







Friedman test和Nemenyi test
(1)Friedman test分别对每个数据集的算法进行排序,最优算法的排序(rank)为1,次优算法的排序为2…,在排名相同时,指定平均排序(average ranks)。
令 表示第j个算法(1≤j≤k )在第i个数据集(1≤i≤N) 上的排序。Friedman test比较了算法的平均排序,
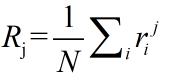
在零假设下,即所有的算法都是等价的,因此它们的排序Rj应该相等,Friedman统计量按照
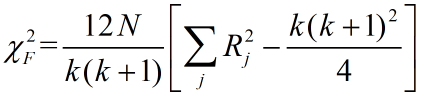
分布,当N和k足够大时(根据经验,N﹥10并且k﹥5),自由度为k-1;当N较小时,有Friedman临界检验值表,找不到对应情况时,只能用卡方近似表示。Iman和Davenport的研究表明,Friedman的 过于保守,并得出一个更好的统计:
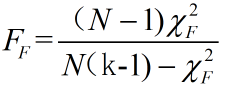
它服从F-分布,自由度为k-1和(k-1)(N-1)。如果零假设被拒绝,说明算法间有显著性差异,则我们可以继续进行后续检验。后续检验有两种: Nemenyi test和 Bonferroni- Dunn test。 Nemenyi test将k两两比较,需比较k(k-1)/2次。但实际在写论文时,我们主要目的是比较我们自己的算法即控制算法(control algorithm)与其他算法之间的关系,比较k-1次即可。
当将所有分类器与控制分类器进行比较时,我们可以不使用 Nemenyi检验,而使用Bonferroni校正或类似的方法来控制多个假设检验中的 family-wise错误。虽然这些方法通常比较保守,功率较小,但在本例中它们比 Nemenyi测试更强大,因为 Nemenyi测试调整了进行k(k-1)/2比较的临界值,而与控件相比,我们只进行k-1比较”。。
(2)Nemenyi test
一般的,使用临界差CD(critical difference)来控制family-wise错误率。
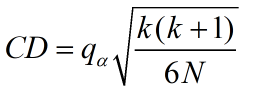
其中,针对Nemenyi test 的 (临界值,critical values)对应查询表格。
参考文献:
[1] Ststistical Comparisons of Classifiers over Multiple Data Sets
[2] Streaming Feature Selection for Multilabel Learning Based on Fuzzy Multual
Information















 5901
5901











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









