







这一周学校的事情比较多所以拖了几天,这回我们来讲一讲聚类算法哈。
首先,我们知道,主要的机器学习方法分为监督学习和无监督学习。监督学习主要是指我们已经给出了数据和分类,基于这些我们训练我们的分类器以期达到比较好的分类效果,比如我们前面讲的Logistic回归啊,决策树啊,SVM啊都是监督学习模型。无监督学习就是指我们就只有数据,没有分类结果,然后根据数据进行建模能够给出哪些样本是属于一类的一个过程,通常我们就称之为聚类。
今天我主要介绍以下几种最常见的聚类算法,包括K-Means算法,基于密度的聚类(DBSCAN)算法,密度最大值算法(DPEAK),谱聚类算法,基本上也是从易到难,从原理讲讲我自己的理解,希望对大家有用。
====================================================================
K-Means算法。
原理上来讲,K-Means算法其实是假设我们数据的分布是K个sigma相同的高斯分布的,每个分布里有N1,N2……Nk个样本,其均值分别是Mu1,Mu2……Muk,那么这样的话每个样本属于自己对应那个簇的似然概率就是
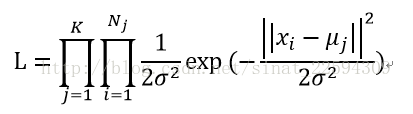
这个套路我们就很熟悉了,下面就是取对数似然概率,要求似然概率的最大值,给它加个负号就可以作为损失函数了,考虑到所有簇的sigma是相等的,所以我们就可到了K-Means的损失函数

接着我们对损失函数求导数为0,就可以得到更新后最佳的簇中心了
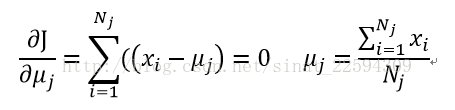
这样我们就得到了所谓的K-Means算法
1 初始选择K个类别中心。
2 将每个样本标记为距离类别中心最近的那个类别。
3 将每个类别中心更新为隶属该类别所有点的中心。
4 重复2,3两步若干次直至终止条件(迭代步数,簇中心变化率,MSE等等)
现在我们回过头来看看K-Means算法的问题。
首先,正如我刚开始介绍它的时候,它是假设数据服从sigma相同的混合高斯分布的,所
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 632
632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









