如 AutoML、Vision API、Natural Language API),它是我最有经验的一个。但该领域还有其他几家供应商,例如 Amazon AWS SageMaker 和 Microsoft AI Platform,它们也能够为 TensorFlow 模型提供服务。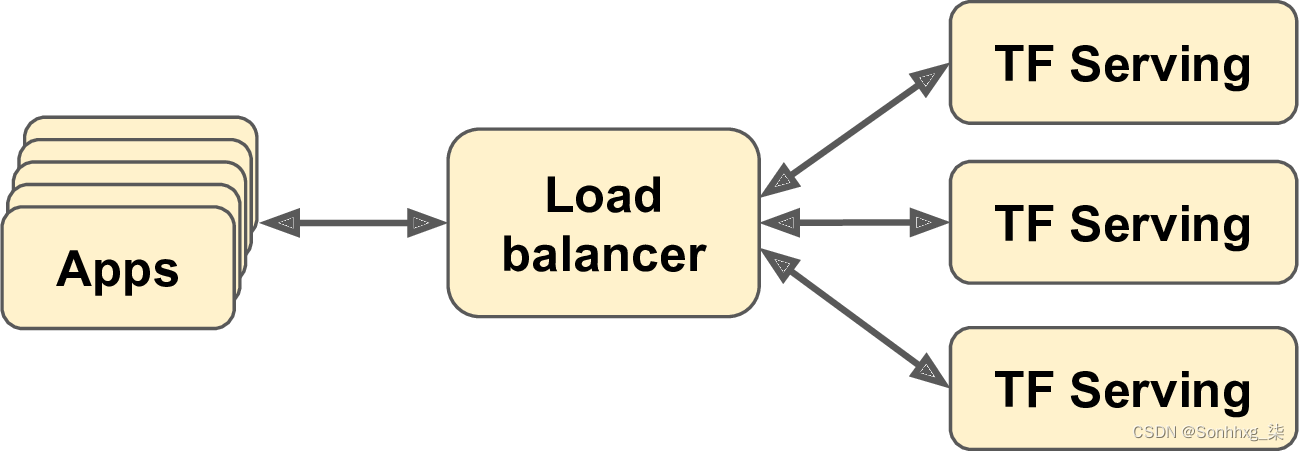
图 19-2。通过负载均衡扩展 TF Serving
现在让我们看看如何在云端服务我们出色的 MNIST 模型!
在 GCP AI 平台上创建预测服务
在部署模型之前,需要进行一些设置:
-
日志进入你的谷歌账户,然后进入谷歌云平台(GCP)控制台(见图19-3)。如果您没有 Google 帐户,则必须创建一个。
-
如果这是您第一次使用 GCP,您必须阅读并接受条款和条件。如果需要,请单击 Tour Console。在撰写本文时,新用户可以免费试用,包括价值 300 美元的 GCP 信用额度,您可以在 12 个月内使用。您只需要其中的一小部分来支付您将在本章中使用的服务。注册免费试用后,您仍然需要创建付款资料并输入您的信用卡号:它用于验证目的(可能是为了避免人们多次使用免费试用),但不会向您收费。如果需要,激活并升级您的帐户。
图 19-3。谷歌云平台控制台
-
如果您之前使用过 GCP,并且您的免费试用期已过期,那么您将在本章中使用的服务将花费您一些钱。它不应该太多,特别是如果您记得在不再需要服务时关闭它们。在运行任何服务之前,请确保您了解并同意定价条件。如果服务最终花费超过您的预期,我特此拒绝承担任何责任!还要确保您的结算帐户处于活动状态。要检查,请打开左侧的导航菜单并单击结算,并确保您已设置付款方式并且结算帐户处于活动状态。
-
GCP 中的每个资源都属于一个项目。这包括您可能使用的所有虚拟机、您存储的文件以及您运行的训练作业。当您创建帐户时,GCP 会自动为您创建一个名为“我的第一个项目”的项目。如果需要,您可以通过转到项目设置来更改其显示名称:在导航菜单(屏幕左侧)中,选择 IAM & admin → Settings,更改项目的显示名称,然后单击保存。请注意,该项目还具有唯一的 ID 和编号。您可以在创建项目时选择项目 ID,但以后无法更改。项目编号是自动生成的,不能更改。如果要创建新项目,请单击页面顶部的项目名称,然后单击新建项目并输入项目 ID。确保此新项目的计费有效。
警告
当您知道只需要几个小时的服务时,请始终设置警报以提醒自己关闭服务,否则您可能会让它们运行数天或数月,从而产生潜在的巨额成本。
-
现在如果您有一个激活了结算功能的 GCP 帐户,您就可以开始使用这些服务了。您需要的第一个是 Google Cloud Storage (GCS):您将在其中放置 SavedModel、训练数据等。在导航菜单中,向下滚动到存储部分,然后单击存储 → 浏览器。您的所有文件都将放在一个或多个存储桶中. 单击创建存储桶并选择存储桶名称(您可能需要先激活存储 API)。GCS 对存储桶使用单一的全球命名空间,因此像“机器学习”这样的简单名称很可能不可用。确保存储桶名称符合 DNS 命名约定,因为它可能会在 DNS 记录中使用。此外,存储桶名称是公开的,因此不要在其中放置任何私有内容。通常使用您的域名或您的公司名称作为前缀以确保唯一性,或者只是使用随机数作为名称的一部分。选择您希望托管存储桶的位置,其余选项默认情况下应该没问题。然后单击创建。
-
将您之前创建的my_mnist_model文件夹(包括一个或多个版本)上传到您的存储桶。为此,只需进入 GCS 浏览器,单击存储桶,然后将my_mnist_model文件夹从系统拖放到存储桶(见图 19-4)。或者,您可以单击“上传文件夹”并选择要上传的my_mnist_model文件夹。默认情况下,SavedModel 的最大大小为 250 MB,但可以请求更高的配额。

图 19-4。将 SavedModel 上传到 Google Cloud Storage
-
现在您需要配置 AI Platform(以前称为 ML Engine),以便它知道您要使用哪些模型和版本。在导航菜单中,向下滚动到人工智能部分,然后单击 AI 平台 → 模型。单击激活 API(需要几分钟),然后单击“创建模型”。填写模型详细信息(见图 19-5)并单击 Create。

图 19-5。在 Google Cloud AI Platform 上创建新模型
-
现在您在 AI Platform 上拥有了一个模型,您需要创建一个模型版本。在模型列表中,点击刚刚创建的模型,然后点击“创建版本”并填写版本详情(见图19-6):设置名称、描述、Python版本(3.5或以上)、框架(TensorFlow )、框架版本(2.0 如果可用,或 1.13)、6 ML 运行时版本(2.0,如果可用或 1.13)、机器类型(现在选择“单核 CPU”)、GCS 上的模型路径(这是完整路径实际版本文件夹,例如gs://my-mnist-model-bucket/my_mnist_model/0002/)、缩放(选择自动)以及始终运行的 TF Serving 容器的最小数量(将此字段留空) . 然后单击保存。

图 19-6。在 Google Cloud AI Platform 上创建新模型版本
恭喜,您已经在云端部署了您的第一个模型!因为您选择了自动扩展,所以当每秒查询数增加时,AI Platform 会启动更多的 TF Serving 容器,并对它们之间的查询进行负载均衡。如果 QPS 下降,它将自动停止容器。因此,成本与 QPS(以及您选择的机器类型和您在 GCS 上存储的数据量)直接相关。这种定价模型对于偶尔使用的用户和具有重要使用高峰的服务以及初创公司特别有用:在初创公司真正启动之前,价格一直很低。
笔记
如果您不使用预测服务,AI Platform 将停止所有容器。这意味着您只需为使用的存储量付费(每月每 GB 几美分)。请注意,当您查询服务时,AI Platform 将需要启动一个 TF Serving 容器,这需要几秒钟的时间。如果此延迟不可接受,则必须在创建模型版本时将 TF Serving 容器的最小数量设置为 1。当然,这意味着至少有一台机器会持续运行,因此月费会更高。
使用预测服务
在下面引擎盖上,AI Platform 只运行 TF Serving,所以原则上你可以使用与之前相同的代码,如果你知道要查询哪个 URL。只有一个问题:GCP 还负责加密和身份验证。加密基于 SSL/TLS,身份验证基于令牌:必须在每个请求中将秘密身份验证令牌发送到服务器。因此,在您的代码可以使用预测服务(或任何其他 GCP 服务)之前,它必须获得一个令牌。我们将很快看到如何执行此操作,但首先您需要配置身份验证并为您的应用程序提供 GCP 上的适当访问权限。您有两种身份验证选项:
-
您的应用程序(即,将查询预测服务的客户端代码)可以使用具有您自己的 Google 登录名和密码的用户凭据进行身份验证。使用用户凭据会给您的应用程序提供与 GCP 完全相同的权限,这肯定超出了它的需要。此外,您必须在应用程序中部署您的凭据,因此任何有权访问的人都可以窃取您的凭据并完全访问您的 GCP 帐户。总之,不要选择这个选项;它仅在极少数情况下需要(例如,当您的应用程序需要访问其用户的 GCP 帐户时)。
-
这客户端代码可以使用服务帐户进行身份验证。这是一个代表应用程序的帐户,而不是用户。它通常被赋予非常有限的访问权限:严格来说是它需要的,仅此而已。这是推荐的选项。
因此,让我们为您的应用程序创建一个服务帐户:在导航菜单中,转到 IAM & admin → 服务帐户,然后单击创建服务帐户,填写表格(服务帐户名称、ID、描述),然后单击创建(见图 19-7)。接下来,您必须授予此帐户一些访问权限。选择 ML Engine Developer 角色:这将允许服务帐户进行预测,仅此而已。或者,您可以授予某些用户对服务帐号的访问权限(当您的 GCP 用户帐号是组织的一部分时,这很有用,并且您希望授权组织中的其他用户部署将基于此服务帐号的应用程序或管理服务帐户本身)。接下来,单击 Create Key 以导出服务帐户的私钥,选择 JSON,然后单击 Create。这将以 JSON 文件的形式下载私钥。确保保密!
图 19-7。在 Google IAM 中创建新服务帐号
伟大的!现在让我们编写一个查询预测服务的小脚本。Google 提供了几个库来简化对其服务的访问:
Google API 客户端库
这是OAuth 2.0(用于身份验证)和 REST之上的一个相当薄的层。您可以将它与所有 GCP 服务一起使用,包括 AI Platform。您可以使用 pip 安装它:该库名为google-api-python-client.
谷歌云客户端库
这些是更高级别的:每个都专用于特定的服务,例如 GCS、Google BigQuery、Google Cloud Natural Language 和 Google Cloud Vision。所有这些库都可以使用 pip 安装(例如,调用 GCS 客户端库google-cloud-storage)。当客户端库可用于给定服务时,建议使用它而不是 Google API 客户端库,因为它实现了所有最佳实践,并且通常使用 gRPC 而不是 REST,以获得更好的性能。
在撰写本文时,还没有适用于 AI Platform 的客户端库,因此我们将使用 Google API 客户端库。它将需要使用服务帐户的私钥;GOOGLE_APPLICATION_CREDENTIALS您可以通过在启动脚本之前或在脚本中设置环境变量来告诉它它在哪里,如下所示:
import os
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = "my_service_account_key.json"笔记
如果您将应用程序部署到 Google Cloud Engine (GCE) 上的虚拟机,或使用 Google Cloud Kubernetes Engine 在容器内,或作为 Google Cloud App Engine 上的 Web 应用程序,或作为 Google Cloud Functions 上的微服务,并且如果
GOOGLE_APPLICATION_CREDENTIALS未设置环境变量,则库将使用主机服务的默认服务帐户(例如,默认 GCE 服务帐户,如果您的应用程序在 GCE 上运行)。
接下来,您必须创建一个资源对象来包装对预测服务的访问:7
import googleapiclient.discovery
project_id = "onyx-smoke-242003" # change this to your project ID
model_id = "my_mnist_model"
model_path = "projects/{}/models/{}".format(project_id, model_id)
ml_resource = googleapiclient.discovery.build("ml", "v1").projects()请注意,您可以将/versions/0001(或任何其他版本号)附加到model_path以指定要查询的版本:这对于 A/B 测试或在发布之前在一小群用户上测试新版本很有用它广泛(这称为金丝雀)。接下来,让我们编写一个小函数,该函数将使用资源对象调用预测服务并取回预测:
def predict(X):
input_data_json = {"signature_name": "serving_default",
"instances": X.tolist()}
request = ml_resource.predict(name=model_path, body=input_data_json)
response = request.execute()
if "error" in response:
raise RuntimeError(response["error"])
return np.array([pred[output_name] for pred in response["predictions"]])该函数接受一个包含输入图像的 NumPy 数组,并准备一个字典,客户端库将转换为 JSON 格式(正如我们之前所做的那样)。然后它准备一个预测请求,并执行它;如果响应包含错误,它会引发异常,否则它会提取每个实例的预测并将它们捆绑在 NumPy 数组中。让我们看看它是否有效:
>>> Y_probas = predict(X_new)
>>> np.round(Y_probas, 2)
array([[0. , 0. , 0. , 0. , 0. , 0. , 0. , 1. , 0. , 0. ],
[0. , 0. , 0.99, 0.01, 0. , 0. , 0. , 0. , 0. , 0. ],
[0. , 0.96, 0.01, 0. , 0. , 0. , 0. , 0.01, 0.01, 0. ]])是的!您现在在云上运行了一个不错的预测服务,它可以自动扩展到任意数量的 QPS,而且您可以从任何地方安全地查询它。此外,当您不使用它时,您几乎不需要花费任何费用:您只需每月在 GCS 上使用的每 GB 支付几美分。您还可以使用Google Stackdriver获取详细的日志和指标。
将模型部署到移动或嵌入式设备
如果您需要将模型部署到移动或嵌入式设备,大型模型可能需要很长时间才能下载并使用过多的 RAM 和 CPU,所有这些都会使您的应用程序无响应、设备发热并耗尽电池电量。为避免这种情况,您需要制作一个适合移动设备、轻量级且高效的模型,同时又不会牺牲太多的准确性。TFLite库提供了多种工具8来帮助您将模型部署到移动和嵌入式设备,具有三个主要目标:
-
减小模型大小,以缩短下载时间并减少 RAM 使用量。
-
减少每次预测所需的计算量,以减少延迟、电池使用和发热。
-
使模型适应特定于设备的约束。
为了减小模型大小,TFLite 的模型转换器可以采用 SavedModel 并将其压缩为基于FlatBuffers的更轻量级的格式。这是一个高效的跨平台序列化库(有点像协议缓冲区),最初由 Google 创建用于游戏。它的设计目的是让您无需任何预处理即可将 FlatBuffers 直接加载到 RAM:这减少了加载时间和内存占用。一旦模型加载到移动或嵌入式设备中,TFLite 解释器将执行它以进行预测。以下是将 SavedModel 转换为 FlatBuffer 并将其保存到.tflite文件的方法:
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_path)
tflite_model = converter.convert()
with open("converted_model.tflite", "wb") as f:
f.write(tflite_model)小费
您还可以使用 .将 tf.keras 模型直接保存到 FlatBuffer 中
from_keras_model()。
转换器还优化模型,以缩小模型并减少延迟。它修剪所有不需要进行预测的操作(例如训练操作),并尽可能优化计算;例如, 3× a + 4× a + 5× a将转换为 (3 + 4 + 5)× a。它还尽可能尝试融合操作。例如,Batch Normalization 层最终会尽可能地折叠到前一层的加法和乘法运算中。要了解 TFLite 可以优化模型的程度,请下载一个预训练的TFLite 模型,解压缩存档,然后打开出色的Netron 图形可视化工具并上传.pb文件以查看原始模型。这是一个大而复杂的图表,对吧?接下来,打开优化的.tflite模型,惊叹于它的美丽!
另一种可以减小模型大小(而不是简单地使用更小的神经网络架构)的方法是使用更小的位宽:例如,如果您使用半浮点数(16 位)而不是常规浮点数(32 位),则模型尺寸将缩小 2 倍,代价是(通常很小)精度下降。此外,训练会更快,您将使用大约一半的 GPU RAM。
TFLite 的转换器可以走得更远,通过将模型权重量化为定点 8 位整数!与使用 32 位浮点数相比,这导致大小减少了四倍。这最简单的方法称为训练后量化:它只是在训练后量化权重,使用一种相当基本但有效的对称量化技术。它找到最大绝对权重值m,然后将浮点范围 – m到 + m映射到定点(整数)范围 –127 到 +127。例如(参见图 19-8),如果权重范围从 –1.5 到 +0.8,那么字节 –127、0 和 +127 将分别对应于浮点数 –1.5、0.0 和 +1.5。请注意,当使用对称量化时,0.0 始终映射为 0(另请注意,不会使用字节值 +68 到 +127,因为它们映射到大于 +0.8 的浮点数)。
图 19-8。从 32 位浮点数到 8 位整数,使用对称量化
要执行此训练后量化,只需OPTIMIZE_FOR_SIZE在调用方法之前添加到转换器优化列表convert():
converter.optimizations = [tf.lite.Optimize.OPTIMIZE_FOR_SIZE]这种技术极大地减小了模型的大小,因此下载和存储速度要快得多。然而,在运行时,量化权重在使用之前会被转换回浮点数(这些恢复的浮点数与原始浮点数并不完全相同,但不会相差太远,因此精度损失通常是可以接受的)。为了避免一直重新计算它们,恢复的浮点数被缓存,因此不会减少 RAM 使用量。而且计算速度也没有降低。
减少延迟和功耗的最有效方法是同时量化激活,以便可以完全使用整数完成计算,而无需任何浮点运算。即使使用相同的位宽(例如,32 位整数而不是 32 位浮点数),整数计算使用更少的 CPU 周期、消耗更少的能量并产生更少的热量。而且,如果您还减少位宽(例如,减少到 8 位整数),您可以获得巨大的加速。此外,一些神经网络加速器设备(例如 Edge TPU)只能处理整数,因此必须对权重和激活进行完全量化。这可以在训练后完成;它需要一个校准步骤来找到激活的最大绝对值,
量化的主要问题是它失去了一点准确性:它相当于在权重和激活中添加了噪声。如果精度下降太严重,那么您可能需要使用量化感知训练。这意味着向模型添加虚假量化操作,以便它可以学会在训练期间忽略量化噪声;最终的权重将对量化更加稳健。此外,校准步骤可以在训练期间自动完成,从而简化了整个过程。
我已经解释了 TFLite 的核心概念,但要编写一个移动应用程序或嵌入式程序需要另外一本书。幸运的是,存在一个:如果您想了解有关为移动和嵌入式设备构建 TensorFlow 应用程序的更多信息,请查看由 Pete Warden(谁领导 TFLite 团队)和 Daniel Situnayake。
浏览器中的 TENSORFLOW
如果您想在网站中使用您的模型,直接在用户的浏览器中运行怎么办?这在许多情况下都很有用,例如:
-
当您的 Web 应用程序经常在用户连接断断续续或缓慢的情况下使用时(例如,徒步旅行者的网站),因此直接在客户端运行模型是使您的网站可靠的唯一方法。
-
当您需要模型的响应尽可能快时(例如,对于在线游戏)。消除查询服务器以进行预测的需要肯定会减少延迟并使网站更具响应性。
-
当您的 Web 服务根据一些私人用户数据进行预测时,您希望通过在客户端进行预测来保护用户的隐私,从而使私人数据永远不必离开用户的机器。9
对于所有这些场景,您可以将模型导出为可由TensorFlow.js JavaScript 库加载的特殊格式。然后,该库可以使用您的模型直接在用户的浏览器中进行预测。TensorFlow.js 项目包括一个tensorflowjs_converter可以将 TensorFlow SavedModel 或 Keras 模型文件转换为TensorFlow.js 层格式的工具:这是一个包含一组二进制格式的分片权重文件和一个model.json的目录描述模型架构和权重文件链接的文件。此格式经过优化,可在网络上有效下载。然后,用户可以使用 TensorFlow.js 库下载模型并在浏览器中运行预测。这是一个代码片段,可让您了解 JavaScript API 的外观:
import * as tf from '@tensorflow/tfjs';
const model = await tf.loadLayersModel('https://example.com/tfjs/model.json');
const image = tf.fromPixels(webcamElement);
const prediction = model.predict(image);再一次,公正地处理这个话题需要一整本书。如果您想了解有关 TensorFlow.js 的更多信息,请查看由 Anirudh Koul、Siddha Ganju 和 Meher Kasam撰写的 O'Reilly的云、移动和边缘实用深度学习一书。
使用 GPU 加速计算
在第 11 章中,我们讨论了几种可以大大加快训练速度的技术:更好的权重初始化、批量标准化、复杂的优化器等等。但即使使用所有这些技术,在具有单个 CPU 的单台机器上训练大型神经网络也可能需要数天甚至数周的时间。
在本节中,我们将了解如何使用 GPU 加速您的模型。我们还将看到如何将计算拆分到多个设备上,包括 CPU 和多个 GPU 设备(见图 19-9)。现在我们将在一台机器上运行所有东西,但在本章后面我们将讨论如何在多个服务器上分布计算。
图 19-9。跨多个设备并行执行 TensorFlow 图
多亏了 GPU,您不必等待数天或数周才能完成训练算法,您最终可能只需要等待几分钟或几小时。这不仅节省了大量时间,而且还意味着您可以更轻松地试验各种模型,并经常根据新数据重新训练模型。
小费
你只需将 GPU 卡添加到单台机器上,通常就可以大幅提升性能。事实上,在很多情况下这已经足够了;您根本不需要使用多台机器。例如,由于分布式设置中网络通信带来的额外延迟,您通常可以在单台机器上使用 4 个 GPU 而不是在多台机器上使用 8 个 GPU 以同样快的速度训练神经网络。同样,使用单个强大的 GPU 通常比使用多个速度较慢的 GPU 更可取。
第一步是使用 GPU。有两种选择:您可以购买自己的 GPU,也可以在云上使用配备 GPU 的虚拟机。让我们从第一个选项开始。
获得自己的 GPU
如果您选择购买 GPU 卡,然后花一些时间做出正确的选择。Tim Dettmers 写了一篇出色的博客文章来帮助您选择,他会定期更新:我鼓励您仔细阅读。在撰写本文时,TensorFlow 仅支持具有 CUDA Compute Capability 3.5+ 的 Nvidia 卡(当然还有 Google 的 TPU),但它可能会将支持扩展到其他制造商。此外,虽然 TPU 目前仅在 GCP 上可用,但很有可能在不久的将来会出售类似 TPU 的卡,TensorFlow 可能会支持它们。简而言之,请务必查看TensorFlow 的文档以了解此时支持哪些设备。
如果如果您选择 Nvidia GPU 卡,则需要安装适当的 Nvidia 驱动程序和几个 Nvidia 库。10其中包括 计算统一设备架构库 (CUDA),它允许开发人员使用支持 CUDA 的 GPU 进行各种计算(不仅仅是图形加速),以及CUDA 深度神经网络库 (cuDNN),一个 GPU 加速的 DNN 原语库. cuDNN 提供了常见 DNN 计算的优化实现,例如激活层、归一化、前向和后向卷积以及池化(参见第 14 章)。它是 Nvidia 的深度学习 SDK 的一部分(请注意,您需要创建一个 Nvidia 开发人员帐户才能下载它)。TensorFlow 使用 CUDA 和 cuDNN 来控制 GPU 卡并加速计算(见图 19-10)。
图 19-10。TensorFlow 使用 CUDA 和 cuDNN 来控制 GPU 和增强 DNN
安装 GPU 卡和所有必需的驱动程序和库后,您可以使用该nvidia-smi命令检查 CUDA 是否已正确安装。它列出了可用的 GPU 卡,以及在每张卡上运行的进程:
$ nvidia-smi
Sun Jun 2 10:05:22 2019
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 418.67 Driver Version: 410.79 CUDA Version: 10.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla T4 Off | 00000000:00:04.0 Off | 0 |
| N/A 61C P8 17W / 70W | 0MiB / 15079MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+在撰写本文时,您还需要安装 TensorFlow 的 GPU 版本(即tensorflow-gpu库);但是,目前正在努力为纯 CPU 和 GPU 机器制定统一的安装过程,因此请查看安装文档以了解您应该安装哪个库。在任何情况下,由于正确安装每个所需的库有点长且棘手(如果您不安装正确的库版本,一切都会变得混乱),TensorFlow 提供了一个 Docker 映像,其中包含您需要的所有内容。但是,为了让 Docker 容器能够访问 GPU,您仍然需要在主机上安装 Nvidia 驱动程序。
要检查 TensorFlow 是否确实看到了 GPU,请运行以下测试:
>>> import tensorflow as tf
>>> tf.test.gpu_device_name()
'/device:GPU:0'
>>> tf.config.experimental.list_physical_devices(device_type='GPU')
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]该gpu_device_name()函数给出了第一个 GPU 的名称:默认情况下,操作将在此 GPU 上运行。该list_physical_devices()函数返回所有可用 GPU 设备的列表(本例中只有一个)。11
现在,如果您不想花时间和金钱购买自己的 GPU 卡怎么办?只需在云上使用 GPU VM!
使用配备 GPU 的虚拟机
全部主要云平台现在提供 GPU VM,其中一些预配置了您需要的所有驱动程序和库(包括 TensorFlow)。谷歌云平台在全球和每个地区强制执行各种 GPU 配额:您不能在未经谷歌事先授权的情况下创建数千个 GPU 虚拟机。12默认情况下,全球 GPU 配额为零,因此您不能使用任何 GPU 虚拟机。因此,您需要做的第一件事就是申请更高的全球配额。在 GCP 控制台中,打开导航菜单并转到 IAM & admin → Quotas。点击 Metric,点击 None 取消勾选所有指标,然后搜索“GPU”,选择“GPUs (all region)”可以看到对应的配额。如果此配额的值为零(或仅不足以满足您的需要),则选中它旁边的框(它应该是唯一选择的)并单击“编辑配额”。填写请求的信息,然后单击“提交请求”。处理和(通常)接受您的配额请求可能需要几个小时(或最多几天)。默认情况下,每个区域和每个 GPU 类型也有一个 GPU 的配额。您也可以请求增加这些配额:单击 Metric,选择无取消选中所有指标,搜索“GPU”,然后选择您想要的 GPU 类型(例如,NVIDIA P4 GPU)。然后点击Location下拉菜单,点击None取消勾选所有位置,点击你想要的位置;选中要更改的配额旁边的框,然后单击“编辑配额”以提交请求。
一次您的 GPU 配额请求获得批准,您可以立即使用 Google Cloud AI Platform 的深度学习 VM 映像创建配备一个或多个 GPU 的VM :转到https://homl.info/dlvm,单击查看控制台,然后单击“在 Compute Engine 上启动”并填写 VM 配置表。请注意,有些位置没有所有类型的 GPU,有些根本没有 GPU(更改位置以查看可用的 GPU 类型,如果有)。确保选择 TensorFlow 2.0 作为框架,并勾选“首次启动时自动安装 NVIDIA GPU 驱动程序”。勾选“Enable access to JupyterLab via URL instead of SSH”也是一个好主意:这将使启动在此 GPU VM 上运行的 Jupyter notebook 变得非常容易,供电由 JupyterLab 提供(这是运行 Jupyter 笔记本的替代 Web 界面)。创建 VM 后,向下滚动导航菜单到人工智能部分,然后单击 AI Platform → Notebooks。一旦 Notebook 实例出现在列表中(这可能需要几分钟,因此请不时单击 Refresh 直到它出现),单击其 Open JupyterLab 链接。这将在 VM 上运行 JupyterLab 并将您的浏览器连接到它。您可以在此 VM 上创建笔记本并运行您想要的任何代码,并从其 GPU 中受益!
但是,如果您只想运行一些快速测试或轻松与同事共享笔记本,那么您应该尝试 Colaboratory。
合作实验室
这访问 GPU VM 的最简单和最便宜的方法是使用Colaboratory(或简称 Colab)。免费!只需转到https://colab.research.google.com/并创建一个新的 Python 3 笔记本:这将创建一个 Jupyter 笔记本,存储在您的 Google Drive 上(或者,您可以在 GitHub 或 Google Drive 上打开任何笔记本,或者您甚至可以上传自己的笔记本)。Colab 的用户界面类似于 Jupyter 的,除了您可以像普通的 Google Docs 一样共享和使用笔记本,还有一些其他的细微差别(例如,您可以使用代码中的特殊注释创建方便的表单)。
什么时候你打开一个 Colab 笔记本,它运行在一个专用于该笔记本的免费 Google VM 上,称为Colab 运行时(见图 19-11)。默认情况下,运行时只有 CPU,但您可以通过转到运行时→“更改运行时类型”,在“硬件加速器”下拉菜单中选择 GPU,然后单击保存来更改它。事实上,您甚至可以选择 TPU!(是的,你实际上可以免费使用 TPU;不过,我们将在本章后面讨论 TPU,所以现在只选择 GPU。)

图 19-11。Colab 运行时和笔记本
Colab 确实有一些限制:首先,您可以同时运行的 Colab 笔记本的数量是有限制的(目前每个 Runtime 类型有 5 个)。此外,正如常见问题解答所述,“Colaboratory 旨在用于交互使用。长时间运行的后台计算,特别是在 GPU 上,可能会停止。请不要使用 Colaboratory 进行加密货币挖掘。” 此外,如果您让其一段时间(约 30 分钟)无人看管,Web 界面将自动与 Colab Runtime 断开连接。当您重新连接到 Colab Runtime 时,它可能已被重置,因此请确保始终导出您关心的任何数据(例如,下载或保存到 Google Drive)。即使您从未断开连接,Colab Runtime 也会在 12 小时后自动关闭,因为它不适用于长时间运行的计算。尽管有这些限制,同事。
管理 GPU RAM
经过默认 TensorFlow 在您第一次运行计算时会自动获取所有可用 GPU 中的所有 RAM。它这样做是为了限制 GPU RAM 碎片。这意味着如果您尝试启动第二个 TensorFlow 程序(或任何需要 GPU 的程序),它将很快耗尽 RAM。这并不像您想象的那样经常发生,因为您通常会在机器上运行一个 TensorFlow 程序:通常是训练脚本、TF Serving 节点或 Jupyter 笔记本。如果您出于某种原因需要运行多个程序(例如,在同一台机器上并行训练两个不同的模型),那么您需要在这些进程之间更均匀地分配 GPU RAM。
如果您的机器上有多个 GPU 卡,一个简单的解决方案是将它们中的每一个分配给一个进程。为此,您可以设置CUDA_VISIBLE_DEVICES 环境变量,以便每个进程只能看到相应的 GPU 卡。还要设置CUDA_DEVICE_ORDER环境变量以PCI_BUS_ID确保每个 ID 始终引用同一个 GPU 卡。例如,如果您有四个 GPU 卡,您可以通过在两个单独的终端窗口中执行如下命令来启动两个程序,为每个程序分配两个 GPU:
$ CUDA_DEVICE_ORDER=PCI_BUS_ID CUDA_VISIBLE_DEVICES=0,1 python3 program_1.py# and in another terminal:
$ CUDA_DEVICE_ORDER=PCI_BUS_ID CUDA_VISIBLE_DEVICES=3,2 python3 program_2.py程序 1 将只能看到 GPU 卡 0 和 1,分别命名为/gpu:0和/gpu:1,程序 2 将只能看到 GPU 卡 2 和 3,分别命名为/gpu:1和/gpu:0(注意顺序)。一切都会正常工作(见图 19-12)。当然,你也可以在 Python 中通过设置os.environ["CUDA_DEVICE_ORDER"]和来定义这些环境变量os.environ["CUDA_VISIBLE_DEVICES"],只要你在使用 TensorFlow 之前这样做。
图 19-12。每个程序都有两个 GPU
其他选项是告诉 TensorFlow 只获取特定数量的 GPU RAM。这必须在导入 TensorFlow 后立即完成。例如,要让 TensorFlow 在每个 GPU 上只抓取 2 GiB 的 RAM,您必须为每个物理 GPU 设备创建一个虚拟 GPU 设备(也称为逻辑 GPU 设备)并将其内存限制设置为 2 GiB(即 2,048 MiB) :
for gpu in tf.config.experimental.list_physical_devices("GPU"):
tf.config.experimental.set_virtual_device_configuration(
gpu,
[tf.config.experimental.VirtualDeviceConfiguration(memory_limit=2048)])现在(假设你有四个 GPU,每个都有至少 4 GiB 的 RAM)像这样的两个程序可以并行运行,每个程序都使用所有四个 GPU 卡(见图 19-13)。
如果您nvidia-smi在两个程序都运行时运行该命令,您应该会看到每个进程在每张卡上拥有 2 GiB 的 RAM:
$ nvidia-smi
[...]
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 2373 C /usr/bin/python3 2241MiB |
| 0 2533 C /usr/bin/python3 2241MiB |
| 1 2373 C /usr/bin/python3 2241MiB |
| 1 2533 C /usr/bin/python3 2241MiB |
[...]另一种选择是告诉 TensorFlow 仅在需要时才获取内存(这也必须在导入 TensorFlow 后立即完成):.
for gpu in tf.config.experimental.list_physical_devices("GPU"):
tf.config.experimental.set_memory_growth(gpu, True)另一种方法是将TF_FORCE_GPU_ALLOW_GROWTH环境变量设置为true. 使用此选项,TensorFlow 将永远不会释放内存(再次,以避免内存碎片),当然程序结束时除外。使用此选项可能更难保证确定性行为(例如,一个程序可能会因为另一个程序的内存使用量过大而崩溃),因此在生产中您可能希望坚持使用以前的选项之一。但是,在某些情况下它非常有用:例如,当您使用一台机器运行多个 Jupyter 笔记本时,其中有几个使用 TensorFlow。这就是在 Colab RuntimesTF_FORCE_GPU_ALLOW_GROWTH中设置环境变量的原因。true
最后,在某些情况下,您可能希望将 GPU 拆分为两个或多个虚拟 GPU — 例如,如果您想测试分布算法(这是尝试本章其余部分的代码示例的便捷方法,即使您有一个 GPU,例如在 Colab Runtime 中)。以下代码将第一个 GPU 拆分为两个虚拟设备,每个设备有 2 GiB 的 RAM(同样,这必须在导入 TensorFlow 后立即完成):
physical_gpus = tf.config.experimental.list_physical_devices("GPU")
tf.config.experimental.set_virtual_device_configuration(
physical_gpus[0],
[tf.config.experimental.VirtualDeviceConfiguration(memory_limit=2048),
tf.config.experimental.VirtualDeviceConfiguration(memory_limit=2048)])然后将调用这两个虚拟设备/gpu:0and /gpu:1,您可以在它们中的每一个上放置操作和变量,就好像它们真的是两个独立的 GPU 一样。现在让我们看看 TensorFlow 如何决定它应该在哪些设备上放置变量并执行操作。
在设备上放置操作和变量
这TensorFlow白皮书13呈现一种友好的动态布局器算法,它自动在所有可用设备上分配操作,考虑到诸如先前运行图的测量计算时间、每个操作的输入和输出张量大小的估计、可用的 RAM 量等因素。每个设备,将数据传入和传出设备时的通信延迟,以及来自用户的提示和约束。在实践中,该算法的效率低于用户指定的一小组放置规则,因此 TensorFlow 团队最终放弃了动态放置器。
也就是说,tf.keras 和 tf.data 通常可以很好地将操作和变量放在它们所属的位置(例如,GPU 上的繁重计算和 CPU 上的数据预处理)。但是,如果您想要更多控制,您也可以在每个设备上手动放置操作和变量:
-
如前所述,您通常希望将数据预处理操作放在 CPU 上,而将神经网络操作放在 GPU 上。
-
GPU 通常具有相当有限的通信带宽,因此避免不必要的数据进出 GPU 非常重要。
-
向机器添加更多 CPU RAM 很简单,而且相当便宜,因此通常有很多,而 GPU RAM 被嵌入到 GPU 中:它是一种昂贵且因此有限的资源,所以如果在接下来的几个中不需要变量训练步骤,它可能应该放在 CPU 上(例如,数据集通常属于 CPU)。
默认情况下,所有变量和所有操作都将放置在第一个 GPU(命名/gpu:0)上,除了没有 GPU 内核的变量和操作:14这些都放置在 CPU(命名/cpu:0)上。张量或变量的device属性告诉您它被放置在哪个设备上:15
>>> a = tf.Variable(42.0)
>>> a.device
'/job:localhost/replica:0/task:0/device:GPU:0'
>>> b = tf.Variable(42)
>>> b.device
'/job:localhost/replica:0/task:0/device:CPU:0'你现在可以放心地忽略前缀/job:localhost/replica:0/task:0(它允许你在使用 TensorFlow 集群时将操作放在其他机器上;我们将在本章后面讨论作业、副本和任务)。如您所见,第一个变量放置在 GPU 0 上,这是默认设备。然而,第二个变量被放在了 CPU 上:这是因为没有用于整数变量(或涉及整数张量的操作)的 GPU 内核,所以 TensorFlow 又回到了 CPU 上。
如果要将操作放在与默认设备不同的设备上,请使用tf.device()上下文:
>>> with tf.device("/cpu:0"):
... c = tf.Variable(42.0)
...
>>> c.device
'/job:localhost/replica:0/task:0/device:CPU:0'笔记
CPU 始终被视为单个设备 (
/cpu:0),即使您的机器有多个 CPU 内核。如果 CPU 具有多线程内核,则任何放置在 CPU 上的操作都可以跨多个内核并行运行。
如果您明确尝试将操作或变量放置在不存在或没有内核的设备上,那么您将收到异常。但是,在某些情况下,您可能更愿意回退到 CPU;例如,如果您的程序既可以在仅 CPU 的机器上运行,也可以在 GPU 机器上运行,您可能希望 TensorFlow 忽略您tf.device("/gpu:*")在仅 CPU 的机器上的运行。为此,您可以tf.config.set_soft_device_placement(True)在导入 TensorFlow 后立即调用:当放置请求失败时,TensorFlow 将回退到其默认放置规则(即,如果存在且有 GPU 内核,则默认为 GPU 0,否则为 CPU 0)。
现在 TensorFlow 将如何跨多个设备执行所有这些操作?
跨多个设备并行执行
作为我们在第 12 章中看到,使用 TF 函数的好处之一是并行性。让我们更仔细地看一下。当 TensorFlow 运行 TF 函数时,它首先分析其图形以查找需要评估的操作列表,并计算每个操作有多少依赖项。然后,TensorFlow 将每个具有零依赖关系的操作(即每个源操作)添加到该操作设备的评估队列中(见图 19-14)。一旦一个操作被评估,依赖于它的每个操作的依赖计数器都会递减。一旦操作的依赖计数器达到零,它就会被推送到其设备的评估队列中。一旦评估了 TensorFlow 需要的所有节点,它就会返回它们的输出。

图 19-14。TensorFlow 图的并行执行
运营在 CPU 的评估队列中被分派到一个称为inter-op 线程池的线程池。如果 CPU 有多个内核,那么这些操作将有效地并行评估。一些操作具有多线程 CPU 内核:这些内核将它们的任务分成多个子操作,这些子操作被放置在另一个评估队列中并分派到称为操作内线程池的第二个线程池(由所有多线程 CPU 内核共享)。简而言之,可以在不同的 CPU 内核上并行评估多个操作和子操作。
对于 GPU,事情要简单一些。GPU 评估队列中的操作是按顺序评估的。但是,大多数操作都有多线程 GPU 内核,通常由 TensorFlow 依赖的库实现,例如 CUDA 和 cuDNN。这些实现有自己的线程池,它们通常会尽可能多地利用 GPU 线程(这就是 GPU 中不需要互操作线程池的原因:每个操作已经淹没了大多数 GPU 线程)。
例如,在图 19-14,操作 A、B 和 C 是源操作,因此可以立即评估它们。操作 A 和 B 放在 CPU 上,因此它们被发送到 CPU 的评估队列,然后它们被分派到操作间线程池并立即并行评估。操作 A 恰好有一个多线程内核;它的计算分为三个部分,由内部操作线程池并行执行。操作 C 进入 GPU 0 的评估队列,在此示例中,其 GPU 内核恰好使用 cuDNN,它管理自己的内部操作线程池并在多个 GPU 线程上并行运行操作。假设 C 先完成。D 和 E 的依赖计数器递减并达到零,因此这两个操作都被推送到 GPU 0 的评估队列,并按顺序执行。请注意,C 只被评估一次,即使 D 和 E 都依赖它。假设 B 接下来完成。然后 F 的依赖计数器从 4 递减到 3,因为它不是 0,所以它还没有运行。一旦 A、D 和 E 完成,则 F 的依赖计数器达到 0,并将其推送到 CPU 的评估队列并进行评估。最后,TensorFlow 返回请求的输出。
TensorFlow 执行的一个额外魔法是当 TF 函数修改有状态资源(例如变量)时:它确保执行顺序与代码中的顺序匹配,即使语句之间没有显式依赖关系。例如,如果您的 TF 函数包含v.assign_add(1)后跟v.assign(v * 2),TensorFlow 将确保这些操作按该顺序执行。
小费
您可以通过调用来控制互操作线程池中的
tf.config.threading.set_inter_op_parallelism_threads()线程数。要设置操作内线程的数量,请使用tf.config.threading.set_intra_op_parallelism_threads(). 如果您不希望 TensorFlow 使用所有 CPU 内核或者您希望它是单线程的,这将非常有用。16
有了它,您就拥有了在任何设备上运行任何操作所需的一切,并利用 GPU 的强大功能!以下是您可以做的一些事情:
-
您可以并行训练多个模型,每个模型都在自己的 GPU 上:只需为每个模型编写一个训练脚本并并行运行它们,设置
CUDA_DEVICE_ORDER等,CUDA_VISIBLE_DEVICES以便每个脚本只看到一个 GPU 设备。这对于超参数调整非常有用,因为您可以使用不同的超参数并行训练多个模型。如果您有一台带有两个 GPU 的机器,并且在一个 GPU 上训练一个模型需要一个小时,那么并行训练两个模型,每个模型都在自己的专用 GPU 上,只需要一个小时。简单的! -
您可以在单个 GPU 上训练模型并在 CPU 上并行执行所有预处理,使用数据集的
prefetch()方法17提前准备接下来的几个批次,以便在 GPU 需要它们时准备好它们(参见第 13 章)。 -
如果您的模型将两个图像作为输入,并在加入它们的输出之前使用两个 CNN 处理它们,那么如果您将每个 CNN 放在不同的 GPU 上,它可能会运行得更快。
-
您可以创建一个高效的集成:只需在每个 GPU 上放置一个不同的训练模型,这样您就可以更快地获得所有预测,从而生成集成的最终预测。
跨多个设备训练模型
那里在多个设备上训练单个模型有两种主要方法:模型并行性,模型在设备间拆分;数据并行性,模型在每个设备上复制,每个副本都在数据子集上进行训练。在我们在多个 GPU 上训练模型之前,让我们仔细看看这两个选项。
模型并行
到目前为止,我们已经在单个设备上训练了每个神经网络。如果我们想在多个设备上训练单个神经网络怎么办?这需要将模型切成单独的块并在不同的设备上运行每个块。不幸的是,这种模型并行性非常棘手,它实际上取决于您的神经网络的架构。对于完全连接的网络,这种方法通常没有什么好处(见图 19-15)。直觉上,拆分模型的一种简单方法似乎是将每一层放在不同的设备上,但这不起作用,因为每一层都需要等待前一层的输出才能做任何事情。所以也许你可以垂直分割它——例如,每一层的左半部分在一个设备上,而右部分在另一个设备上?这样稍微好一点,因为每一层的两半确实可以并行工作,但问题是下一层的每一半都需要两半的输出,所以会有很多跨设备通信(以虚线箭头)。这很可能完全抵消了并行计算的好处,因为跨设备通信很慢(尤其是当设备位于不同的机器上时)。

图 19-15。拆分全连接神经网络
一些神经网络架构,例如卷积神经网络(参见第 14 章),包含仅部分连接到较低层的层,因此以有效的方式跨设备分布块要容易得多(图 19-16)。

图 19-16。拆分部分连接的神经网络
深度循环神经网络(见第 15 章)可以更有效地跨多个 GPU 进行拆分。如果您通过将每一层放置在不同的设备上来水平拆分网络,并为网络提供要处理的输入序列,那么在第一个时间步,只有一个设备将处于活动状态(处理序列的第一个值),在第二步二将处于活动状态(第二层将处理第一层的第一个值的输出,而第一层将处理第二个值),当信号传播到输出层时,所有设备将同时激活(图 19-17)。仍然有很多跨设备通信正在进行,但由于每个单元可能相当复杂,并行运行多个单元的好处可能(理论上)超过通信损失。LSTM然而,实际上,在单个 GPU 上运行的常规层堆栈实际上运行得更快。

图 19-17。拆分深度递归神经网络
简而言之,模型并行性可能会加速运行或训练某些类型的神经网络,但不是全部,它需要特别小心和调整,例如确保最需要通信的设备在同一台机器上运行。18让我们看一个更简单且通常更有效的选择:数据并行。
数据并行
其他并行化神经网络训练的方法是在每个设备上复制它,并在所有副本上同时运行每个训练步骤,为每个副本使用不同的小批量。然后对每个副本计算的梯度进行平均,并将结果用于更新模型参数。这称为数据并行。这个想法有很多变体,所以让我们看一下最重要的变体。
使用镜像策略的数据并行性
可以说最简单的方法是在所有 GPU 上完全镜像所有模型参数,并始终在每个 GPU 上应用完全相同的参数更新。这样,所有副本始终保持完全相同。这被称为镜像策略,结果证明它非常有效,尤其是在使用单机时(见图 19-18)。

图 19-18。使用镜像策略的数据并行性
使用这种方法的棘手部分是有效地计算来自所有 GPU 的所有梯度的平均值,并将结果分布到所有 GPU 上。这可以使用AllReduce算法,一类算法,多个节点协作以有效地执行归约操作(例如计算均值、总和和最大值),同时确保所有节点获得相同的最终结果。幸运的是,正如我们将看到的,这些算法有现成的实现。
具有集中参数的数据并行性
另一种方法是将模型参数存储在执行计算的 GPU 设备(称为工人)之外,例如在 CPU 上(见图 19-19)。在分布式设置中,您可以将所有参数放在一个或多个 CPU 上服务器称为参数服务器,其唯一作用是托管和更新参数。

图 19-19。具有集中参数的数据并行性
镜像策略在所有 GPU 上强制同步权重更新,而这种集中式方法允许同步或异步更新。让我们看看这两种选择的优缺点。
同步更新
和 同步更新,聚合器等待直到所有梯度都可用,然后计算平均梯度并将它们传递给优化器,优化器将更新模型参数。一旦副本完成计算其梯度,它必须等待参数更新,然后才能继续下一个小批量。缺点是某些设备可能比其他设备慢,因此所有其他设备在每一步都必须等待它们。此外,参数将几乎同时复制到每个设备(在应用梯度后立即),这可能会使参数服务器的带宽饱和。
小费
为了减少每一步的等待时间,您可以忽略最慢的几个副本的梯度(通常约为 10%)。例如,你可以运行 20 个副本,但在每一步只聚合最快的 18 个副本的梯度,而忽略最后 2 个的梯度。一旦参数更新,前 18 个副本可以立即重新开始工作,而不必等待 2 个最慢的副本。这个setup 通常被描述为有 18 个副本加上 2 个备用副本。19
异步更新
和异步更新,每当副本完成计算梯度时,它立即使用它们来更新模型参数。没有聚合(它删除了图 19-19中的“平均”步骤),也没有同步。副本独立于其他副本工作。由于没有等待其他副本,这种方法每分钟运行更多的训练步骤。此外,虽然每一步仍然需要将参数复制到每个设备,但每个副本的复制时间不同,因此降低了带宽饱和的风险。
具有异步更新的数据并行是一个有吸引力的选择,因为它简单、没有同步延迟以及更好地利用带宽。然而,尽管它在实践中运行得相当好,但它的运行几乎令人惊讶!事实上,当一个副本根据某些参数值计算完梯度时,这些参数将被其他副本更新几次(如果有N个副本,则平均更新N - 1 次),并且不能保证计算出的梯度仍将指向正确的方向(见图 19-20)。当梯度严重过时时,它们是称为陈旧梯度:它们可以减慢收敛速度,引入噪声和摆动效应(学习曲线可能包含临时振荡),甚至可以使训练算法发散。

图 19-20。使用异步更新时的陈旧梯度
有几种方法可以减少陈旧渐变的影响:
-
降低学习率。
-
删除陈旧的渐变或缩小它们。
-
调整小批量大小。
-
开始前几个时期只使用一个副本(这称为预热阶段)。陈旧的梯度在训练开始时往往更具破坏性,此时梯度通常很大并且参数尚未稳定到成本函数的谷底,因此不同的副本可能会将参数推向完全不同的方向。
Google Brain 团队在 2016 年20发表的一篇论文对各种方法进行了基准测试,发现使用带有少量备用副本的同步更新比使用异步更新更有效,不仅收敛速度更快,而且可以生成更好的模型。但是,这仍然是一个活跃的研究领域,因此您暂时不应该排除异步更新。
带宽饱和
无论您使用同步或异步更新,具有集中参数的数据并行性仍然需要在每个训练步骤开始时将模型参数从参数服务器传递到每个副本,并在每个训练步骤结束时将梯度传递到另一个方向。同样,当使用镜像策略时,每个 GPU 产生的梯度需要与其他所有 GPU 共享。不幸的是,总有一点,添加额外的 GPU 根本不会提高性能,因为将数据移入和移出 GPU RAM(以及在分布式设置中通过网络)所花费的时间将超过通过拆分计算获得的加速加载。那时,添加更多 GPU 只会恶化带宽饱和度,实际上会减慢训练速度。
小费
对于某些模型,通常相对较小且在非常大的训练集上进行训练,通常最好在具有大内存带宽的单个强大 GPU 的单台机器上训练模型。
对于大型密集模型,饱和度更为严重,因为它们有很多参数和梯度需要传递。对于小型模型(但并行化增益有限)和大型稀疏模型而言,它不太严重,其中梯度通常大部分为零,因此可以有效地传达。Google Brain 项目的发起人和负责人 Jeff Dean报告说,在 50 个 GPU 上为密集模型分配计算时,典型的加速比为 25-40 倍,而在 500 个 GPU 上训练的稀疏模型的加速比为 300 倍。如您所见,稀疏模型确实可以更好地扩展。下面是几个具体的例子:
-
神经机器翻译:8 个 GPU 上的 6 倍加速
-
Inception/ImageNet:在 50 个 GPU 上加速 32 倍
-
RankBrain:在 500 个 GPU 上加速 300 倍
密集模型需要几十个 GPU 或稀疏模型需要几百个 GPU,饱和度开始出现,性能下降。有大量研究正在解决这个问题(探索点对点架构而不是集中式参数服务器、使用有损模型压缩、优化副本需要通信的时间和内容等),因此可能会有未来几年在并行化神经网络方面取得了很大进展。
同时,为了减少饱和问题,您可能希望使用一些强大的 GPU,而不是大量的弱 GPU,并且您还应该将 GPU 分组在少数且互连良好的服务器上。您还可以尝试将浮点精度从 32 位 ( tf.float32) 降低到 16 位 ( tf.bfloat16)。这将减少一半的数据传输量,通常不会对收敛速度或模型性能产生太大影响。最后,如果您使用集中式参数,您可以将参数分片(拆分)到多个参数服务器:添加更多参数服务器将减少每个服务器上的网络负载并限制带宽饱和的风险。
好的,现在让我们在多个 GPU 上训练一个模型!
使用 Distribution Strategies API 进行大规模培训
许多模型可以在单个 GPU 甚至 CPU 上很好地训练。但如果训练太慢,您可以尝试将其分布在同一台机器上的多个 GPU 上。如果这仍然太慢,请尝试使用更强大的 GPU,或在机器上添加更多 GPU。如果您的模型执行繁重的计算(例如大型矩阵乘法),那么它将在强大的 GPU 上运行得更快,您甚至可以尝试在 Google Cloud AI Platform 上使用 TPU,对于此类模型通常运行得更快。但是,如果您无法在同一台机器上安装更多 GPU,并且 TPU 不适合您(例如,您的模型可能无法从 TPU 中获得太多好处,或者您可能想使用自己的硬件基础设施),那么你可以尝试在多台服务器上训练它,每台服务器都有多个 GPU(如果这还不够,作为最后的手段,您可以尝试添加一些模型并行性,但这需要更多的努力)。在本节中,我们将了解如何大规模训练模型,从同一台机器(或 TPU)上的多个 GPU 开始,然后在多台机器上使用多个 GPU。
幸运的是,TensorFlow附带一个非常简单的 API,可以为您处理所有复杂性:分发策略 API。要在所有可用 GPU 上(目前在单台机器上)使用数据并行和镜像策略来训练 Keras 模型,请创建一个MirroredStrategy对象,调用其scope()方法以获取分布上下文,然后将模型的创建和编译包装在其中语境。然后正常调用模型的fit()方法:
distribution = tf.distribute.MirroredStrategy()
with distribution.scope():
mirrored_model = keras.models.Sequential([...])
mirrored_model.compile([...])
batch_size = 100 # must be divisible by the number of replicas
history = mirrored_model.fit(X_train, y_train, epochs=10)在底层,tf.keras 是分布感知的,因此在这种MirroredStrategy情况下,它知道它必须在所有可用的 GPU 设备上复制所有变量和操作。请注意,该fit()方法会自动将每个训练批次拆分到所有副本中,因此批次大小可被副本数整除很重要。就这样!训练通常会比使用单个设备快得多,而且代码更改非常小。
完成模型训练后,您可以使用它来有效地进行预测:调用该predict()方法,它会自动将批次拆分到所有副本中,并行进行预测(同样,批次大小必须能被副本数整除)。如果调用模型的save()方法,它将被保存为常规模型,而不是具有多个副本的镜像模型。因此,当您加载它时,它将像常规模型一样在单个设备上运行(默认为 GPU 0,如果没有 GPU,则为 CPU)。如果要加载模型并在所有可用设备上运行它,则必须keras.models.load_model()在分发上下文中调用:
with distribution.scope():
mirrored_model = keras.models.load_model("my_mnist_model.h5")如果您只想使用所有可用 GPU 设备的子集,可以将列表传递给MirroredStrategy的构造函数:
distribution = tf.distribute.MirroredStrategy(["/gpu:0", "/gpu:1"])默认情况下,MirroredStrategy该类使用NVIDIA 集体通信库(NCCL)对于 AllReduce 均值操作,但您可以通过将cross_device_ops参数设置为tf.distribute.HierarchicalCopyAllReduce类的实例或类的实例来更改它tf.distribute.ReductionToOneDevice。默认的 NCCL 选项基于tf.distribute.NcclAllReduce类,这通常更快,但这取决于 GPU 的数量和类型,因此您可能想尝试替代方案。21
如果您想尝试使用具有集中参数的数据并行性,请将 替换MirroredStrategy为CentralStorageStrategy:
distribution = tf.distribute.experimental.CentralStorageStrategy()您可以选择设置compute_devices参数以指定要用作工作人员的设备列表(默认情况下,它将使用所有可用的 GPU),并且您可以选择设置parameter_device参数以指定要在其上存储参数的设备(默认情况下如果只有一个,它将使用 CPU 或 GPU)。
现在让我们看看如何跨 TensorFlow 服务器集群训练模型!
在 TensorFlow 集群上训练模型
TensorFlow集群是一组 TensorFlow 进程并行运行,通常在不同的机器上,并相互交谈以完成某些工作——例如,训练或执行神经网络。集群中的每个 TF 进程称为一个任务,或一个TF 服务器。它有一个 IP 地址、一个端口和一个类型(也称为它的角色或它的工作)。类型可以是"worker", "chief", "ps"(参数服务器), 或"evaluator":
-
每个工作人员执行计算,通常在具有一个或多个 GPU 的机器上。
-
主管也执行计算(它是一个工人),但它也处理额外的工作,例如编写 TensorBoard 日志或保存检查点。集群中只有一个酋长。如果没有指定负责人,则第一个工人是负责人。
-
参数服务器只跟踪变量值,它通常位于仅 CPU 的机器上。这种类型的任务仅与
ParameterServerStrategy. -
评估员显然负责评估。
至启动 TensorFlow 集群,您必须先指定它。这意味着定义每个任务的 IP 地址、TCP 端口和类型。例如,下面的集群规范定义了一个包含三个任务的集群(两个工作人员和一个参数服务器;见图 19-21)。集群规范是一个字典,每个作业有一个键,值是任务地址列表(IP:端口):
cluster_spec = {
"worker": [
"machine-a.example.com:2222", # /job:worker/task:0
"machine-b.example.com:2222" # /job:worker/task:1
],
"ps": ["machine-a.example.com:2221"] # /job:ps/task:0
}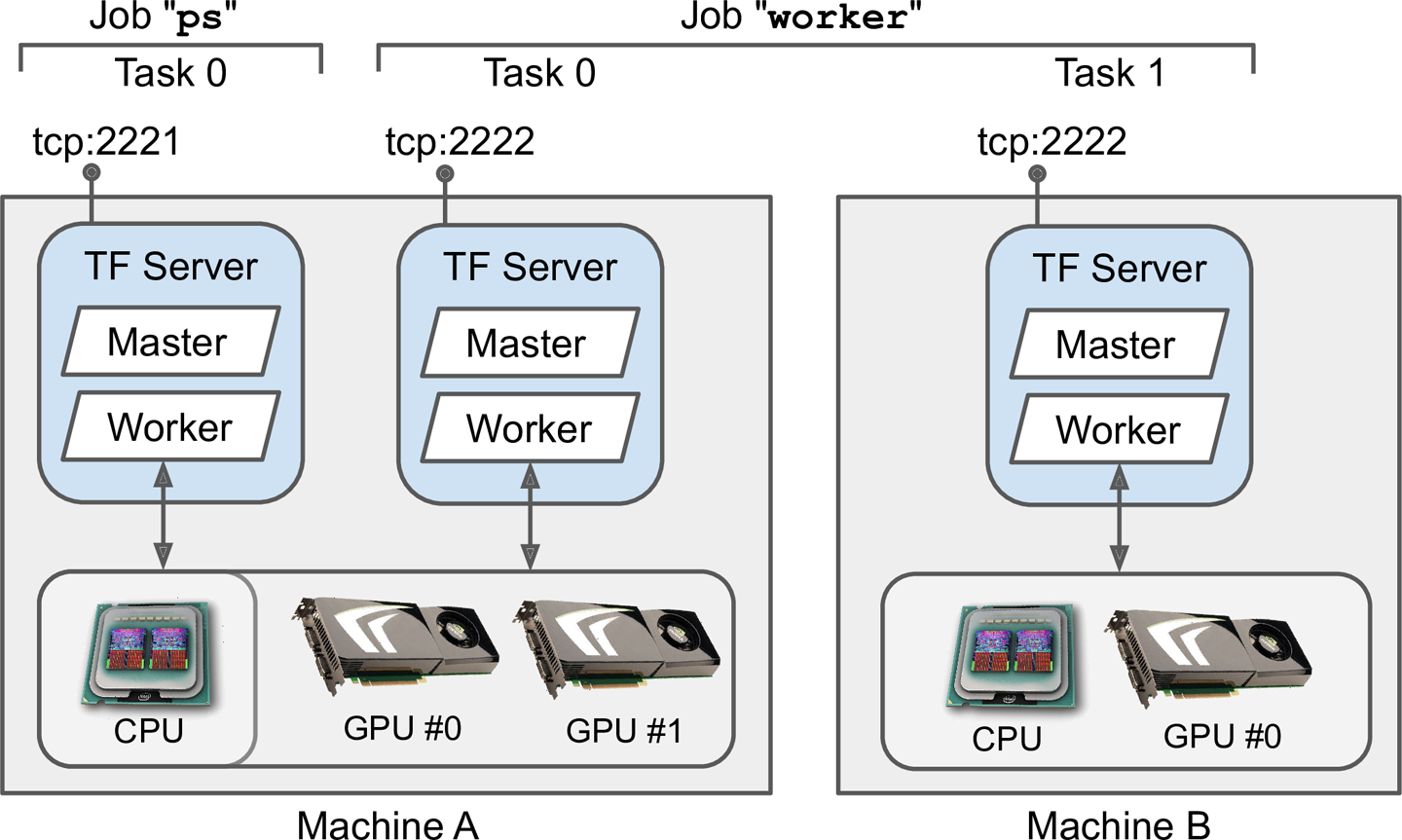
图 19-21。TensorFlow 集群
一般来说,每台机器都会有一个任务,但正如这个例子所示,如果你愿意,你可以在同一台机器上配置多个任务(如果它们共享相同的 GPU,请确保适当地分割 RAM,如前所述)。
警告
默认情况下,集群中的每个任务都可以与其他任务进行通信,因此请确保将防火墙配置为在这些端口上授权这些机器之间的所有通信(如果在每台机器上使用相同的端口,通常会更简单)。
当你开始一个任务时,你必须给它集群规范,你还必须告诉它它的类型和索引是什么(例如,worker 0)。一次指定所有内容(集群规范和当前任务的类型和索引)的最简单方法是TF_CONFIG在启动 TensorFlow 之前设置环境变量。它必须是一个 JSON 编码的字典,包含集群规范(在"cluster"键下)以及当前任务的类型和索引(在"task"键下)。例如下面的TF_CONFIG环境变量使用我们刚刚定义的集群,并指定要启动的任务是第一个worker:
import os
import json
os.environ["TF_CONFIG"] = json.dumps({
"cluster": cluster_spec,
"task": {"type": "worker", "index": 0}
})小费
通常,您希望在
TF_CONFIGPython 之外定义环境变量,因此代码不需要包含当前任务的类型和索引(这使得在所有工作人员中使用相同的代码成为可能)。
现在让我们在集群上训练一个模型!我们将从镜像策略开始——它非常简单!首先,您需要TF_CONFIG为每个任务适当地设置环境变量。不应该有参数服务器(删除集群规范中的“ps”键),通常你会希望每台机器有一个工作人员。确保为每个任务设置不同的任务索引。最后,在每个 worker 上运行以下训练代码:
distribution = tf.distribute.experimental.MultiWorkerMirroredStrategy()
with distribution.scope():
mirrored_model = keras.models.Sequential([...])
mirrored_model.compile([...])
batch_size = 100 # must be divisible by the number of replicas
history = mirrored_model.fit(X_train, y_train, epochs=10)是的,这与我们之前使用的代码完全相同,只是这次我们使用的是MultiWorkerMirroredStrategy(在未来的版本中,MirroredStrategy可能会同时处理单机和多机情况)。当您在第一个工作人员上启动此脚本时,他们将在 AllReduce 步骤中保持阻塞,但是一旦最后一个工作人员启动,培训就会开始,您会看到他们都以完全相同的速度前进(因为它们在每个步)。
您可以从两种 AllReduce 实现中选择此分发策略:基于 gRPC 的环 AllReduce 算法用于网络通信,以及 NCCL 的实现。使用的最佳算法取决于工作人员的数量、GPU 的数量和类型以及网络。默认情况下,TensorFlow 会应用一些启发式方法来为您选择正确的算法,但如果您想强制使用一种算法,请将CollectiveCommunication.RINGor CollectiveCommunication.NCCL(from tf.distribute.experimental) 传递给策略的构造函数。
如果您更喜欢使用参数服务器实现异步数据并行,请将策略更改为ParameterServerStrategy,添加一个或多个参数服务器,并TF_CONFIG为每个任务进行适当的配置。请注意,虽然工作人员将异步工作,但每个工作人员上的副本将同步工作。
最后,如果您可以访问Google Cloud 上的 TPU,您可以创建一个TPUStrategy这样的(然后像其他策略一样使用它):
resolver = tf.distribute.cluster_resolver.TPUClusterResolver()
tf.tpu.experimental.initialize_tpu_system(resolver)
tpu_strategy = tf.distribute.experimental.TPUStrategy(resolver)小费
如果您是研究人员,您可能有资格免费使用 TPU;有关更多详细信息,请参阅https://tensorflow.org/tfrc。
您现在可以跨多个 GPU 和多个服务器训练模型:给自己点赞!如果你想训练一个大型模型,你将需要跨许多服务器的许多 GPU,这将需要购买大量硬件或管理大量云虚拟机。在许多情况下,使用云服务会在您需要时为您提供和管理所有这些基础设施,这样会更轻松、更便宜。让我们看看如何在 GCP 上做到这一点。
在 Google Cloud AI 平台上运行大型训练作业
如果您决定使用 Google AI Platform,您可以使用与在您自己的 TF 集群上运行的相同训练代码部署一个训练作业,该平台将负责预置和配置任意数量的 GPU 虚拟机(在您的配额)。
要开始这项工作,您需要gcloud命令行工具,它是Google Cloud SDK的一部分。您可以在自己的机器上安装 SDK,也可以在 GCP 上使用 Google Cloud Shell。这是您可以直接在网络浏览器中使用的终端;它在免费的 Linux VM (Debian) 上运行,已经为您安装和预配置了 SDK。Cloud Shell 在 GCP 中的任何地方都可用:只需单击页面右上角的激活 Cloud Shell 图标(见图 19-22)。
图 19-22。激活 Google Cloud Shell
如果你喜欢在你的机器上安装 SDK,一旦你安装了它,你需要通过运行来初始化它gcloud init:你需要登录到 GCP 并授予对 GCP 资源的访问权限,然后选择你要使用的 GCP 项目(如果您有多个),以及您希望作业运行的区域。该gcloud命令使您可以访问每个 GCP 功能,包括我们之前使用的功能。您不必每次都通过网络界面;您可以编写脚本来为您启动或停止虚拟机、部署模型或执行任何其他 GCP 操作。
在您可以运行训练作业之前,您需要编写训练代码,就像您之前为分布式设置所做的那样(例如,使用ParameterServerStrategy)。AI Platform 将为TF_CONFIG您在每个 VM 上进行设置。完成后,您可以使用如下命令行在 TF 集群上部署并运行它
$ gcloud ai-platform jobs submit training my_job_20190531_164700 \
--region asia-southeast1 \
--scale-tier PREMIUM_1 \
--runtime-version 2.0 \
--python-version 3.5 \
--package-path /my_project/src/trainer \
--module-name trainer.task \
--staging-bucket gs://my-staging-bucket \
--job-dir gs://my-mnist-model-bucket/trained_model \
--
--my-extra-argument1 foo --my-extra-argument2 bar让我们来看看这些选项。该命令将使用规模层my_job_20190531_164700在该地区启动一个名为 的培训作业:这对应于 20 个工作人员(包括一个主管)和 11 个参数服务器(查看其他可用的规模层)。所有这些 VM 都将基于 AI Platform 的 2.0 运行时(一种包括 TensorFlow 2.0 和许多其他包的 VM 配置)22和 Python 3.5。训练代码位于/my_project/src/trainer目录下,该命令会自动将其打包成一个 pip 包并上传到gs://my-staging-bucket 的GCS 。接下来,AI Platform 将启动几个 VM,将包部署到它们,然后运行asia-southeast1PREMIUM_1 gcloudtrainer.task模块。最后,--job-dir参数和额外参数(即位于--分隔符之后的所有参数)将被传递给训练程序:主要任务通常会使用--job-dir参数来找出在 GCS 上保存最终模型的位置,在这种情况下在gs://my-mnist-model-bucket/trained_model。就是这样!然后,您可以在 GCP 控制台中打开导航菜单,向下滚动到人工智能部分,然后打开 AI Platform → Jobs。您应该看到您的作业正在运行,如果单击它,您将看到显示每个任务的 CPU、GPU 和 RAM 利用率的图表。您可以单击查看日志以使用 Stackdriver 访问详细日志。
笔记
如果您将训练数据放在 GCS 上,您可以创建tf.data.TextLineDataset或tf.data.TFRecordDataset访问它:只需使用 GCS 路径作为文件名(例如gs://my-data-bucket/my_data_001.csv)。这些数据集依赖tf.io.gfile包来访问文件:它支持本地文件和 GCS 文件(但请确保您使用的服务帐户可以访问 GCS)。
如果您想探索一些超参数值,您可以简单地运行多个作业并使用任务的额外参数指定超参数值。但是,如果您想有效地探索许多超参数,最好使用 AI Platform 的超参数调整服务。
AI 平台上的黑盒超参数调优
AI Platform 提供强大的贝叶斯优化超参数调优服务,称为Google Vizier。23要使用它,您需要在创建作业时传递一个 YAML 配置文件(--config tuning.yaml)。例如,它可能看起来像这样:
trainingInput:
hyperparameters:
goal: MAXIMIZE
hyperparameterMetricTag: accuracy
maxTrials: 10
maxParallelTrials: 2
params:
- parameterName: n_layers
type: INTEGER
minValue: 10
maxValue: 100
scaleType: UNIT_LINEAR_SCALE
- parameterName: momentum
type: DOUBLE
minValue: 0.1
maxValue: 1.0
scaleType: UNIT_LOG_SCALE这告诉 AI Platform 我们要最大化名为 的指标"accuracy",该作业将运行最多 10 次试验(每个试验将运行我们的训练代码以从头开始训练模型),并且最多并行运行 2 次试验。我们希望它调整两个超参数:n_layers超参数(10 到 100 之间的整数)和momentum超参数(0.1 到 1.0 之间的浮点数)。该scaleType参数指定超参数值的先验:UNIT_LINEAR_SCALE表示平坦的先验(即没有先验偏好),而UNIT_LOG_SCALE表示我们有一个先验信念,即最优值更接近最大值(另一个可能的先验是UNIT_REVERSE_LOG_SCALE,当我们相信接近最小值的最佳值)。
n_layers和参数将momentum作为命令行参数传递给训练代码,当然它应该使用它们。问题是,训练代码如何将指标传达回 AI 平台,以便它可以决定在下一次试验期间使用哪些超参数值?好吧,AI Platform 只是监视输出目录(通过 指定),以查找包含名为(或任何指定为 的度量名称)的指标的摘要的--job-dir事件文件(在第 10 章中介绍),并读取这些值。因此,您的训练代码只需使用回调(无论如何您都希望使用回调进行监控),您就可以开始了!"accuracy"hyperparameterMetricTagTensorBoard()
作业完成后,每次试验中使用的所有超参数值和结果精度都将在作业的输出中可用(可通过 AI 平台 → 作业页面获得)。
笔记
AI Platform 作业还可用于在大量数据上高效地执行模型:每个工作人员都可以从 GCS 读取部分数据、进行预测并将其保存到 GCS。
现在,您拥有创建最先进的神经网络架构所需的所有工具和知识,并使用各种分布策略在您自己的基础架构或云上进行大规模训练——您甚至可以执行强大的贝叶斯优化以微调超参数!
练习
-
SavedModel 包含什么?你如何检查它的内容?
-
什么时候应该使用 TF Serving?它的主要特点是什么?您可以使用哪些工具来部署它?
-
如何跨多个 TF Serving 实例部署模型?
-
什么时候应该使用 gRPC API 而不是 REST API 来查询 TF Serving 提供的模型?
-
TFLite 减少模型大小以使其在移动或嵌入式设备上运行的不同方式有哪些?
-
什么是量化感知训练,为什么需要它?
-
什么是模型并行和数据并行?为什么一般推荐后者?
-
在多台服务器上训练模型时,可以使用哪些分布策略?你如何选择使用哪一种?
-
训练模型(您喜欢的任何模型)并将其部署到 TF Serving 或 Google Cloud AI Platform。编写客户端代码以使用 REST API 或 gRPC API 对其进行查询。更新模型并部署新版本。您的客户端代码现在将查询新版本。回滚到第一个版本。
-
MirroredStrategy使用(如果您无权访问 GPU,您可以将 Colaboratory 与 GPU Runtime 一起使用并创建两个虚拟 GPU)在同一台机器上跨多个 GPU 训练任何模型。使用 再次训练模型CentralStorageStrategy并比较训练时间。 -
使用黑盒超参数调优在 Google Cloud AI Platform 上训练一个小型模型。
谢谢你!
在我们结束本书的最后一章之前,我要感谢你阅读到最后一段。我真诚地希望您在阅读这本书时和我写这本书时一样愉快,并且它对您的项目(无论大小)都有用。
如果您发现错误,请发送反馈。更一般地说,我很想知道你的想法,所以请不要犹豫,通过 O'Reilly、ageron/handson-ml2 GitHub 项目或 Twitter 上的@aureliengeron 与我联系。
展望未来,我对您的最佳建议是练习和练习:尝试完成所有练习(如果您还没有这样做),使用 Jupyter 笔记本,加入 Kaggle.com 或其他一些 ML 社区,观看 ML 课程,阅读论文、参加会议并会见专家。无论是为了工作还是为了娱乐(理想情况下两者都适用),有一个具体的项目来进行工作也非常有帮助,所以如果有任何你一直梦想建造的东西,那就试一试吧!逐步工作;不要马上就登月,而是要专注于您的项目并逐步构建它。这需要耐心和毅力,但是当你有一个行走的机器人、一个工作的聊天机器人,或者你想建造的任何其他东西时,这将是巨大的回报。
我最大的希望是,这本书将激励您构建一个让我们所有人受益的精彩 ML 应用程序!会是什么?
——Aurélien Géron,2019 年 6 月 17 日
1A/B 实验包括在不同的用户子集上测试产品的两个不同版本,以检查哪个版本最有效并获得其他见解。
2REST(或 RESTful)API 是一种使用标准 HTTP 动词(例如 GET、POST、PUT 和 DELETE)并使用 JSON 输入和输出的 API。gRPC 协议更复杂但更高效。使用协议缓冲区交换数据(参见第 13 章)。
3如果您不熟悉 Docker,它可以让您轻松下载一组打包在Docker 映像中的应用程序(包括它们的所有依赖项,通常还有一些好的默认配置),然后使用Docker 引擎在您的系统上运行它们。当您运行映像时,引擎会创建一个Docker 容器,使应用程序与您自己的系统保持良好的隔离(但您可以根据需要为其提供一些有限的访问权限)。它类似于虚拟机,但速度更快、更轻量级,因为容器直接依赖于主机的内核。这意味着映像不需要包含或运行自己的内核。
4公平地说,这可以通过在创建 REST 请求之前先序列化数据并将其编码为 Base64 来缓解。此外,可以使用 gzip 压缩 REST 请求,从而显着减小负载大小。
5如果 SavedModel 在assets/extra目录中包含一些示例实例,您可以配置 TF Serving 以在这些实例上执行模型,然后再开始使用它来服务新请求。这称为模型预热:它将确保所有内容都正确加载,避免第一次请求的响应时间过长。
6在撰写本文时,TensorFlow 版本 2 尚未在 AI Platform 上可用,但没关系:您可以使用 1.13,它会很好地运行您的 TF 2 SavedModels。
7如果你得到一个错误说google.appengine没有找到模块,cache_discovery=False在方法的调用中设置build();请参阅python - ModuleNotFoundError: No module named 'google.appengine' - Stack Overflow。
8还可以查看 TensorFlow 的Graph Transform Tool来修改和优化计算图。
10请查看文档以获取详细和最新的安装说明,因为它们经常更改。
11本章中的许多代码示例都使用了实验性 API。它们很可能会在未来的版本中移至核心 API。因此,如果实验功能失败,请尝试简单地删除单词experimental,希望它会起作用。如果没有,那么 API 可能发生了一些变化;请检查 Jupyter 笔记本,因为我会确保它包含正确的代码。
12据推测,这些配额是为了阻止那些可能试图使用 GCP 和被盗信用卡来挖掘加密货币的坏人。
13Martín Abadi 等人,“TensorFlow:异构分布式系统上的大规模机器学习”谷歌研究白皮书(2015 年)。
14正如我们在第 12 章中看到的,内核是针对特定数据类型和设备类型的变量或操作的实现。例如,有一个 GPU 内核用于float32 tf.matmul()操作,但没有 GPU 内核用于int32 tf.matmul()(只有一个 CPU 内核)。
15您还可以使用tf.debugging.set_log_device_placement(True)记录所有设备放置。
16如果您想保证完美的再现性,这将很有用,正如我在此视频中解释的那样,基于 TF 1。
17在撰写本文时,它仅将数据预取到 CPU RAM,但您可以使用tf.data.experimental.prefetch_to_device()它使其预取数据并将其推送到您选择的设备,这样 GPU 就不会浪费时间等待数据传输.
18如果您有兴趣进一步了解模型并行性,请查看Mesh TensorFlow。
19这个名字有点令人困惑,因为听起来有些副本很特别,什么都不做。实际上,所有副本都是等价的:它们都努力在每个训练步骤中成为最快的,而失败者在每个步骤中都各不相同(除非某些设备真的比其他设备慢)。但是,这确实意味着如果服务器崩溃,训练将继续正常进行。
20陈建民等人,“重新审视分布式同步 SGD”,arXiv 预印本 arXiv:1604.00981 (2016)。
21有关 AllReduce 算法的更多详细信息,请阅读 Yuichiro Ueno 的这篇精彩文章,以及有关使用 NCCL 进行缩放的页面。
22在撰写本文时,2.0 运行时尚不可用,但在您阅读本文时它应该已准备就绪。查看可用运行时列表。
23Daniel Golovin 等人,“Google Vizier:黑盒优化服务” ,第 23 届 ACM SIGKDD 知识发现和数据挖掘国际会议论文集(2017 年):1487-1495。















 375
375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









