







基于Fisher判别的线性分类
一、何为Fisher判别?
1. Fisher判别法原理介绍
Fisher判别法是判别分析的方法之一,它是借助于方差分析的思想,利用已知各总体抽取的样品的p维观察值构造一个或多个线性判别函数y=l′x其中l= (l1,l2…lp)′,x= (x1,x2,…,xp)′,使不同总体之间的离差(记为B)尽可能地大,而同一总体内的离差(记为E)尽可能地小来确定判别系数l=(l1,l2…lp)′。数学上证明判别系数l恰好是|B-λE|=0的特征根,记为λ1≥λ2≥…≥λr>0。所对应的特征向量记为l1,l2,…lr,则可写出多个相应的线性判别函数,在有些问题中,仅用一个λ1对应的特征向量l1所构成线性判别函数y1=l′1x不能很好区分各个总体时,可取λ2对应的特征向量l′2建立第二个线性判别函数y2=l′2x,如还不够,依此类推。有了判别函数,再人为规定一个分类原则(有加权法和不加权法等)就可对新样品x判别所属
2. Fisher线性判别基本思想
Fisher线性判别分析的基本思想:选择一个投影方向(线性变换,线性组合),将高维问题降低到一维问题来解决,同时变换后的一维数据满足每一类内部的样本尽可能聚集在一起,不同类的样本相隔尽可能地远。
线性判别函数的一般形式可表示成
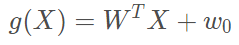
其中
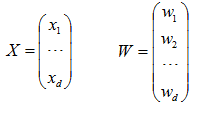
Fisher选择投影方向W的原则,即使原样本向量在该方向上的投影能兼顾类间分布尽可能分开,类内样本投影尽可能密集的要求。
3. “群内离散度”与“群间离散度”
“群内离散度”要求的是距离越远越好;而“群间离散度”的距离越近越好。
“群内离散度”(样本类内离散矩阵)的计算公式为
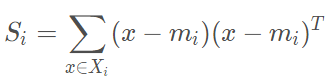
因为每一个样本有多维数据,因此需要将每一维数据代入公式计算后最后在求和即可得到样本类内离散矩阵。存在多个样本,重复该计算公式即可算出每一个样本的类内离散矩阵。
“群间离散度”(总体类离散度矩阵)的计算公式为
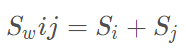
二、python代码实现推导
#导入包
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
#导入数据集
df = pd.read_csv("./iris.data", header=0)
Iris1=df.values[0:50,0:4]
Iris2=df.values[50:100,0:4]
Iris3=df.values[100:150,0:4]
#定义类均值向量
m1=np.mean(Iris1,axis=0)
m2=np.mean(Iris2,axis=0)
m3=np.mean(Iris3,axis=0)
#定义类内离散度矩阵
s1=np.zeros((4,4))
s2=np.zeros((4,4))
s3=np.zeros((4,4))
for i in range(0,30,1):
a=Iris1[i,:]-m1
a=np.array([a])
b=a.T
s1=s1+np.dot(b,a)
for i in range(0,30,1):
c=Iris2[i,:]-m2
c=np.array([c])
d=c.T
s2=s2+np.dot(d,c)
#s2=s2+np.dot((Iris2[i,:]-m2).T,(Iris2[i,:]-m2))
for i in range(0,30,1):
a=Iris3[i,:]-m3
a=np.array([a])
b=a.T
s3=s3+np.dot(b,a)
#定义总类内离散矩阵
sw12 = s1 + s2;
sw13 = s1 + s3;
sw23 = s2 + s3;
#定义投影方向
a=np.array([m1-m2])
sw12=np.array(sw12,dtype='float')
sw13=np.array(sw13,dtype='float')
sw23=np.array(sw23,dtype='float')
#判别函数以及阈值T(即w0)
a=m1-m2
a=np.array([a])
a=a.T
b=m1-m3
b=np.array([b])
b=b.T
c 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1233
1233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









