






 本文详述了语义分割技术的发展历程,包括传统方法与基于深度学习的方法,如FCN、SegNet、U-net、DeepLab系列、RefineNet、PSPNet等模型的原理、优缺点。探讨了实时、弱监督和三维场景分割的研究方向。
本文详述了语义分割技术的发展历程,包括传统方法与基于深度学习的方法,如FCN、SegNet、U-net、DeepLab系列、RefineNet、PSPNet等模型的原理、优缺点。探讨了实时、弱监督和三维场景分割的研究方向。
点击上方“AI算法修炼营”,选择加星标或“置顶”
标题以下,全是干货

引言
语义分割结合了图像分类、目标检测和图像分割,通过一定的方法将图像分割成具有一定语义含义的区域块,并识别出每个区域块的语义类别,实现从底层到高层的语义推理过程,最终得到一幅具有逐像素语义标注的分割图像。
图像语义分割方法有传统方法和基于卷积神经网络的方法,其中传统的语义分割方法又可以分为基于统计的方法和基于几何的方法。随着深度学习的发展,语义分割技术得到很大的进步,基于卷积神经网络的语义分割方法与传统的语义分割方法最大不同是,网络可以自动学习图像的特征,进行端到端的分类学习,大大提升语义分割的精确度。
基于候选区域的深度语义分割模型
基于候选区域的语义分割方法首先从图像中提取自由形式的区域并对他们的特征进行描述,然后再基于区域进行分类,最后将基于区域的预测转换为像素级预测,使用包含像素最高得分的区域来标记像素。
基于候选区域的模型方法虽然为语义分割的发展带来很大的进步,但是它需要生成大量的候选区域,生成候选区域的过程要花费大量的时间和内存空间。此外,不同算法提取的候选区域集的质量也千差万别,直接影响了最终的语义分割效果。
基于全卷积的深度语义分割模型
基于全卷积的深度语义分割模型,主要特点是,全卷积网络没有全连接层,全部由卷积层构成。
主要思想
目前流行的深度网络,比如VGG,Resnet等,由于pooling和卷积步长的存在,feature map会越来越小,导致损失一些细粒度的信息(低层feature map有较丰富的细粒度信息,高层feature map则拥有更抽象,粗粒度的信息)。对于分类问题而言,只需要深层的强语义信息就能表现较好,但是对于稠密预测问题,比如逐像素的图像分割问题,除了需要强语义信息之外,还需要高空间分辨率。
针对这些问题,很多方法都提出了解决方案:
1、针对pooling下采样过程中的分辨率损失,采用deconvolution恢复。但是却很难恢复位置信息。
2、使用空洞卷积保持分辨率,增大感受野,但是这么做有两个缺点:A.明显增加了计算代价。B.空洞卷积是一种coarse sub-sampling,因此容易损失重要信息。
3、通过skip connection来产生高分辨率的预测。
► 基于全卷积的对称语义分割模型
1.FCN
首先将一幅 RGB 图像输入到卷积神经网络后,经过多次卷积及池化过程得到一系列的特征图,然后利用反卷积层对最后一个卷积层得到的特征图进行上采样,使得上采样后特征图与原图像的大小一样,从而实现对特征图上的每个像素值进行预测的同时保留其在原图像中的空间位置信息,最后对上采样特征图进行逐像素分类,逐个像素计算 softmax 分类损失。

主要特点:
不含全连接层(fc)的全卷积(fully conv)网络。从而可适应任意尺寸输入。
引入增大数据尺寸的反卷积(deconv)层,能够输出精细的结果。
结合不同深度层结果的跳级(skip)结构。同时确保鲁棒性和精确性。
2.SegNet
针对 FCN 在语义分割时感受野固定和分割物体细节容易丢失或被平滑的问题, SegNet被提出。SegNet和FCN思路十分相似,编码部分主要由VGG16网络的前 13 个卷积层和 5 个池化层组成,解码部分同样也由 13 个卷积层和 5 个上采样层组成,最后一个解码器输出的高维特征被送到可训练的softmax 分类器中,用于分类每个独立的像素。特别地,SegNet 网络采用了 pooling indices 来保存图像的轮廓信息,降低了参数数量。

3.Unet及各种变体
U-net 对称语义分割模型,该网络模型主要由一个收缩路径和一个对称扩张路径组成,收缩路径用来获得上下文信息,对称扩张路径用来精确定位分割边界。U-net 使用图像切块进行训练,所以训练数据量远远大于训练图像的数量,这使得网络在少量样本的情况下也能获得不变性和鲁棒性。

主要特点:
U 形的对称结构,左半部分收缩路径采用卷积,RELU 和最大池化获得图像的上下文信息,右边的扩展层直接复制过来,然后裁剪到与上采样的图片大小一样,再将它们连接起来,实现了不同层特征相结合的上采样特征图。
模型实现了很好的分割效果,但只能处理 2D 图像。
► 基于全卷积的扩张卷积语义分割模型
基于全卷积对称语义分割模型得到分割结果较粗糙,忽略了像素与像素之间的空间一致性关系。于是 Google 提出了一种新的扩张卷积语义分割模型,考虑了像素与像素之间的空间一致性关系,可以在不增加参数量的情况下增加感受野。
1、DeepLab系列
DeepLabv1 是由深度卷积网络和概率图模型级联而成的语义分割模型,由于深度卷积网络在重复最大池化和下采样的过程中会丢失很多的细节信息,所以采用扩张卷积算法增加感受野以获得更多上下文信息。考虑到深度卷积网络在图像标记任务中的空间不敏感性限制了它的定位精度,采用了完全连接条件随机场(Conditional Random Field,CRF)来提高模型捕获细节的能力。
DeepLabv2 语义分割模型增加了 ASPP(Atrous spatial pyramid pooling)结构,利用多个不同采样率的扩张卷积提取特征,再将特征融合以捕获不同大小的上下文信息。
DeepLabv3 语义分割模型,在 ASPP 中加入了全局平均池化,同时在平行扩张卷积后添加批量归一化,有效地捕获了全局语境信息。
DeepLabv3+语义分割模型在 DeepLabv3 的基础上增加了编-解码模块和 Xception 主干网络,增加编解码模块主要是为了恢复原始的像素信息,使得分割的细节信息能够更好的保留,同时编码丰富的上下文信息。增加 Xception 主干网络是为了采用深度卷积进一步提高算法的精度和速度。在inception结构中,先对输入进行1*1的卷积,之后将通道分组,分别使用不同的3*3卷积提取特征,最后将各组结果串联在一起作为输出。
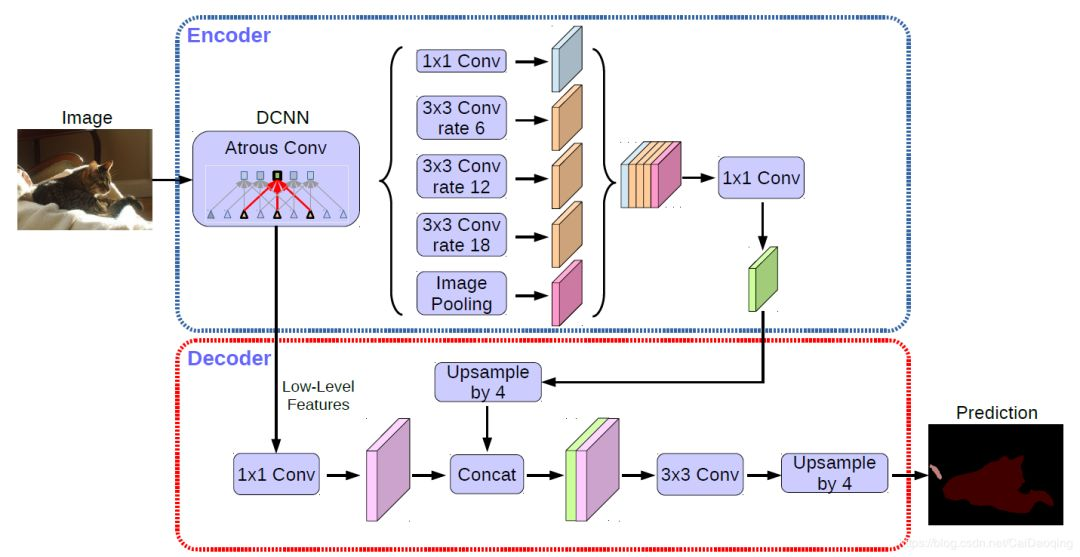
主要特点:
在多尺度上为分割对象进行带洞空间金字塔池化(ASPP)
通过使用 DCNNs (空洞卷积)提升了目标边界的定位
降低了由 DCNN 的不变性导致的定位准确率。
2.RefineNet
RefineNet采用了通过细化中间激活映射并分层地将其连接到结合多尺度激活,同时防止锐度损失。网络由独立的RefineNet模块组成,每个模块对应于ResNet。每个RefineNet模块由三个主要模块组成,即:剩余卷积单元(RCU),多分辨率融合(MRF)和链剩余池(CRP)。RCU块由一个自适应块组成卷积集,微调预训练的ResNet权重对于分割问题。MRF层融合不同的激活物使用卷积和上采样层来创建更高的分辨率地图。最后,在CRP层池中使用多种大小的内核用于从较大的图像区域捕获背景上下文。

主要特点:
提出一种多路径refinement网络,称为RefineNet。这种网络可以使用各个层级的features,使得语义分割更为精准。
RefineNet中所有部分都利用residual connections(identity mappings),使得梯度更容易短向或者长向前传,使段端对端的训练变得更加容易和高效。
提出了一种叫做chained residual pooling的模块,它可以从一个大的图像区域捕捉背景上下文信息。
► 基于全卷积的残差网络语义分割模型
深度卷积神经网络的每一层特征对语义分割都有影响,如何将高层特征的语义信息与底层识别的边界与轮廓信息结合起来是一个具有挑战性的问题。
PSPNet
金字塔场景稀疏网络语义分割模型(Pyramid Scene Parsing Network,PSP)首先结合预训练网络 ResNet和扩张网络来提取图像的特征,得到原图像 1/8 大小的特征图,然后,采用金字塔池化模块将特征图同时通过四个并行的池化层得到四个不同大小的输出,将四个不同大小的输出分别进行上采样,还原到原特征图大小,最后与之前的特征图进行连接后经过卷积层得到最后的预测分割图像。

主要特点:
金字塔场景解析网络是建立在FCN之上的基于像素级分类网络。将大小不同的内核集中在一起激活地图的不同区域创建空间池金字塔。
特性映射来自网络被转换成不同分辨率的激活,并经过多尺度处理池层,稍后向上采样并与原始层连接进行分割的feature map。
学习的过程利用辅助分类器进一步优化了像ResNet这样的深度网络。不同类型的池模块侧重于激活的不同区域地图。
► 基于全卷积的GAN语义分割模型
生成对抗网络模型(Generative Adversarial Nets,GAN)同时训练生成器 G 和判别器 D,判别器用来预测给定样本是来自于真实数据还是来自于生成模型。
利用对抗训练方法训练语义分割模型,将传统的多类交叉熵损失与对抗网络相结合,首先对对抗网络进行预训练,然后使用对抗性损失来微调分割网络,如下图所示。左边的分割网络将 RGB 图像作为输入,并产生每个像素的类别预测。右边的对抗网络将标签图作为输入并生成类标签(1 代表真实标注,0 代表合成标签)。

► 基于全卷积语义分割模型对比
名称 | 优点 | 缺点 |
FCN | 可以接受任意大小的图像输入;避免了采用像素块带来的重复存储和计算的问题 | 得到的结果不太精确,对图像的细节不敏感,没有考虑像素与像素之间的关系,缺乏空间一致性 |
SegNet | 使用去池化对特征图进行上采样,在分割中保持细节的完整性;去掉全连接层,拥有较少的参数 | 当对低分辨率的特征图进行去池化时,会忽略邻近像素的信息 |
Deconvnet | 对分割的细节处理要强于 FCN,位于低层的filter 能捕获目标的形状信息,位于高层的 filter能够捕获特定类别的细节信息,分割效果更好 | 对细节的处理难度较大 |
U-net | 简单地将编码器的特征图拼接至每个阶段解码器的上采样特征图,形成了一个梯形结构;采用跳跃连接架构,允许解码器学习在编码器池化中丢失的相关性 | 在卷积过程中没有加pad,导致在每一次卷积后,特征长度就会减少两个像素,导致网络最后的输出与输入大小不一样 |
DeepLab | 使用了空洞卷积;全连接条件随机场 | 得到的预测结果只有原始输入的 1/8 大小 |
RefineNet | 带有解码器模块的编码器-解码器结构;所有组件遵循残差连接的设计方式 | 带有解码器模块的编码器-解码器结构;所有组件遵循残差连接的设计方式 |
PSPNet | 提出金字塔模块来聚合背景信息;使用了附加损失 | 采用四种不同的金字塔池化模块,对细节的处理要求较高 |
GCN | 提出了带有大维度卷积核的编码器-解码器结构 | 计算复杂,具有较多的结构参数 |
DeepLabV3 ASPP | 采用了Multigrid;在原有的网络基础上增加了几个 block;提出了ASPP,加入了 BN | 不能捕捉图像大范围信息,图像层的特征整合只存在于 ASPP中 |
GAN | 提出将分割网络作为判别器,GAN 扩展训练数据,提升训练效果;将判别器改造为 FCN,从将判别每一个样本的真假变为每一个像素的真假 | 没有比较与全监督+半监督精调模型的实验结果,只体现了在本文中所提创新点起到了一定的作用,但并没有体现有效的程度 |
基于弱监督学习的语义分割模型
边界框标注
为了扩展可用数据集,Dai 等人使用易获取的边界框标注数据集来训练分割模型,该模型在自动生成候选区域与训练卷积网络之间交替进行,通过 MCG来选取带有语义标注的区域,采用卷积网络生成候选区域的分割掩膜。在网络迭代时,由于边界框可以增强网络识别目标的能力,通过更新卷积网络中的参数来校正分割掩膜,提升语义分割效率。
简笔标注
Lin 等人提出基于用户交互的图像语义分割方法,该方法使用简笔对图像进行注释,利用图模型训练卷积网络,用来对简笔标注的图像进行语义分割,基于图模型将简笔标注的信息结合空间约束、外观及语义内容,传播到未标记的像素上并学习网络参数。简笔标注无需仔细勾勒图像边界和形状,只需对每类语义画一条线作为标记,有利于注释没有明确定义形状的物体(例如,天空,草)。
图像级标注
Pinheiro 等人采用多示例学习模型构建图像标签与像素之间的关联性,首先使用 ImageNet图像级标签对模型进行训练,利用 CNN 生成特征平面,然后将这些特征平面通过聚合层对模型进行约束,该模型得到了很好的分割结果。
总结
本文主要对于图像语义分割技术的研究发展历程进行了详细评述,对于传统的语义分割方法到当前主流的基于深度学习的图像语义分割理论及其方法做出了综合性的评估,对基于深度学习语义分割技术需要用到的网络模型、网络框架、分割流程进行了详细的评估。
在深入该领域后发现该领域仍然存在着非常多的未知问题值得深入探究。基于以上分析,提出今后的研究方向:
(1)实时语义分割技术。现阶段评价应用于语义分割的网络模型主要着重点在精确率上,但是随着应用于现实场景的要求越来越高,需要更短的响应时间,因此在维持高精确率的基础上,尽量缩短响应时间应是今后工作的方向。
(2)弱监督或无监督语义分割技术。针对需要大量的标注数据集才能提高网络模型的精度这个问题,弱监督或无监督的语义分割技术将会是未来发展的趋势。
(3)三维场景的语义分割技术。目前的诸多基于深度学习的语义分割技术所用以训练的数据主要是二维的图片数据,同时测试的对象往往也是二维的图片,但是在实际应用时所面对的环境是一个三维环境,将语义分割技术应用至实际中,未来需要针对三维数据的语义分割技术进行研究。
扩展阅读
https://zhuanlan.zhihu.com/p/76418243
https://zhuanlan.zhihu.com/p/37805109
https://zhuanlan.zhihu.com/p/37618829

▲长按关注我们
题目以下,全是干货!
原创不易,在看鼓励!


















 32万+
32万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









