







🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
图数据库在过去几年中得到了越来越多的关注。从图形构建的数据模型结合了面向文档的数据库的简单性和 SQL 表的清晰性。其中,Neo4j 是一个带有大型生态系统的数据库,包括数据库,还有构建 Web 应用程序的工具,例如 GRANDstack,以及在机器学习管道中使用图形数据的工具,以及图形数据科学图书馆。本书将讨论这些工具,但让我们先从头开始。
谈论图数据库意味着谈论图。即使您不需要了解有关图论的所有细节,但了解您正在使用的工具的一些基本概念始终是一个好主意。在本章中,我们将从定义图开始,并给出一些简单和不太简单的图及其应用示例。然后,我们将了解如何从众所周知的 SQL 表转移到图形数据建模。最后,我们将介绍 Neo4j 及其构建块,并回顾一些设计原则以了解 Neo4j 可以做什么和不可以做什么。
本章将涵盖以下主题:
- 图形定义和示例
- 从 SQL 迁移到图形数据库
- Neo4j:节点、关系和属性模型
- 了解图形属性
- Neo4j 中图形建模的注意事项
图形定义和示例
此时您可能会问的问题是“我为什么要关心图表?毕竟,我的公司/业务/兴趣与任何类型的图表或网络无关。我知道我的数据模型,可以很好地安排在 SQL 表或 NoSQL 文档中,我可以随时检索我想要的信息。” 本书将教你如何以不同的方式看待数据来增强数据的能力。令人惊讶的是,图表可用于对许多过程进行建模,从更明显的过程(如道路网络)到不太直观的用例(如视频游戏或信用卡欺诈检测等)。
图论
让我们从头开始 ,回答“什么是图?”这个问题。
一点历史:柯尼斯堡的 S 偶数桥问题
图形研究起源于生活在 18 世纪的多产瑞士数学家莱昂哈德·欧拉 (Leonhard Euler)。1735 年,他发表了一篇论文,提出了解决柯尼斯堡七桥问题的方案。问题如下:
给定下图所描绘的城市,有没有一种方法可以一次且只穿过城市的七座桥中的每座桥,然后返回我们的起点?
如您所见,这座城市被一条河流穿过,这条河流将城市分成两岸,A和B。河流蜿蜒另外创造了两个岛屿,C和D,也是城市的一部分。这两个岸和两个岛共由七座桥连接:A和C之间的两座桥,C和B之间的另外两座桥, C和D之间的一座,B和D之间的一座,以及D和A之间的最后一座:
Euler 的推理(在右侧)是将 这个复杂的地理简化 为最 简单的绘图,就像您在上 一张图片右侧看到的那样, 因为每个岛屿内使用的路线是不相关的。 然后 每个岛变成一个点 或节点, 通过一个或多个链接 或边连接到另一个, 代表桥梁。
通过这个简单的可视化,数学家能够通过注意到,如果您通过一座桥到达一个岛(顶点),您将需要使用另一座桥离开它(起点和终点除外),从而解决了最初的问题。换句话说,除了两个之外的所有顶点都需要连接到偶数个关系。柯尼斯堡图中的情况并非如此,因为我们有以下内容:
A:3 个连接(到 C 两次,到 D 一次)
B:3 个连接(到 C 两次,到 D 一次)
C:5 个连接(到 A 两次,到 B 两次,到 D 一次)
D:3 个连接( A 一次,C 一次,D 一次)
这种每条边只使用一次的路径称为欧拉环,可以说一个图具有欧拉环当且仅当它的所有顶点都具有偶数度数。
图定义
这将我们引向图的数学定义:
图G = (V, E)是一对:
- V,一组节点或顶点:我们前面例子中的岛屿
- E,一组边连接节点:桥
上图右侧所示的柯尼斯堡图 可以定义如下:
V = [A, B, C, D]
E = [
(A, C),
(A, C),
(C, B),
(C, B),
(A, D),
(C, D),
(B, D)
]像许多数学对象一样,图形是定义良好的。虽然很难为其中一些对象找到良好的可视化效果,但另一方面,图形的绘制方式几乎是无限的。
可视化
除了非常特殊的情况外,没有一种方法可以绘制图形并将其可视化。事实上,图表通常是现实的抽象表示。例如,下图中描绘的所有四个图都表示完全相同的节点和边集,因此,根据定义,相同的数学图:
我们不能仅仅依靠我们的眼睛在图表中找到模式。例如,仅查看右下图,不可能看到右上图中可见的模式。这就是图算法进入游戏的地方,这将在第 6 章,节点重要性和第 7 章,社区检测和相似性度量中进行更详细的讨论。
图表示例
现在我们对图是什么有了更好的了解,是时候发现更多示例来了解图可以用于哪些用途。
网络
考虑到图定义(一组通过边相互连接的节点)和上一节中的桥示例,我们可以很容易地想象各种网络 如何被视为 图,包括道路网络、计算机网络或甚至社交网络。
道路网络
道路网络是图的完美示例。 在这样的网络中,节点是道路交叉口,边是道路本身,如下图所示: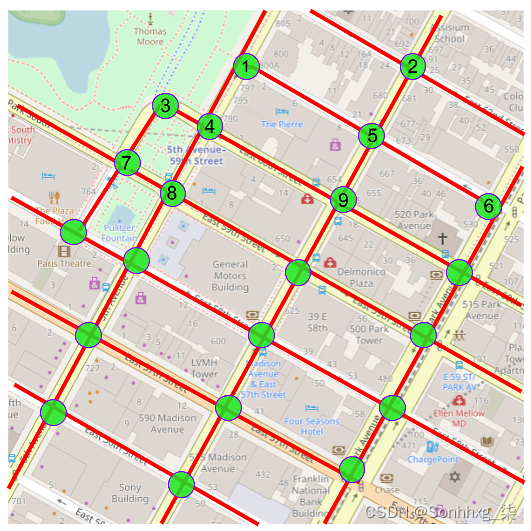
这张图片显示了纽约市中央公园周围的道路网络,其中街道是代表节点的交叉点之间的边缘
使用道路网络,可以通过图分析来回答许多问题,例如:
- 两点(节点)之间的最短路径是什么?
- 这条最短路径有多长?
- 有替代路线吗?
- 如何在最短的时间内访问列表中的所有节点?
最后一个问题对于包裹递送尤为重要,以便最大限度地减少行驶里程数以最大限度地提高递送包裹的数量和满意的客户。
我们将在第 4 章“图形数据科学库和路径查找”中更详细地介绍这个主题。
计算机网络
在计算机网络中,每台计算机/路由器都是一个节点,它们之间的电缆是边缘。下图说明了用于计算机网络的一些可能的拓扑(来源:https ://commons.wikimedia.org/wiki/File:NetworkTopologies.svg ):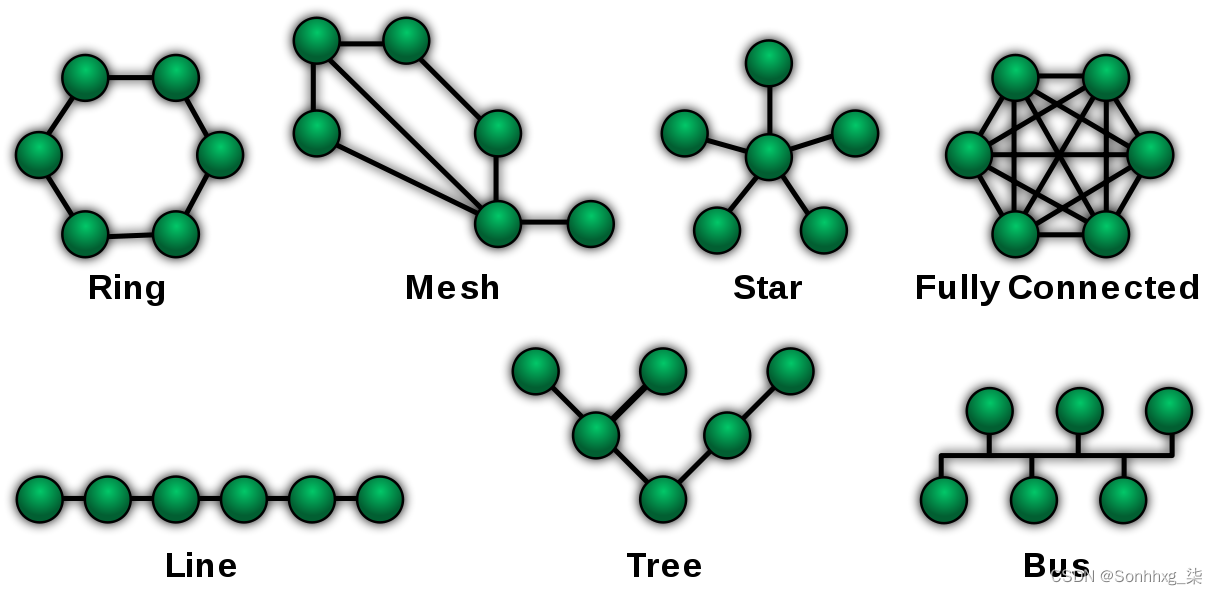
您现在可以绘制与我们在上一节中发现的图形定义的平行线。同样,图结构有助于回答您可能会问自己的有关网络的一些常见问题:
- 这些信息从 A 传输到 B 的速度有多快?这听起来像是一个最短路径问题。
- 我的哪个节点是最关键的?关键是指如果这个节点由于某种原因不能工作,整个网络都会受到影响。并非所有节点对网络都有相同的影响。这就是中心性算法发挥作用的地方(参见第 6 章,节点重要性)。
社交网络
Facebook、LinkedIn 和所有我们最喜欢的社交网络都使用图表来建模他们的用户和交互。在社交图的最基本示例中,节点代表人,边缘代表他们之间的友谊或职业关系,如下图所示: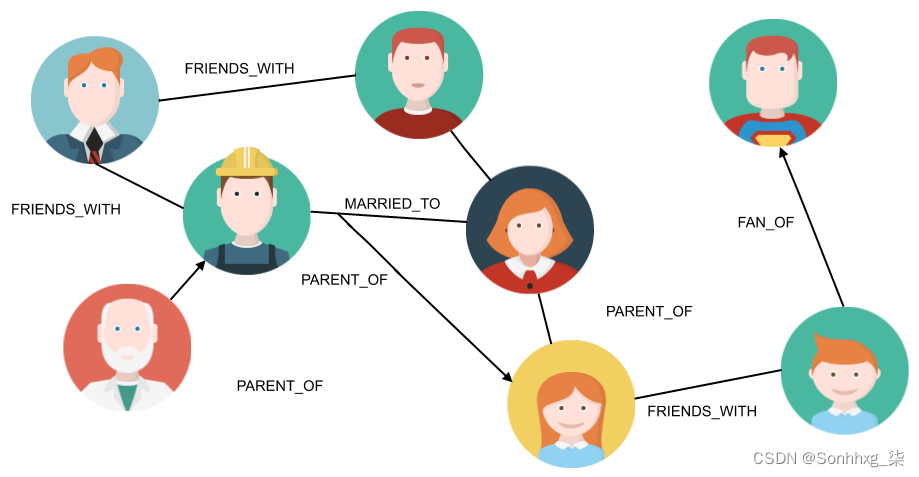
再次,图表使我们能够从不同的角度查看数据。例如,我们在 LinkedIn 上查看某人的个人资料时看到了此类信息: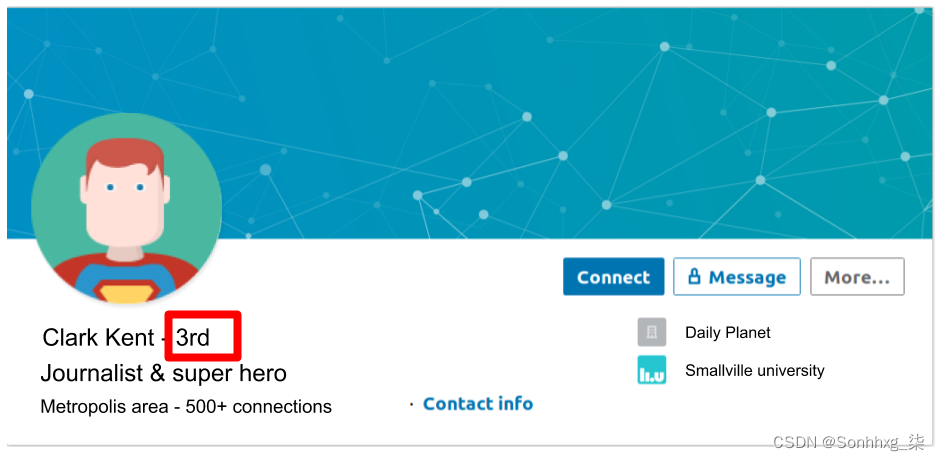
在这种情况下,它告诉我们连接的用户(我) 距离 Clark Kent 只有两个连接。换句话说,我网络中的一个人已经连接到一个连接到克拉克肯特的人。 下图在分离度方面更清楚地说明了这一点: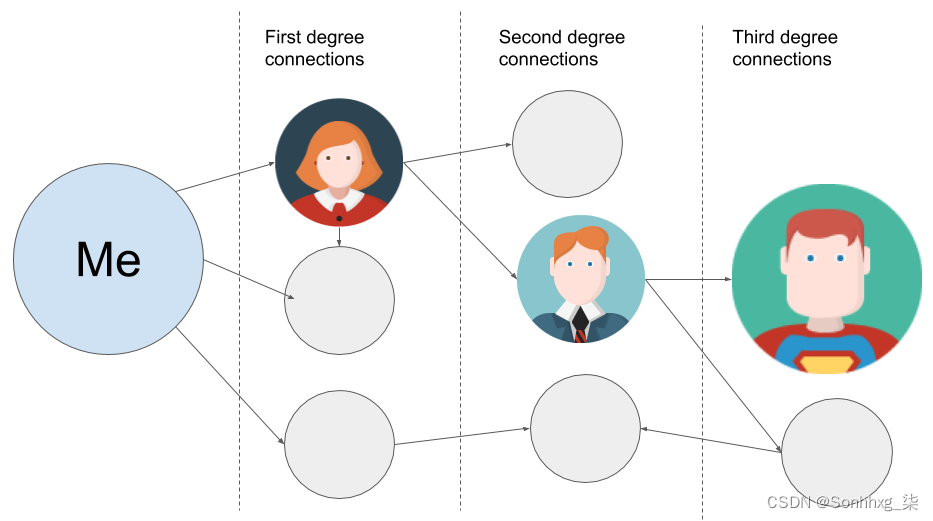
您可能听说过六度分离理论。1929 年,匈牙利记者 Frigyes Karinthy 提出了一个理论,根据该理论,地球上的每个人与任何其他人最多有六个连接。换句话说,如果你想和一个人交谈,比如说巴拉克奥巴马,你的一个朋友有一个朋友,他的朋友有一个朋友……他认识巴拉克奥巴马,可以把你介绍给他。根据 Karinthy 的说法,这个连接链必须包含少于 6 个连接,或者总共 7 个人,包括你和 Barack Obama。
鉴于地球上有超过 70 亿人,这是一个惊人的小数字!借助当今可用的大型数据库,例如来自 Facebook 的友谊连接或来自微软的电子邮件交换,研究人员试图证明上述说法。例如,从 Microsoft 电子邮件数据库中,2008 年的数据显示,1800 亿不同的人之间的平均分离度约为 6.6。但这只是一个平均值,使用该数据集连接两个人的跳数可能高达 29。
许多其他类型的分析可以在社交图上执行:
- 节点重要性:同样,了解哪些节点(人)最重要可能非常有用。然而,这里对重要性的定义将不同于计算机网络的情况,因为一个人从社交媒体上退休不太可能导致整个世界崩溃。但是,影响者对营销专家特别感兴趣。
- 社区检测:也称为集群,是一种找到一组具有某些特征的节点的方法。例如,找到具有相同兴趣或访问相同地点的用户,可用于向他们推荐产品。
- 链接预测:使用图,您可以考虑创建智能模型来预测两个实体将来是否可能连接。同样,推荐引擎是这种工具的一种可能应用。
如您所见,各种网络都非常适合图形数据库。但我们可以 远远 超越这种观点,将各种数据想象成一张图,这将开辟很多新的视角。
你的数据也是一个图表
您可能已经注意到,在上一张社交图的图像中,边有名称。确实,有些人是朋友,有些人是父子关系。现在,让我们想象一下我们可以有任何类型的关系,这意味着我们可以开始连接不同类型的实体。例如,一个人生活在一个特定的国家,所以他与那个国家有一个 type 的关系LIVES_IN。你开始明白重点了吗?有了这种推理,世界本身就是一个图表,您的业务是它的一部分。
图表是关于关系的,世界 是相连的,这意味着到处都有关系。 我们将在第 3 章中更详细地讨论这一点,使用Pure Cypher 为您的业务赋能,该章专门用于知识图谱。
图形数据库允许您以这种方式对数据建模:节点,通过某种类型的关系连接。让我们看看如何将存储在关系数据库中的数据迁移到图形数据库中。
从 SQL 迁移到图形数据库
在详细介绍 Neo4j 之前,我们先来看看现有的数据库模型。然后,我们将关注最著名的关系模型,并学习如何从 SQL 迁移到图形数据库模型。
数据库模型
想想水:根据最终目标,您不会使用同一个容器。如果你想喝,你可能会用一杯水,但如果你想洗澡,你可能会选择另一个。容器的选择在每种情况下都会有所不同。数据也有类似的问题:没有合适的容器,我们就无能为力,我们需要一个合适的容器,这不仅可以存储数据,还可以帮助解决我们遇到的问题。这个数据容器就是数据库。
在市场上绘制一份详尽的数据库类型列表并非不可能,但将远远超出本书的范围。但是,我想举一些最流行的例子,这样你就可以看到图数据库在大图中的位置:
- 关系数据库:它们是迄今为止最著名的数据库类型。从SQLite到MySQL或PostgreSQL,它们使用一种通用的查询语言,称为结构化查询语言( SQL ),在不同的实现中有一些变化。它们已经很好地建立并允许数据的清晰结构。但是,当数据增长时,它们会遇到性能问题,并且令人惊讶地不擅长管理复杂的关系,因为这些关系需要表之间的许多连接。
- 面向文档的数据库:面向文档的数据库是 NoSQL(不仅仅是 SQL)时代的一部分,在过去几年中引起了越来越多的关注。与关系数据库相反,它们可以管理灵活的数据模型,并且以更好地扩展大量数据而闻名。NoSQL 数据库的示例包括MongoDB和Cassandra,但您可以在市场上找到更多。
- 键值存储:Redis、RocksDB和Amazon DynamoDB是键值数据库的示例。它们非常简单且速度非常快,但不太适合存储复杂数据。
以下是如何以图形表示方式查看不同的数据库: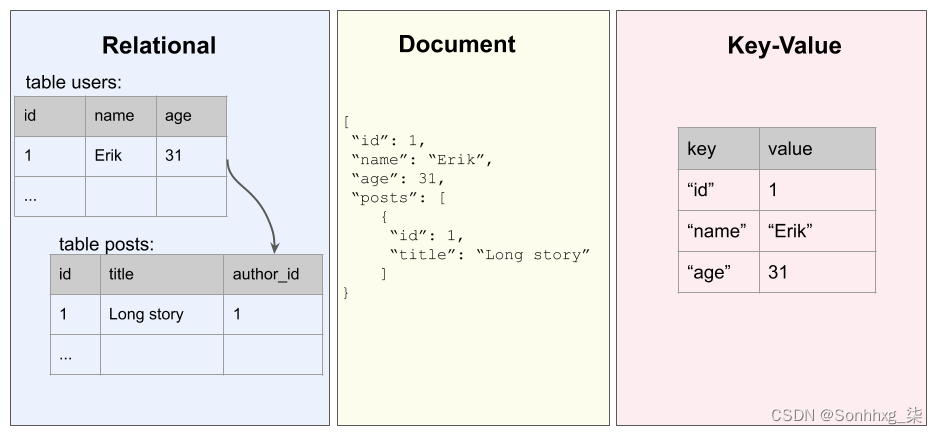
图形数据库试图通过简单易用、灵活且在关系方面非常高效,将每个世界的精华集中到一个地方。
SQL 和连接
让我们简要地关注关系数据库。想象一下,我们想要创建一个问答网站(类似于无价的 Stack Overflow)。要求如下:
- 用户应该能够登录。
- 登录后,用户可以发布问题。
- 用户可以发布现有问题的答案。
- 问题需要有标签以更好地识别哪个问题与哪个用户相关。
作为习惯于 SQL 的开发人员或数据科学家,我们自然会开始考虑表。我应该创建哪个表来存储这些数据?好吧,首先我们将寻找似乎是业务核心的实体。在这个 QA 网站中,我们可以识别以下内容:
- 用户,具有属性:ID、姓名、电子邮件、密码
- 问题:ID、标题、文本
- 答案:ID、文字
- 标签: ID, 文本
有了这些实体,我们现在需要创建它们之间的关系。为此,我们可以使用外键。例如,给定用户已提出问题,因此我们可以向表中添加一个新列question,author_id引用该user表。这同样适用于答案:它们是由给定用户编写的,因此我们在表中添加一author_id列Answer: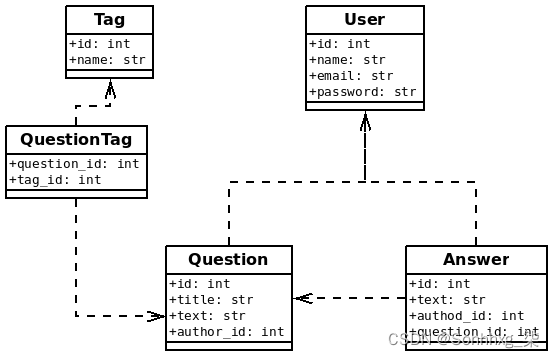
标签变得更加复杂,因为一个问题可以有多个标签,而一个标签可以分配给多个问题。我们处于多对多关系类型中,这需要添加一个连接表,一个用于记住这种关系的表。上图中的表格就是这种情况;它只是保存标签和问题之间的关系。 QuestionTag
一切都与关系有关
上一个练习对您来说可能看起来很容易,因为您已经学习了有关 SQL 的讲座或教程,并且在日常工作中经常使用它。但老实说,当您第一次遇到问题并且必须创建允许您解决问题的数据模型时,您可能会绘制类似于下图中的图表的东西,对吧?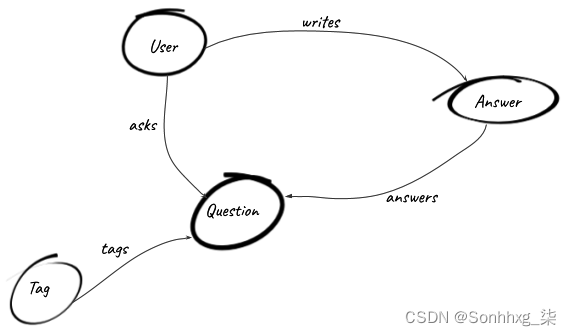
这是图数据库的强大功能之一:
Neo4j 作为一个图形数据库,允许您创建顶点或节点以及连接它们的关系。下一部分总结了 Neo4j 生态系统中不同实体之间的关系,以及我们如何在图表中构建数据。
Neo4j——节点、关系和属性模型
Neo4j 是一个基于 Java 的高度可扩展的图形数据库,其代码可在 GitHub 上的github.com/neo4j/neo4j上公开获得。本节介绍了它的构建块及其主要案例,以及由于没有系统是完美的而导致性能不佳的案例。
建筑模块
正如我们在图论中讨论的那样,像 Neo4j 这样的图数据库至少由两个基本构建块组成:
- 节点
- 节点之间的关系:

让我们详细看看其中的每一个。
节点
在 Neo4j 中,顶点称为节点。节点可以是不同的类型,就像Question我们Answer之前的例子中的那样。为了区分这些实体,节点可以有一个标签。如果我们继续与 SQL 并行,具有给定标签的所有节点将在同一个表中。但是类比到此结束,因为节点可以有多个标签。例如,克拉克肯特是一名记者,但他也是一名超级英雄;代表这个人的节点可以有两个标签:Journalist和SuperHero。
标签定义节点所属的实体类型。存储该实体的特征也很重要。在 Neo4j 中,这是通过将属性附加到节点来完成的。
关系
像节点一样,关系携带不同的信息。两个人之间的关系可以是类型MARRIED_TO或FRIEND_WITH许多其他类型的关系。这就是为什么 Neo4j 的关系必须只有一种类型。
Neo4j 的主要功能之一是关系也具有属性。例如,在添加MARRIED_TO两个人的关系时,我们可以添加婚礼日期、地点、他们是否签署婚前协议等作为关系属性。
特性
属性保存为键值对,其中键是捕获属性名称的字符串。然后,每个值可以是以下任何类型:
- 数字:整数或浮点数
- 文本:字符串
- 布尔值:布尔值
- 时间属性:Date、Time、DateTime、LocalTime、LocalDateTime或Duration
- 空间:点
在内部,属性保存为LinkedList,每个元素都包含一个键值对。节点或关系然后链接到其属性列表的第一个元素。
SQL 到 Neo4j 的翻译器
以下是一些能够轻松从关系模型转换为图形模型的指南:
| SQL世界 | Neo4j 世界 |
| Table | Node label |
| Row | Node |
| Column | Node property |
| Foreign key | Relationship |
| Join table | Relationship |
| NULL | 不要在属性中存储空值;只是省略属性 |
将这些准则应用于问答表图中的 SQL 模型,我们为本章前面的简单问答网站构建了显示在白板模型中的图形模型。全图模型如下:

//www.apcjones.com/arrows。
Neo4j 用例
与任何其他工具一样,Neo4j 在某些情况下非常好,但不太适合其他情况。基本原理是 Neo4j 为图遍历提供了惊人的性能。需要从一个节点跳转到另一个节点的一切都非常快。
另一方面,如果您想执行以下操作,Neo4j 可能不是最好的工具:
- 执行完整的数据库扫描,例如,回答“什么是?”的问题。
- 做全表聚合
- 存储大型文档:键值属性列表需要保持较小(假设不超过 10 个属性)
其中一些痛点可以通过适当的图形模型来解决。例如,不是将所有信息保存为节点属性,我们是否可以考虑将其中一些信息移动到另一个具有它们之间关系的节点?根据您感兴趣的请求类型,最适合您的应用程序的图形模式可能会有所不同。在深入了解图建模的细节之前,我们需要停下来谈谈不同种类的图属性,这些属性也会影响我们的选择。
了解图形属性
根据节点之间连接的属性,图分为几类。在将数据建模为图形时,这些类别非常重要,当您想要在它们上运行算法时更是如此,因为算法的行为可能会发生变化并在某些情况下产生意想不到的结果。让我们通过示例来发现其中的一些属性。
有向与无向
到目前为止,我们只讨论了作为一组连接节点的图。这些连接可能会有所不同,具体取决于您是从节点A到节点B,反之亦然。例如,有些街道只能朝一个方向行驶,对吗?或者,您在 Twitter 上关注某人的事实(您与该用户存在关注关系)并不意味着该用户也在关注您。这就是为什么有些关系是定向的。相反,结婚类型的关系自然是无向的,如果A与B结婚,通常B也与A 结婚:
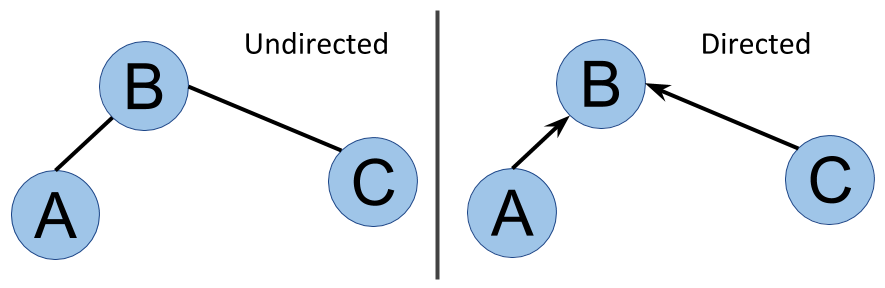
在右侧图中,有向图中,B 和 A 之间的过渡在该方向上是不允许的
加权与未加权
除了方向,关系还可以携带更多信息。实际上,例如在道路网络中,并非所有街道在路线系统中都具有相同的重要性。它们在高峰时段有不同的长度或占用率,这意味着从一条街道到另一条街道的旅行时间会有很大差异。用图对这一事实建模的方法是为每条边分配一个权重:
在加权图中,关系的权重为 16 和 4
最短路径算法等算法会考虑此权重来计算最短加权路径。
这不仅对道路网络很重要。在计算机网络中,单元之间的距离在连接速度方面也有其自身的重要性。在社交网络中,距离通常不是量化关系强度的最重要属性,但我们可以考虑其他指标。例如,这两个人联系了多久?或者用户A最后一次对用户B的帖子做出反应是什么时候?
循环与非循环
一个循环就是一个循环。如果您可以找到至少一条从一个节点开始并返回到完全相同的节点的路径,则图是循环的。
可以想象,了解图中循环的存在很重要,因为如果我们没有给予足够的关注,它们会在图遍历算法中创建无限循环。下图显示了n 非循环图与循环图: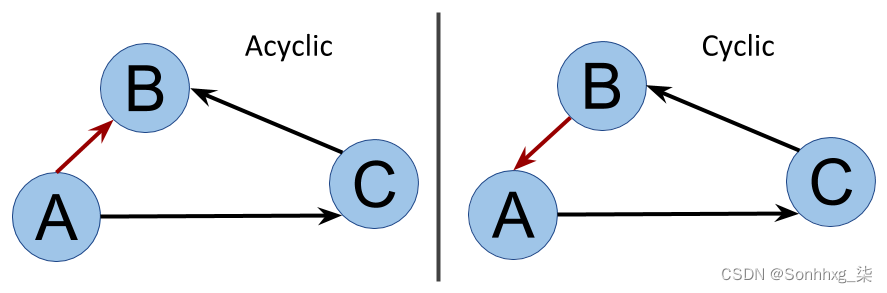
密集与稀疏
图密度是另一个重要的属性。它与每个节点的平均连接数有关。在下图中,左图对于四个节点只有三个连接,而右图对于相同数量的节点有六个连接,这意味着后者比前者更密集: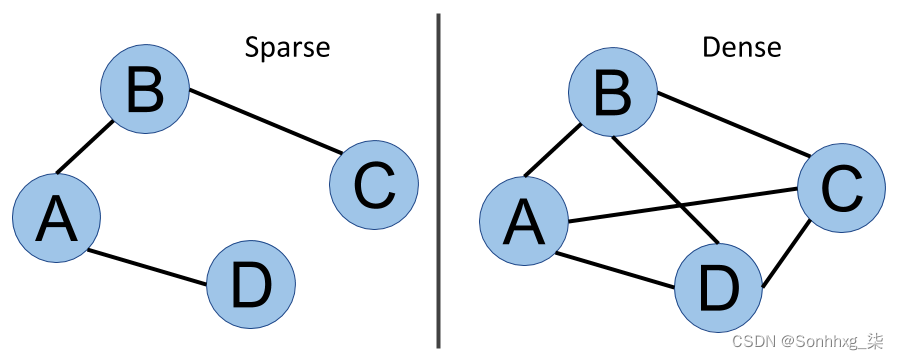
图遍历
但是为什么要担心密度呢?重要的是要认识到图数据库中的所有内容都是关于图遍历,通过沿一条边从一个节点跳到另一个节点。对于非常密集的图,这可能会变得非常耗时,尤其是在以广度优先方式遍历图时。下图显示了将广度优先搜索与深度优先搜索进行比较的图遍历: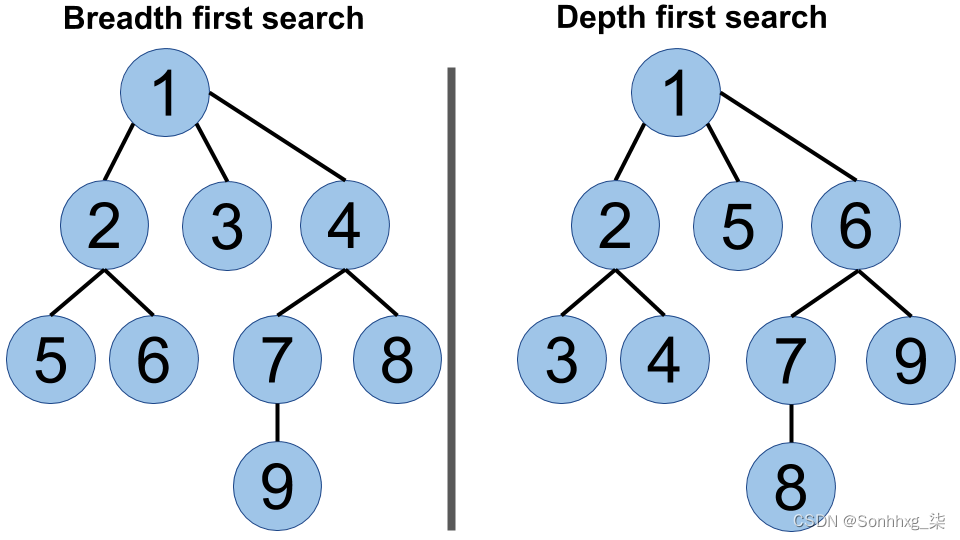
连接与断开
最后但并非最不重要的是连通性或连通图的概念。在下图中,无论考虑哪对顶点,从一个顶点到另一个顶点总是可能的。这张图被称为是连通的。在图的另一边,您可以看到D是孤立的 - 例如,没有办法从D转到A。这个图是不连贯的,我们甚至可以说它有两个分量。我们将在第 7 章“社区检测和相似性措施”中对这种结构进行分析。下图显示了连接与断开连接的图表: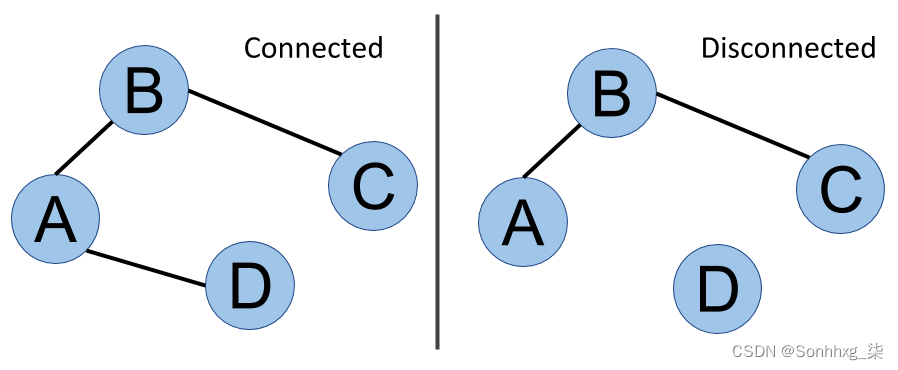
这是图属性的非详尽列表,但它们是我们在图数据库冒险中必须担心的主要属性。在为我们的数据创建白板图形模型时,其中一些很重要,我们将在下一节中讨论。
Neo4j 中图形建模的注意事项
我们简单的问答网站的白板模型是解决这个问题的第一种方法。根据您希望应用程序回答的问题类型,并且为了充分利用 Neo4j,架构可能会非常不同。
关系取向
正如我们在本章前面所讨论的,Neo4j 中的关系是面向的。但是,使用 Cypher,我们可以构建与方向无关的查询(参见第 2 章,Cypher 查询语言)。在这种情况下,绝对双射的关系不应在数据库中存储两次。简而言之,应该只在一个方向上建立友谊关系,如下图所示: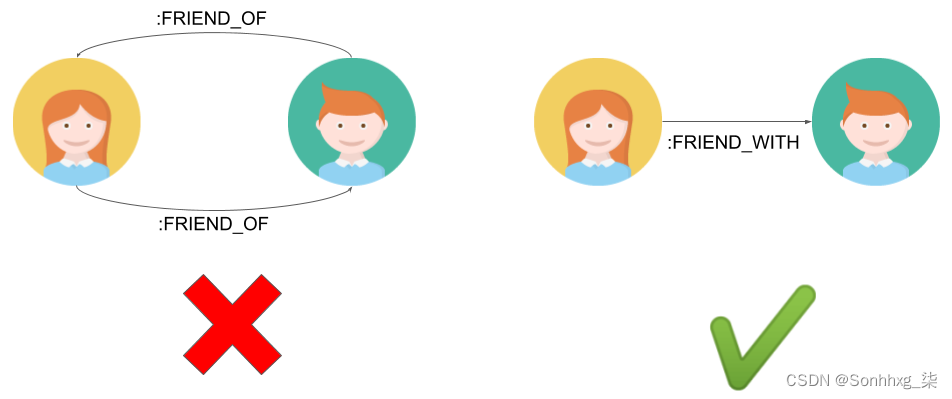
节点还是属性?
在选择图模型时经常和早期出现的另一个问题是(分类)特征是否应该存储为节点属性,或者它是否应该有自己的节点。
节点如下:
- 显式:节点出现在图形模式中,这使得它们比属性更可见。
- 性能:如果我们需要找到具有相同特征的节点,使用节点比过滤属性要快得多。
另一方面,属性如下:
- 更简单:它只是一个有值的属性,而不是复杂的节点和关系结构。如果您不需要对属性进行特殊分析,并且只希望它在处理其所属的节点时可用,那么属性就可以了。
- Indexable:Neo4j 支持对属性进行索引。它用于查找图遍历中的第一个节点并且非常高效(更多详细信息请参见第 2 章,Cypher 查询语言)。
如您所见,这个问题没有通用答案,解决方案将取决于您的用例。通常建议列出它们并尝试编写和测试关联的查询,以确保您不会陷入 Neo4j 陷阱。
有关图建模的更多信息和更多示例,我鼓励您查看Neo4j Graph Data Modeling(请参阅进一步阅读部分)。
概括
在本章中,我们讨论了图的数学定义以及它与图数据库的关系。然后,我们继续讨论我们将在本书中使用的特定图形数据库实例 Neo4j。我们已经了解了它的构建块、具有标签和属性的节点以及必须具有类型以及可选的一些属性的关系。最后,我们对不同类型的图(加权图、有向图、循环图或连接图)进行了一些重要的解释,以及这如何有助于定义最适合给定用例的数据模型。
在下一章中,我们将研究Cypher,Neo4j 使用的查询语言,以及我们如何为数据库提供数据并从中检索数据。
进一步阅读
- 如果您想了解更多关于图论背后的数学知识,您可以从Graph Theory with Applications、JA Bondy和 USR Murty、Elsevier 开始,他们的第一版可在网络上免费获得,例如https://www。 freetechbooks.com/graph-theory-with-applications-t559。
- 有关为图形数据选择适当模式的更多信息,请参阅Neo4j 图形数据建模,M. Lal,Packt Publishing。
-
一些参考资料以了解有关分离度的更多信息:
- 关于微软研究的论文:Jure Leskovec 和 Eric Horvitz对即时消息网络的行星规模视图
- Facebook 研究博客文章:https ://research.fb.com/blog/2016/02/three-and-a-half-degrees-of-separation/

















 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}