







🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
最后一章(结论和在线章节除外)看起来会有些不同。与前几章相比,它包含更多的代码和更少的散文。我们将在不讨论的情况下介绍新的 Python 关键字和库。本章旨在为您开启一个重要的研究项目。你看,我们将从头开始实现 fastai 和 PyTorch API 的许多关键部分,除了我们在第 17 章中开发的组件之外别无他物!这里的关键目标是结束你自己的Learner类和一些回调——足以在 Imagenette 上训练模型,包括我们研究过的每个关键技术的例子。在构建的过程中Learner,我们将创建我们自己的版本Module,Parameter和平行的DataLoader,所以你会很好地了解这些 PyTorch 类的作用。
章末问卷对于本章尤为重要。在这里,我们将以本章为起点,为您指明许多您可以采取的有趣方向。我们建议您在计算机上按照本章进行操作,并进行大量实验、网络搜索以及您需要了解的任何其他内容。您已经在本书的其余部分中积累了执行此操作的技能和专业知识,因此我们认为您会做得很好!
让我们从(手动)收集一些数据开始。
数据
查看源代码以untar_data了解其工作原理。 我们将在此处使用它来访问本章中使用的 160 像素版本的 Imagenette:
path = untar_data(URLs.IMAGENETTE_160)要访问图像文件,我们可以使用get_image_files:
t = get_image_files(path) t[0]Path('/home/jhoward/.fastai/data/imagenette2-160/val/n03417042/n03417042_3752.JP
> EG')
或者我们可以只使用 Python 的标准库来做同样的事情glob:
from glob import glob
files = L(glob(f'{path}/**/*.JPEG', recursive=True)).map(Path)
files[0]Path('/home/jhoward/.fastai/data/imagenette2-160/val/n03417042/n03417042_3752.JP
> EG')
如果您查看 的源代码get_image_files,您会发现它使用 Python 的os.walk; 这是一个比 更快更灵活的功能glob,所以一定要试试看。
我们可以使用 Python 图像库的 Image类打开图像:
im = Image.open(files[0])
im
im_t = tensor(im)im_t.shapetorch.Size([160, 213, 3])
这将是我们自变量的基础。对于我们的因变量,我们可以使用Path.parentfrom pathlib。首先我们需要我们的词汇
lbls = files.map(Self.parent.name()).unique(); lbls(#10) ['n03417042','n03445777','n03888257','n03394916','n02979186','n03000684','
> n03425413','n01440764','n03028079','n02102040']
和反向映射,感谢L.val2idx:
v2i = lbls.val2idx(); v2i{'n03417042': 0,
'n03445777':1,
'n03888257':2,
'n03394916':3,
'n02979186':4,
'n03000684':5,
'n03425413':6,
'n01440764':7,
'n03028079':8,
'n02102040': 9}
这就是我们将Dataset.
数据集
PyTorch 中的 ADataset可以是任何支持索引的东西 ( __getitem__) 和len:
class Dataset:
def __init__(self, fns): self.fns=fns
def __len__(self): return len(self.fns)
def __getitem__(self, i):
im = Image.open(self.fns[i]).resize((64,64)).convert('RGB')
y = v2i[self.fns[i].parent.name]
return tensor(im).float()/255, tensor(y)我们需要一个训练和验证文件名列表来传递给 Dataset.__init__:
train_filt = L(o.parent.parent.name=='train' for o in files)
train,valid = files[train_filt],files[~train_filt]
len(train),len(valid)(9469, 3925)
现在我们可以尝试一下:
train_ds,valid_ds = Dataset(train),Dataset(valid)
x,y = train_ds[0]
x.shape,y(torch.Size([64, 64, 3]), tensor(0))
show_image(x, title=lbls[y]);
如您所见,我们的数据集将自变量和因变量作为元组返回,这正是我们所需要的。我们需要能够将这些整理成一个小批量。通常,这是通过 完成的torch.stack,我们将在此处使用:
def collate(idxs, ds):
xb,yb = zip(*[ds[i] for i in idxs])
return torch.stack(xb),torch.stack(yb)这是一个包含两个项目的小批量,用于测试我们的 collate:
x,y = collate([1,2], train_ds)
x.shape,y(torch.Size([2, 64, 64, 3]), tensor([0, 0]))
现在我们有了一个数据集和一个整理函数,我们是 准备创建 DataLoader。我们将在此处添加另外两件事:shuffle训练集的可选内容,以及ProcessPoolExecutor 并行进行预处理的内容。并行数据加载器非常重要,因为打开和解码 JPEG 图像是一个缓慢的过程。一个 CPU 核心不足以足够快地解码图像以保持现代 GPU 忙碌。这是我们的DataLoader课程:
class DataLoader:
def __init__(self, ds, bs=128, shuffle=False, n_workers=1):
self.ds,self.bs,self.shuffle,self.n_workers = ds,bs,shuffle,n_workers
def __len__(self): return (len(self.ds)-1)//self.bs+1
def __iter__(self):
idxs = L.range(self.ds)
if self.shuffle: idxs = idxs.shuffle()
chunks = [idxs[n:n+self.bs] for n in range(0, len(self.ds), self.bs)]
with ProcessPoolExecutor(self.n_workers) as ex:
yield from ex.map(collate, chunks, ds=self.ds)让我们用我们的训练和验证数据集试试看:
n_workers = min(16, defaults.cpus)
train_dl = DataLoader(train_ds, bs=128, shuffle=True, n_workers=n_workers)
valid_dl = DataLoader(valid_ds, bs=256, shuffle=False, n_workers=n_workers)
xb,yb = first(train_dl)
xb.shape,yb.shape,len(train_dl)(torch.Size([128, 64, 64, 3]), torch.Size([128]), 74)
这个数据加载器并不比 PyTorch 的慢很多,但它要简单得多。因此,如果您正在调试复杂的数据加载过程,请不要害怕尝试手动执行操作以帮助您准确了解正在发生的事情。
对于规范化,我们需要图像统计信息。通常,在单个训练小批量上计算这些很好,因为这里不需要精度:
stats = [xb.mean((0,1,2)),xb.std((0,1,2))]
stats[tensor([0.4544, 0.4453, 0.4141]), tensor([0.2812, 0.2766, 0.2981])]
我们的Normalize班级只需要存储这些统计数据并应用它们(看看为什么to_device需要它,试着把它注释掉,然后看看这个笔记本后面会发生什么):
class Normalize:
def __init__(self, stats): self.stats=stats
def __call__(self, x):
if x.device != self.stats[0].device:
self.stats = to_device(self.stats, x.device)
return (x-self.stats[0])/self.stats[1]我们总是喜欢测试我们在笔记本中构建的所有内容,一旦我们构建它:
norm = Normalize(stats)
def tfm_x(x): return norm(x).permute((0,3,1,2))t = tfm_x(x)
t.mean((0,2,3)),t.std((0,2,3))(tensor([0.3732, 0.4907, 0.5633]), tensor([1.0212, 1.0311, 1.0131]))
这里tfm_x不仅应用了Normalize,而且还置换了轴顺序从NHWC到NCHW( 如果您需要提醒这些首字母缩写词指的是什么,请参阅第 13 章)。PIL 使用HWC轴顺序,我们不能将其与 PyTorch 一起使用,因此需要 this permute。
这就是我们模型所需的全部数据。所以现在我们需要模型本身!
模块和参数
要创建模型,我们需要Module. 要创建Module,我们需要Parameter,所以让我们从这里开始。 回想一下,在第 8 章中我们说过Parameter 该类“不添加任何功能(除了自动调用requires_grad_我们)”。它仅用作“标记”以显示要包含在中的内容 parameters。” 下面是一个定义,正是这样做的:
class Parameter(Tensor):
def __new__(self, x): return Tensor._make_subclass(Parameter, x, True)
def __init__(self, *args, **kwargs): self.requires_grad_()这里的实现有点笨拙:我们必须定义特殊的 __new__Python 方法并使用内部 PyTorch 方法 _make_subclass,因为在撰写本文时,PyTorch 不能以其他方式正确处理这种子类化或提供官方支持的 API 来做这个。这可能在您阅读本文时已经修复,因此请访问本书的网站以查看是否有更新的详细信息。
正如我们想要的那样,我们Parameter现在的行为就像一个张量:
Parameter(tensor(3.))tensor(3., requires_grad=True)
现在我们有了这个,我们可以定义Module:
class Module:
def __init__(self):
self.hook,self.params,self.children,self._training = None,[],[],False
def register_parameters(self, *ps): self.params += ps
def register_modules (self, *ms): self.children += ms
@property
def training(self): return self._training
@training.setter
def training(self,v):
self._training = v
for m in self.children: m.training=v
def parameters(self):
return self.params + sum([m.parameters() for m in self.children], [])
def __setattr__(self,k,v):
super().__setattr__(k,v)
if isinstance(v,Parameter): self.register_parameters(v)
if isinstance(v,Module): self.register_modules(v)
def __call__(self, *args, **kwargs):
res = self.forward(*args, **kwargs)
if self.hook is not None: self.hook(res, args)
return res
def cuda(self):
for p in self.parameters(): p.data = p.data.cuda()关键功能在以下定义中parameters:
self.params + sum([m.parameters() for m in self.children], [])这意味着我们可以向 any 询问Module它的参数,它会返回它们,包括它的所有子模块(递归)。但是它怎么知道它的参数是什么?这要归功于实现 Python 的特殊__setattr__方法,只要 Python 在类上设置属性,我们就会调用该方法。我们的实施包括这一行:
if isinstance(v,Parameter): self.register_parameters(v)如您所见,这是我们使用新Parameter类作为“标记”的地方——该类的任何内容都添加到我们的params.
Python__call__允许我们定义当我们的对象被视为函数时会发生什么;我们只是调用forward(这里不存在,因此需要由子类添加)。之后,如果已定义,我们将调用一个钩子。现在您可以看到 PyTorch 挂钩根本没有做任何花哨的事情——它们只是调用任何已 注册的挂钩。
除了这些功能之外,我们Module还提供 cuda和training属性,我们将很快使用它们。
现在我们可以创建我们的第一个Module,它是ConvLayer:
class ConvLayer(Module):
def __init__(self, ni, nf, stride=1, bias=True, act=True):
super().__init__()
self.w = Parameter(torch.zeros(nf,ni,3,3))
self.b = Parameter(torch.zeros(nf)) if bias else None
self.act,self.stride = act,stride
init = nn.init.kaiming_normal_ if act else nn.init.xavier_normal_
init(self.w)
def forward(self, x):
x = F.conv2d(x, self.w, self.b, stride=self.stride, padding=1)
if self.act: x = F.relu(x)
return x我们不是F.conv2d从头开始实施,因为您应该已经在第 17 章unfold的调查问卷中完成(使用) 。相反,我们只是创建一个小类,将其与偏差和权重初始化一起包装起来。让我们检查它是否可以正常工作 Module.parameters:
l = ConvLayer(3, 4)
len(l.parameters())2
我们可以调用它(这将导致forward被调用):
xbt = tfm_x(xb)
r = l(xbt)
r.shapetorch.Size([128, 4, 64, 64])
同样的,我们可以实现Linear:
class Linear(Module):
def __init__(self, ni, nf):
super().__init__()
self.w = Parameter(torch.zeros(nf,ni))
self.b = Parameter(torch.zeros(nf))
nn.init.xavier_normal_(self.w)
def forward(self, x): return x@self.w.t() + self.b
并测试它是否有效:
l = Linear(4,2)
r = l(torch.ones(3,4))
r.shapetorch.Size([3, 2])
我们还创建一个测试模块来检查我们是否包含多个参数作为属性,它们是否都已正确注册:
class T(Module):
def __init__(self):
super().__init__()
self.c,self.l = ConvLayer(3,4),Linear(4,2)由于我们有一个转换层和一个线性层,每个层都有权重和偏差,所以我们总共需要四个参数:t =
t = T()
len(t.parameters())4
我们还应该发现调用cuda此类会将所有这些参数放在 GPU 上:
t.cuda()t.l.w.devicedevice(type='cuda', index=5)
简单的CNN
正如我们所见,一个Sequential类使许多架构更容易实现,所以让我们做一个:
class Sequential(Module):
def __init__(self, *layers):
super().__init__()
self.layers = layers
self.register_modules(*layers)
def forward(self, x):
for l in self.layers: x = l(x)
return x这里的forward方法只是依次调用每一层。请注意,我们必须使用register_modules我们在 中定义的方法Module,否则 的内容 layers将不会出现在 中 parameters。
请记住,我们在这里没有为模块使用任何 PyTorch 功能;我们自己定义一切。因此,如果您不确定是做什么
register_modules的,或者为什么需要它,请再看看我们的代码,Module看看我们写了什么!
我们可以创建一个简化AdaptivePool的,只处理池化到 1×1 的输出,并将其展平,只需使用mean:
class AdaptivePool(Module):
def forward(self, x): return x.mean((2,3))这足以让我们创建一个 CNN!
def simple_cnn():
return Sequential(
ConvLayer(3 ,16 ,stride=2), #32
ConvLayer(16,32 ,stride=2), #16
ConvLayer(32,64 ,stride=2), # 8
ConvLayer(64,128,stride=2), # 4
AdaptivePool(),
Linear(128, 10)
)让我们看看我们的参数是否都被正确注册:
m = simple_cnn()
len(m.parameters())10
现在我们可以尝试添加一个钩子。请注意,我们只为一个钩子留了空间 Module;你可以把它做成一个列表,或者使用类似的东西Pipeline将几个作为一个函数运行:
def print_stats(outp, inp): print (outp.mean().item(),outp.std().item())
for i in range(4): m.layers[i].hook = print_stats
r = m(xbt)
r.shape0.5239089727401733 0.8776043057441711 0.43470510840415955 0.8347987532615662 0.4357188045978546 0.7621666193008423 0.46562111377716064 0.7416611313819885 torch.Size([128, 10])
我们有数据和模型。现在我们需要一个损失函数。
Loss
def nll(input, target): return -input[range(target.shape[0]), target].mean()实际上,这里没有日志,因为我们使用的是与 PyTorch 相同的定义。这意味着我们需要将日志与 softmax 放在一起:
def log_softmax(x): return (x.exp()/(x.exp().sum(-1,keepdim=True))).log()
sm = log_softmax(r); sm[0][0]tensor(-1.2790, grad_fn=<SelectBackward>)
结合这些给我们我们的交叉熵损失:
loss = nll(sm, yb)
losstensor(2.5666, grad_fn=<NegBackward>)
注意公式
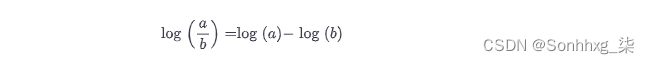
当我们计算 log softmax 时,给出了一个简化,它之前被定义为(x.exp()/(x.exp().sum(-1))).log():
def log_softmax(x): return x - x.exp().sum(-1,keepdim=True).log()
sm = log_softmax(r); sm[0][0]tensor(-1.2790, grad_fn=<SelectBackward>)
然后,有一种更稳定的方法来计算指数和的对数,称为 LogSumExp技巧。这个想法是使用以下公式
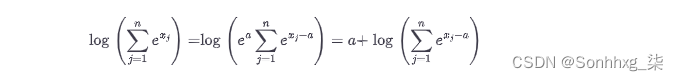
其中a是最大值Xj.
这是代码中的相同内容:
x = torch.rand(5)
a = x.max()
x.exp().sum().log() == a + (x-a).exp().sum().log()tensor(True)
我们将把它放入一个函数中
def logsumexp(x):
m = x.max(-1)[0]
return m + (x-m[:,None]).exp().sum(-1).log()
logsumexp(r)[0]tensor(3.9784, grad_fn=<SelectBackward>)
所以我们可以将它用于我们的log_softmax功能:
def log_softmax(x): return x - x.logsumexp(-1,keepdim=True)这给出了与以前相同的结果:
sm = log_softmax(r); sm[0][0]tensor(-1.2790, grad_fn=<SelectBackward>)
我们可以使用这些来创建cross_entropy:
def cross_entropy(preds, yb): return nll(log_softmax(preds), yb).mean()现在让我们将所有这些部分组合起来创建一个 Learner.
Learner
我们有数据、模型和损失函数;在拟合模型之前,我们只需要再做一件事,那就是优化器!这是新加坡元:
class SGD:
def __init__(self, params, lr, wd=0.): store_attr(self, 'params,lr,wd')
def step(self):
for p in self.params:
p.data -= (p.grad.data + p.data*self.wd) * self.lr
p.grad.data.zero_()正如我们在本书中所见,有了Learner. Learner需要知道我们的训练和验证集,这意味着我们需要存储DataLoaders它们。我们不需要任何其他功能,只需要一个存储和访问它们的地方:
class DataLoaders:
def __init__(self, *dls): self.train,self.valid = dls
dls = DataLoaders(train_dl,valid_dl)class Learner:
def __init__(self, model, dls, loss_func, lr, cbs, opt_func=SGD):
store_attr(self, 'model,dls,loss_func,lr,cbs,opt_func')
for cb in cbs: cb.learner = self def one_batch(self):
self('before_batch')
xb,yb = self.batch
self.preds = self.model(xb)
self.loss = self.loss_func(self.preds, yb)
if self.model.training:
self.loss.backward()
self.opt.step()
self('after_batch')
def one_epoch(self, train):
self.model.training = train
self('before_epoch')
dl = self.dls.train if train else self.dls.valid
for self.num,self.batch in enumerate(progress_bar(dl, leave=False)):
self.one_batch()
self('after_epoch')
def fit(self, n_epochs):
self('before_fit')
self.opt = self.opt_func(self.model.parameters(), self.lr)
self.n_epochs = n_epochs
try:
for self.epoch in range(n_epochs):
self.one_epoch(True)
self.one_epoch(False)
except CancelFitException: pass
self('after_fit')
def __call__(self,name):
for cb in self.cbs: getattr(cb,name,noop)()这是我们在本书中创建的最大的类,但每个方法都非常小,因此通过依次查看每个方法,您应该能够了解发生了什么。
我们将调用的主要方法是fit. 这循环与
for self.epoch in range(n_epochs)并且在每个时代要求self.one_epoch每个train=True然后train=False。然后在dls.train或者dls.valid中self.one_epoch调用self.one_batch每个批次(在包装DataLoader在 progress.progress_bar之后)。最后, self.one_batch按照我们在本书中看到的一组常用步骤来拟合一个小批量。
在每个步骤之前和之后,Learner调用self,调用 __call__(这是标准的 Python 功能)。在self.cbs 中的每个回调上__call__使用 getattr(cb,name),这是一个 Python 内置函数,它返回具有请求名称的属性(在本例中为方法)。因此,例如,self('before_fit') 将调用 cb.before_fit()定义该方法的每个回调。
如您所见,Learner实际上只是在使用我们的标准训练循环,只是它还在适当的时间调用回调。所以让我们定义一些回调!
Callbacks(回调)
for cb in cbs: cb.learner = self换句话说,每个回调都知道它在哪个学习者中使用。这很关键,否则回调无法从学习者那里获取信息,或改变学习者的内容。因为从学习者那里获取信息是如此普遍,我们通过定义Callback为 的子类来简化这一过程GetAttr,默认属性为learner:
class Callback(GetAttr): _default='learner'GetAttr__getattr__是一个为您实现 Python 标准和方法的 fastai 类__dir__,因此无论何时您尝试访问不存在的属性,它都会将请求传递给您定义为_default.
例如,我们希望在 的开始自动将所有模型参数移动到 GPU fit。我们可以通过定义 before_fit为来做到这一点self.learner.model.cuda;但是,因为learner 是默认属性,而且我们SetupLearnerCB继承自 Callback(继承自GetAttr),我们可以删除.learner 并调用self.model.cuda:
class SetupLearnerCB(Callback):
def before_batch(self):
xb,yb = to_device(self.batch)
self.learner.batch = tfm_x(xb),yb
def before_fit(self): self.model.cuda()在SetupLearnerCB中,我们还通过调用 to_device(self.batch)(我们也可以使用更长 的 )将每个小批量移动到 GPU to_device(self.learner.batch)。但是请注意,在行 self.learner.batch = tfm_x(xb),yb中,我们不能删除 .learner,因为这里我们设置属性,而不是它。
在我们尝试之前Learner,让我们创建一个回调来跟踪和打印进度。否则,我们不会真正知道它是否正常工作:
class TrackResults(Callback):
def before_epoch(self): self.accs,self.losses,self.ns = [],[],[]
def after_epoch(self):
n = sum(self.ns)
print(self.epoch, self.model.training,
sum(self.losses).item()/n, sum(self.accs).item()/n)
def after_batch(self):
xb,yb = self.batch
acc = (self.preds.argmax(dim=1)==yb).float().sum()
self.accs.append(acc)
n = len(xb)
self.losses.append(self.loss*n)
self.ns.append(n)现在我们准备好Learner第一次使用我们的了!
cbs = [SetupLearnerCB(),TrackResults()]
learn = Learner(simple_cnn(), dls, cross_entropy, lr=0.1, cbs=cbs)
learn.fit(1)0 True 2.1275552130636814 0.2314922378287042 0 False 1.9942575636942674 0.2991082802547771
意识到我们可以Learner用这么少的代码实现 fastai 的所有关键思想,真是太神奇了!现在让我们添加一些学习率调度。
安排学习率
如果我们要获得好的结果,我们将需要 LR finder 和 1cycle 训练。这些都是退火 回调——也就是说,它们随着我们逐渐改变超参数 火车。这是LRFinder:
class LRFinder(Callback):
def before_fit(self):
self.losses,self.lrs = [],[]
self.learner.lr = 1e-6
def before_batch(self):
if not self.model.training: return
self.opt.lr *= 1.2
def after_batch(self):
if not self.model.training: return
if self.opt.lr>10 or torch.isnan(self.loss): raise CancelFitException
self.losses.append(self.loss.item())
self.lrs.append(self.opt.lr)这显示了我们如何使用CancelFitException,它本身是一个空类,仅用于表示异常类型。你可以看到Learner这个异常被捕获了。(您应该自己添加和测试CancelBatchException、CancelEpochException等。)让我们尝试一下,将其添加到我们的回调列表中:
lrfind = LRFinder()
learn = Learner(simple_cnn(), dls, cross_entropy, lr=0.1, cbs=cbs+[lrfind])
learn.fit(2)0 True 2.6336045582954903 0.11014890695955222 0 False 2.230653363853503 0.18318471337579617
看看结果:
plt.plot(lrfind.lrs[:-2],lrfind.losses[:-2])
plt.xscale('log')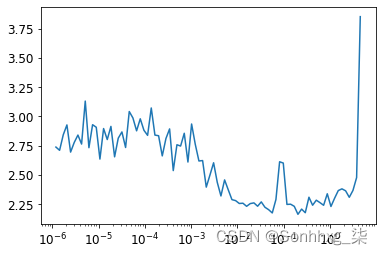
现在我们可以定义我们的OneCycle训练回调:
class OneCycle(Callback):
def __init__(self, base_lr): self.base_lr = base_lr
def before_fit(self): self.lrs = []
def before_batch(self):
if not self.model.training: return
n = len(self.dls.train)
bn = self.epoch*n + self.num
mn = self.n_epochs*n
pct = bn/mn
pct_start,div_start = 0.25,10
if pct<pct_start:
pct /= pct_start
lr = (1-pct)*self.base_lr/div_start + pct*self.base_lr
else:
pct = (pct-pct_start)/(1-pct_start)
lr = (1-pct)*self.base_lr
self.opt.lr = lr
self.lrs.append(lr)我们将尝试 0.1 的 LR:
onecyc = OneCycle(0.1)
learn = Learner(simple_cnn(), dls, cross_entropy, lr=0.1, cbs=cbs+[onecyc])让我们适应一下,看看它看起来如何(我们不会在书中展示所有输出——在笔记本中尝试一下以查看结果):
learn.fit(8)最后,我们将检查学习率是否遵循我们定义的时间表(如您所见,我们在这里没有使用余弦退火):
plt.plot(onecyc.lrs);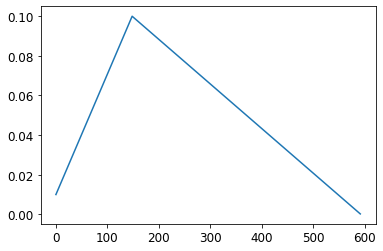
结论
在本章中,我们通过重新实现 fastai 库的关键概念来探索它们是如何实现的。由于它大部分都是代码,你绝对应该通过查看本书网站上的相应笔记本来尝试对它进行试验。现在您知道它是如何构建的,下一步一定要查看 fastai 文档中的中级和高级教程,以了解如何自定义库的每一部分。

















 586
586











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











