






Generative Learning algorithms
因为我们想直接得到p(y|x),因此引入介绍Generative Learning algorithms。
根据贝叶斯准则,我们可以对分类问题分析建立模型:
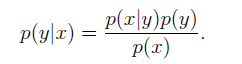
我们的最终的分类结果是选择后验概率最大的y
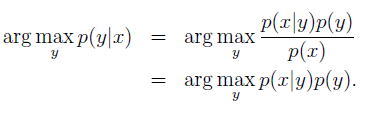
1.Gaussian discriminant analysis
1.1 The multivariate normal distribution
The multivariate normal distribution也叫作The multivariate Gaussian distribution,是一个n维高斯分布,表达式如下:
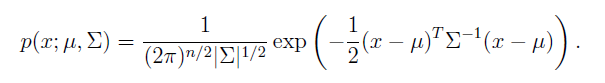
上式中每个参数的物理含义不再介绍,参考notes2。
1.2 The Gaussian Discriminant Analysis model
对于输入x为连续的随机变量,我们可以建立如下模型:
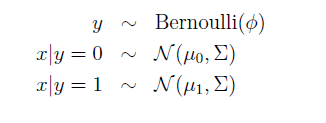
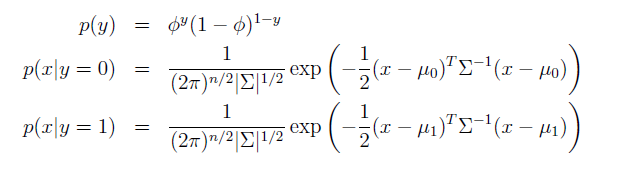
因此log-likelihood函数为:
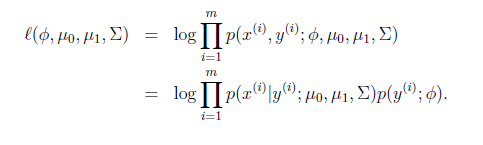
对该函数最大化求得参数为:
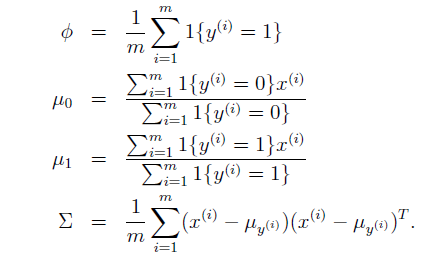
该结果可形象地通过下图表达:
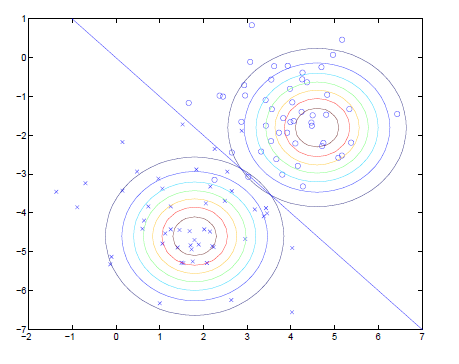
通过上图可以看出,两个高斯分布的边缘具有相同的形状和方向,因为他们的协方差矩阵相同。图中标出的直线为分界线。
1.3 Discussion: GDA and logistic regression
将
p(y=1|x;ϕ;μ0;μ1;∑)
改写为关于x的函数,我们可以发现可以改写为如下形式:
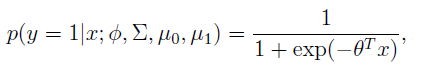
这正是logistic regression—–一种discriminative algorithm的形式
GDA和逻辑回归对于相同的数据集,通常会给出不同的分界,我们应该如何选取模型?总结如下:
首先我们考虑到,如果输入满足高斯分布的假设,那么GDA一定可以用逻辑回归表示,反之则不成立,因为逻辑回归包含了一族分布。因此GDA需要更强的假设。当数据严格满足高斯分布时,我们倾向于选择GDA模型,因为计算十分高效;相反如果数据不严格满足我们的假设,即不是高斯分布,那么逻辑回归模型根据鲁棒性。因此在实际应用中逻辑回归用的更加多些。
2.Naive Bayes
我们将要讨论输入
xi
为离散值时的情况,notes里面拒了判断垃圾邮件的例子,这里偷点懒不再赘述,只说定义和结论。
Naive Bayes (NB) assumption:
xi
are conditionally independent given y,即对于给定的y,x的分布是条件独立的(根据英文自行理解)。
对于基于朴素贝叶斯假设的算法,成为朴素贝叶斯分类器Naive Bayes classi er。
基于该种假设下的 likelihood函数为:
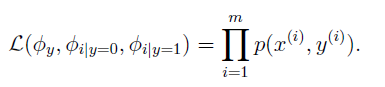
最大化上式得到:
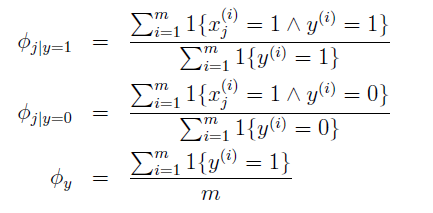
对于需要预测的数据x,我们只需要计算:
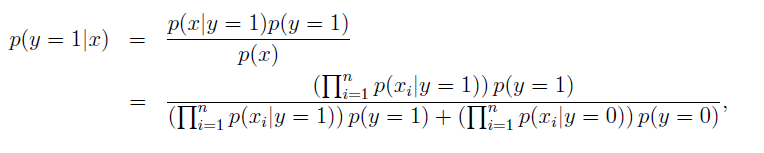
然后挑选具有更大后验概率的类别。
2.1 Laplace smoothing
为了避免出现样本中没有的数据,导致后验概率出现0/0无法求后验概率的情况,我们引入Laplace smoothing。引入该方法后的参数计算如下:
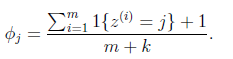
k为变量的取值个数,当只可以取两个值时,k=2。
2.2 Event models for text classi cation
在这里需要搞清楚themulti-variate Bernoulli event model和 the multinomial event model两个模型的区别(实际上也就是伯努利分布和多项分布的区别),在notes中的垃圾邮件分类的实例有很好的说明,有助于理解。在notes例子中注意要搞清输入变量发生了变化,要明白两个模型表达上的不同。















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









