







🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
在本章中,我们不是使用数值的时间序列,而是将 RNN 应用于自然语言文本(英语)。有两种简单的方法可以做到这一点。我们可以将文本视为字符序列或单词序列。在本章中,我们将它视为一个字符序列,因为这是最简单的入门方法。在许多情况下,使用单词比使用字符更强大,在接下来的几章中将对此进行探讨。
除了使用文本而不是数值之外,我们还演示了如何将模型与可变输入长度一起使用,以及如何预测多个时间步长,而不仅仅是紧跟在输入数据之后的一个步骤。
编码文本
要使用文本作为RNN的输入,我们需要首先以合适的方式对其进行编码。我们使用一个热编码,就像我们在图像分类问题中对类别所做的那样。一热编码适用于字符,因为典型的字母表只包含数十个字符。顺便说一句,one-hot编码单词的效率较低:它会导致更宽的向量,因为输入向量的宽度与要编码的符号总数相同,并且典型语言包含数万或数十万个单词。
为了更具体地说明这一点,假定文本仅由小写字符组成,没有特殊符号,如句点、逗号、感叹号、空格或换行符。然后,我们可以将字符编码为宽度为 26 的 one-hot 编码向量,因为英语中有 26 个小写字符。现在,我们可以定义一个将 26 个元素向量作为其 x 输入的 RNN,并且我们可以用具有 26 个输出的完全连接的 softmax 层结束它。现在,我们可以通过为每个时间步长提供一个单一热编码字符来向网络呈现文本序列,并且softmax输出可以解释为网络预测的下一个字符。最高值输出表示网络发现最有可能成为下一个字符的字符。具有第二高值的输出对应于第二个最有可能的下一个字符,依此类推。
处理文本时,通常使用单热编码来表示字符。
图 1-1 说明了在时间上展开的循环网络。在时间步长 0 处,字母 h 显示为网络的输入,在接下来的三个时间步长中,后跟 e、l 和 l。网络在最后一个时间步长中的预测是 o;也就是说,网络预测单词 hello 中的最后一个字符。显然,网络也会在前几个时间步长中预测一些东西,但是我们忽略了这些时间步长期间的输出,因为我们知道我们还没有呈现整个输入序列。
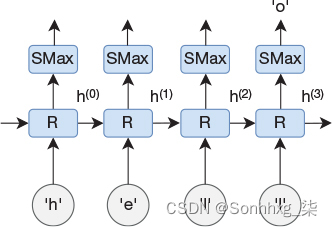
图 1-1文本预测网络具有递归层和完全连接的 softmax 层。标记为 SMax 的矩形不仅是数学 softmax 函数,而且是一个以 softmax 作为激活函数的完全连接的层。
在大多数情况下,我们希望能够处理大写字符以及特殊符号,因此one-hot编码字符的宽度可能包含大约100个元素而不是26个元素。我们很快就会看到一个编程示例,其中我们将一个热编码字符与RNN一起使用,但首先我们讨论如何预测未来的多个时间步长。这是我们在编程示例中使用的另一个属性。
长期预测和自回归模型
在前面的章节中,我们只预测了时间序列中的下一个值。能够预测更长的输出序列而不仅仅是单个符号通常是有益的。在本节中,我们将讨论几种预测多个时间步长的方法。
一种简单的方法是创建多个模型,其中每个附加模型预测未来进一步的时间步长。为了说明这一点,请考虑我们在第 9 章中为图书销售预测模型提供的训练示例。我们用输入数据x呈现它(t–n), ... . ., x(t–1),x(t)和所需的输出值 y(t+1).如果我们使用相同的输入数据,但相反地为它提供了稍后的时间步长 y 所需的输出值(t+2),我们将得到一个预测未来两步的模型。然后,我们可以创建另一个模型,用y训练(t+3),等等。现在,给定一个输入序列 x(t–n), . . . , x(t–1),x(t),我们可以将其呈现给我们的三个模型中的每一个,并得到接下来三个时间步的预测。这种方法实现起来很简单,但不太灵活,而且模型之间也没有共享或重用。
另一种选择是创建一个模型,该模型一次预测 m 个时间步长。我们将模型定义为具有 m 个输出,并且每个训练示例将再次由输入序列 x 组成。(t–n), . . . , x(t–1),x(t),但所需的输出现在是序列 y(t+1),y(t+2), 。 。 (吨+米).在这里,我们获得了重用参数来预测多个时间步长的潜在好处,但是我们需要预先决定要预测的未来有多少个时间步长,如果我们想预测极长的序列,我们最终会得到大量的输出神经元。
有一件事让我们对这两种方法产生了错误的影响,那就是我们需要在训练时预先决定我们想要预测多少个时间步长。就像我们希望能够处理可变长度的输入序列一样,我们希望动态选择输出序列的长度。对于模型仅基于变量的历史值(而不是其他变量的集合)预测变量的未来值的情况,有一种聪明的方法可以做到这一点。我们只需获取一个时间步的预测输出值,并将其作为下一个时间步的模型的输入反馈回来。我们可以在任意数量的时间步长内重复执行此操作。深度学习 (DL) 模型,其中一个时间步的输出用作下一个时间步的输入值,通常称为自回归模型。在深度学习领域之外,自回归模型通常是线性模型(哈斯蒂,蒂比希拉尼和弗里德曼,2009)。在DL的上下文中,它更广泛地用于任何类型的模型(通常是非线性的),其中我们使用一个时间步的输出作为下一个时间步的输入。
可以通过重复将预测的输出作为模型的输入反馈来完成长期预测。仅当网络预测作为输入所需的所有变量时,这才有效。它被称为自回归模型。
现在考虑文本自动完成的问题。在本例中,我们有一个字符序列,并且我们想要预测可能遵循输入序列的字符序列。也就是说,用于自动完成文本的神经网络的合理设计是采用图 11-1 中描述的网络,并首先向其提供我们想要自动完成的句子的开头。这将导致网络输出上的预测字符。然后,我们以自回归方式将此字符作为输入反馈到网络。图 11-2 说明了如何完成此操作。
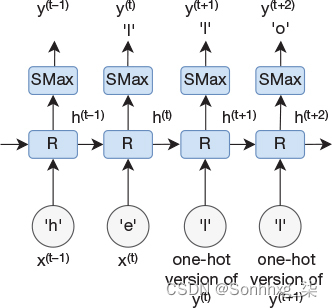
图 1-2文本预测网络,其预测作为输入反馈。对于前两个时间步长,网络最初将前两个字母 h 和 e 馈送,然后输出被反馈到其余时间步的输入。第一个时间步的输出将被忽略。
我们不会完全按原样获取输出并将其作为输入反馈。请记住,输出是概率分布;也就是说,网络将为每个字符分配一个介于 0 和 1 之间的值。但是,输入应为单热编码 - 只有对应于单个字符的元素应设置为 1,所有其他元素应设置为 0。因此,我们确定网络预测为最高概率的字符,并将该字符的 one-hot 编码作为输入(自回归)反馈回去。我们在下一个编程示例中就是这样做的,但首先我们介绍了一种技术,该技术需要获得多个可能的预测,而不仅仅是单个预测。
当输出是softmax函数时,我们通常不会将确切的输出作为输入反馈,而是识别最可能的元素,并使用该元素的一热编码版本作为网络的输入。
束搜索
执行文本自动完成时,通常希望模型预测一个句子的多个替代完成。算法波束搜索可实现此目的。Beam搜索自20世纪70年代以来就为人所知,但在基于DL的自然语言处理中已经变得流行起来,例如,用于自然语言翻译(Sutskever,Vinyals和Le,2014)。
Beam搜索使我们能够在将输出作为输入反馈到网络时创建多个替代预测。
该算法的工作方式如下。我们不是总是为每个时间步长选择最可能的预测,而是选择N个预测,其中N是一个称为光束大小的常数。如果我们这样做很天真,我们将在第一个时间步长之后有N个候选者,在第二个时间步长之后有N×N个候选者,在第三个时间步之后有N×N×N个候选者,依此类推。为了避免这种组合爆炸,每个时间步长还涉及修剪候选项的数量,以仅保留 N 个最可能的候选项。为了更具体地说明这一点,让我们看一下图 1-3 中所示的示例,其中我们假设 N = 2。
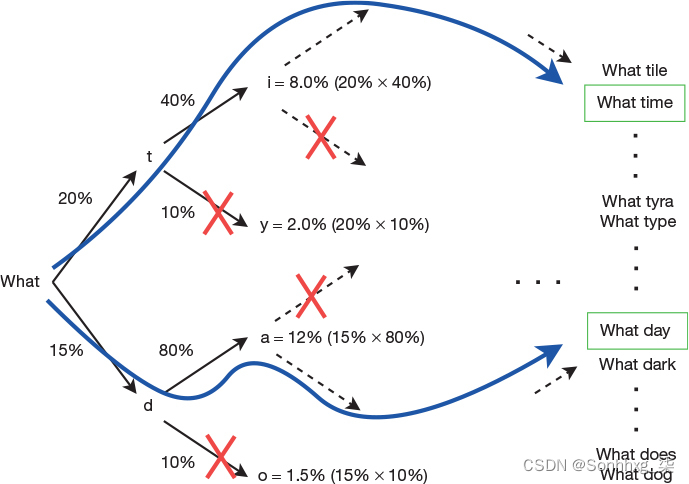
图 1-3光束大小为 2 的逐个字符进行光束搜索。在每个步骤中,除了两个最可能的替代方案(总体)之外,所有选项都被修剪。
假设我们刚刚向网络呈现了序列“W-h-a-t”,后跟一个字符空间。我们得到一个输出向量,其中对应于字符 t 的条目具有最高概率 (20%),字符 d 具有第二高的概率 (15%)。因为 N = 2,所以我们忽略所有其他候选项。我们将第一个候选项 t 作为输入反馈回网络,并找到两个最可能的输出 i (40%) 和 y (10%)。在模型的另一个副本中,我们改为将第二个候选项 d 作为网络的输入反馈,并找到两个最可能的输出 a (80%) 和 o (10%)。
我们现在有四个候选人 什么 ti,什么 ty,什么哒,做什么做什么。我们可以通过乘以每个步骤的概率来计算这四个候选者中每个候选者的总体概率。例如,ti 被分配的概率为 0.2 × 0.4 = 0.08。我们现在修剪树并仅保留N个最可能的候选者,在我们的示例中,它们是什么ti(8%)和什么da(12%)。
有一个关键的观察结果值得指出。什么 t 导致比什么 d 更高的概率。尽管如此,在下一步中,什么da(这是什么d的延续)被赋予比什么ti(这是更可能的什么t的延续)更高的概率。这也意味着,由于最有可能的候选者很可能在流程的早期就被修剪过,因此无法保证波束搜索总体上会找到最有可能的候选者。也就是说,在这个例子中,我们到达了什么时间和什么日期,但很可能是“什么夜晚”是总体上最有可能的替代选择。
如果您熟悉搜索算法,您可能会注意到它是一种广度优先的搜索算法,但我们限制了搜索的广度。光束搜索也是贪婪算法的一个例子。
如果您不熟悉广度优先搜索或贪婪算法,则无需担心。但是,与往常一样,您可能需要考虑在将来学习它。
现在,我们有了所有需要的构建块,可以转到我们的编程示例,在那里我们在实践中实现所有这些内容。
编程示例:使用 LSTM 进行文本自动完成
在这个编程示例中,我们想要创建一个基于长短期记忆(LSTM)的RNN,它可用于文本的自动完成。为此,我们需要首先在一些可用作训练集的现有文本上训练我们的网络。网上有大量的文本数据可用于这样的练习,一些研究甚至使用了维基百科的全部内容。对于更简单的演示示例,例如本章中的演示示例,我们通常需要一些较小的示例来避免冗长的训练时间,而一个流行的选择是从古腾堡项目中挑选您喜欢的书籍。1它是不再受版权保护的书籍的集合,可以在线以文本格式提供。对于这个例子,我们选择使用弗兰肯斯坦,这应该是大多数读者所熟悉的(Shelley,1818)。我们只需下载文本文件并将其保存在本地计算机上,以便访问下面描述的代码。
1. https://www.gutenberg.org
初始化代码显示在代码片段 11-1 中。除了 import 语句之外,我们还需要提供用于训练的文本文件的路径。我们还定义了两个变量和 ,它们用于控制将此文本文件拆分为多个训练示例的过程。其他三个变量控制波束搜索算法,稍后将对此进行介绍。WINDOW_LENGTHWINDOW_STEP
初始化代码
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM
import tensorflow as tf
import logging
tf.get_logger().setLevel(logging.ERROR)
EPOCHS = 32
BATCH_SIZE = 256
INPUT_FILE_NAME = '../data/frankenstein.txt'
WINDOW_LENGTH = 40
WINDOW_STEP = 3
BEAM_SIZE = 8
NUM_LETTERS = 11
MAX_LENGTH = 50打开并读取文件的内容,将其全部转换为小写,并将双空格替换为单空格。为了使我们能够轻松地对每个字符进行一次热编码,我们希望为每个字符分配一个单调递增的索引。这是通过首先创建唯一字符列表来完成的。获得该列表后,我们可以循环访问它并为每个字符分配一个递增索引。我们这样做两次,以创建一个从字符映射到索引的字典(哈希表)和一个从索引到字符的反向字典。
当我们想要将文本转换为网络的一热编码输入时,以及当我们想要将一热编码输出转换为字符时,这些将派上用场。最后,我们使用唯一字符的计数初始化一个变量,该计数将是表示一个字符的每个 one-hot 编码向量的宽度。encoding_width
读取文件、处理文本和准备字符映射
点击此处查看代码图像
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM
import tensorflow as tf
import logging
tf.get_logger().setLevel(logging.ERROR)
EPOCHS = 32
BATCH_SIZE = 256
INPUT_FILE_NAME = '../data/frankenstein.txt'
WINDOW_LENGTH = 40
WINDOW_STEP = 3
BEAM_SIZE = 8
NUM_LETTERS = 11
MAX_LENGTH = 50
下一步是从文本文件创建训练示例。这是通过代码片段 11-3 完成的。每个训练示例将包含一个字符序列和紧跟在输入字符后面的单个字符的目标输出值。我们使用长度的滑动窗口创建这些输入示例。创建一个训练示例后,我们按位置滑动窗口并创建下一个训练示例。我们将输入示例添加到一个列表中,将输出值添加到另一个列表中。所有这些都是通过第一个循环完成的。WINDOW_LENGTHWINDOW_STEPfor
创建字典的代码行是“Pythonic”,因为它们将许多功能压缩到一行代码中,这使得如果你是Python的初学者,几乎不可能理解。我们通常尽量避免编写这样的代码行,但它们确实具有非常紧凑的好处。
如果你想更流利地使用这些类型的紧凑表达式,那么你可以考虑阅读有关概念生成器,列表理解和字典理解 python.org。
准备单热编码训练数据
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM
import tensorflow as tf
import logging
tf.get_logger().setLevel(logging.ERROR)
EPOCHS = 32
BATCH_SIZE = 256
INPUT_FILE_NAME = '../data/frankenstein.txt'
WINDOW_LENGTH = 40
WINDOW_STEP = 3
BEAM_SIZE = 8
NUM_LETTERS = 11
MAX_LENGTH = 50然后,我们创建一个包含所有输入示例的张量和另一个保存输出值的张量。这两个张量都将以一个热编码形式保存数据,因此每个字符都由大小的维度表示。我们首先为两个张量分配空间,然后使用嵌套循环填充值。encoding_widthfor
正如我们对图书销售预测示例所做的那样,我们花费了大量的代码来准备数据,这是你应该习惯做的事情。现在,我们已准备好构建模型。从训练模型的角度来看,它看起来类似于图书销售预测示例,但我们使用了由两个 LSTM 层组成的更深层次的模型。两个 LSTM 层在层之间的连接以及循环连接上使用 0.2 的压差值。请注意我们如何传递给第一层的构造函数,因为第二层需要查看第一层的所有时间步的输出值。第二个 LSTM 层后面是一个完全连接的层,但这次输出层由多个神经元组成,使用 softmax 函数而不是单个线性神经元,因为我们将预测离散实体(字符)的概率,而不是单个数值。我们使用分类交叉熵作为我们的损失函数,这是多类别分类的推荐损失函数。return_sequences=True
需要注意的一点是,当我们准备数据时,我们没有将数据集拆分为训练集和测试集。相反,我们向函数提供一个参数。然后,Keras 会自动将我们的训练数据拆分为训练集和测试集,其中参数 0.05 表示 5% 的数据将用作测试集。对于文本自动完成的情况,我们也可以省略此参数,而只是使用所有数据进行训练,而不进行任何验证。相反,我们可以通过使用自己的判断手动检查输出,因为文本自动完成的“正确”结果有点主观。在代码片段 11-4 中,我们选择使用 5% 的验证集,但也会检查预测,以了解网络是否正在执行我们希望它执行的操作。最后,我们训练模型的 32 个 epoch,小批量大小为 256。validation_split=0.05fit()
构建和训练模型
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM
import tensorflow as tf
import logging
tf.get_logger().setLevel(logging.ERROR)
EPOCHS = 32
BATCH_SIZE = 256
INPUT_FILE_NAME = '../data/frankenstein.txt'
WINDOW_LENGTH = 40
WINDOW_STEP = 3
BEAM_SIZE = 8
NUM_LETTERS = 11
MAX_LENGTH = 50
这导致训练损失为 1.85,测试数据的损失为 2.14。我们可能会调整网络以产生更好的损失值,但我们更感兴趣的是尝试使用我们的模型来预测文本。我们使用前面描述的波束搜索算法来做到这一点。
在我们的实现中,每个梁都由一个包含三个元素的元组表示。第一个元素是当前字符序列的累积概率的对数。我们稍后将描述为什么使用对数。第二个元素是字符串。第三个元素是字符串的单热编码版本。代码片段 11-5 中显示了该实现。
使用模型和 Do 梁搜索来提供多个文本补全
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import LSTM
import tensorflow as tf
import logging
tf.get_logger().setLevel(logging.ERROR)
EPOCHS = 32
BATCH_SIZE = 256
INPUT_FILE_NAME = '../data/frankenstein.txt'
WINDOW_LENGTH = 40
WINDOW_STEP = 3
BEAM_SIZE = 8
NUM_LETTERS = 11
MAX_LENGTH = 50
我们首先创建一个具有初始字符序列()的单个光束,并将初始概率设置为1.0。字符串的单热编码版本由第一个循环创建。我们将此梁添加到名为 的列表中。'the body 'beams
接下来是一个嵌套循环,该循环使用经过训练的模型根据波束搜索算法进行预测。我们提取每个光束的单热编码表示,并创建一个包含多个输入示例的NumPy数组。每个波束有一个输入示例。在第一次迭代期间,只有一个输入示例。在剩余的迭代中,将有许多示例。BEAM_SIZE
我们调用 ,它导致每个光束一个软最大向量。softmax 向量在词汇表中每个单词都包含一个概率。对于每个光束,我们创建新的光束,每个光束由原始光束中的单词组成,这些单词与另一个单词连接在一起。我们在创建梁时选择最有可能的单词。每个光束的概率可以通过将光束的当前概率乘以添加字的概率来计算。但是,鉴于这些概率很小,计算机算术的有限精度存在导致下溢的风险。这可以通过计算概率的对数来解决,在这种情况下,乘法被转换为加法。对于少量单词,这不是必需的,但为了良好的实践,我们还是这样做。model.predict()BEAM_SIZE
一旦我们为每个现有梁创建了光束,我们就会根据它们的概率对新光束的列表进行排序。然后,我们丢弃除顶部梁之外的所有光束。这表示修剪步骤。对于第一次迭代,这不会导致任何修剪,因为我们从单个梁开始,而这个梁只产生梁。对于所有剩余的迭代,我们最终会得到光束并丢弃其中的大多数。BEAM_SIZEBEAM_SIZEBEAM_SIZEBEAM_SIZE * BEAM_SIZE
值得指出的是,我们的实现不会逐个字符地获取预测的输出并将其反馈回输入。相反,循环的每次迭代都会产生一个包含整个字符序列的全新迷你批次,我们通过网络将此序列馈送。也就是说,结果是相同的,但是我们进行了许多冗余计算。在第12章“神经语言模型和词嵌入”中,我们提出了一个替代实现的示例,该实现确实将输出反馈到输入,一次一个符号。
循环运行固定次数的迭代,然后打印出生成的预测:
the body which the m
the body which the s
the body of the most
the body which i hav
the body which the d
the body with the mo
请注意,网络生成的预测既使用拼写正确的单词,又具有看起来合理的语法结构。这完成了我们的编程示例,但我们鼓励您使用不同的训练数据和用作起点的不同部分短语进行进一步实验。
双向RNN
在处理文本序列时,查看以前和将来的单词通常是有益的。例如,在写段落时,通常的情况是,我们先写一个句子,然后写另一个句子,然后返回并编辑前一个句子,以便更好地与后面的句子组合在一起。另一个例子是当我们解析某人所说的话时。假设我们听到一句话的开头,“我看到了b.......”,但没有完全听到最后一个字。然而,我们确实听说这是一个以b开头的单音节单词。我们可能需要要求这个人重复他们说的话,因为这个词可能是什么并不明显 - 它可能是球或男孩或比尔或以b开头的数字单词中的任何一个。相反,假设我们听到了整个句子:“我看到了b。天空。以b音和天空为背景,我们可能不会要求这个人重复,而只是假设这个词是蓝色的。换句话说,观察未来的单词使我们能够预测缺失的单词,而这方面的典型应用是语音识别。
双向RNN(舒斯特和帕利瓦尔,1997)是一种网络架构,能够查看未来的单词。双向RNN层由并行运行的两层组成,但它们接收不同方向的输入数据。为此,完整的输入序列需要预先可用,因此不能在动态创建序列的在线设置中使用。为了简单起见,请考虑由单个单元组成的常规RNN层。如果我们想创建这个RNN层的双向版本,我们会添加另一个单元。如果我们随后想将字符 h、e、l、l、o 馈送到网络,我们会在第一个时间步长将 h 馈送到其中一个单元,将 o 馈送到另一个单元。在时间阶梯2,我们会喂它们e和l,在时间阶梯3,l和l,在时进阶4,l和e,最后,在时进阶5,o和h。在每个时间步长中,两个单元中的每一个都会产生一个输出值。在序列结束时,我们将为每个输入值组合两个输出。也就是说,第一个单位的时间步长 0 的输出值和第二个单位的时间步长 4 的输出值将被合并,因为这些时间步长表示单位接收 h 作为输入的时间。有多种方法可以组合两个单位的输出,例如加法、乘法或平均值。
双向 RNN 预测来自过去和未来的元素。
在 Keras 中,双向层实现为可与任何 RNN 层一起使用的包装器。代码片段 11-6 展示了如何使用它将常规 LSTM 层更改为双向 LSTM 层。
如何在 Keras 中声明双向层
from tensorflow.keras.layers import Bidirectional
…
model.add(Bidirectional(LSTM(16, activation='relu')))
如果您发现双向层令人困惑,请不要太担心。我们在这里提到它们主要是因为您在阅读更复杂的网络时可能会遇到它们。在本书的编程示例中,我们没有使用双向层。
输入和输出序列的不同组合
我们最初的图书销售预测采用一系列值作为输入,并返回单个输出值。我们的文本自动完成模型将一系列字符作为输入,并生成一系列字符作为输出。在一篇流行的博客文章中,Karpathy(2015)讨论了输入和输出的其他组合。如图 1-4 所示。
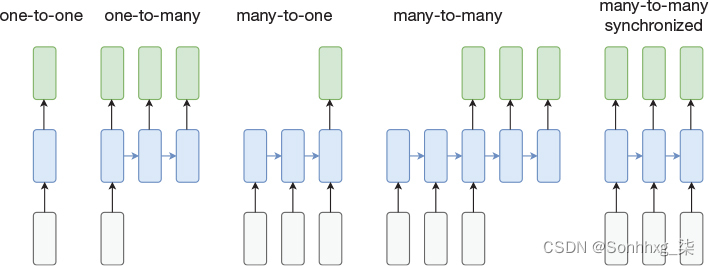
图 1-4RNN 的输入/输出组合在时间上展开。灰色表示输入,蓝色表示网络,绿色表示输出。(资料来源:改编自Karpathy,A.,“递归神经网络的不合理有效性”,2015年5月,http://karpathy.github.io/2015/05/21/rnn-effectiveness/。
从左开始,一对一网络不是一个循环网络,而只是一个前馈网络,它接受一个输入并产生单个输出。这些输入和输出很可能是向量,但它们不是以可变长度序列的形式呈现,而是以单个时间步长表示。第二种组合是一对多情况,它在第一个时间步长期间接收输入,并在随后的时间步长中产生多个输出。一个典型的用例是,图像被呈现为输入,网络生成图像中内容的文本描述。第三个例子是多对一模型,这正是我们在书籍销售预测示例中所做的。接下来是多对多案例。尽管输入序列的长度与图中的输出序列相同,但这不是必需的。例如,在我们的文本自动完成示例中,我们实现了一个多对多网络,其中输入序列和输出序列可以具有不同的步数。最后,图中最右边的示例显示了一个同步的多对多网络,其中每个时间步的输入都有相应的输出。一个典型的例子是一个网络,它对视频的每个帧进行分类,以确定帧中是否有猫。
一个合理的问题是不同类型的网络在实践中是如何实现的。首先,请注意,我们不应该将讨论限制在“纯”循环网络上,但刚刚描述的概念可以应用于更复杂的混合架构。
现在让我们考虑一对多的情况。从图中看,它可能看起来并不那么复杂,但是在尝试实现模型时想到的第一个问题是如何处理第一个时间步长之后所有时间步的输入。请记住,该图表示在时间上展开网络的抽象,如果网络在第一个时间步长期间具有输入,则这些输入对于后续时间步长仍然存在,并且必须提供一些东西。对此,两个明显而常见的解决方案是,要么在每个时间步长中用相同的输入值馈送网络,要么在第一个时间步进给网络提供真实的输入值,对于每个后续的时间步长,向它提供某种在输入数据中不会自然出现的特殊值, 然后只是依靠网络学习来忽略这个价值。
同样,多对一网络将在每个时间步长期间产生输出,但我们可以选择简单地忽略除最后一个时间步长之外的所有时间步的输出。在我们的图书销售预测示例中,我们告诉 Keras 通过隐式地将最后一个循环层的参数设置为(其默认值)来做到这一点。return_valuesFalse
最右边的同步多对多体系结构是微不足道的。我们在每个时间步长期间向网络提供输入,并在每个时间步长期间查看输出。图中的其他多对多体系结构不同,因为它可以具有与输入步骤不同数量的输出步骤。我们带有文本自动完成功能的编程示例就是此体系结构的一个示例。这种网络的一个设计选择是如何与网络通信输入序列已完成,以及网络在输出序列完成时如何通信。在我们的编程示例中,这是由用户隐式完成的,方法是在特定数量的字符后开始查看输出(并将其反馈到输入),然后在网络预测固定数量的字符后停止该过程。还有其他方法可以做到这一点(例如,通过教网络使用START和STOP令牌)。
关于使用 LSTM 自动完成文本的结论性意见
在本章中,我们用一个编程示例结束了对循环网络的介绍,该示例说明了如何使用基于 LSTM 的 RNN 来自动完成文本。这也是我们应用于自然语言处理(NLP)的网络的第一个例子,而不是图像数据和数字数据。这个编程示例以及书店销售预测示例的另一个有趣的方面是,我们创建了没有显式标记的训练示例。数据本身的顺序性质使得可以为每个训练示例自动创建基本事实。

















 4005
4005











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











