







🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
图是数据表示的一种特定形式。在前面的章节中,我们学习了如何以无监督或半监督的方式从图中提取信息。我们探索了如何将这些信息用作经典机器学习模型的特征,其中节点是观察值。在本章中,我们将处理一种只有图才有可能解决的全新类型的问题:链接预测。在准确了解链接预测问题是什么以及如何将其应用于不同的案例之后,我们将了解 Graph Data Science 库中实现的功能,这可以帮助我们找到问题的解决方案。最后,我们将使用 Python 及其数据科学工具箱研究一个真实的示例应用程序问题。
本章将涵盖以下主题:
- 为什么要使用链接预测?
- 使用 Neo4j 创建链接预测指标
- 使用 ROC 曲线构建链路预测模型
技术要求
本章将使用以下工具:
- 我们依赖 Neo4j 图数据库,版本 ≥ 3.5,以及以下插件:
- 图数据科学库(版本 ≥ 1.0)
- 代码示例将使用 Python (≥ 3.6) 给出,我们将使用以下包进行数据建模和数据可视化:
- 要存储数据并创建 DataFrame,我们将依赖. pandas
- 为了构建模型,我们将使用. scikit-learn
- 数据可视化将使用. matplotlib
- 本章的代码可以在 GitHub 上的以下链接中找到:
https ://github.com/PacktPublishing/Hands-On-Graph-Analytics-with-Neo4j/ch9
如果您使用的是Neo4j < 4.0,那么GDS插件的最后一个兼容版本是1.1,而如果您使用的是Neo4j ≥ 4.0,那么GDS插件的第一个兼容版本是1.2。
为什么要使用链接预测?
链接预测包括猜测图中现有节点之间的哪些未知连接现在或将来更有可能是真实的。通过适当的表述,这可以转化为机器学习问题。但在尝试建立链接预测模型之前,对于任何数据科学任务,我们必须从对问题的深刻理解开始。这将是我们在本节中的目标。首先,通过使用动态图的上下文,我们将定义链接预测背后究竟隐藏了什么。我们还将审查一些应用程序,从营销到科学。
动态图
到目前为止,在本书中,我们以静态的方式研究了图。换句话说,我们从外部数据源导入图表,并且图表内容(节点或关系)从未改变。以这种方式研究图结构可以为我们提供一些关于它所代表的数据的信息。然而,在现实生活场景中,无论您的图模型是道路网络还是电子商务网站,它都会随着时间而改变。在动态图中,图的所有部分都可以改变。以下是图表可以更改的方式的一些示例:
- 节点添加:订阅服务的新用户、添加到目录的新产品或创建的新交叉点。
- 节点移除:产品不再生产或客户离开。
- 链接添加:现有客户购买另一种产品,或在两个路口之间添加一条道路。
- 链接删除:一条封闭的道路或客户取消订阅某些服务,但保持订阅其他产品。
预测所有这些变化可能非常具有挑战性。因此,我们将专注于本章中的链接,假设节点没有变化。有了这个假设,图G在时间t 2的状态由以下公式给出:
G(t 1 ) + added_links - removed_links = G(t 2 )
下图是对上述公式的说明: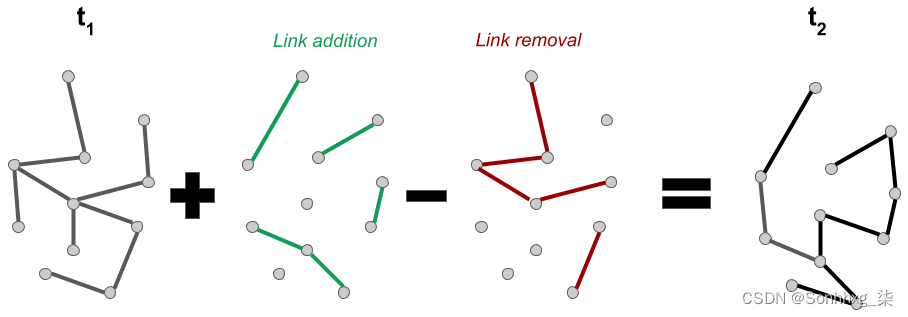
由于我们只关注链接添加,我们的目标是预测我们图中两个现有但未连接的节点将来是否可能连接。为此可以考虑许多不同类型的应用程序。
应用
预测未来的链接是链接预测的目标之一。但是可以找到其他应用程序,尤其是在我们掌握的信息不完整的情况下。
恢复丢失的数据
有时我们的图表数据并不能代表全貌。我们的知识将是不完整的,并且图中实体之间的某些链接可能会丢失。至少有两种情况经常发生这种情况。
打击犯罪
在犯罪行为方面,警方并不了解犯罪组织内部和之间的所有节点或关系。链接预测方法已被用于推断丢失的链接,并找到未来最有可能合作犯罪的犯罪分子。
研究
研究,就其本质而言,总是在发展和变化。当一个图用于对某个主题的知识进行建模时,这些知识通常是部分的,因为研究正在进行中,我们还没有完全理解图的所有元素之间的相互作用。
链接预测技术在生物学中已经被大量使用,例如,试图根据当前有关遗传疾病的知识来识别与某些疾病有关的基因。
提出建议
在日常生活中,链接预测可用于在社交网络和电子商务环境中向用户推荐。
社交链接(Facebook 好友、LinkedIn 联系人...)
Facebook、Twitter 和 LinkedIn 等网站都可以使用连接图表示:
- Facebook 是一种无向图建模友谊。
- LinkedIn 也是一个代表专业联系人的无向图。
- Twitter 是一个有向图(您可能会关注不关注您的人,反之亦然)。
所有这些社交媒体网站都包含类似“您可能认识的人”部分的内容。这些建议可以基于不同的因素。例如,他们可以使用以下事实:
- 你们参加了同一所大学的讲座,所以即使这种关系没有在社交媒体上正式公布,你们也可能认识对方。
- 你们有共同的朋友,所以你们很可能彼此认识,或者在未来的聚会、婚礼或其他涉及共同朋友的活动中被介绍。
除了连接推荐,链接预测也可以用于产品推荐。
产品推荐
想象一个类似于这个的图形模式:

用户链接到他们购买的产品。因此,为每个用户推荐产品是一个链接预测问题,我们试图预测用户和产品之间的新链接。
但是,这种链接预测与社交网络中使用的链接预测之间存在根本区别。这种差异来自图表的性质;在社交网络中,该图被称为monopartite,而 user-product 图是bipartite。区别如下图所示: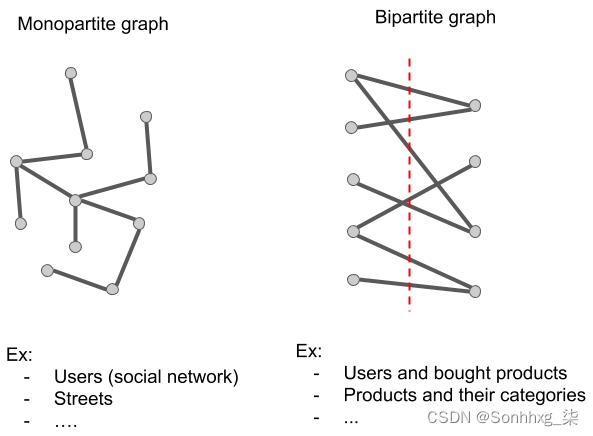
在二分图中,图由两组节点 N 和 M 组成,边必然连接节点 N 和节点 M。在前面显示用户和产品的图模式中,关系仅连接用户和产品;我们从来没有看到用户-用户或产品-产品的关系。这就是使图表具有二分性的原因——一侧是用户,另一侧是产品。
我们将在本章中学习的技术主要是为单部图设计的。我们将在本章的最后一节看到它们如何适应二分图。
使用链接预测算法进行推荐
在第 8 章,在机器学习中使用基于图的特征中,我们研究了一个包含以下列的数据集:
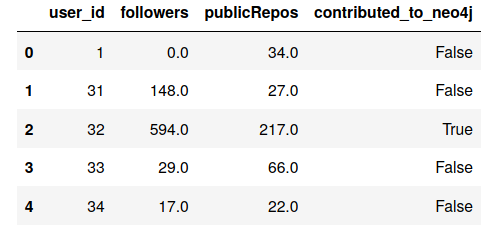
如果您阅读了第 2 章,Cypher 查询语言,您可能已经注意到该数据集与我们在本章中研究的图之间的相似性。它基于 GitHub 公共 API 构建,包含与 GitHub 上的 Neo4j 组织相关的数据:
- 它的贡献者
- 这些贡献者贡献的存储库
- 这些新存储库的贡献者
图模式如下:
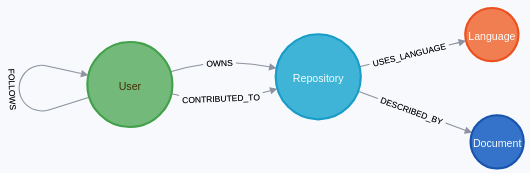
Language并且Document是通过对存储库的自述文件进行基于 NLP 的分析添加的一些特殊节点。我们将在这里重点关注User和Repository标签。
从该图中,我们可以使用以下 Cypher 查询构建上一章中使用的数据:
MATCH (u:User)
OPTIONAL MATCH (u)-[:CONTRIBUTED_TO]->(r:Repository)<-[:OWNS]-(:User {login: "neo4j"})
WITH u, COLLECT(r) as rs
RETURN id(u) as user_id,
u.followers as followers,
u.publicRepos as publicRepos,
size(rs) > 0 as contributed_to_neo4j
ORDER BY user_id该OPTIONAL MATCH语句允许我们检索所有用户,包括那些没有为 Neo4j 做出贡献的用户。使用COLLECT语句是必要的,这样我们就不会计算两次为 Neo4j 拥有的多个存储库做出贡献的用户。
但是,再次查看图模式,我们可以看到我们在前一章中试图回答的问题,“该用户是否对 Neo4j 拥有的存储库做出了贡献?”。也可以转化为链接预测问题:
用户和 Neo4j 拥有的存储库之间是否存在链接?
多年来已经开发了几种技术来找到解决这个问题的方法。在下一节中,我们将探讨 GDS 插件中已实现的主要算法。
使用 Neo4j 创建链接预测指标
有许多指标可用于链接预测问题。我们已经在本书中研究了其中的一些,但我们将在本节中以链接预测为新焦点来回顾它们。已经引入了一些其他指标,特别是针对此类应用程序,它们linkprediction位于 GDS 的命名空间下。
链接预测算法的想法是能够创建一个矩阵N×N,其中N是图中的节点数。矩阵的每个ij元素必须指示节点i和j之间存在链接的概率。
可以使用不同类型的指标来实现这一目标。其中之一是节点相似度度量,例如我们在第 7 章社区检测和相似度度量中研究的 Jaccard 相似度。在这种方法中,通过比较节点邻居的集合,我们可以了解节点的相似性以及它们未来连接的可能性。
相似性是可以在链接预测上下文中使用的度量的一个示例,但已经开发了更多。以下段落介绍其中最著名的。
基于社区的指标
社区指标包含有关图结构的信息。第 7 章,社区检测和相似性度量中介绍了不同类型的此类算法。其中包括用于发现孤立节点组的强连接和弱连接组件以及用于更微妙社区识别的标签传播和 Louvain 算法。
在许多情况下,我们可以安全地假设同一社区中的两个节点更有可能被连接。下图说明了这个概念: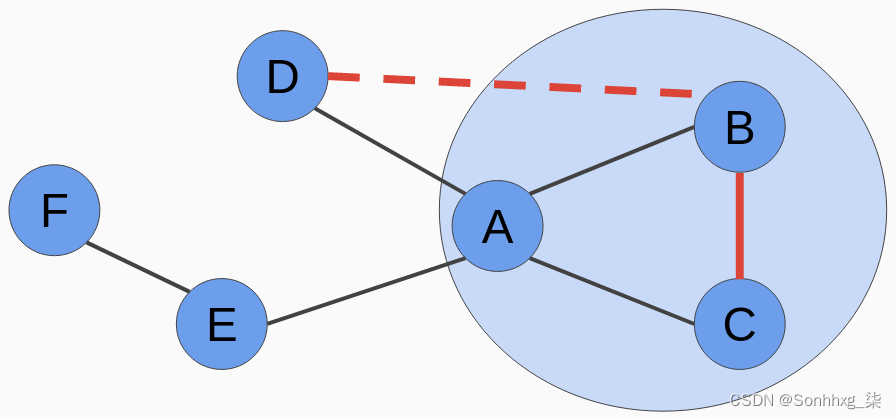
接下来更有可能创建B和C之间的链接,因为B和C位于同一个社区中,与节点B和D不同。在这种情况下,评分函数如下:
如果 u 和 v 在同一个社区中,则 score(u, v) = 1,否则为 0
在这些情况下,我们可以使用sameCommunityGDS 插件的功能。这将简单地检查两个节点是否在同一个社区中,假设社区存储为每个节点的节点属性:
MATCH (u:User {user_id: 32})
MATCH (v:User {user_id: 12464})
RETURN gds.alpha.linkprediction.sameCommunity(u, v, "louvain") as sameCommunity这完全等同于使用以下内容:
MATCH (u:User {user_id: 32})
MATCH (v:User {user_id: 12464})
RETURN u.louvain = v.louvain as sameCommunity路径相关指标
两个节点之间的距离可以是它们接近程度和未来可能连接的另一个指标。
节点之间的距离
让我们再看一下下图: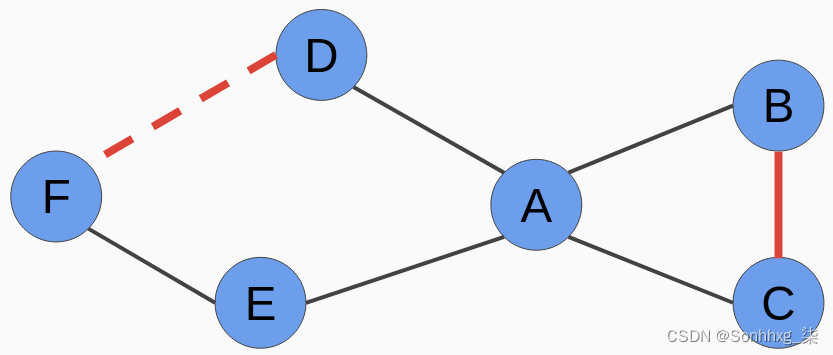
在上图中,我们可以看到B和C之间的关系比D和F之间的关系更可能为真,因为B和C之间的最短路径只有 2(未加权图),而 B 和 C 之间的最短路径D和F为 3。
所以我们可以设想一个评分函数如下:
score(u, v) = 1/d(u, v),
其中d(u, v)是节点u和v之间的最短路径
在第 4 章,图数据科学库和路径查找中,我们研究了所有对的最短路径算法,如果基于距离的链接预测指标与您的问题相关,则该算法在这里很有用。请记住,该算法可以graph使用以下查询在先前创建的名为投影图 上运行:
CALL gds.alpha.allShortestPaths.stream("projected_graph", {})
YIELD sourceNodeId, targetNodeId, distance
WITH gds.util.asNode(sourceNodeId) as startNode,
gds.util.asNode(targetNodeId) as endNode,
distance
RETURN startNode.name as start,
endNode.name as end,
distance为了将此距离转换为链接预测分数,我们将取距离的倒数,并根据这个新指标将结果按升序排序。这会导致最近的节点首先出现。如果我们只想显示不存在的链接,我们必须添加一个额外的过滤器来删除已经通过直接链接相互连接的节点对。这两个操作都在以下 Cypher 查询中执行:
CALL gds.alpha.allShortestPaths.stream("projected_graph", {})
YIELD sourceNodeId, targetNodeId, distance
WITH gds.util.asNode(sourceNodeId) as startNode,
gds.util.asNode(targetNodeId) as endNode,
1.0 / distance as score
WHERE NOT ((startNode)-[:LINKED_TO]->(endNode))
RETURN startNode.name, endNode.name, score
LIMIT 10未加权图中的最高可能分数为 0.5,因为断开连接的节点彼此相距至少两跳。创建两个节点B和C之间的边,得分为 0.5,包括闭合由三个节点B、C及其公共邻居A组成的三角形。下图说明了这个概念;节点C和B彼此相距两跳,因为它们之间的最短路径通过节点A。连接它们将闭合顶点为A、B和C 的三角形:
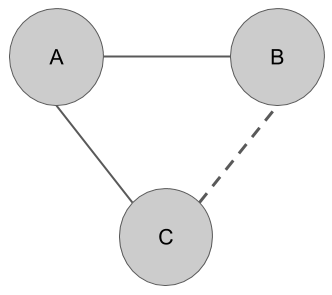
然而,在一个大图上,我们可能有很多节点,在这种情况下,关闭所有三角形几乎是不可行的。幸运的是,基于当地社区,存在更精细的技术。
卡茨指数(The Katz index)
计算节点之间的最短距离是一种非常基本的方法,它没有考虑节点之间可能的连接。一个详细的版本,称为Katz 索引,包括对两个节点之间的所有路径求和,长度增加。它使用以下公式计算:
分数(u, v) = ∑ l β l p(u, v; l)
让我们详细看看每个组件:
- l是路径长度,从 1 到 ∞。
- p(u, v; l)是节点u和v之间长度为l的路径数。
- β是一个权重参数,其值在 0 和 1 之间选择,以便为最短距离赋予更多权重。
在实践中,邻接矩阵用于计算这个分数,因为可以证明u和v之间长度为l的路径的数量等于邻接矩阵的uv元素的幂l:
score(u, v) = ∑l βl A(u, v)l
Katz 索引已被证明是性能最佳的基于路径的链接预测算法之一。例如,请看进一步阅读部分中题为“复杂网络中的链接预测:一项调查”的论文。
使用当地邻里信息
为了理解以下公式背后的数学原理,我们首先介绍一些符号,类似于第 7 章,社区检测和相似性度量中使用的符号:
- u、v和i是图的节点。
- N(u)表示节点u的邻居集合。
- |N(u)| 是集合的大小,表示节点u的邻居数。
共同邻居
公共邻居方法支持以下假设:
两个有共同朋友的人比没有共同朋友的人更有可能被介绍。
共同邻居度量度量u和v之间的共同朋友集的大小:
score(u, v) = | N(u) ∩ N(v) |
在 GDS 插件中,链接预测指标是函数,可以使用以下方法计算:
MATCH (u) MATCH (v)
RETURN id(u), id(v), gds.alpha.linkprediction.commonNeighbors(u, v)亚当-阿达尔
Adamic-Adar得分是对共同邻居方法的改进。Adamic-Adar 假设稀有连接比普通连接提供更多信息。在 Adamic-Adar 公式中,与邻居的每个关系都根据以下公式通过邻居度的倒数加权:
score(u, v) = Σ i 1/log|N(i)|, i ∈ N(u) ∩ N(v)
下图说明了这个想法。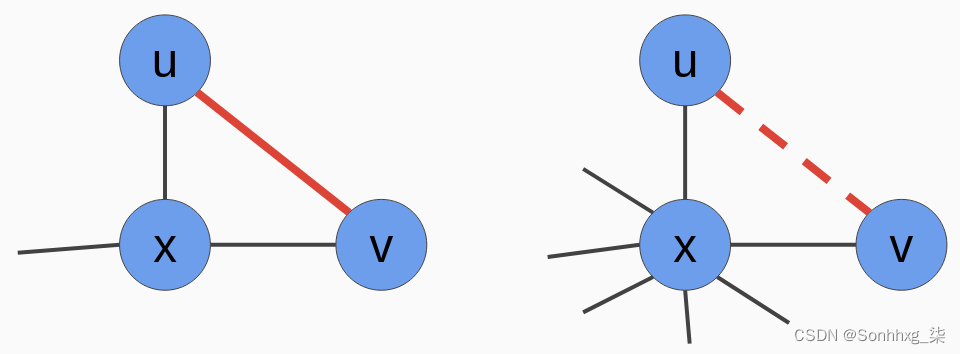
而节点u和v在两侧通过x连接,由于x在左图中的度数较低,它与u和v的关系更重要,u和v之间的边更可能:
邻居总数
当以下假设合理时,必须使用总邻居度量:
一个节点连接得越多,它的社交性越强,接收新链接的可能性就越大。
在量化节点u和v连接的可能性时,我们可以使用属于两个节点的相邻集的节点数:
score(u, v) = | N(u) ∪ N(v) |
让我们通过考虑以下两个图表来理解这个公式:
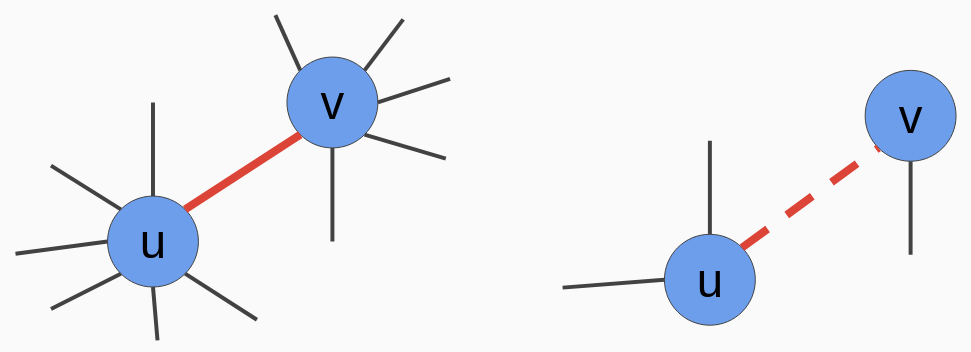
下图左侧的节点u和v与右侧的节点u和v相比有很多连接。因此,左侧的节点u和v更有可能接受新连接:
优先附加
在某些情况下,假设以下是合理的:
更受欢迎的人更有可能与其他受欢迎的人联系起来。
在这些情况下,必须使用优先连接方法。节点u和v的优先附着分数等于节点u和v的度数的乘积:
score(u, v) = | N(u) | × | N(v) |
这个分数也在gds.alpha.preferentialAttachment函数下的GDS插件中实现:
MATCH (u), MATCH (v)
RETURN id(u), id(v),
gds.alpha.linkprediction.preferentialAttachment(u, v, {
relationshipType: "REL",
direction: "BOTH"
})请注意,我们可以选择指定用于查找邻域的关系的类型和方向。我们将在下一节中查看一个示例应用程序。
其他指标
并非所有上述指标都可以同时使用。在哪种情况下最好使用哪一个取决于控制图增长的底层过程,并且在许多情况下,有必要测试几个指标以找到最合适的一个。我们甚至可以想象更多的指标,例如:
- 互惠性:链接的存在使得在相反方向上添加链接的可能性更大,而删除互惠链接的可能性更小。
- 新的弱点:新形成的链接比旧链接不太可能持续存在,因此权重较小。
- 不稳定性:如果连接到节点u和v的属性或链接经常变化,则u和v之间的边也更有可能无法生存并且权重较小。
在这篇关于链接预测评分方法的回顾之后,我们现在将使用 Neo4j 和scikit-learn.
使用 ROC 曲线构建链路预测模型
在我们迄今为止研究的所有图分析问题中,我们的观察都是图的节点。然而,现在我们正在转向一个不同的概念,其中观察是边缘。数据集的每一行都应包含有关图形一条边的信息。由于我们的目标是预测链接是否会在未来出现或从我们当前的知识中丢失,我们可以将问题转化为二分类问题,即边缘可以具有:
- 类True,链接存在或可能被创建,或者
- 类False,链接不太可能出现。
由于我们即将建立一个分类模型,我们的数据集必须包括现有和不存在的边(二元分类器的两个类)。
将数据导入 Neo4j
我们将在本章其余部分使用的数据是随机生成的几何图。这种图有许多有趣的特征,其中之一是它能够重现一些现实生活中的图的行为,例如社交图。
下载数据并将其放入import我们图的文件夹后,我们可以使用以下 Cypher 语句将其导入到 Neo4j 中:
LOAD CSV FROM "file:///graph_T2.edgelist" AS row
FIELDTERMINATOR " "
MERGE (u:Node {id: toInteger(row[0])})
MERGE (v:Node {id: toInteger(row[1])})
MERGE (u)-[:KNOWS_T2]->(v)训练集包含在时间t 2时已经存在于图中的边。因此,我们还要在之前的时间t 1导入图形。此时,节点与已经存在的节点相同,因此我们可以使用MATCH子句代替MERGE:
LOAD CSV FROM "file:///graph_T1.edgelist" AS row
FIELDTERMINATOR " "
MATCH (u:Node {id: toInteger(row[0])})
MATCH (v:Node {id: toInteger(row[1])})
MERGE (u)-[:KNOWS_T1]->(v)所以我们现在有一个包含两种关系的图表:
- KNOWS_T1如果两个节点在时间t1相互认识,则链接它们。
- KNOWS_T2如果两个节点在时间t2相互认识,则链接它们。类型关系集是类型关系KNOWS_T1集的子集,因为在时间t1KNOWS_T2相互认识的两个节点在时间t2仍然相互认识。
我们现在将学习如何计算该图的链接预测分数。
分割图并计算每条边的分数
为了使用链接预测分数进行预测,我们需要遵循以下步骤:
- 定义图在给定时间的状态,t 1
- 在时间t 1,计算图中每对节点的链接预测分数
- 将这些预测与t 1和t 2之间创建的链接进行比较
- 确定一个分数阈值,使得分数高于该阈值的对更有可能出现在时间t 2 > t 1
在这个例子中,图在 t 1的状态已经通过KNOWS_T1关系提供了。
我们现在可以计算图中每对节点的链接预测分数,使用新创建的关系仅考虑时间t 1的知识。在这里,我们选择使用 Adamic-Adar 分数:
MATCH (u) MATCH (v) WHERE u <> v
RETURN u.id as u_id,
v.id as v_id,
gds.alpha.linkprediction.adamicAdar(u, v, {
relationshipQuery: "KNOWS_T1",
direction: "BOTH"
}) as score
LIMIT 10前面查询中最重要的部分在这里突出显示:
- 链接预测函数将仅使用一种类型的关系KNOWS_T1,忽略我们试图预测的有关后验关系的信息。
- 该图被认为是无向的;如果 A 知道 B(在任何时候),那么我们认为 B 知道 A。
Adamic-Adar 算法识别的一些最可能的节点对如下:
╒══════╤══════╤═══════╕
│"u_id"│"v_id"│"score"│
╞══════╪══════╪═══════╡
│41 │33 │7.3 │
├──────┼──────┼───────┤
│33 │41 │7.3 │
├──────┼──────┼───────┤
│171 │42 │7.1 │
├──────┼──────┼───────┤
│162 │178 │6.9 │
├──────┼──────┼───────┤
│3 │124 │6.7 │
├──────┼──────┼───────┤
│75 │16 │6.6 │
└──────┴──────┴───────┘要在模型中使用这个分数,我们需要量化它的辨别能力,这可以通过接收器操作特征( ROC ) 曲线来实现。我们还需要为分数找到一个最佳截止值,以决定将来是否会出现链接;例如,我们应该停止在 score=5、score=4.5 还是更低?我们现在将讨论这两个主题。
测量二元分类模型的性能
这个问题是一个二元分类任务。我们的观察是链接,我们必须决定它们属于以下两个类别中的哪一个:
- 链接将在时间t 1和t 2之间创建。
- 在时间t 1和t 2之间不会创建链接。
为了衡量给定模型的性能,我们可以使用 ROC 曲线。
了解 ROC 曲线
到目前为止,我们有什么信息?对于测试样本,我们在时间 t 2的图,我们知道每对节点的以下内容:
- 在时间t 2时它们之间是否确实存在联系(基本事实)
- 从链接预测指标计算的分数
从这些信息中,我们可以得出每个标签的分数分布。让我们考虑以下情节: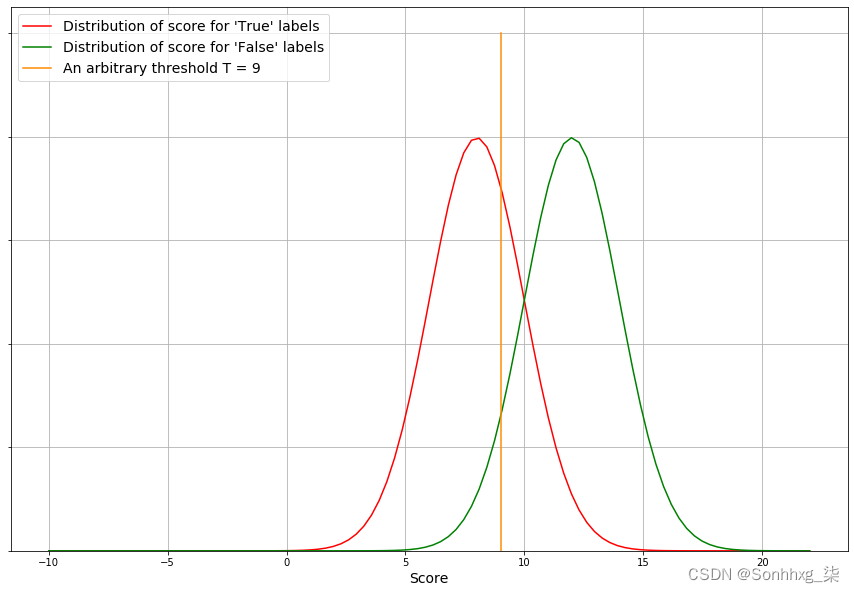
最左边的曲线表示具有标签的所有观察的分数分布False,而最右边的曲线对应于具有标签的所有观察的分数分布True。为了评估指标的质量,我们可以使用 ROC 曲线。
为了根据这些信息做出预测,我们需要定义一个分数阈值。要定义分数阈值,我们需要设置一条垂直线,以便将这条线左侧的所有观测值分类为False,而将右侧的所有观测值(即分数高于阈值的观测值)分类为归类为True。下图说明了两种可能的阈值选择;顶行有一个阈值T=11,而底行的两个图有一个阈值T=7: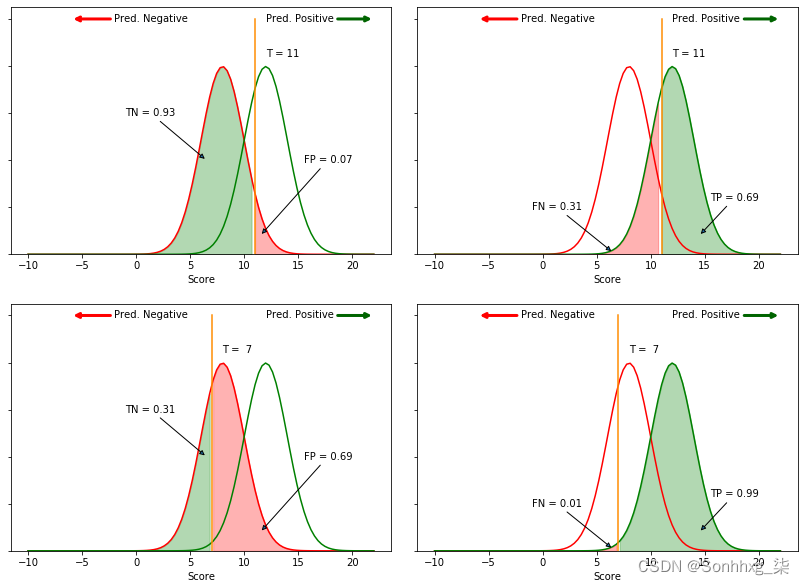
从这些曲线中,我们可以定义一些变量:
- 真阳性( TP ):正确分类为阳性的观察次数。这对应于绿色曲线下方和所选阈值右侧的绿色区域。
- 假阴性( FN ):这是 TP 的对应物,对应于被分类为阴性的阳性观察的比例。在图上,这是绿色曲线下的红色区域。
- 真阴性( TN ):正确分类为阴性的阴性观察次数。这是左侧红色曲线下方的绿色区域。
- 假阳性( FP ):被错误归类为阳性的负面观察的数量。这对应于红色曲线下的红色区域。
这四个变量组合起来定义真阳性率( TPR ) 和假阳性率( FPR ):
TPR = TP / (TP + FN)
FPR = FP / (FP + TN)
TPR衡量正确分类的True观察值与整个正面观察值的比例。FPR量化了错误分类的负面观察的比例。这两个量之间的权衡由 ROC 曲线表示: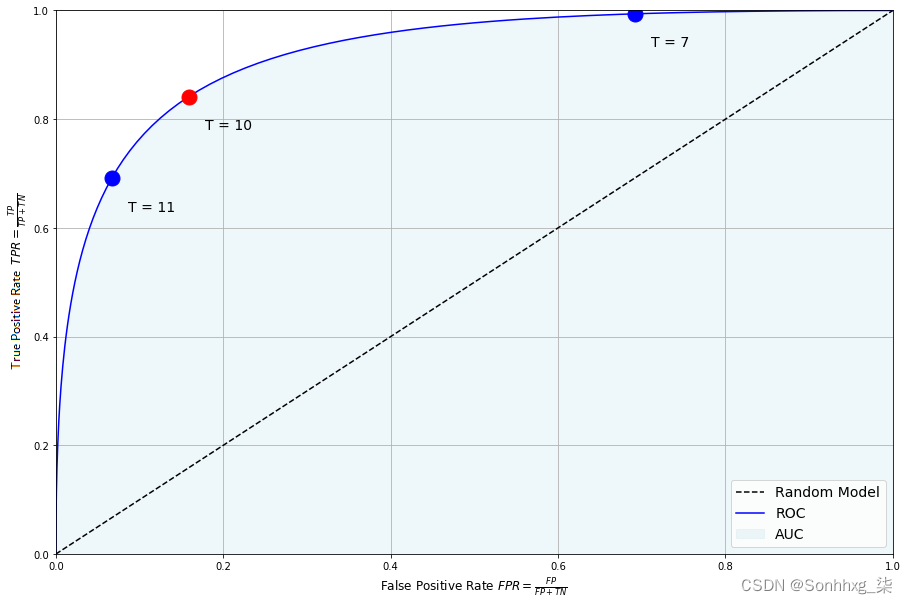
每个点对应一个给定的阈值。T=10处的点接近最优分区,即 FPR 和 TPR 之间折衷最佳的分区。
下图说明了一些配置,以帮助我们更好地了解 ROC 在不同场景下的样子: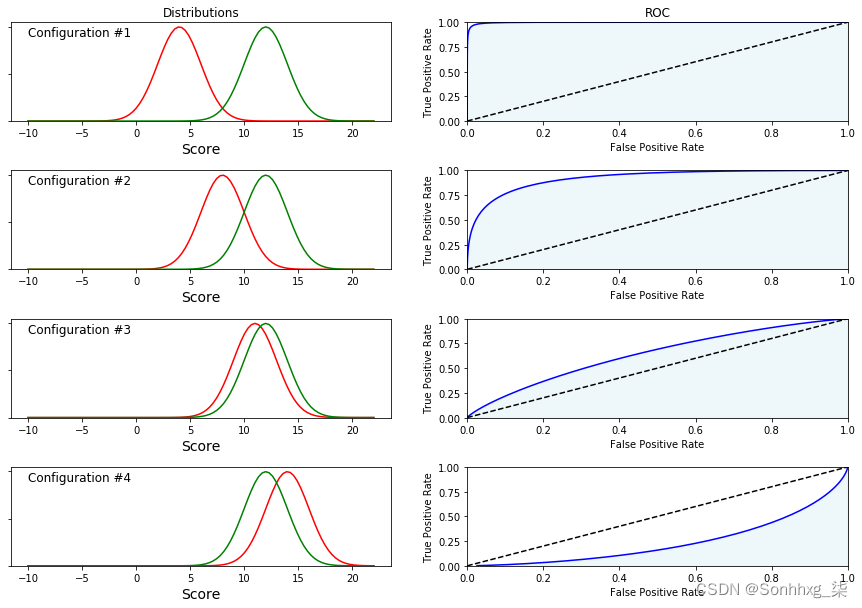
让我们来看看这些配置中的每一个:
- False在配置 1 中, (最左边的曲线)和(最右边的曲线)标签的分数分布True很好地分开。您可以轻松猜测应该使用哪个阈值来创建一个模型,该模型将成功地将观察结果分配给正确的类。在这种情况下,AUC 接近1,这是一个几乎完美模型的标志。
- 在配置 2 中,两个分布更接近,但仍然可以区分。AUC 较低,约为 0.8,但我们仍然可以获得良好的性能。
- 在配置 3 中,两个分布几乎相同,模型几乎不比随机选择好。
- 最后,在配置 4 中,模型似乎颠倒了这两个类别,因为False标签现在由最右边的曲线表示,因此得分高于True标签。如果我们坚持将较高分数归类为正数的预期规则,那么性能会比随机模型差。
现在让我们回到我们最初的链路预测问题并绘制 ROC 曲线。
提取特征和标签
为了为链接预测任务创建数据集,我们需要执行以下操作:
- KNOWS_T1仅使用关系计算图中每对节点的分数。
- 丢弃在t 1处已经相互链接的节点对。
- 为剩余的每一对提取标签;标签是True如果两个节点之间的关系在时间t 2存在,否则False。
以下查询执行这三个操作:
MATCH (u)
MATCH (v)
// take only one link from undirected graph
WHERE u.id < v.id // exclude u = v
// exclude edges that were already there at T1:
AND NOT ( (u)-[:KNOWS_T1]-(v) )
// compute score
WITH u, v, gds.alpha.linkprediction.adamicAdar(
u, v, {
relationshipQuery: "KNOWS_T1",
direction: "BOTH"
}
) as score
RETURN u.id as u_id,
v.id as v_id,
score,
// get the label: does the edge exist at time t2?
EXISTS( (u)-[:KNOWS_T2]-(v) ) as label从此查询创建的数据集也可在文件中找到adamic_adar_scores_labelled.csv。
绘制 ROC 曲线
在使用 Neo4j 计算基于图的信息之后,让我们使用一些更经典的数据科学工具来量化分数的质量。我们将使用pandas和中实现的功能scikit-learn。
创建数据框
首先,让我们使用 Neo4j Python 驱动程序将 Neo4j 中的数据导出到 pandas DataFrame(类似于第 8 章,在机器学习中使用基于图的特征中使用的方法):
import pandas as pd
from neo4j import GraphDatabase
driver = GraphDatabase.driver("bolt://localhost:7687", auth=("neo4j", "<YOUR_PASSWORD>"))
cypher = """
MATCH (u)
MATCH (v)
WHERE u.id < v.id // exclude u = v
AND NOT ( (u)-[:KNOWS_T2]-(v) )
WITH u, v, gds.alpha.linkprediction.adamicAdar(
u, v, {
relationshipQuery: "KNOWS_T1",
direction: "BOTH"
}
) as score
RETURN u.id as u_id,
v.id as v_id,
score,
EXISTS( (u)-[:KNOWS_T1]-(v) ) as label
"""
with driver.session() as session:
rec = session.run(cypher)
df = pd.DataFrame.from_records(rec.data())我们可以检查 DataFrame 中的类重新分区:
False 105555 True 3839
我们的非现有链接大约是现有链接的 30 倍。我们的数据集是不平衡的。对于这一阶段的分析,只要我们使用不受这种不平衡影响的指标,这将不是问题。
每个班级的归一化分数分布在下图中再现: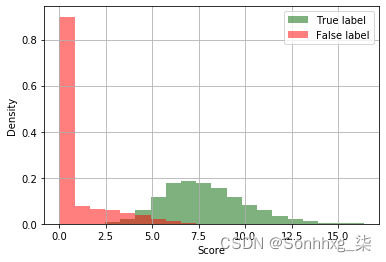
正如您从图中看到的那样, Adamic-Adar 分数似乎是推断未来链接的一个很好的指标。现在让我们使用 ROC 曲线对此进行量化。
绘制 ROC 曲线
首先,我们应该将数据集拆分为训练和测试样本,同时尊重两个样本中的类重新分区:
from sklearn.model_selection import train_test_split
X = df[["score"]]
y = df.label
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2,
random_state=42,
# make sure both the train and test samples are representative
# of the whole dataset in terms of class unbalance
stratify=y
)正如我们之前注意到的,我们的数据集是不平衡的。我们可以使用一些采样技术来恢复训练集中的类平衡:
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler(random_state=SEED)
X_train, y_train = rus.fit_resample(X_train, y_train)为了计算不同阈值的 FPR 和 TPR,我们将使用一个scikit-learn函数来为我们这样做:
from sklearn.metrics import roc_curve
fpr, tpr, thresholds = roc_curve(y_train, X_train.score)要使用 绘制 ROC 曲线matplotlib,请使用以下代码:
import matplotlib.pyplot as plt
plt.plot(fpr, tpr, color='blue', linewidth=2)结果如下图所示:

从上图中可以看出,我们的模型表现得非常好,并且有一些阈值我们可以在 TPR 和 FPR 中实现良好的性能。我们只需要选择这个阈值来完成我们的第一个链接预测模型的构建。
确定最佳截止和计算性能
选择用于分类的阈值取决于许多参数。在这里,我们将使用一个阈值来实现精确度和召回率之间的最佳权衡:
precisions, recalls, thresholds = precision_recall_curve(y_train, X_train.score)
plt.plot(thresholds, recalls[:-1], label="Recall")
plt.plot(thresholds, precisions[:-1], label="Precision")
plt.legend()
plt.grid()
plt.xlabel("Threshold")
plt.show()生成的图在这里重现,其中下降曲线表示召回率,上升曲线表示精度:

选择阈值 5 会导致以下混淆矩阵:

在时间t 2(第一行)的所有现有边中,97% 被我们的算法正确标记为True 。同样,对于不存在的边缘,93% 被正确分类为False。
使用 scikit-learn 构建更复杂的模型
第一个模型仅使用 Adamic-Adar 分数进行预测,已经运行良好,但是,它只使用了一个特征。在下一节中,我们将从图中提取更多特征,就像我们之前在第 8 章中所做的那样,在机器学习中使用基于图的特征。一旦将数据提取到 DataFrame 中并且我们正确设置了标签,我们就可以想象使用任何二进制分类器,无论是它scikit-learn还是其他包。
将链接预测结果保存到 Neo4j
一旦我们的模型准备好并产生预测,我们可以将它们保存回 Neo4j 以供将来使用(参见第 11 章,在 Web 应用程序中使用 Neo4j)。关于链接预测问题,我们将保存一个新的关系类型,FUTURE_LINK对于我们识别为未来更有可能连接的每一对节点。
让我们从编写将执行此操作的参数化 Cypher 查询开始:
cypher = """
MATCH (u:Node {id: $u_id})
MATCH (v:Node {id: $v_id})
CREATE (u)-[:FUTURE_LINK {score: $score}]->(v)
"""我们将所有需要的信息合并到一个 DataFrame 中:
df_test = df.loc[X_test.index]
df_test["score"] = pred然后我们可以遍历这些数据并为每行创建一个关系label=True:
with driver.session() as session:
for t in df_test.itertuples():
if t.label:
session.run(cypher, parameters={
"u_id": t.u_id,
"v_id": t.v_id,
"score": t.score
})循环现在关闭;从 Neo4j 中提取数据以执行我们的分析后,此分析的结果现在返回到数据库中。它们现在可以由后端或前端应用程序获取,例如,向用户显示连接建议。
在结束这个话题之前,让我们回到二分图的话题,例如,它对于进行产品推荐特别有用。
预测二分图中的关系
在二分图的情况下,以前的方法效果不佳。实际上,包含闭合三角形的算法是不合适的。
例如,考虑下图:
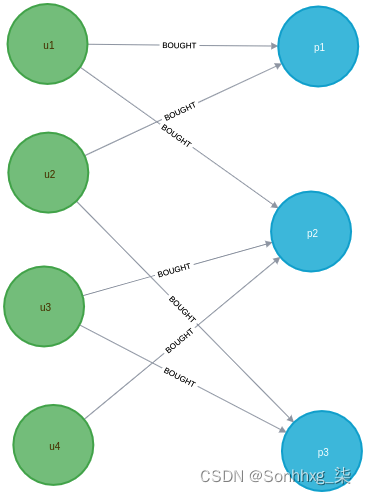
可以使用以下 Cypher 创建此图:
CREATE (u1:User {name: "u1"})
CREATE (u2:User {name: "u2"})
CREATE (u3:User {name: "u3"})
CREATE (u4:User {name: "u4"})
CREATE (p1:Product {name: "p1"})
CREATE (p2:Product {name: "p2"})
CREATE (p3:Product {name: "p3"})
CREATE (u1)-[:BOUGHT]->(p1)
CREATE (u1)-[:BOUGHT]->(p2)
CREATE (u2)-[:BOUGHT]->(p1)
CREATE (u2)-[:BOUGHT]->(p3)
CREATE (u3)-[:BOUGHT]->(p2)
CREATE (u3)-[:BOUGHT]->(p3)
CREATE (u4)-[:BOUGHT]->(p2)用户u1都u2购买了产品p1。u1, u2,p1因此是可能三角形的三个角。然而,通过在u1和之间添加一条边来闭合这个三角形u2是不可能的,因为我们不能在u1和之间建立关系u2。
解决这个问题的方法要么是改变我们寻找邻居的方式,要么是创建一些虚假的关系,以便将二分图转换为单分图。在前面的图表示例中,我们可以通过考虑购买相同产品的用户可以以某种方式连接来创建用户之间的虚假关系。
可以使用以下查询创建新关系:
MATCH (u1:User)-[:BOUGHT]->(:Product)<-[:BOUGHT]-(u2:User)
CREATE (u1)-[:LINKED_TO]->(u2)由User节点和LINKED_TO关系组成的结果图如下图所示: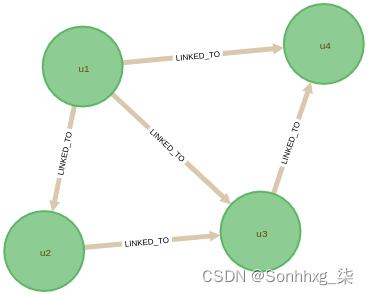
这种新LINKED_TO关系可以用作链接预测函数中的参数:
MATCH (u:User)
MATCH (v:User)
WHERE id(u) < id(v)
RETURN gds.alpha.linkprediction.commonNeighbors(u, v, {
relationshipQuery: "LINKED_TO",
direction: "BOTH"
})知道两个用户可能会通过这种虚假关系联系起来,这将使我们对他们未来可能购买的产品有所了解。但是,它还不是用户和产品之间的链接预测问题。
为此,我们需要在产品和用户之间创建一种新的关系,这正好与这种BOUGHT关系相反:
MATCH (p:Product)<-[:BOUGHT]-(u:User)
CREATE (p)-[:LINKED_TO]->(u)有了这些新关系,我们的图表如下所示: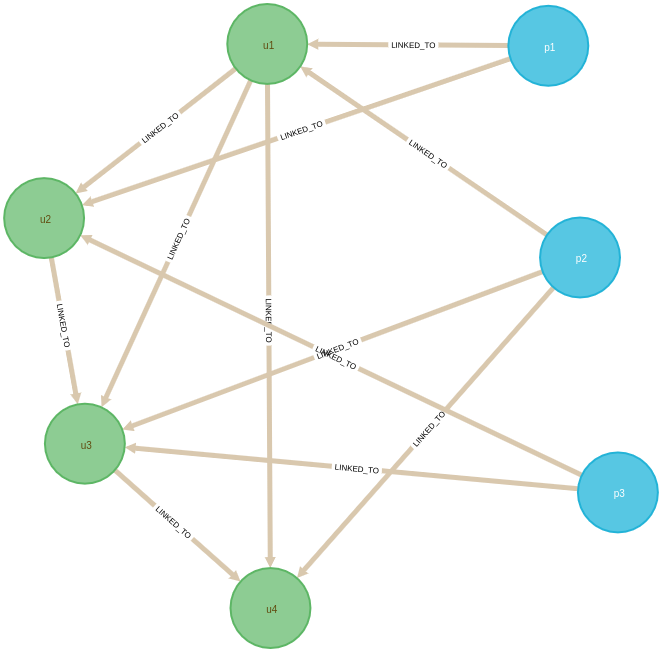
我们现在可以使用以下查询来获取用户和产品之间链接的预测分数:
MATCH (u:User)
MATCH (p:Product)
WHERE NOT EXISTS ( (u)-[:BOUGHT]->(p) )
WITH u.name as user, p.name as product, gds.alpha.linkprediction.commonNeighbors(u, p, {
relationshipQuery: "LINKED_TO",
direction: "BOTH"
}) as score
RETURN user, product, score
ORDER BY score DESC结果在下表中重现:
╒══════╤═════════╤═══════╕
│"user"│"product"│"score"│
╞══════╪═════════╪═══════╡
│"u3" │"p1" │2.0 │
├──────┼─────────┼───────┤
│"u2" │"p2" │2.0 │
├──────┼─────────┼───────┤
│"u1" │"p3" │2.0 │
├──────┼─────────┼───────┤
│"u4" │"p1" │1.0 │
├──────┼─────────┼───────┤
│"u4" │"p3" │1.0 │
└──────┴─────────┴───────┘我们来分析一下这个结果:
- u3连接到u2和u1,他们都购买了产品p1,所以u3和之间的共同邻居数p1为 2。
- u4并且p1有一个共同的邻居,u1,因为另一个邻居p1是u2并且u2不连接到,所以和p1之间的关系得分为 1。u4p1
我们在commonNeighbors这里使用了该算法,因为它更容易分析结果,但是我们在本章中看到的任何其他链接预测函数都可以实现同样的效果。
概括
阅读本章后,您应该对链接预测的含义以及如何使用它来解决许多与图相关的问题有了更清晰的理解。您还应该知道可以使用哪种指标来预测链接将来在两个节点之间出现的可能性。最后,您从头构建了一个链接预测问题,了解它与经典数据科学问题的不同之处,并学习了如何成功构建预测模型以预测图中的新关系。
到目前为止,我们已经学会了如何根据我们的数据形成图形结构这一事实来构建特征。了解图结构和这些特征的预测能力是重要的一步。然而,现代机器学习技术倾向于避免算法自动学习特征的特征工程步骤,称为嵌入。将这种技术应用于图形是我们将在下一章中介绍的主题。
问题
- 尝试 GDS 插件中的其他链接预测算法
进一步阅读
- 复杂网络中的链接预测:调查:https ://arxiv.org/abs/1010.0725
- 关于生物学和基因-疾病关系的链接预测的论文:
https ://bigdata.oden.utexas.edu/publication/prediction-and-validation-of-gene-disease-associations-using-methods-inspired-by-social -网络分析/ - 犯罪背景下的链接预测:
https ://www.ncbi.nlm.nih.gov/pmc/articles/PMC4841537/ - 推特上的链接预测:WTF:推特上的关注者服务:
https ://dl.acm.org/doi/10.1145/2488388.2488433 - Katz 指数计算(2019 年的论文):
https ://arxiv.org/abs/1912.06525

















 3482
3482











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











