







 本文介绍了生成学习算法,包括高斯判别分析(GDA)和朴素贝叶斯方法。GDA适用于连续变量,假设输入数据遵循多维高斯分布,但在模型假设较强的情况下,其鲁棒性较差。朴素贝叶斯方法用于离散变量,如文本分类,通过多变量伯努利和多项式事件模型进行建模。拉普拉斯平滑解决了未出现单词的概率问题。
本文介绍了生成学习算法,包括高斯判别分析(GDA)和朴素贝叶斯方法。GDA适用于连续变量,假设输入数据遵循多维高斯分布,但在模型假设较强的情况下,其鲁棒性较差。朴素贝叶斯方法用于离散变量,如文本分类,通过多变量伯努利和多项式事件模型进行建模。拉普拉斯平滑解决了未出现单词的概率问题。
Generative Learning algorithms
上一篇文章主要讲了线性回归和逻辑回归,它们都是给定x对y进行建模,即求出
p(y| x;θ) ,本章将介绍另外一种学习算法:生成学习算法。主要思路是依据条件概率公式p(y|x) = p(x|y)p(y)/p(x),间接求出p(y| x;θ) 。通俗点讲就是对不同的输出y分别建立模型,在预测的时候带入这两个模型,看谁概率更大。用公式来表示:
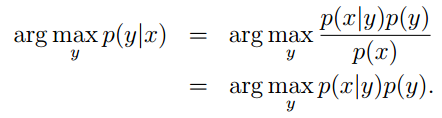
针对x是连续和离散值的情况,介绍高斯判别分析(GDA)和朴素贝叶斯方法。在x为多维高斯分布的情况下,GDA比逻辑回归更能得到好的结果,但是也由于其更强的条件假设,鲁棒性比逻辑回归更差。因此一般还是逻辑回归用的更多。在文本分类中应用朴素贝叶斯算法,又分为多变量贝努力事件模型和多项式事件模型。当用高斯判别分析不能很好地对连续型变量建模时,可以将其离散化,再用朴素贝叶斯。
Gaussian discriminant analysis(GDA)
在这个模型中,假设p(x|y)服从多维高斯分布。下面首先介绍多维高斯分布。
The multivariate normal distribution
多维高斯分布写作N(μ,∑) ,其中,μ 是平均向量,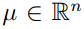
是协方差矩阵,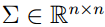
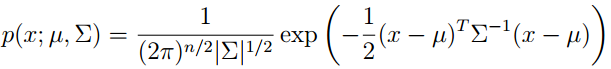
The Gaussian Discriminant Analysis model
一个分类问题中,如果输入x是一个连续随
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2023
2023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









