









作者:whj95
导读
树
树的定义
没有简单回路 连通 无向图(回忆简单图:没有重复边)
简单理解,无环 无多重边 连通
树的高度:以根节点为0层,到树叶的最长路径为树的高度
平衡(balanced):所有树叶都在h或h-1层
树的种类

m元树: 每个内点不超过m个子女
正则m元树: 每个内点恰好等于m个子女
二叉树: 正则2元树
树的性质
①n个顶点n-1个边
②有着i个内点的正则m元树有n= mi + 1顶点(所有子正则m元树+根)
③根据2和n= l+i(n为顶点数,l为叶子数,i为内点数)
④高度为h的m元树中至多有m
h
个树叶
树的运用
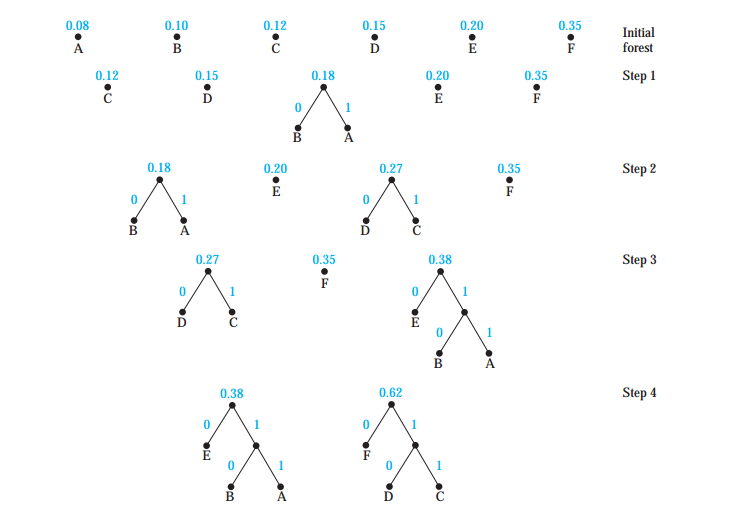
哈夫曼编码
①选出当前最小的两个权值构成较小的树,树叶左大右小放置,根节点记下权值和,树枝左0右1
②把生成的树新的权值插入队伍,重复①
③编码即为从根节点到路径的01编码,平均位数就为
∑
权值乘以长度
例子如下:
树的遍历 TreeTraversal
遍历
下面的前中后序的前中后都是描述对根的优先级,每移动一步都要重置指令:
首先贴个万能的例题,然后在不同的排序方法中展示它的不同:
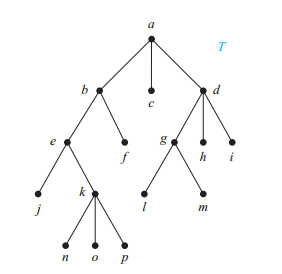
前序遍历(Preorder):优先级即根左右,例题的排序就为:a,b,e,j,k,n,o,p,f,c,d,g,l,m,h,i
中序遍历(Inorder):优先级即左根右,例题的排序就为:j,e,n,k,o,p,b,f,a,c,l,g,m,d,h,i
后序遍历(Postorder):优先级即左右根,例题的排序就为:j,n,o,p,k,e,f,b,c,l,m,g,h,i,d,a
记法及读法
前缀记法(Prefix Notation):
记法:
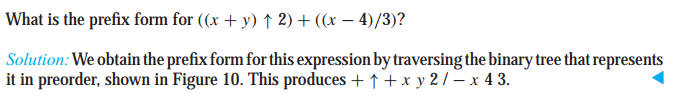
读法:从后向前读

后缀记法(Postfix Notation):
记法:

读法:从前往后

中缀记法(Infix Notation):
给出一个中缀表达式:
a+b*c-(d+e)
第一步:
按照运算符的优先级对所有的运算单位加括号,式子变成:
((a+(b*c))-(d+e))
第二步:
转换前缀:把运算符号移动到对应的括号前面则变成拉:-( +(a *(bc)) +(de))把括号去掉:
-+a*bc+de
转换后缀:把运算符号移动到对应的括号后面则变成拉:((a(bc)* )- (de)+ )+把括号去掉:
abc*-de++
生成树 Spanning Trees
定义:包含原图中所有顶点的树(无环 无多重边 连通)
广度优先搜索(Breadth First Search):即横向遍历,以行为单位一层一层地深究到最右方,然后跳至下一行最左端。
简言之,目光短浅一手抓
深度优先搜索(Depth First Search):即纵向遍历,以“列”为单位从左向右一竖一竖地深究到最底端,到达最底端后返回根节点,遍历新一竖的列。
简言之,一条路走到黑
举个万能的例子:
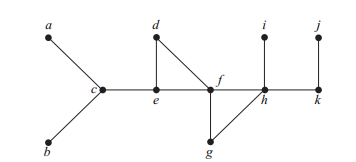
以f为起点,BFS第一步是d,e,g,h
以f为起点,DFS第一步是h,k,j(其中一种)
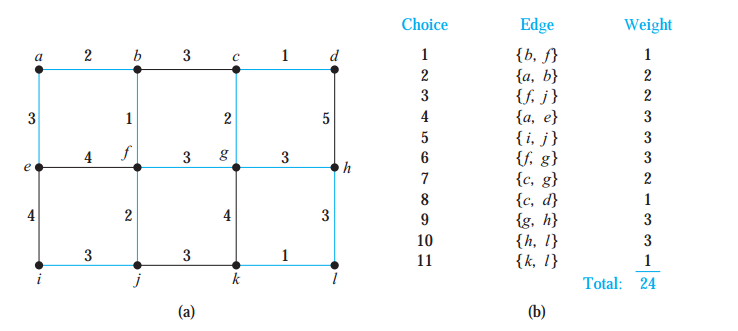
最小生成树 Minimum Spanning Trees
普林算法( Prim’s Algorithm)
①选择权值最小的一条边记下两端端点加入队列
②找出与队列中任一端点有关的所有边,选择权值最小的,记下其端点
③重复②并且不形成回路,直到遍历了所有顶点(出现生成树)
给个例子:
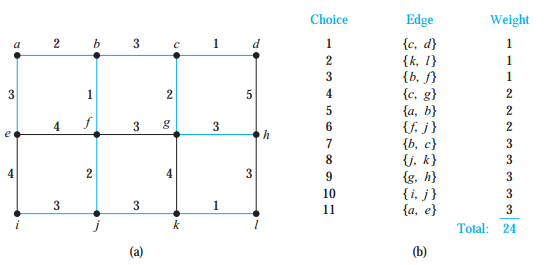
克鲁斯卡尔算法( Kruskal’s Algorithm)
与Prim Algorithm唯一区别是不定死要求要找与点联系的边,把边以权值从小到大排序,从上到下挑选直至挑选完所有顶点且之前不形成回路















 8173
8173

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









