






牛顿方法,一种最大(小)化算法
—–Newton’s method
算法原理,对函数f(
θ
),使用下式进行迭代:
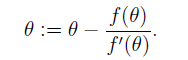
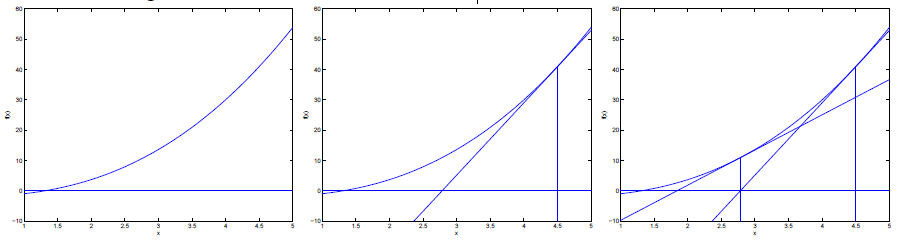
最终
θ
的收敛值会使得f(
θ
)=0,图像只管理解如下,详细介绍在note1 page20:
对于最大化问题,我们应当使目标函数的导数为0,因此f(
θ
)在这里为目标函数的一阶导数ℓ′(θ):
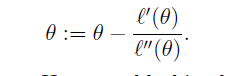
在逻辑回归中,
θ
为向量,因此迭代公式为矩阵形式:
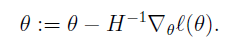
这里H叫做Hessian矩阵:
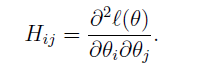
过半情况下,牛顿法比梯度下降法收敛更快,但是当θ的维数很高时,求逆的计算代价很大。档牛顿法用于最大化log likelihood function时,该方法也被叫做Fisher scoring。
通用线性模型
—–Generalized Linear Models
之前介绍的高斯分布和伯努利分布的分类,都是在一个更大的模型里,我们叫做Generalized Linear Models,接下来我们将对GLM进行推导并应用于其他的回归分类问题。
指数家族
—–The exponential family
对于可以写成如下形式的分布,我们称其在指数家族中:
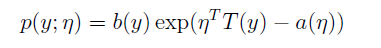
η:natural parameter/canonical parameter
T(y):sufficient statistic/充分统计量(统计学中的概念,日后再理解),通常情况下为y。
a(η):log partition function;
e−a(η)
是一个归一化常量,它确保p(y; η)的积分为1。
对于固定的T,a和b定义了一个参数为η的分布族,当我们改变η,我们会获得这个族中不同的分布。
对于伯努利分布:
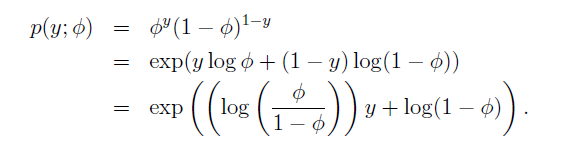
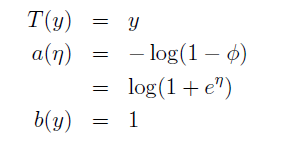
对于高斯函数,为了简化推导过程,令方差为1,则:
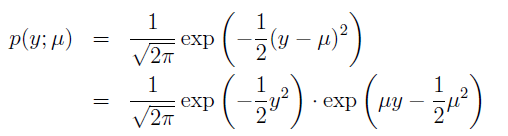
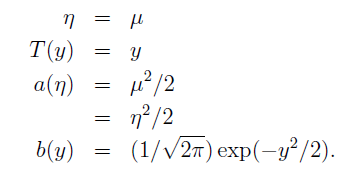
由此可见,伯努利分布高斯分布都是指数分布族。
事实上还有许多分布也在指数族中,例如泊松,多项式分布multinomial,伽马和指数分布等。接下来讨论如何建立一种模型,该模型能通过给定的x和
θ
来得到y。
建立GLMs
为了推导GLMs,我们首先要对y对x的条件分布做如下三点假设:
1.y | x; θ∼ ExponentialFamily(η).
2.给定x,我们的目标是预测T(y)的期望值,当T(y)=y,
hθ(x)
=E[y|x; θ].
3.natural parameter η和inputs x满足线性关系:η = θT x;如果η是一个向量,那么
ηi=θTix
.
第三条假设是最难满足的一条,接下来我们将用GLM推导逻辑回归和最小二乘法。
最小二乘法
目标变量y在GLM术语中被称为response variable,假设我们假设条件分布满足高斯分布,则由之前的推导,得到
u=η
,所以:
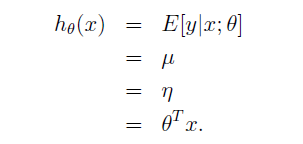
逻辑回归
如果y|x; θ ∼ Bernoulli(φ), then E[y|x; θ] = φ,由之前的推导,φ = 1/(1 +
e−η
),可得:
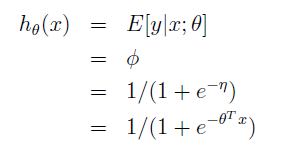
g(η)=E[T(y);η]
被称作canonical response function
g−1
被称作canonical link function
Softmax Regression
对于预测目标
y∈12,...,k
,这是一个多分类问题。可以将其定义为多项式分布。
因为多分类问题有k个可能的结果,因此使用k个参数
φ1,...,φk
来表示每种结果的可能性,事实上只需要k-1个参数就可以表示所有的参数,因为
∑i=1kφi=1
。
为了把多项式分布表示为指数族分布,定义
T(y)∈Rk−1
:
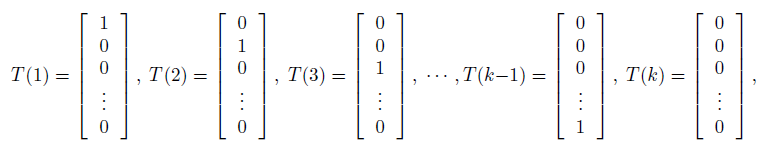
这里介绍一个指示函数indicator function 1{·}:1{True} = 1, 1{False} = 0.
所以(T(y))i = 1{y = i},(T(y))i表示T(y)的第i个元素
再之后我们还有E[(T(y))i] = P(y = i) = φi.
首先我们证明多项式分布是指数家族的一员:
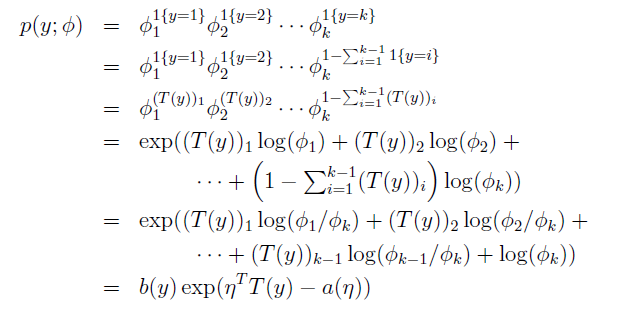
这里:
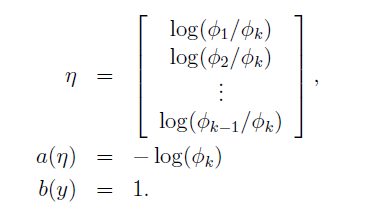
link function为:
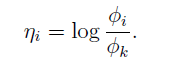
为了方便我们定义
ηk=log(φk/φk)=0
对link function求逆得到response function:
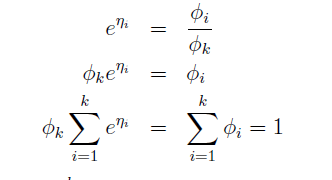
这意味着
φk=1/∑ki=1eηi
,带入上式可得
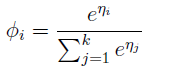
从
η
到
φ
的映射成为softmax function
根据假设可得:
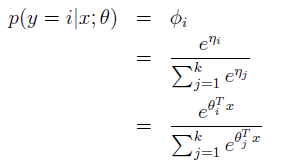
应用在多分类问题上的该模型成为softmax regression

换句话说,对于每一个i = 1, … , k,我们的假设都会输出一个估计的可能性p(y = i|x; θ)。
最后对于参数的训练,我们写下 log-likelihood函数
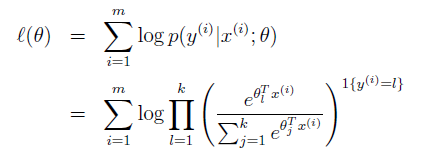
我们使用梯度上升或者牛顿法来获取最大值点。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









