







流程图
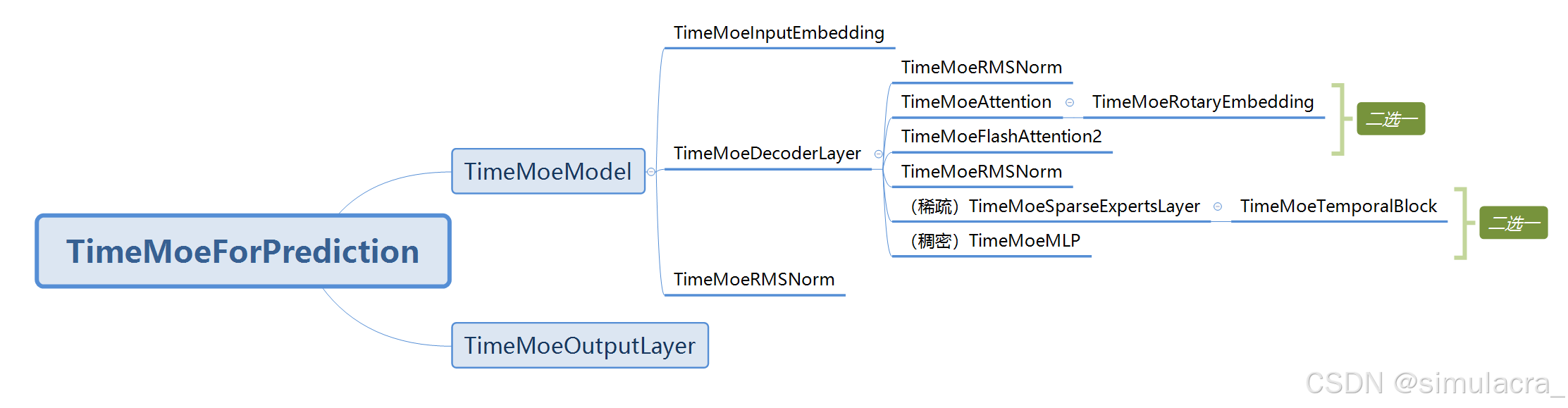
TimeMoe的核心模型的代码在文件夹models的modeling_time_moe.py文件中,下图为该文件中的实现该模型的核心类之间的调用图:
github:
Time-MoE/Time-MoE: Time-MoE: Billion-Scale Time Series Foundation Models with Mixture of Experts
hugging face:
Maple728/TimeMoE-200M · Hugging Face
TimeMoeTemporalBlock
class TimeMoeTemporalBlock(nn.Module):
def __init__(self, hidden_size: int, intermediate_size: int, hidden_act: str):
super().__init__()
self.hidden_size = hidden_size
self.intermediate_size = intermediate_size
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
self.act_fn = ACT2FN[hidden_act]
def forward(self, hidden_state):
return self.down_proj(self.act_fn(self.gate_proj(hidden_state)) * self.up_proj(hidden_state))TimeMoe模型的专家模块:
- gate_proj:这是一个线性层,用来将输入隐藏状态映射到一个中间维度 intermediate_size。
- up_proj:这是另一个线性层,用于通过另一个线性变换将输入隐藏状态映射到 intermediate_size。
- down_proj:这是将经过激活函数处理后的输出映射回原来的维度(即 hidden_size)。
TimeMoeSparseExpertsLayer
该类是核心模块之一,负责处理模型中的 Mixture-of-Experts(MoE)机制,MoE 是一种稀疏计算方法,目标是通过激活少量的专家神经网络来减少计算量,而保持较高的模型容量。
class TimeMoeSparseExpertsLayer(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.top_k = config.num_experts_per_tok
self.hidden_size = config.hidden_size
self.num_experts = config.num_experts
self.norm_topk_prob = False
moe_intermediate_size = self.config.intermediate_size // self.top_k
# gating
self.gate = nn.Linear(config.hidden_size, config.num_experts, bias=False)
self.experts = nn.ModuleList(
[TimeMoeTemporalBlock(
hidden_size=self.config.hidden_size,
intermediate_size=moe_intermediate_size,
hidden_act=self.config.hidden_act,
) for _ in range(self.num_experts)]
)
self.shared_expert = TimeMoeTemporalBlock(
hidden_size=self.config.hidden_size,
intermediate_size=self.config.intermediate_size,
hidden_act=self.config.hidden_act,
)
self.shared_expert_gate = torch.nn.Linear(config.hidden_size, 1, bias=False)
def forward(self, hidden_states: torch.Tensor):
""" """
batch_size, sequence_length, hidden_dim = hidden_states.shape
hidden_states = hidden_states.view(-1, hidden_dim)
# router_logits -> (batch * sequence_length, n_experts)
router_logits = self.gate(hidden_states)
routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float)
routing_weights, selected_experts = torch.topk(routing_weights, self.top_k, dim=-1)
if self.norm_topk_prob:
routing_weights /= routing_weights.sum(dim=-1, keepdim=True)
# we cast back to the input dtype
routing_weights = routing_weights.to(hidden_states.dtype)
final_hidden_states = torch.zeros(
(batch_size * sequence_length, hidden_dim), dtype=hidden_states.dtype, device=hidden_states.device
)
# One hot encode the selected experts to create an expert mask
# this will be used to easily index which expert is going to be sollicitated
expert_mask = torch.nn.functional.one_hot(selected_experts, num_classes=self.num_experts).permute(2, 1, 0)
# Loop over all available experts in the model and perform the computation on each expert
for expert_idx in range(self.num_experts):
expert_layer = self.experts[expert_idx]
idx, top_x = torch.where(expert_mask[expert_idx])
# Index the correct hidden states and compute the expert hidden state for
# the current expert. We need to make sure to multiply the output hidden
# states by `routing_weights` on the corresponding tokens (top-1 and top-2)
current_state = hidden_states[None, top_x].reshape(-1, hidden_dim)
current_hidden_states = expert_layer(current_state) * routing_weights[top_x, idx, None]
# However `index_add_` only support torch tensors for indexing so we'll use
# the `top_x` tensor here.
final_hidden_states.index_add_(0, top_x, current_hidden_states.to(hidden_states.dtype))
shared_expert_output = self.shared_expert(hidden_states)
shared_expert_output = F.sigmoid(self.shared_expert_gate(hidden_states)) * shared_expert_output
final_hidden_states = final_hidden_states + shared_expert_output
final_hidden_states = final_hidden_states.reshape(batch_size, sequence_length, hidden_dim)
return final_hidden_states, router_logits初始化
- 门控网络 (self.gate):对隐藏状态进行映射,生成每个专家的“路由logits”。
- 专家网络 (self.experts):每个专家是一个TimeMoeTemporalBlock,这些专家网络通过不同的路径对输入数据进行处理。
- 共享专家 (self.shared_expert):除了通过gate选择的专家外,还有一个共享专家用于捕获通用知识。
- 共享专家门控网络 (self.shared_expert_gate):声称共享专家的权重。
前向传播
路由计算
router_logits = self.gate(hidden_states)
routing_weights = F.softmax(router_logits, dim=1, dtype=torch.float)
routing_weights, selected_experts = torch.topk(routing_weights, self.top_k, dim=-1)- 计算路由 logits:通过
self.gate对输入进行线性变换,生成每个专家的路由 logits,然后做softmax处理。 - 选择激活的专家:使用
torch.topk选择top_k个最活跃的专家,并计算路由权重,得到的routing_weights和selected_experts形状为 (batch_size * sequence_length, top_k)
初始化最终隐藏状态并构造专家掩码
final_hidden_states = torch.zeros(
(batch_size * sequence_length, hidden_dim), dtype=hidden_states.dtype, device=hidden_states.device
)
expert_mask = torch.nn.functional.one_hot(selected_experts,num_classes=self.num_experts).permute(2, 1, 0)final_hidden_states是最终的隐藏状态初始化为零张量,并将 selected_experts 转换为 one-hot 编码,表示每个 token 对应的top_k专家在哪些位置。它的形状是(batch_size * sequence_length, top_k, num_experts)。
遍历每个专家
是每个时间步分别选择路由权重最高的top_k个专家网络进行处理并进行加权求和,而不是只选择部分专家模型,理论上每个专家模型都会处理部分时间步。同时会有一个全局的共享专家参与所有时间步的处理,确保全局信息建模能力 。
我们假设未经处理的hidden_states的大小为(1,6,3),num_experts=6,top_k=4:
hidden_states = torch.tensor([[[ 1.0, 2.0, 3.0],
[ 4.0, 5.0, 6.0],
[ 7.0, 8.0, 9.0],
[10.0, 11.0, 12.0],
[13.0, 14.0, 15.0],
[16.0, 17.0, 18.0]]]) # 形状为 (1, 6, 3)取num_experts=6,假设初始routing_weights的值为:
routing_weights = torch.tensor([[0.15, 0.25, 0.10, 0.10, 0.30, 0.10],
[0.05, 0.15, 0.15, 0.25, 0.40, 0.20],
[0.10, 0.15, 0.10, 0.35, 0.30, 0.25],
[0.30, 0.25, 0.20, 0.25, 0.25, 0.10],
[0.10, 0.20, 0.35, 0.30, 0.35, 0.10],
[0.05, 0.30, 0.15, 0.30, 0.35, 0.40]])取 top_k=4,则selected_experts的值为:
selected_experts= torch.tensor([[4, 1, 0, 2],
[4, 3, 5, 1],
[3, 4, 5, 1],
[0, 1, 3, 4],
[2, 4, 3, 1],
[5, 4, 1, 3]])for循环以expert_idx=0时为例:
idx, top_x = torch.where(expert_mask[expert_idx])则expert_mask[0]为:
expert_mask[0]= torch.tensor([[0, 0, 0, 1, 0, 0],
[0, 0, 0, 0, 0, 0],
[1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0]])idx表示对应专家的位置,top_x 表示对应时间步的选择。,在示例中两者的值为:
idx: tensor([0, 2])
top_x: tensor([3, 0])通过 top_x 索引出选择了该专家的 token 对应的 hidden_states,并 reshape 为适合输入的形状。:
current_state = hidden_states[None, top_x].reshape(-1, hidden_dim)在示例中,可能激活专家0的为时间步0和3,即:
current_state = torch.tensor([[10., 11., 12.],
[ 1., 2., 3.]])将得到的 current_state 输入到专家0中并将得到的结果与时间步0和3激活专家0的概率相乘得到current_hidden_states ,并将结果添加进最终输出final_hidden_states中:
current_hidden_states = expert_layer(current_state) * routing_weights[top_x, idx, None]
final_hidden_states.index_add_(0, top_x, current_hidden_states.to(hidden_states.dtype))共享专家和最终输出
共享专家对所有的 token 都进行统一处理,输出通过 shared_expert_gate 加权:
shared_expert_output = self.shared_expert(hidden_states)
shared_expert_output = F.sigmoid(self.shared_expert_gate(hidden_states)) * shared_expert_output最终的 final_hidden_states 是所有专家的输出加上共享专家的输出:
final_hidden_states = final_hidden_states + shared_expert_output
final_hidden_states = final_hidden_states.reshape(batch_size, sequence_length, hidden_dim)TimeMoeDecoderLayer
class TimeMoeDecoderLayer(nn.Module):
def __init__(self, config: TimeMoeConfig, layer_idx: int):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.self_attn = TIME_MOE_ATTENTION_CLASSES[config._attn_implementation](config, layer_idx)
if self.config.use_dense:
self.ffn_layer = TimeMoeMLP(
hidden_size=self.config.hidden_size,
intermediate_size=self.config.intermediate_size,
hidden_act=self.config.hidden_act,
)
else:
self.ffn_layer = TimeMoeSparseExpertsLayer(config)
self.input_layernorm = TimeMoeRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
self.post_attention_layernorm = TimeMoeRMSNorm(config.hidden_size, eps=config.rms_norm_eps)
def forward(
self,
hidden_states: torch.Tensor,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_value: Optional[Tuple[torch.Tensor]] = None,
output_attentions: Optional[bool] = False,
use_cache: Optional[bool] = False,
**kwargs,
) -> Tuple[torch.FloatTensor, torch.FloatTensor, Optional[torch.FloatTensor], Optional[torch.FloatTensor]]:
if "padding_mask" in kwargs:
warnings.warn(
"Passing `padding_mask` is deprecated and will be removed in v4.37. "
"Please make sure use `attention_mask` instead.`"
)
"""
Args:
hidden_states (`torch.FloatTensor`): input to the layer of shape `(batch, seq_len, embed_dim)`
attention_mask (`torch.FloatTensor`, *optional*): attention mask of size
`(batch, sequence_length)` where padding elements are indicated by 0.
output_attentions (`bool`, *optional*):
Whether or not to return the attentions tensors of all attention layers. See `attentions` under
returned tensors for more detail.
use_cache (`bool`, *optional*):
If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding
(see `past_key_values`).
past_key_value (`Tuple(torch.FloatTensor)`, *optional*): cached past key and value projection states
"""
residual = hidden_states
hidden_states = self.input_layernorm(hidden_states)
# Self Attention
hidden_states, self_attn_weights, present_key_value = self.self_attn(
hidden_states=hidden_states,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_value=past_key_value,
output_attentions=output_attentions,
use_cache=use_cache,
)
hidden_states = residual + hidden_states
# Fully Connected
residual = hidden_states
hidden_states = self.post_attention_layernorm(hidden_states)
hidden_states, router_logits = self.ffn_layer(hidden_states)
hidden_states = residual + hidden_states
if not output_attentions:
self_attn_weights = None
if not use_cache:
present_key_value = None
return hidden_states, self_attn_weights, present_key_value, router_logits
由归一化层、自注意力层和全连接层组成:
归一化层:使用 TimeMoeRMSNorm类对输入进行规范化处理,该类采用均方根(Root Mean Square)规范化方法。TimeMoeRMSNorm的具体代码如下:
class TimeMoeRMSNorm(torch.nn.Module):
def __init__(self, hidden_size, eps=1e-6):
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps
def forward(self, hidden_states):
input_dtype = hidden_states.dtype
hidden_states = hidden_states.to(torch.float32)
variance = hidden_states.pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
return self.weight * hidden_states.to(input_dtype)自注意力层:自注意力机制会处理序列中每个时间步与其他时间步之间的关系,可以根据项目需求和实际情况选择是采用TimeMoeAttention还是TimeMoeFlashAttention2(加速计算过程)进行注意力计算。
全连接层:若选择稀疏结构则用MoE网络替换ffn_layer。
TimeMoeModel
是模型的核心实现,由嵌入层、解码器层和归一化层组成。
TimeMoeInputEmbedding(嵌入层)
self.embed_layer = TimeMoeInputEmbedding(config)
TimeMoeModel类的输入首先会经过嵌入层将其转换为一个高维嵌入表示,输出的形状是 [batch_size, seq_len, hidden_size],hidden_size 是模型的隐藏层维度,TimeMoeInputEmbedding类的具体代码如下:
class TimeMoeInputEmbedding(nn.Module):
"""
Use a mlp layer to embedding the time-series.
"""
def __init__(self, config: TimeMoeConfig):
super().__init__()
self.config = config
self.input_size = config.input_size # default 1
self.hidden_size = config.hidden_size
self.emb_layer = nn.Linear(self.input_size, self.hidden_size, bias=False)
self.gate_layer = nn.Linear(self.input_size, self.hidden_size, bias=False)
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x):
emb = self.act_fn(self.gate_layer(x)) * self.emb_layer(x)
return emb解码器层
self.layers = nn.ModuleList(
[TimeMoeDecoderLayer(config, layer_idx) for layer_idx in range(config.num_hidden_layers)]
)经过嵌入层处理后的输入被送入由layer_idx个TimeMoeDecoderLayer组成的解码器层中,且每一层的输出都是 [batch_size, seq_len, hidden_size]。
TimeMoeRMSNorm(归一化层)
self.norm = TimeMoeRMSNorm(config.hidden_size, eps=config.rms_norm_eps)hidden_states 在通过解码器层之后,将进入归一化层对最后的隐藏状态进行规范化处理,以提高训练稳定性并加速收敛,得到形状为 (batch_size, seq_length, hidden_size) 的结果。
TimeMoeForPrediction
TimeMoe模型的主体,基于MoE和Transformer 架构。在这个类中,输入数据经过解码器、预测层、损失计算等层级的处理。
初始化
def __init__(self, config: TimeMoeConfig):
super().__init__(config)
self.config = config
self.apply_aux_loss = config.apply_aux_loss
self.num_experts_per_tok = config.num_experts_per_tok
self.router_aux_loss_factor = config.router_aux_loss_factor
self.model = TimeMoeModel(config)
# output layer
lm_head_list = []
self.horizon_length_map = {}
for i, horizon_length in enumerate(config.horizon_lengths):
lm_head_list.append(
TimeMoeOutputLayer(
hidden_size=self.config.hidden_size,
input_size=self.config.input_size,
horizon_length=horizon_length,
)
)
self.horizon_length_map[horizon_length] = i
self.lm_heads = nn.ModuleList(lm_head_list)
self.loss_function = torch.nn.HuberLoss(reduction='none', delta=2.0)
# Initialize weights and apply final processing
self.post_init()核心模型:self.model = TimeMoeModel(config),TimeMoeMode类负责执行主要的计算操作,其输出是经过多个解码器层后的隐状态(hidden_states)。
预测层:self.lm_heads这是一个包含多个TimeMoeOutputLayer的模块列表。每个预测层对应一个 不同的预测 horizon,每个预测层的输出维度由horizon_length 和 input_size 决定,TimeMoeOutputLayer类的实现如下:
class TimeMoeOutputLayer(nn.Module):
def __init__(self, hidden_size: int, horizon_length: int, input_size: int = 1):
super().__init__()
self.out_layer = nn.Linear(
hidden_size,
input_size * horizon_length,
bias=False,
)
def forward(self, x):
"""
Args:
x (torch.FloatTensor): with shape [B, seq_len, hidden_size]
Returns:
` torch.FloatTensor: final prediction with shape [B, seq_len, input_size]
"""
return self.out_layer(x)horizon_length决定了每个预测层的 输出维度。每个预测层将输出形状为 (batch_size, seq_length, input_size * horizon_length),其中 input_size 是每个时间步的输入特征维度,horizon_length 是预测的未来步数。
前向传播
def forward(
self,
input_ids: torch.FloatTensor = None,
attention_mask: Optional[torch.Tensor] = None,
position_ids: Optional[torch.LongTensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
inputs_embeds: Optional[torch.FloatTensor] = None,
labels: Optional[torch.FloatTensor] = None,
loss_masks: Optional[torch.FloatTensor] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
max_horizon_length: Optional[int] = None,
) -> Union[Tuple, MoeCausalLMOutputWithPast]:
output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
output_hidden_states = (
output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
)
return_dict = return_dict if return_dict is not None else self.config.use_return_dict
# decoder outputs consists of (dec_features, layer_state, dec_hidden, dec_attn)
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
position_ids=position_ids,
past_key_values=past_key_values,
inputs_embeds=inputs_embeds,
use_cache=use_cache,
output_attentions=output_attentions,
output_hidden_states=output_hidden_states,
return_dict=return_dict,
)
hidden_states = outputs[0]
predictions = None
loss = None
aux_loss = None
if labels is not None:
# AutoRegressive loss
ar_loss = 0.0
for lm_head, horizon_length in zip(self.lm_heads, self.config.horizon_lengths):
one_predictions = lm_head(hidden_states)
one_loss = self.calc_ar_loss(one_predictions, labels, loss_masks, horizon_length)
ar_loss += one_loss
if predictions is None:
predictions = one_predictions
loss = ar_loss / len(self.config.horizon_lengths)
if self.apply_aux_loss:
router_logits = outputs.router_logits if return_dict else outputs[-1]
temporal_aux_loss = load_balancing_loss_func(
router_logits,
top_k=self.num_experts_per_tok,
num_experts=self.config.num_experts,
attention_mask=attention_mask
)
loss += self.router_aux_loss_factor * temporal_aux_loss.to(loss.device)
else:
if max_horizon_length is None:
horizon_length = self.config.horizon_lengths[0]
max_horizon_length = horizon_length
else:
horizon_length = self.config.horizon_lengths[0]
for h in self.config.horizon_lengths[1:]:
if h > max_horizon_length:
break
else:
horizon_length = h
lm_head = self.lm_heads[self.horizon_length_map[horizon_length]]
predictions = lm_head(hidden_states)
if horizon_length > max_horizon_length:
predictions = predictions[:, :, : self.config.input_size * max_horizon_length]
if not return_dict:
output = (predictions,) + outputs[1:]
return (loss, aux_loss) + output if loss is not None else output
return MoeCausalLMOutputWithPast(
loss=loss,
aux_loss=aux_loss,
logits=predictions,
past_key_values=outputs.past_key_values,
hidden_states=outputs.hidden_states,
attentions=outputs.attentions,
)解码器:调用 self.model(即 TimeMoeModel)来计算模型的 hidden_states,它的形状为 (batch_size, seq_length, hidden_size)。
预测层:根据 self.config.horizon_lengths初始化多个预测层 self.lm_heads。在训练过程中,如果提供了labels,则计算自回归损失。否则选择合适的预测层并根据 horizon_length 输出预测结果。
自回归损失计算:计算每个预测层的输出,并根据标签计算损失。损失是通过 calc_ar_loss 方法计算的,考虑了掩码和时间步长(horizon_length)。
def calc_ar_loss(self, predictions, labels, loss_masks, horizon_length):
if len(labels.shape) == 2:
labels.unsqueeze_(dim=-1)
# enable model parallelism
labels = labels.to(predictions.device)
if loss_masks is not None and len(loss_masks.shape) == 2:
loss_masks.unsqueeze_(dim=-1)
# enable model parallelism
loss_masks = loss_masks.to(predictions.device)
if horizon_length > 1:
batch_size, seq_len, output_size = predictions.shape
shift_predictions = predictions.view(batch_size, seq_len, horizon_length, -1)
# pad to the same length with predictions
# shape -> [B, input_size, seq_len + horizon_length -1]
labels = F.pad(labels.transpose(-1, -2), (0, horizon_length - 1), mode='constant', value=0)
# shape -> [B, input_size, seq_len, horizon_length]
shift_labels = labels.unfold(dimension=-1, size=horizon_length, step=1)
shift_labels = shift_labels.permute(0, 2, 3, 1)
if loss_masks is not None:
# pad to the same length with predictions
loss_masks = F.pad(loss_masks.transpose(-1, -2), (0, horizon_length - 1), mode='constant', value=0)
loss_masks = loss_masks.unfold(dimension=-1, size=horizon_length, step=1)
loss_masks = loss_masks.permute(0, 2, 3, 1)
else:
shift_predictions = predictions
shift_labels = labels
# Calculate loss with mask
losses = self.loss_function(shift_predictions, shift_labels)
if loss_masks is not None:
losses = losses * loss_masks
loss = losses.sum() / loss_masks.sum()
else:
loss = torch.mean(losses)
return loss辅助损失:如果apply_aux_loss为True,则计算路由器辅助损失,即对专家选择的平衡性进行惩罚。因为在通常的MoE训练中,门控网络往往倾向于主要激活相同的几个专家,为了减轻这个问题的影响,引入一个辅助损失以确保所有专家接收到大致相等数量的训练样本平衡专家之间的选择。
输出:如果没有标签(即预测模式),返回预测结果;如果有标签,则返回包括损失在内的完整输出。输出的predictions形状为 (batch_size, seq_length, horizon_length * input_size)。

















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









