







学习了一个多学期的机器学习和数据挖掘的基本知识,经过一次考试认识到,目前知识还处于混乱状态,借此平台整理,加深记忆。
如果中间过程没有看懂,我相信我的例子一定能让你透彻理解。例子需要动手计算,相信算完再回顾前面的理论就会有新的理解。例子在第五部分。
1. 简介
naive bayes分类器是一种很简单的概率分类器。主要理论是bayes理论,以及对特征间强独立性的假设。就是假设所有事件互相独立。举例来说就是,决定是否买电脑时,我的年龄和我的收入是完全独立的。年龄不会影响收入。
优点:Simple and fast
缺点:在现实问题中,对于各个特征完全独立的假设可能不准确。
2. 概率模型
naive bayes分类器是一个条件概率模型,该分类器如下面公式所示:
问题描述: X=(x(1),x(2)...,x(m)) 其中m代表特征的数量。 P(Ck|X) 代表分到第k类的概率。如果满足:
也就是说,选择概率最大的那一类将X归入。
基于Bayes理论,条件概率可以被表示为
下面讨论此公式的计算问题。
<1>在实际使用中 p(x) 可以不用计算,因为对于所有类来说 p(x) 相同。
<2>
p(X|Ck)
的计算。由概率论中的知识我们可以知道这是一个已知
Ck
时
X
的联合分布,对于计算这个联合分布是十分困难的。所以这就是naive bayes的奇妙之处,下面是详细的公式推导,使用naive bayes的特征独立性,得出来
由于naive bayes假设所有特征独立,此时条件概率等于无条件概率即:
所以(1)可以化简为:
但是读者可能又会问, p(x(j)|Ck) 怎么计算呢,这个你看到第四部分,参数估计就明白了。这里是原理,请耐心阅读。
<3>
P(Ck)
的计算。
P(C_k)为先验概率,此概率一半为已知。
<4>接下来就是结论,编程的时候就是使用的这一部分,综上naive bayes分类器可以表示为:
3. 事件模型
这一部分是针对上一部分 P(xj|Ck) 的进一步讨论,在实际计算时,我们往往将 P(xj|Ck) 假定为某一种分布,例如:
正态分布
P(x=v|c)=12πσ2c‾‾‾‾‾√e−(v−μc)22σ2cBernoulli分布
P(x=l|Ck)=plkj(1−pkj)1−l l=0,1
4. 参数估计
上一部分,就是说如果碰到实际问题,可以假设概率就是这个样子。但是如果不能假设成为这个样子,我们就需要用到参数估计的知识了。现在我们再回顾一下我们要计算的公式:
所以本节分为两个部分
part one: P(Ck) 的估计
这个式子就是说,我这一类的先验概率可以表示为,我所有已知数据中是这一类的数量/总的数量。其中 λ 是平滑参数,主要使用意义在part two中防止分母为0,这个值是我们预先取定的,如果 λ=1 则称为拉普拉斯平滑。
part two: P(x(j)|Ck) 的估计
这个式子就是说, P(x(j)=l|Ck) 可以用属于这一类,并且 x(j) 属性为 l 的数据的数量/这一类数据的数量。其中
5. 例子:是否购买电脑
好了,讲了这么多,如果没有例子我也是谜的。下面这个例子相信能让你对我上面总结的各种公式有深刻的理解。
例:现在我们已经有了一些购买电脑人的信息如下图,使用naive bayes模型,预测wxc575843同学他会不会买电脑,此同学的属性为
X=(age=youth,income=medium,student=yes,credit_rating=fair)
不使用平滑即
λ=0
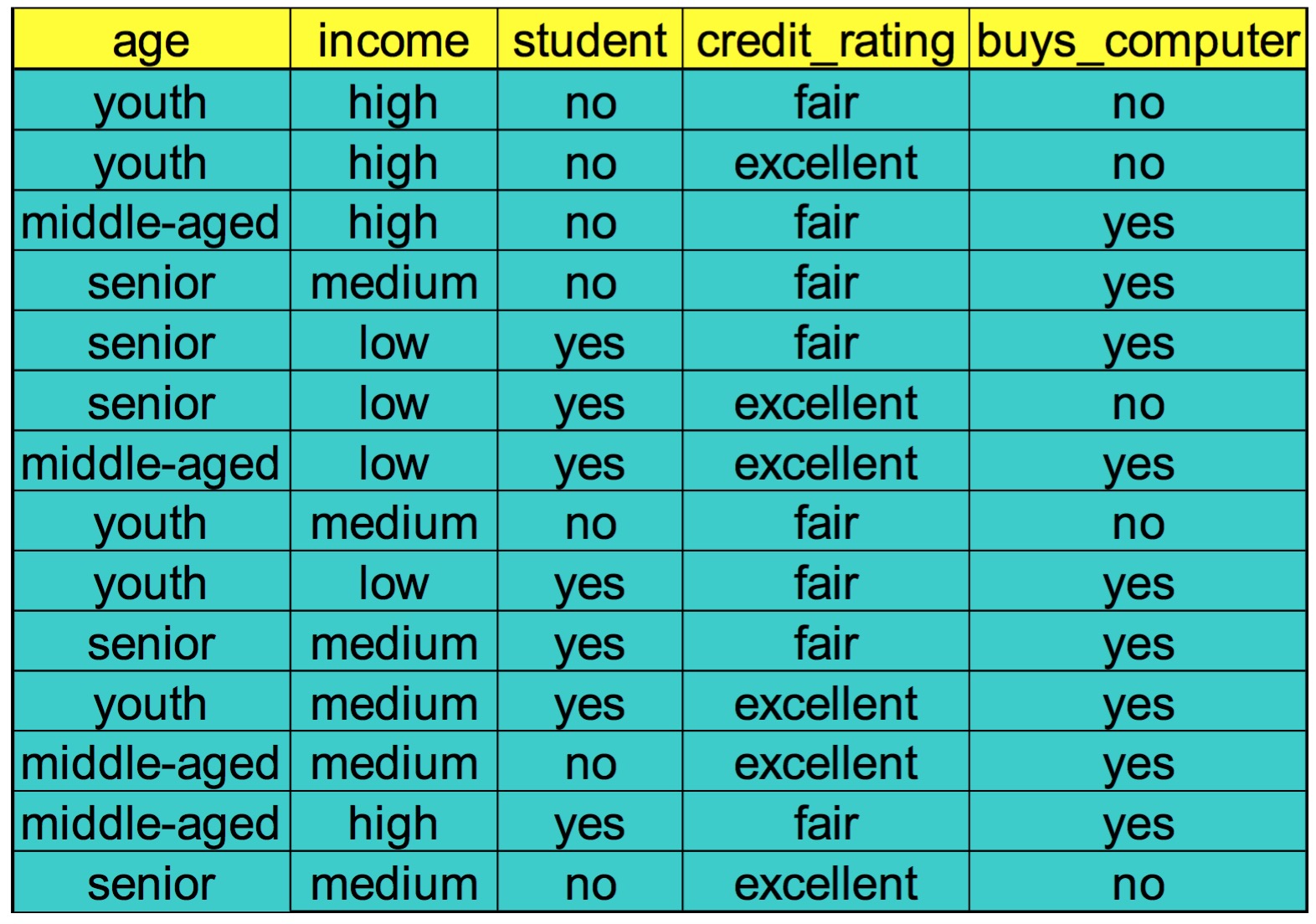
解:
这里一共要计算两个值,
P(buy|X)和P(not buy|X)
<1> P(buy|X)=P(buy)P(age=youth|buy)P(income=medium|buy)P(student=yes|buy)P(credit_rating=fair|buy)
这里我们可以数出,14个人中有9个买了电脑,所以
P(buy)=914
在9个买了电脑的人中age=youth的有两个所以
P(age=youth|buy)=29
在9个买了电脑的人中income=medium的有4个所以
P(income=medium|buy)=49
同理
P(student=yes|buy)=69
P(credit_rating=fair|buy)=69
所以
P(buy|X)=914∗29∗49∗69∗69=0.02822
<2> P(not buy|X)=P(not buy)P(age=youth|not buy)P(income=medium|not buy)P(student=yes|not buy)P(credit_rating=fair|not buy)
同<1>中的计算方式可得 P(not buy|X)=514∗35∗25∗15∗25=0.006757
综上所述: P(not buy|X)< P(buy|X)$所以wxc575843同学会买电脑。
6. python 代码实现
这一部分是用代码实现naive bayes分类器。此部分待我整理好之后,这两天发出。















 2867
2867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









