







1、主要贡献
解耦出了生成网络中style的影响因素,并可以利用这一点实现不同生成图像的风格融合
注意:该网络还是从噪声生成随机图像,只是可以把已经生成的随机图像的latent code相融合,得到介于两者之间的新类型图像;而不是根据手头的图像来实现风格融合
2、网络结构
不更改discriminator或者loss function,只修改generator

1)网络输入用constant
2)[high-level attributes (e.g. pose, identity)] 加入non-linear mapping网络f (8层MLP),将输入的隐编码z映射为同样尺寸的w,然后再用learned affien transformation将w转换为styles
3)Adaptive instance Normalization (AdaIN)
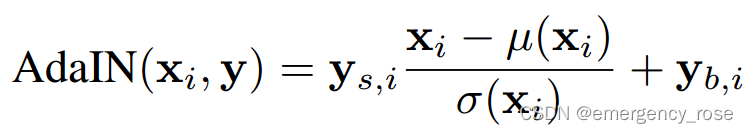
4)[stochatic variation (e.g. freckles, hair)] 用learned per-feature scaling factors将single-channel高斯噪声映射到all feature maps,添加到AdaIN前
5)设置不同scale,便于进行scale-specific mixing and interpolation
6)mixing regularization用于decorrelate相邻的styles,style mixing:在训练阶段,一定比例的图像是用两个随机隐变量生成的,不同的scale随机switch隐变量
在测试阶段,style mixing可以得到融合两种图片特征的图像

3、评估隐空间解耦程度
1)perceptual path length
这个人的解释还是挺清楚的:如何理解 stylegan? - 龙鹏-笔名言有三的回答 - 知乎
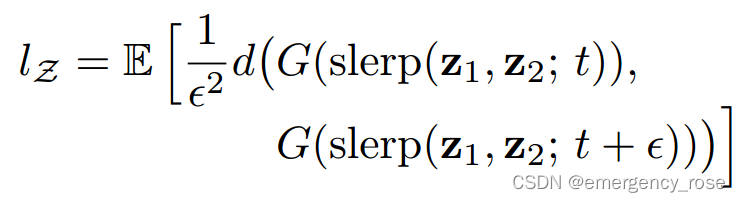
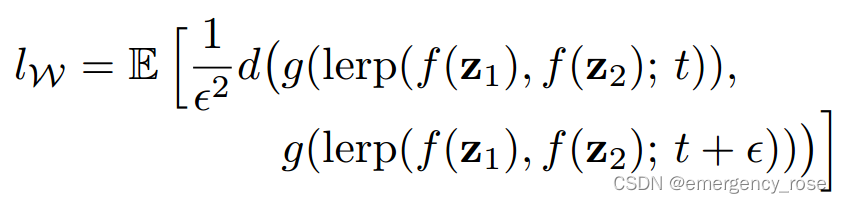
2)linear separability
这个人的解释还是挺清楚的:StyleGAN论文学习笔记 - 小花的文章 - 知乎
![]()















 4114
4114











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









