









YOLO系列博文:
- 【第1篇:概述物体检测算法发展史、YOLO应用领域、评价指标和NMS】
- 【第2篇:YOLO系列论文、代码和主要优缺点汇总】
- 【第3篇:YOLOv1——YOLO的开山之作】
- 【第4篇:YOLOv2——更好、更快、更强】
- 【第5篇:YOLOv3——多尺度预测】
- 【第6篇:YOLOv4——最优速度和精度】
- 【第7篇:YOLOv5——使用Pytorch框架、AutoAnchor、多尺度预训练模型】
- 【第8篇:YOLOv6——更高的并行度、引入量化和蒸馏以提高性能加速推理】
- 【第9篇:YOLOv7——跨尺度特征融合】
- 【第10篇:YOLOv8——集成检测、分割和跟踪能力】
- 【第11篇:YOLO变体——YOLO+Transformers、DAMO、PP、NAS】
- 【第12篇:YOLOv9——可编程梯度信息(PGI)+广义高效层聚合网络(GELAN)】
- 【第13篇:YOLOv10——实时端到端物体检测】
- 【第14篇:YOLOv11——在速度和准确性方面具有无与伦比的性能】
- 【第15篇(完结):讨论和未来展望】
1 摘要
- 发表日期:2022年6月
- 作者:Chuyi Li等人,美团技术团队
- 论文: YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
- 代码:https://github.com/meituan/YOLOv6
- 主要优缺点:
- 使用基于RepVGG的新骨干网络(EfficientRep),比之前的YOLO骨干网络使用了更高的并行度;
- 标签分配策略采用TOOD中提出的任务对齐学习方法进行标签分配;
- 使用了变焦损失(VariFocal loss)作为分类损失,以及SIoU/GIoU作为回归损失;
- 为回归和分类任务引入了自蒸馏策略;
- 通过使用RepOptimizer和通道级蒸馏的检测量化方案来实现更快的检测器;
- 这些新特性共同作用,旨在提高模型性能、加速推理过程,并在保持准确性的同时提升效率。
2 其他变体
先介绍一些其他的YOLO变体。
2.1 Scaled-YOLOv4
在YOLOv4发布一年后,同一组作者在2021年的CVPR上提出了Scaled-YOLOv4。与YOLOv4不同,Scaled-YOLOv4是在PyTorch框架下开发的,而不是Darknet。其主要创新在于引入了放大(scaling up)和缩小(scaling down)技术。放大意味着生成一个以牺牲速度为代价来提高准确性的模型;相反,缩小则意味着生成一个以牺牲准确性为代价来提高速度的模型。此外,缩小后的模型需要更少的计算资源,并且可以在嵌入式系统上运行。
- 缩小的架构被称为YOLOv4-tiny,它专为低端GPU设计,可以在Jetson TX2上以46 FPS的速度运行,或在RTX 2080Ti上以440 FPS的速度运行,在MS COCO数据集上达到22%的平均精度(AP)。
- 放大的架构被称为YOLOv4-large,包括三种不同的尺寸P5、P6和P7。这种架构是为云GPU设计的,达到了最先进的性能,在MS COCO数据集上实现了56%的AP,超过了所有先前的模型。
2.2 YOLOR
YOLOR于2021年5月在ArXiv上由YOLOv4的研究团队发布。它的全称是“You Only Learn One Representation”(你只需要学习一种表示)。在这篇论文中,作者开发了一种多任务学习方法,旨在通过学习一种通用表示,并使用子网络来创建特定任务的表示,从而创建一个适用于多种任务(如分类、检测、姿态估计)的单一模型。鉴于传统的联合学习方法常常导致次优特征生成,YOLOR 旨在通过编码神经网络中的隐性知识来克服这一问题,类似于人类如何利用过去的经验来解决新问题。实验结果表明,将隐性知识引入神经网络对所有任务都有益。
在MS COCO 2017测试开发集上的评估,YOLOR 在NVIDIA V100上以30帧每秒(FPS)的速度达到了55.4%的平均精度(AP)和73.3%的AP50。
2.3 YOLOX
YOLOX于2021年7月由Megvii Technology在ArXiv上发布。该模型基于PyTorch开发,并以Ultralytics的YOLOv3为起点,进行了五项主要改进:无锚框(anchor-free)架构、多正样本、解耦头、高级标签分配和强数据增强。YOLOX在2021年实现了SOTA的结果,在Tesla V100上以68.9 FPS的速度达到了50.1%的平均精度(AP),实现了速度与精度之间的最佳平衡。
以下是YOLOX相对于YOLOv3的五项主要改进:
-
无锚框(Anchor-free):自YOLOv2以来,所有后续的YOLO版本都是基于锚点的检测器。受CornerNet、CenterNet 和 FCOS等无锚框的先进目标检测器启发,YOLOX回归到无锚框架构,简化了训练和解码过程。无锚框架构使得AP相比YOLOv3基线提高了0.9个百分点。
-
多正样本(Multi positives):为了补偿由于缺乏锚框而产生的大量不平衡问题,作者使用中心采样 方法,将中心3×3区域作为正样本。这种方法使AP提高了2.1%。
-
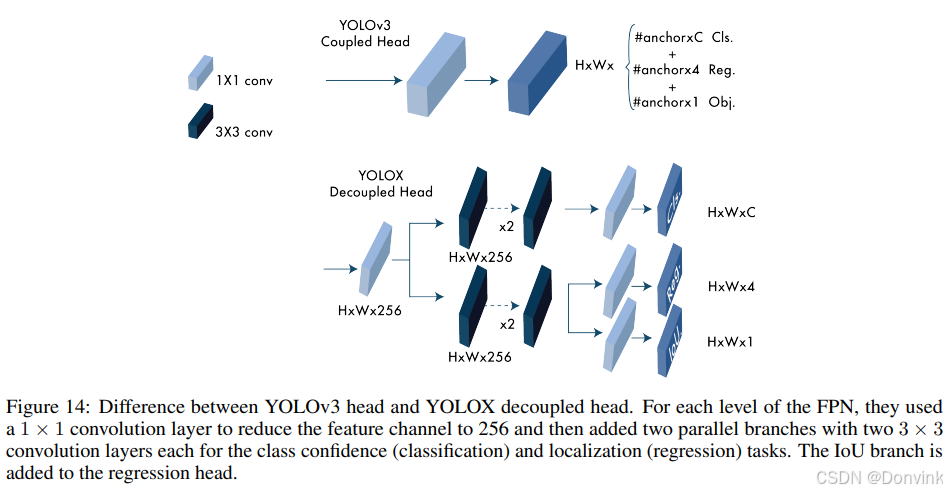
解耦头(Decoupled head):有论文研究表示,分类置信度和定位准确性之间可能存在不一致。因此,YOLOX将这两个任务分离成两个头(如下图所示),一个用于分类任务,另一个用于回归任务。这不仅提高了1.1%的AP,还加快了模型的收敛速度。
-
高级标签分配(Advanced label assignment):有论文表明,当多个物体的边界框重叠时,真实标签的分配可能会有歧义,并将分配过程表述为最优传输(Optimal Transport, OT)问题。受此工作的启发,YOLOX提出了一个简化的版本称为simOTA,使AP提高了2.3个百分点。
-
强数据增强(Strong augmentations):YOLOX使用MixUp和马赛克增强。作者发现,在使用这些增强技术后,ImageNet预训练不再有益。强数据增强使AP提高了2.4个百分点。
3 YOLOv6
YOLOv6于2022年9月由美团视觉AI部门发表在ArXiv上,该网络设计包括一个高效的Backbone,使用RepVGG或CSPStackRep块、PAN拓扑Neck结构,以及一个采用混合通道策略的高效解耦头。此外,论文还介绍了后训练量化和通道级蒸馏的增强量化技术,使用后得到更快且更准确的检测器。总体而言,YOLOv6在精度和速度指标上超越了之前的最先进模型,如YOLOv5、YOLOX和PP-YOLOE。
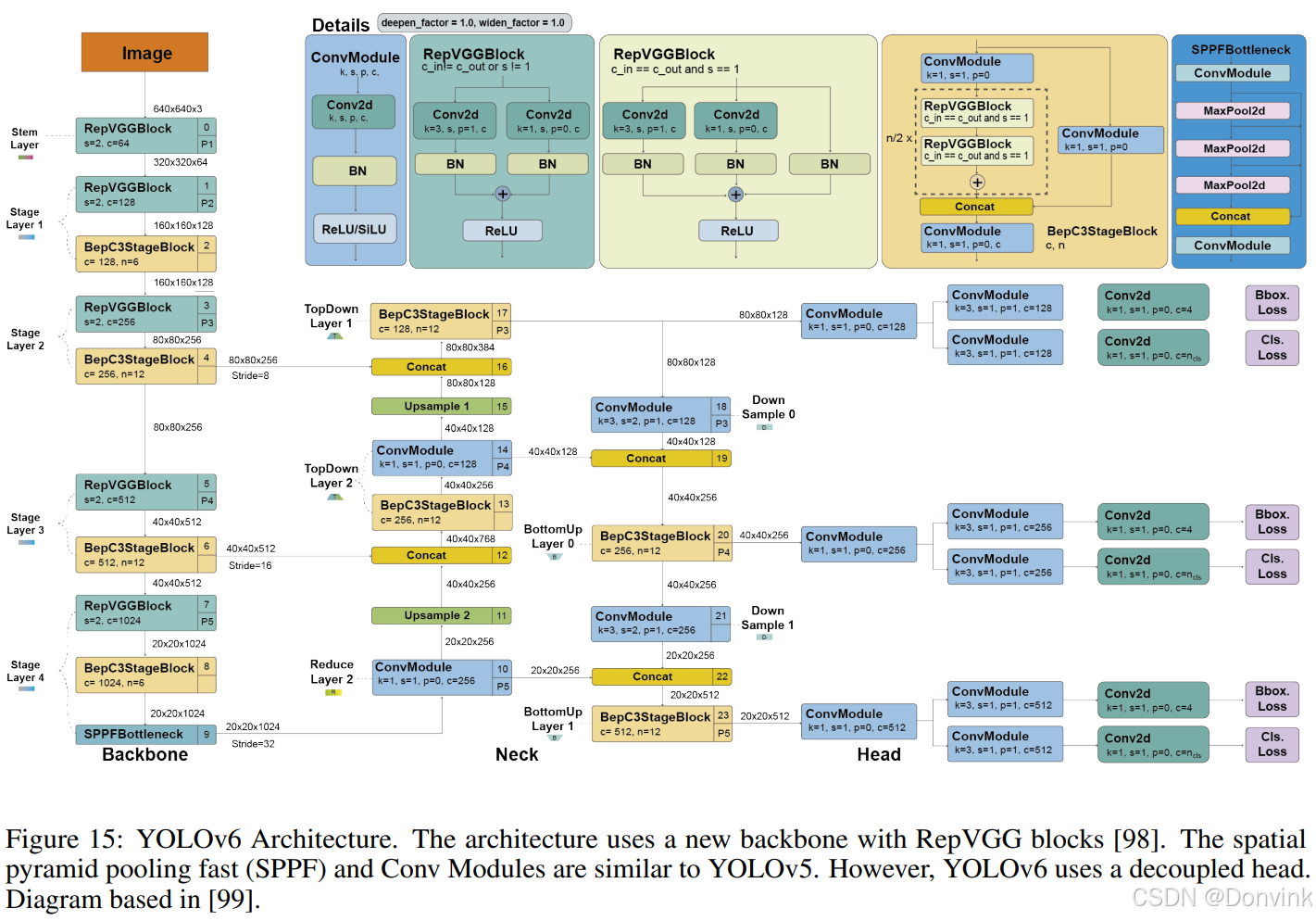
3.1 网络结构
YOLOv6的详细架构图:
3.2 创新点
该模型的主要创新点总结如下:
-
新的骨干网络:Backbone基于RepVGG的EfficientRep,相比之前的YOLO具有更高的并行性。对于Neck,他们使用了增强版的PAN,并在大型模型中引入了RepBlocks或CSPStackRep块。同时,借鉴YOLOX的设计,开发了一个高效的解耦头。
-
标签分配:采用了TOOD中提出的任务对齐学习方法进行标签分配。
-
新的分类和回归损失:他们使用了分类的VariFocal损失和回归的SIoU/GIoU损失。
-
自蒸馏策略:为回归和分类任务引入了自蒸馏策略。
-
量化方案:使用RepOptimizer和通道级蒸馏的量化方案,实现了更快的检测器。
作者提供了从YOLOv6-N到YOLOv6-L6共八个不同规模的模型。
在MS COCO 2017测试开发集上的评估显示,最大的模型在NVIDIA Tesla T4上以约29 FPS的速度达到了57.2%的AP。

















 2922
2922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









