









🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
在第 2 章“ Transformer 模型架构入门”中,我们定义了原始 Transformer 架构的构建块。将最初的变形金刚想象成一个用 LEGO ®积木搭建的模型。构造集包含诸如编码器、解码器、嵌入层、位置编码方法、多头注意力层、掩码多头注意力层、后层归一化、前馈子层和线性输出层等砖块。
这些砖有各种尺寸和形式。您可以花费数小时使用相同的拼搭套件来拼搭各种模型!有些建筑只需要一些砖块。其他结构将添加一个新部件,就像我们为使用 LEGO ®组件构建的模型获得额外的积木一样。
BERT 在 Transformer 构建套件中添加了一个新部分:双向多头注意力子层。当我们人类在理解句子时遇到问题时,我们不会只看过去的单词。BERT 和我们一样,会同时查看同一个句子中的所有单词。
本章将首先探讨来自 Transformers ( BERT )的双向编码器表示的架构。BERT 仅以新颖的方式使用 Transformer 的编码器块,不使用解码器堆栈。
然后我们将微调一个预训练的 BERT 模型。我们将微调的 BERT 模型由第三方训练并上传到 Hugging Face。变形金刚可以进行预训练。然后,例如,预训练的 BERT 可以在多个 NLP 任务上进行微调。我们将通过 Hugging Face 模块来体验下游 Transformer 使用的迷人体验。
本章涵盖以下主题:
- 来自 Transformers (BERT) 的双向编码器表示
- BERT的架构
- 两步 BERT 框架
- 准备预训练环境
- 定义预训练编码器层
- 定义微调
- 下游多任务处理
- 构建微调的 BERT 模型
- 加载可接受性判断数据集
- 创建注意力掩码
- BERT模型配置
- 测量微调模型的性能
我们的第一步将是探索 BERT 模型的背景。
BERT的架构
BERT 引入了对 Transformer 模型的双向关注。双向关注需要许多其他对原始 Transformer 模型的更改。
我们不会详细介绍第 2 章“ Transformer 模型架构入门”中描述的 Transformer 构建块。您可以随时查阅第 2 章来回顾变压器构建块的某个方面。在本节中,我们将重点介绍 BERT 模型的具体方面。
我们将专注于Devlin等人设计的演变。(2018),它描述了编码器堆栈。我们将首先通过编码器堆栈,然后准备预训练输入环境。然后我们将描述 BERT 的两步框架:预训练和微调。
让我们首先探索编码器堆栈。
编码器堆栈
第一个积木我们将取自原始的 Transformer 模型是编码器层。编码器层,如第 2 章“ Transformer 模型架构入门”中所述,如图 3.1所示:
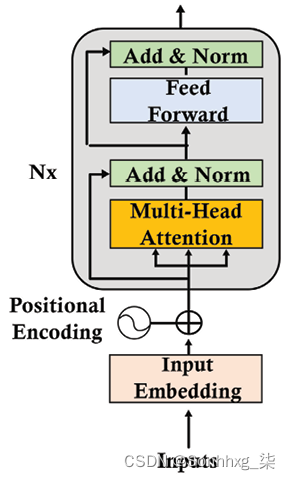
图 3.1:编码器层
BERT 模型不使用解码器层。BERT 模型有一个编码器堆栈,但没有解码器堆栈。掩码标记(隐藏要预测的标记)位于编码器的注意力层中,正如我们将在以下部分中放大 BERT 编码器层时看到的那样。
原始的 Transformer 包含一堆N = 6 层。原Transformer的维数为d model = 512。原Transformer的注意力头数为A =8。原变压器头部尺寸为:

BERT 编码器层大于原始的 Transformer 模型。
可以使用编码器层构建两个 BERT 模型:
- BERT BASE,其中包含N = 12 个编码器层的堆栈。d model = 768 也可以表示为H = 768,如 BERT 论文中所述。多头注意力子层包含A = 12 个头。维度每个头的z A仍然是 64,与原始 Transformer 模型一样:

- 连接前每个多头注意力子层的输出将是 12 个头的输出:
output_multi-head_attention={z 0 , z 1 , z 2 ,…, z 11 }
- BERT LARGE,其中包含N = 24 个编码器层的堆栈。d模型= 1024。一个多头注意力子层包含A = 16 个头。每个头部z A的维度也保持为 64,与原始 Transformer 模型一样:
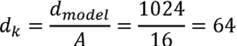
- 连接前每个多头注意力子层的输出将是 16 个头的输出:
output_multi-head_attention={z 0 , z 1 , z 2 ,…, z 15 }
模型的大小可以总结如下:

图 3.2:变压器模型
BERT 模型不限于这三种配置。这三种配置说明了 BERT 模型的主要方面。许多变化是可能的。
尺寸和尺寸在 BERT 式预训练中发挥重要作用。BERT 模型就像人类一样。BERT 模型通过更多的工作记忆(维度)和更多的知识(数据)产生更好的结果。学习大量数据的大型 Transformer 模型将为下游 NLP 任务进行更好的预训练。
让我们转到第一个子层,看看 BERT 模型中输入嵌入和位置编码的基本方面。
准备预训练输入环境
BERT 模型没有层的解码器堆栈。因此,它没有蒙面多头注意力子层。BERT 设计者表示,一个屏蔽了序列其余部分的多头注意力层会阻碍注意力过程。
带掩码的多头注意力层掩盖了当前之外的所有标记位置。例如,采取以下句子:
The cat sat on it because it was a nice rug.如果我们刚刚到达 word it,编码器的输入可能是:
The cat sat on it<masked sequence>这种方法的动机是防止模型看到它应该预测的输出。这种从左到右的方法产生了相对较好的结果。
但是,模型无法通过这种方式学到很多东西。要知道it指的是什么,我们需要查看整个句子以达到单词rug并弄清楚那it是地毯。
BERT 的作者提出了一个想法。为什么不预训练模型以使用不同的方法进行预测?
BERT 的作者提出了双向注意力,让注意力头关注从左到右和从右到左的所有单词。换句话说,编码器的自注意力掩码可以完成这项工作,而不会受到解码器的掩码多头注意力子层的阻碍。
该模型接受了两个任务的训练。第一种方法是掩蔽语言 建模( MLM )。第二种方法是下一句预测(NSP)。
让我们从掩码语言建模开始。
掩蔽语言建模
掩蔽语言建模不需要训练模型带有一系列可见单词,然后是要预测的掩码序列。
BERT 引入了对句子的一个词进行随机掩码的句子的双向分析。
值得注意的是,BERT 将WordPiece子词分割标记化方法应用于输入。它还使用学习的位置编码,而不是正弦余弦方法。
潜在的输入序列可能是:
The cat sat on it because it was a nice rug.模型到达单词后,解码器会屏蔽注意力序列it:
The cat sat on it <masked sequence>.但是 BERT 编码器屏蔽了一个随机标记来进行预测:
The cat sat on it [MASK] it was a nice rug.多注意子层现在可以看到整个序列,运行自注意过程,并预测掩码标记。
输入标记以一种棘手的方式被掩盖,以迫使模型训练更长时间,但使用三种方法产生更好的结果:
- 通过不在 10% 的数据集上屏蔽单个标记来使模型感到惊讶;例如:
The cat sat on it [because] it was a nice rug. - 通过在 10% 的数据集上用随机标记替换标记来给模型带来惊喜;例如:
The cat sat on it [often] it was a nice rug. [MASK]用80% 数据集上的标记替换标记;例如:The cat sat on it [MASK] it was a nice rug.
BERT 还被训练来执行下一句预测。
下一句预测
第二种训练 BERT 的方法是Next Sentence Prediction ( NSP )。输入包含两句话。在 50% 的情况下,第二sentence 是文档的实际第二个句子。在 50% 的情况下,第二句是随机选择的,与第一句无关。
添加了两个新令牌:
[CLS]是添加到第一个序列开头的二进制分类标记,用于预测第二个序列是否跟随第一个序列。正样本通常是从数据集中提取的一对连续句子。使用来自不同文档的序列创建负样本。[SEP]是表示序列结束的分隔标记。
The cat slept on the rug. It likes sleeping all day.这两个句子将成为一个完整的输入序列:
[CLS] the cat slept on the rug [SEP] it likes sleep ##ing all day[SEP]这种方法需要额外的编码信息来区分序列 A 和序列 B。
如果我们把整个嵌入过程放在一起,我们得到:
 图 3.3:输入嵌入
图 3.3:输入嵌入
输入嵌入是通过对标记嵌入、片段(句子、短语、单词)嵌入和位置编码嵌入求和来获得的。
BERT模型的输入嵌入和位置编码子层可以总结如下:
- 一系列单词被分解为
WordPiece标记。 - 一个
[MASK]标记将随机替换初始单词标记以进行掩码语言建模训练。 - 分类标记插入序列的
[CLS]开头以进行分类。 - 一个
[SEP]标记将两个句子(句段、短语)分开,用于 NSP 训练。 - 将句子嵌入添加到token嵌入中,使得句子 A 与句子 B 具有不同的句子嵌入值。
- 学习位置编码。没有应用原始 Transformer 的正余弦位置编码方法。
- BERT 在其多头注意力子层中使用双向注意力,打开了学习和理解令牌之间关系的广阔视野。
- BERT 引入了无监督嵌入场景,使用未标记文本预训练模型。无监督场景迫使模型在多头注意力学习过程中更加努力地思考。这使得 BERT 可以了解语言是如何构建的,并将这些知识应用于下游任务,而无需每次都进行预训练。
- BERT 还使用监督学习,涵盖预训练过程中的所有基础。
BERT 改善了训练环境的变压器。现在让我们看看预训练的动机以及它如何帮助微调过程。
预训练和微调 BERT 模型
BERT 是一个两步框架。第一步是预训练,第二个是微调,如图3.4所示:
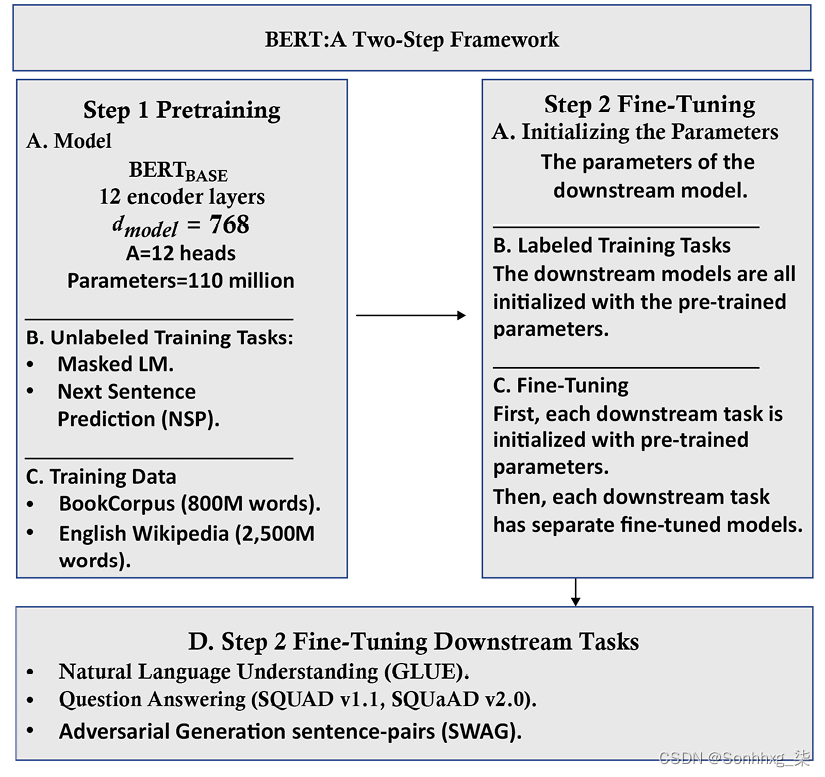 图 3.4:BERT 框架
图 3.4:BERT 框架
训练变压器模型可能需要数小时,甚至数天。这需要相当多的时间是时候设计架构和参数并选择合适的数据集来训练变压器模型了。
预训练是 BERT 框架的第一步,可以分为两个子步骤:
- 定义模型的架构:层数、头数、维度和模型的其他构建块
- 在MLM和NSP任务上训练模型
BERT 框架的第二步是微调,也可以分解为两个子步骤:
- 使用预训练的 BERT 模型的训练参数初始化选择的下游模型
- 微调参数对于特定的下游诸如识别文本蕴涵( RTE )、问题回答 (
SQuAD v1.1,SQuAD v2.0) 和对抗性生成情况( SWAG )等任务
在本节中,我们介绍了我们需要微调 BERT 模型的信息。在下面的章节,我们将更深入地探讨我们在本节中提出的主题:
- 在第 4 章,从头开始预训练 RoBERTa 模型,我们将通过 15 个步骤从头开始预训练类似 BERT 的模型。我们甚至会编译我们的数据,训练一个分词器,然后训练模型。本章旨在首先介绍 BERT 的具体构建模块,然后对现有模型进行微调。
- 在第 5 章,带有 Transformers 的下游 NLP 任务中,我们将完成许多下游任务,探索
GLUE、SQuAD v1.1、SQuAD、SWAG和其他几个 NLP 评估数据集。我们将运行几个下游 Transformer 模型来说明关键任务。本章的目标是微调下游模型。 - 在第 7 章,使用 GPT-3 引擎的超人变形金刚的崛起,将探讨 OpenAI
GPT-2和GPT-3变形金刚的架构和释放用途。BERT BASE被配置为接近 OpenAIGPT,以表明它产生了更好的性能。然而,OpenAI 转换器也在不断发展!我们将看到他们如何达到超人的 NLP 水平。
在本章中,BERT 模型我们将对语言可接受性语料库( CoLA ) 进行微调。下游任务基于Alex Warstadt、Amanpreet Singh和Samuel R. Bowman的神经网络可接受性判断。
我们将微调一个 BERT 模型,该模型将确定一个句子的语法可接受性。微调后的模型将获得一定程度的语言能力。
我们已经了解了 BERT 架构及其预训练和微调框架。现在让我们微调一个 BERT 模型。
微调 BERT
本节将微调 BERT模型来预测可接受性判断和测量的下游任务使用Matthews 相关系数( MCC )进行预测,这将在本章的使用 Matthews 相关系数部分进行解释。
在 Google Colab 中打开BERT_Fine_Tuning_Sentence_Classification_GPU.ipynb(确保您有一个电子邮件帐户)。笔记本位于Chapter03本书的 GitHub 存储库中。
笔记本中每个单元格的标题也与本章每个小节的标题相同或非常接近。
我们将首先研究为什么变压器模型必须考虑硬件约束。
硬件限制
变压器型号需要多处理硬件。转到Google Colab中的Runtime菜单,选择Change runtime type,然后在Hardware Accelerator下拉列表中选择GPU 。
变压器模型是硬件驱动的。在继续本章之前,我建议阅读附录 II,变压器模型的硬件约束。
该程序将使用Hugging Face我们接下来安装的模块。
为 BERT 安装 Hugging Face PyTorch 接口
拥抱脸提供预训练的 BERT 模型。拥抱脸开发一个名为 的基类PreTrainedModel。通过安装这个类,我们可以从预训练的模型配置中加载模型。
Hugging Face 在 TensorFlow 和 PyTorch 中提供模块。我建议开发人员对这两种环境都感到满意。优秀的 AI 研究团队使用其中一种或两种环境。
在本章中,我们将安装所需的模块,如下所示:
#@title Installing the Hugging Face PyTorch Interface for Bert
!pip install -q transformers我们现在可以导入程序所需的模块。
导入模块
我们将导入预训练的所需的模块,例如预训练BERT tokenizer和BERT模型的配置。优化器BERTAdam与序列分类模块一起导入:
#@title Importing the modules
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
from keras.preprocessing.sequence import pad_sequences
from sklearn.model_selection import train_test_split
from transformers import BertTokenizer, BertConfig
from transformers import AdamW, BertForSequenceClassification, get_linear_schedule_with_warmup一个不错的进度条模块是从以下位置导入的tqdm:
from tqdm import tqdm, trange我们现在可以导入广泛使用的标准 Python 模块:
import pandas as pd
import io
import numpy as np
import matplotlib.pyplot as plt
% matplotlib inline如果一切顺利,将不会显示任何消息,请记住 Google Colab已预装模块在我们正在使用的虚拟机上。
将 CUDA 指定为 torch 的设备
我们现在将指定火炬使用Compute Unified Device Architecture ( CUDA )将NVIDIA 卡的并行计算能力为我们的多头注意力模型工作:
#@title Harware verification and device attribution
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
!nvidia-smi输出可能因 Google Colab 配置而异。有关解释和屏幕截图,请参见附录 II:Transformer 模型的硬件约束。
我们现在将加载数据集。
加载数据集
我们现在将加载基于CoLA关于Warstadt等人。(2018)论文。
通用语言理解评估( GLUE ) 将语言可接受性视为重中之重NLP 任务。在第 5 章,带有 Transformer 的下游 NLP 任务中,我们将探讨 Transformer 必须执行的关键任务以证明其效率。
笔记本中的以下单元格会自动下载必要的文件:
import os
!curl -L https://raw.githubusercontent.com/Denis2054/Transformers-for-NLP-2nd-Edition/master/Chapter03/in_domain_train.tsv --output "in_domain_train.tsv"
!curl -L https://raw.githubusercontent.com/Denis2054/Transformers-fo您应该会看到它们出现在文件管理器中:

图 3.5:上传数据集
#@title Loading the Dataset
#source of dataset : https://nyu-mll.github.io/CoLA/
df = pd.read_csv("in_domain_train.tsv", delimiter='\t', header=None, names=['sentence_source', 'label', 'label_notes', 'sentence'])
df.shape输出显示我们导入的数据集的形状:
(8551, 4)显示一个 10 行示例以可视化可接受性判断任务并查看序列是否有意义:
df.sample(10)输出显示10标记数据集的行,每次运行后可能会发生变化:
| 句子源 | 标签 | 标签笔记 | 句子 | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
| | | | |
- 第一栏:句子的来源(代码)
- 第 2 列:标签(
0=不可接受,1=可接受) - 第三列:作者标注的标签
- 第四栏:待分类的句子
您可以在本地打开.tsv文件以阅读一些数据集的样本。该程序现在将处理BERT 模型的数据。
创建句子、标签列表和添加 BERT token
#@ Creating sentence, label lists and adding Bert tokens
sentences = df.sentence.values
# Adding CLS and SEP tokens at the beginning and end of each sentence for BERT
sentences = ["[CLS] " + sentence + " [SEP]" for sentence in sentences]
labels = df.label.values[CLS]和现在[SEP]已添加。
该程序现在激活标记器。
激活 BERT 分词器
在本节中,我们将初始化预训练的 BERT 分词器。这将节省从头开始训练它所需的时间。
程序选择一个不加大小写的分词器,激活它,并显示第一个分词句子:
#@title Activating the BERT Tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased', do_lower_case=True)
tokenized_texts = [tokenizer.tokenize(sent) for sent in sentences]
print ("Tokenize the first sentence:")
print (tokenized_texts[0])输出包含分类标记和序列分割标记:
Tokenize the first sentence:
['[CLS]', 'our', 'friends', 'wo', 'n', "'", 't', 'buy', 'this', 'analysis', ',', 'let', 'alone', 'the', 'next', 'one', 'we', 'propose', '.', '[SEP]']处理数据
我们需要确定固定的最大长度并处理数据为模型。数据集中的句子很短。但是,为了确保这一点,程序将序列的最大长度设置为128,并填充序列:
#@title Processing the data
# Set the maximum sequence length. The longest sequence in our training set is 47, but we'll leave room on the end anyway.
# In the original paper, the authors used a length of 512.
MAX_LEN = 128
# Use the BERT tokenizer to convert the tokens to their index numbers in the BERT vocabulary
input_ids = [tokenizer.convert_tokens_to_ids(x) for x in tokenized_texts]
# Pad our input tokens
input_ids = pad_sequences(input_ids, maxlen=MAX_LEN, dtype="long", truncating="post", padding="post")序列已被处理,现在程序创建了注意掩码。
创建注意力掩码
现在来了该过程的一个棘手部分。我们填充了序列在上一个单元格中。但是我们想阻止模型对那些填充的标记执行注意力!
这个想法是为每个标记应用一个值为 的掩码1,0 将跟随填充:
#@title Create attention masks
attention_masks = []
# Create a mask of 1s for each token followed by 0s for padding
for seq in input_ids:
seq_mask = [float(i>0) for i in seq]
attention_masks.append(seq_mask)将数据拆分为训练集和验证集
#@title Splitting data into train and validation sets
# Use train_test_split to split our data into train and validation sets for training
train_inputs, validation_inputs, train_labels, validation_labels = train_test_split(input_ids, labels, random_state=2018, test_size=0.1)
train_masks, validation_masks, _, _ = train_test_split(attention_masks, input_ids,random_state=2018, test_size=0.1)数据已准备好进行训练,但仍需要适应 Torch。
将所有数据转换为 Torch 张量
#@title Converting all the data into torch tensors
# Torch tensors are the required datatype for our model
train_inputs = torch.tensor(train_inputs)
validation_inputs = torch.tensor(validation_inputs)
train_labels = torch.tensor(train_labels)
validation_labels = torch.tensor(validation_labels)
train_masks = torch.tensor(train_masks)
validation_masks = torch.tensor(validation_masks)转换结束。现在我们需要创建一个迭代器。
选择批量大小并创建迭代器
在这个单元格中,程序选择批量大小并创建一个迭代器。迭代器是一种避免将所有数据加载到内存中的循环的巧妙方法。迭代器与 torch 相结合DataLoader,可以批量训练海量数据集,而不会导致机器内存崩溃。
在此模型中,批量大小为32:
#@title Selecting a Batch Size and Creating and Iterator
# Select a batch size for training. For fine-tuning BERT on a specific task, the authors recommend a batch size of 16 or 32
batch_size = 32
# Create an iterator of our data with torch DataLoader. This helps save on memory during training because, unlike a for loop,
# with an iterator the entire dataset does not need to be loaded into memory
train_data = TensorDataset(train_inputs, train_masks, train_labels)
train_sampler = RandomSampler(train_data)
train_dataloader = DataLoader(train_data, sampler=train_sampler, batch_size=batch_size)
validation_data = TensorDataset(validation_inputs, validation_masks, validation_labels)
validation_sampler = SequentialSampler(validation_data)
validation_dataloader = DataLoader(validation_data, sampler=validation_sampler, batch_size=batch_size)数据已处理完毕,一切就绪。该程序现在可以加载和配置 BERT 模型。
BERT模型配置
#@title BERT Model Configuration
# Initializing a BERT bert-base-uncased style configuration
#@title Transformer Installation
try:
import transformers
except:
print("Installing transformers")
!pip -qq install transformers
from transformers import BertModel, BertConfig
configuration = BertConfig()
# Initializing a model from the bert-base-uncased style configuration
model = BertModel(configuration)
# Accessing the model configuration
configuration = model.config
print(configuration)BertConfig {
"attention_probs_dropout_prob": 0.1,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"type_vocab_size": 2,
"vocab_size": 30522
}让我们来看看这些主要参数:
attention_probs_dropout_prob:0.1将0.1dropout 比率应用于注意力概率。hidden_act:"gelu"是编码器中的非线性激活函数。它是一个高斯误差线性单元激活函数。输入按其大小加权,这使其成为非线性的。hidden_dropout_prob:0.1是应用于全连接层的辍学概率。完全连接可以在嵌入、编码器和池化层中找到。输出并不总是能很好地反映序列的内容。对隐藏状态序列进行池化改进了输出序列。hidden_size:768是编码层的维度,也是池化层的维度。initializer_range:0.02是初始化权重矩阵时的标准偏差值。intermediate_size:3072是编码器前馈层的维度。layer_norm_eps:1e-12是层归一化层的 epsilon 值。max_position_embeddings:512是模型使用的最大长度。model_type:"bert"是模型的名称。num_attention_heads:12是头数。num_hidden_layers:12是层数。pad_token_id:0是填充令牌的 ID,以避免训练填充令牌。type_vocab_size:2是 的大小token_type_ids,用于识别序列。例如,“dog[SEP]The Thecat.[SEP]”可以用令牌 ID 表示[0,0,0, 1,1,1]。vocab_size:30522是模型用来表示的不同标记的数量input_ids。
加载 Hugging Face BERT 无壳基础模型
#@title Loading the Hugging Face Bert uncased base model
model = BertForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
model = nn.DataParallel(model)
model.to(device)我们已经定义了模型,定义了并行处理,并将模型发送到设备。有关详细说明,请参阅附录 II,Transformer 模型的硬件约束。
如果需要,可以进一步训练这个预训练模型。详细探索架构以可视化参数是很有趣的每个子层的,如图在以下摘录中:
BertForSequenceClassification(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(30522, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(1): BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): BertLayerNorm()
(dropout): Dropout(p=0.1, inplace=False)
)
)优化器分组参数
程序现在将初始化模型参数的优化器。微调模型从初始化预训练的模型参数值(不是它们的名称)。
优化器的参数包括一个权重衰减率以避免过拟合,并且过滤了一些参数。
目标是为训练循环准备模型参数:
##@title Optimizer Grouped Parameters
#This code is taken from:
# https://github.com/huggingface/transformers/blob/5bfcd0485ece086ebcbed2d008813037968a9e58/examples/run_glue.py#L102
# Don't apply weight decay to any parameters whose names include these tokens.
# (Here, the BERT doesn't have 'gamma' or 'beta' parameters, only 'bias' terms)
param_optimizer = list(model.named_parameters())
no_decay = ['bias', 'LayerNorm.weight']
# Separate the 'weight' parameters from the 'bias' parameters.
# - For the 'weight' parameters, this specifies a 'weight_decay_rate' of 0.01.
# - For the 'bias' parameters, the 'weight_decay_rate' is 0.0.
optimizer_grouped_parameters = [
# Filter for all parameters which *don't* include 'bias', 'gamma', 'beta'.
{'params': [p for n, p in param_optimizer if not any(nd in n for nd in no_decay)],
'weight_decay_rate': 0.1},
# Filter for parameters which *do* include those.
{'params': [p for n, p in param_optimizer if any(nd in n for nd in no_decay)],
'weight_decay_rate': 0.0}
]
# Note - 'optimizer_grouped_parameters' only includes the parameter values, not the names.训练循环的超参数
超参数s 用于训练循环虽然很关键他们似乎无害。例如,亚当将激活体重衰减并经历一个热身阶段。
学习率 ( lr) 和预热率 ( warmup) 应该在优化阶段的早期设置为非常小的值,并在一定次数的迭代后逐渐增加。这避免了大梯度和超出优化目标。
一些研究人员认为,层归一化之前子层输出层的梯度不需要热身率。解决这个问题需要很多实验运行。
优化器是 Adam 的 BERT 版本,称为BertAdam:
#@title The Hyperparameters for the Training Loop
optimizer = BertAdam(optimizer_grouped_parameters,
lr=2e-5,
warmup=.1)该程序添加了一个准确度测量功能来将预测与标签进行比较:
#Creating the Accuracy Measurement Function
# Function to calculate the accuracy of our predictions vs labels
def flat_accuracy(preds, labels):
pred_flat = np.argmax(preds, axis=1).flatten()
labels_flat = labels.flatten()
return np.sum(pred_flat == labels_flat) / len(labels_flat)数据准备好了。参数准备好了。是时候激活训练循环了!
训练循环
训练循环遵循标准的学习过程。时期数设置为4, 和测量将绘制损失和准确性。训练循环使用dataloader加载和训练批次。对培训过程进行测量和评估。
代码首先初始化train_loss_set,它将存储损失和准确性,并将被绘制。它开始训练其时期并运行标准训练循环,如以下摘录所示:
#@title The Training Loop
t = []
# Store our loss and accuracy for plotting
train_loss_set = []
# Number of training epochs (authors recommend between 2 and 4)
epochs = 4
# trange is a tqdm wrapper around the normal python range
for _ in trange(epochs, desc="Epoch"):
…./…
tmp_eval_accuracy = flat_accuracy(logits, label_ids)
eval_accuracy += tmp_eval_accuracy
nb_eval_steps += 1
print("Validation Accuracy: {}".format(eval_accuracy/nb_eval_steps))输出显示每个epoch带有trange包装器的信息,for _ in trange(epochs, desc="Epoch"):
***output***
Epoch: 0%| | 0/4 [00:00<?, ?it/s]
Train loss: 0.5381132976395461
Epoch: 25%|██▌ | 1/4 [07:54<23:43, 474.47s/it]
Validation Accuracy: 0.788966049382716
Train loss: 0.315329696132929
Epoch: 50%|█████ | 2/4 [15:49<15:49, 474.55s/it]
Validation Accuracy: 0.836033950617284
Train loss: 0.1474070605354314
Epoch: 75%|███████▌ | 3/4 [23:43<07:54, 474.53s/it]
Validation Accuracy: 0.814429012345679
Train loss: 0.07655430570461196
Epoch: 100%|██████████| 4/4 [31:38<00:00, 474.58s/it]
Validation Accuracy: 0.810570987654321Transformer 模型的发展非常迅速,可能会出现弃用消息甚至错误。拥抱的脸也不例外,我们必须更新当这种情况发生时,我们的代码会相应地。
模型经过训练。我们现在可以显示训练评估。
训练评估
损失和准确度值train_loss_set按定义存储在在训练循环的开始。
该程序现在绘制测量值:
#@title Training Evaluation
plt.figure(figsize=(15,8))
plt.title("Training loss")
plt.xlabel("Batch")
plt.ylabel("Loss")
plt.plot(train_loss_set)
plt.show()输出是一个图表,显示训练过程进展顺利且高效:
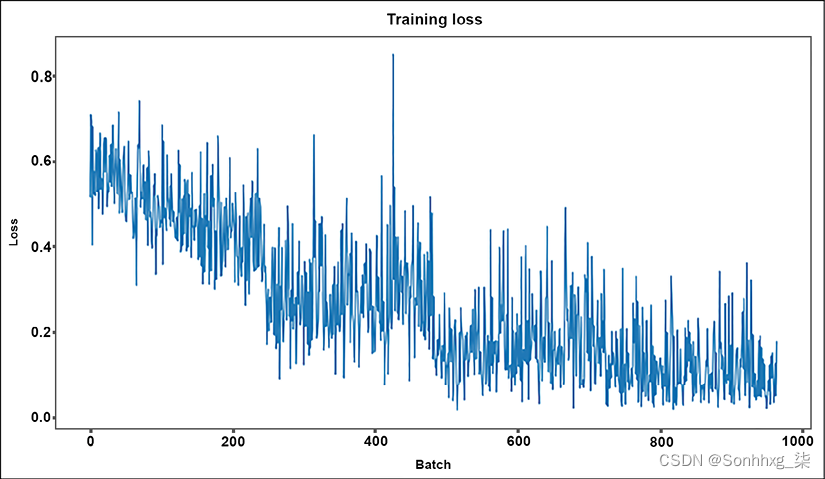 图 3.6:每批次的训练损失
图 3.6:每批次的训练损失
使用holdout数据集进行预测和评估
下游的 BERT模型是用数据集训练的in_domain_train.tsv。该程序现在将进行预测使用out_of_domain_dev.tsv文件中的保留(测试)数据集。目标是预测句子在语法上是否正确。
以下代码摘录显示了应用于训练数据的数据准备过程在保留数据集的代码部分中重复:
#@title Predicting and Evaluating Using the Holdout Dataset
df = pd.read_csv("out_of_domain_dev.tsv", delimiter='\t', header=None, names=['sentence_source', 'label', 'label_notes', 'sentence'])
# Create sentence and label lists
sentences = df.sentence.values
# We need to add special tokens at the beginning and end of each sentence for BERT to work properly
sentences = ["[CLS] " + sentence + " [SEP]" for sentence in sentences]
labels = df.label.values
tokenized_texts = [tokenizer.tokenize(sent) for sent in sentences]
.../...然后程序使用以下命令运行批量预测dataloader:
# Predict
for batch in prediction_dataloader:
# Add batch to GPU
batch = tuple(t.to(device) for t in batch)
# Unpack the inputs from our dataloader
b_input_ids, b_input_mask, b_labels = batch
# Telling the model not to compute or store gradients, saving memory and speeding up prediction
with torch.no_grad():
# Forward pass, calculate logit predictions
logits = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask)
预测的 logits 和标签被移动到 CPU:
# Move logits and labels to CPU
logits = logits['logits'].detach().cpu().numpy()
label_ids = b_labels.to('cpu').numpy()存储预测及其真实标签:
# Store predictions and true labels
predictions.append(logits)
true_labels.append(label_ids)使用 Matthews 相关系数进行评估
马修斯相关系数( MCC ) 最初设计用于衡量二元分类的质量并且可以修改为多类相关系数。一个二等可以在每个预测中使用四个概率进行分类:
- TP = True Positive
- TN = True Negative
- FP = False Positive
- FN = False Negative
生物化学家Brian W. Matthews于 1975 年设计了它,灵感来自他的前辈的phi函数。从那时起,它已经演变成各种格式,例如以下一种:
![]()
MCC 产生的值介于-1和之间+1。+1是预测的最大正值。-1是逆预测。0是平均随机预测。
GLUE使用 MCC评估语言可接受性。
MCC 导入自sklearn.metrics:
#@title Evaluating Using Matthew's Correlation Coefficient
# Import and evaluate each test batch using Matthew's correlation coefficient
from sklearn.metrics import matthews_corrcoef创建了一组预测:
matthews_set = []MCC 值计算并存储在matthews_set:
for i in range(len(true_labels)):
matthews = matthews_corrcoef(true_labels[i],
np.argmax(predictions[i], axis=1).flatten())
matthews_set.append(matthews)由于库和模块版本更改,您可能会看到消息。最终分数将基于整个测试集,但让我们看一下分数在各个批次上以了解可变性在批次之间的度量中。
各批次分数
#@title Score of Individual Batches
matthews_set输出产生介于预期-1之间的 MCC 值:+1
[0.049286405809014416,
-0.2548235957188128,
0.4732058754737091,
0.30508307783296046,
0.3567530340063379,
0.8050112948805689,
0.23329882422520506,
0.47519096331149147,
0.4364357804719848,
0.4700159919404217,
0.7679476477883045,
0.8320502943378436,
0.5807564950208268,
0.5897435897435898,
0.38461538461538464,
0.5716350506349809,
0.0]几乎所有的 MCC 值都是正数,这是个好消息。让我们看看对整个数据集的评估是什么。
整个数据集的 Matthews 评估
该程序现在将聚合整个数据集的真实值:
#@title Matthew's Evaluation on the Whole Dataset
# Flatten the predictions and true values for aggregate Matthew's evaluation on the whole dataset
flat_predictions = [item for sublist in predictions for item in sublist]
flat_predictions = np.argmax(flat_predictions, axis=1).flatten()
flat_true_labels = [item for sublist in true_labels for item in sublist]
matthews_corrcoef(flat_true_labels, flat_predictions)MCC 产生 和 之间的相关–1值+1。0是平均预测,-1是逆预测,并且1是完美的。在这种情况下,输出确认 MCC 为正,这表明该模型与数据集之间存在相关性:
0.45439842471680725在这次对 BERT 模型微调的最终正面评价上,我们对 BERT 训练框架有了一个整体的认识。
概括
BERT 为变压器带来了双向关注。从左到右预测序列并掩盖未来的标记来训练模型具有严重的局限性。如果掩码序列包含我们正在寻找的含义,则模型会产生错误。BERT 同时处理一个序列的所有标记。
我们探索了 BERT 的架构,它只使用了转换器的编码器堆栈。BERT 被设计为一个两步框架。框架的第一步是预训练模型。第二步是微调模型。我们为可接受性判断下游任务构建了一个微调 BERT 模型。微调过程经历了该过程的所有阶段。首先,我们加载数据集并加载模型必要的预训练模块。然后对模型进行训练,并测量其性能。
与从头开始训练下游任务相比,微调预训练模型所需的机器资源更少。微调模型可以执行各种任务。BERT 证明我们可以只在两个任务上预训练模型,这本身就很了不起。但是基于 BERT 预训练模型的训练参数生成多任务微调模型是非同寻常的。
第 7 章,使用 GPT-3 引擎的超人变形金刚的崛起,表明 OpenAI 已经达到了零样本水平,几乎没有微调。
在本章中,我们微调了一个 BERT 模型。在下一章第 4章,从头开始预训练 RoBERTa 模型,我们将更深入地研究 BERT 框架,并从头开始构建一个预训练的类 BERT 模型。

















 3799
3799











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











