






在英伟达官网(https://www.nvidia.cn/autonomous-machines/embedded-systems/jetson-orin/)和各处的宣传里,对Jetson AGX Orin 均提到了275T的性能:
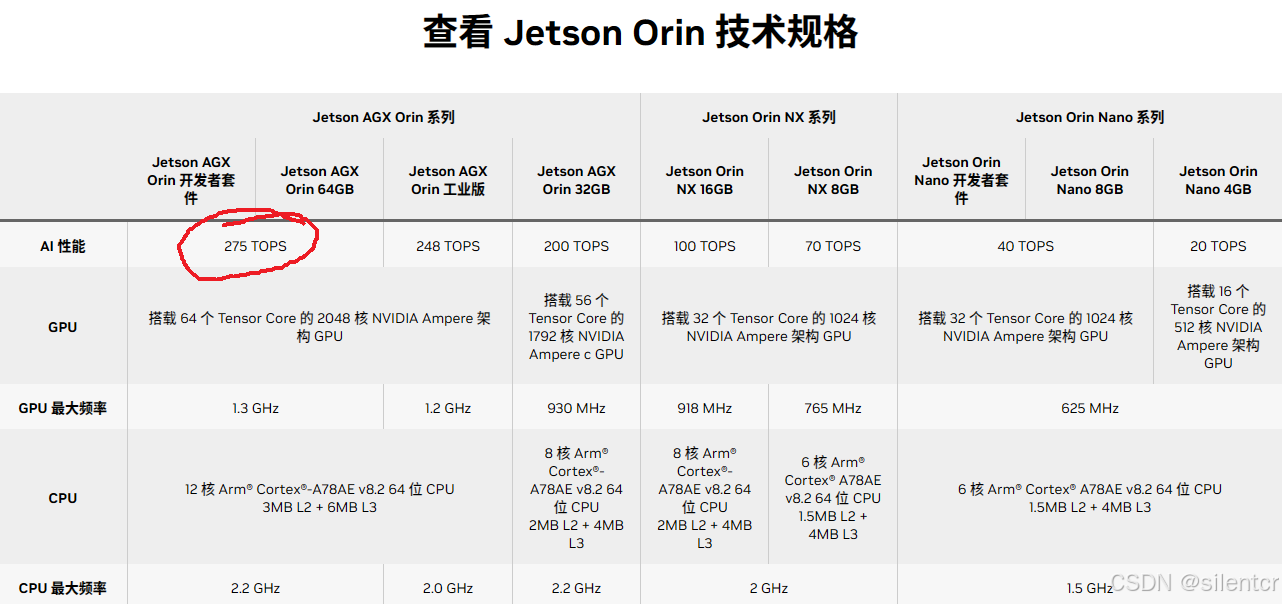
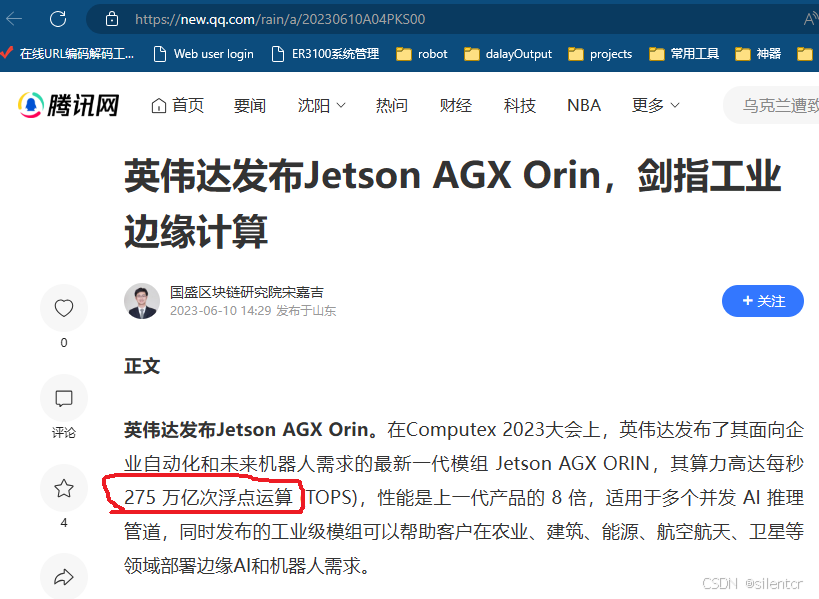
但较少有描述在275T的由来,以至于部分介绍竟然出现了275T的浮点运算:
而实际上,在官网页面的下方,有一个不起眼的按钮,点击之后,才能看到更加具体的描述:
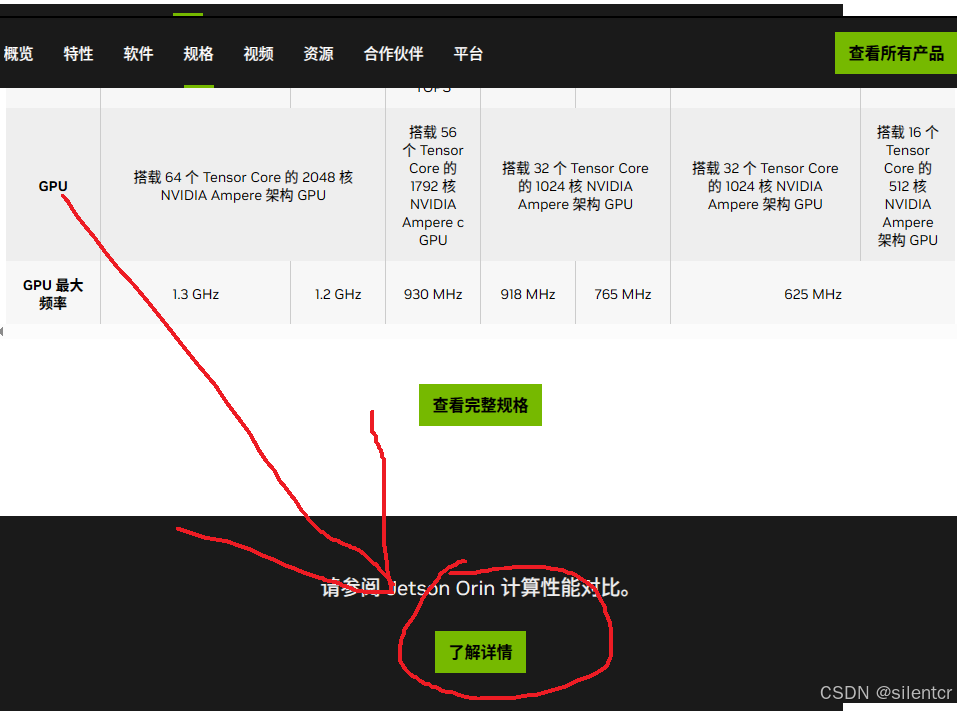
弹出窗口如下:
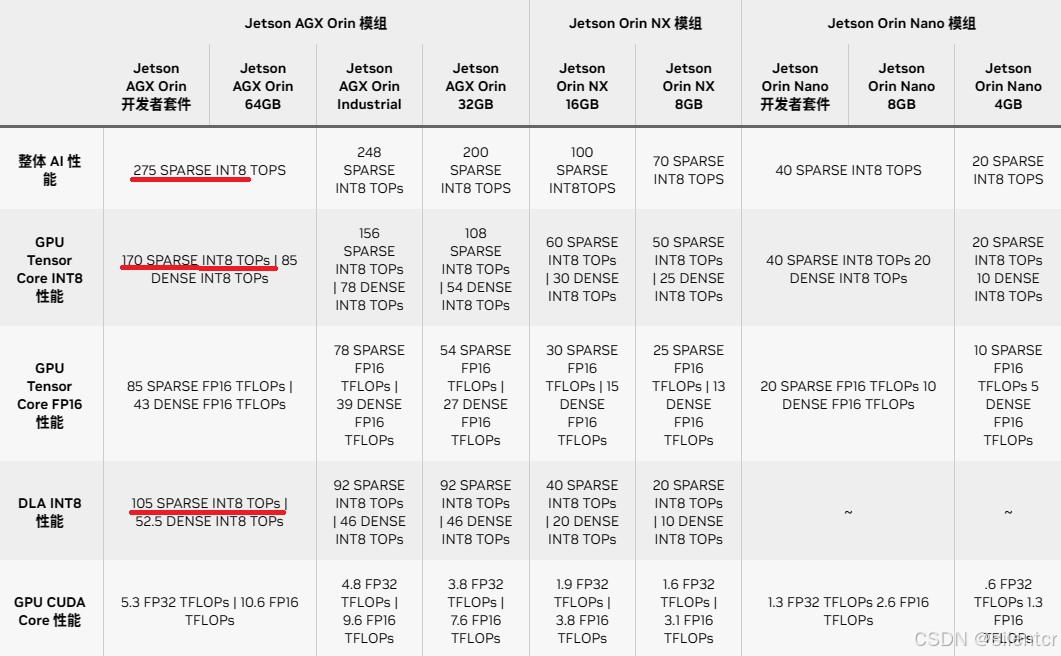
由图可见,很显然,这275TOPS的性能,仅仅是在INT8下的稀疏矩阵运算(SPARSE)情况下得到的。
在稀疏(SPARSE)且INT8情况下,Tensor Core的性能是170T,加上DLA的105T,正好是275TOPS。
如果是密集(DENSE)情况下,只能达到85+52.5=137.5T的性能,还是INT8的精度。
TensorCore如果进行16位浮点运算(FP16),还要在INT8的基础上再次腰斩。
看来,对于硬件的宣传的确是加入了相当多的迷惑性。
如果想发挥出硬件的全部性能,算法上还是需要进行相当程度的优化的。

















 659
659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









