







熟悉CMT的都知道,作者在聚类部分使用了层次凝聚聚类算法(Hierarchical Agglomerative Clustering)并且使用的是单链(Single-link),今天我们就来学习下这个算法。
前面学习了几种聚类算法,K-Means,EM,AP等都属于平面聚类(Flat Clustering),因为这些算法的输出都是返回一个平面的无结构的聚类集合,所以叫做Flat clustering;平面聚类有一个缺陷就是要选择聚类的数目以及初始点,这对于没有经验的人员来说是一件很棘手的工作,因为聚类结果的好坏完全依赖于这一参数的选择,所以很多时候可以考虑下层次聚类算法,避免了聚类数量和初始点的选择。层次聚类算法有多种形式,本篇介绍的这个叫做层次凝聚聚类算法(Hierarchical Agglomerative Clustering),简称HAC,其主要思想就是,先把每一个样本点当做一个聚类,然后不断重复的将其中最近的两个聚类合并(就是凝聚的含义),直到满足迭代终止条件。
HAC具体实现步骤:
1)将训练样本集中的每个数据点都当做一个聚类;
2)计算每两个聚类之间的距离,将距离最近的或最相似的两个聚类进行合并;
3)重复上述步骤,直到得到的当前聚类数是合并前聚类数的10%,即90%的聚类都被合并了;当然还可以设置其他终止条件,这样设置是为了防止过度合并。
很明显,还是一样的老套路,唯一的新鲜处在于第二步中,如何度量两个聚类间的相似度,关于这个主要有三种定义:
1)单链(Single-link):不同两个聚类中离得最近的两个点之间的距离,即MIN;
2)全链(Complete-link):不同两个聚类中离得最远的两个点之间的距离,即MAX;
3)平均链(Average-link):不同两个聚类中所有点对距离的平均值,即AVERAGE;
不难发现,其中前两种定义的出发点是那些点集中的特殊点或外点,如噪点;而最后一种定义相对来说就不那么稳定了,所以又有人提出了使用距离的中值,这样可以排除一些个别点的干扰。
可以看下图效果(基于单链),黑色点是噪声点:
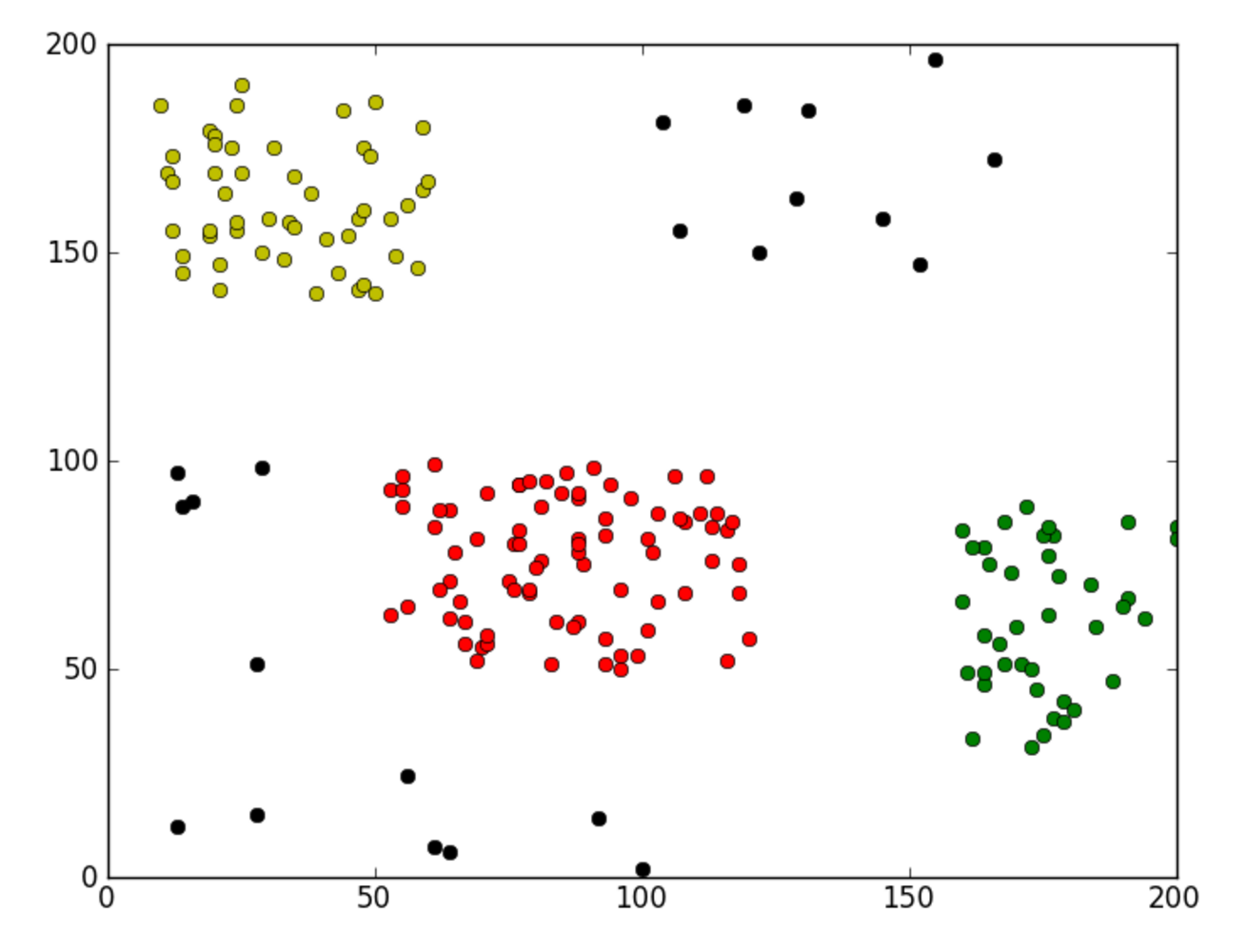
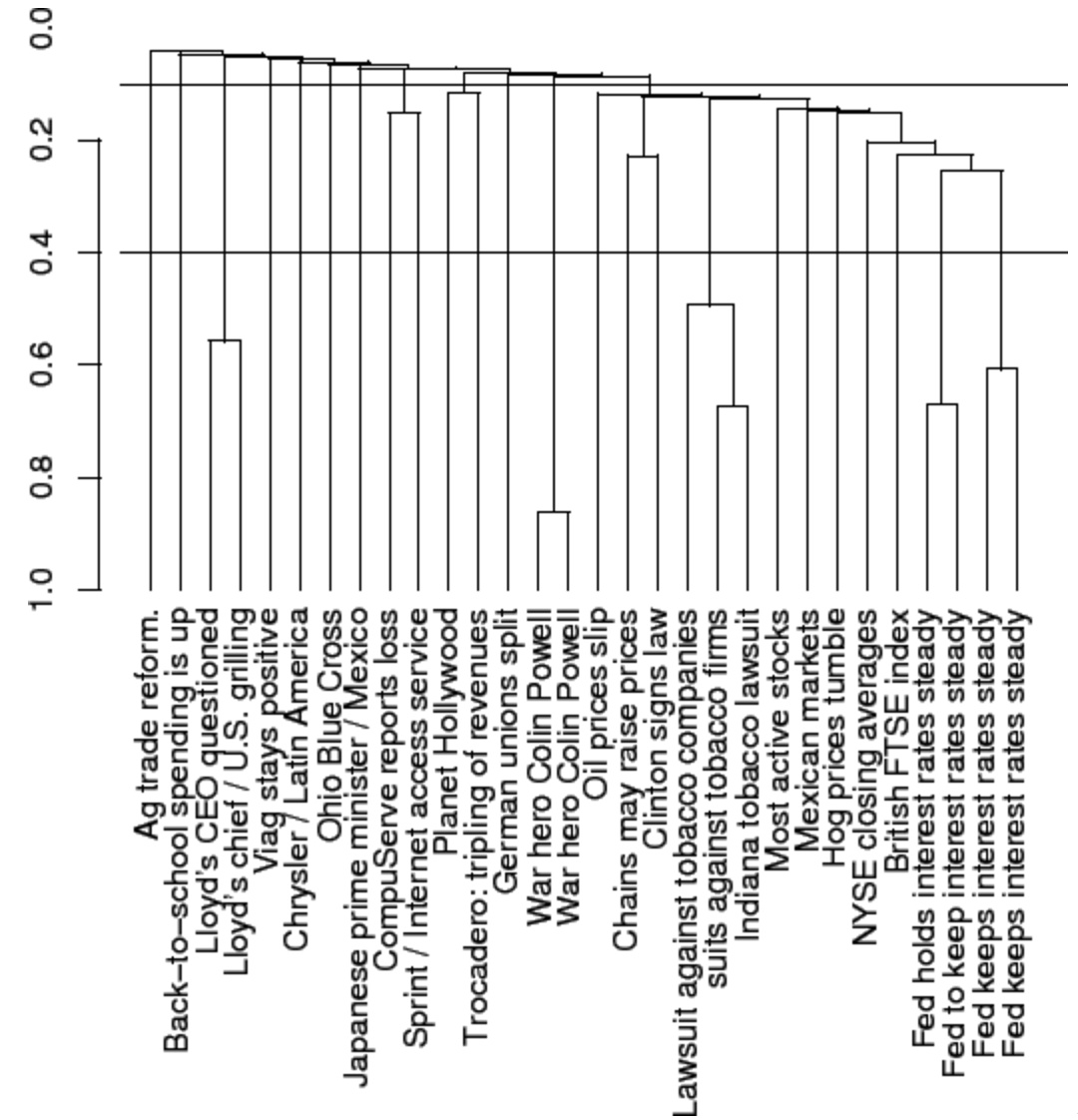
这是一种自下而上(bottom-up)的层次聚类,因此叫做层次凝聚聚类(Hierarchical Agglomerative Clustering),由于其计算点对距离时需要多次遍历,所以计算量可想而知,并且每次迭代只能合并两个聚类,时间复杂度上同样缺乏优势,因此实际应用中没有Flat clustering那么受欢迎,但是由于其避免了聚类数以及初始点的选择,而且不会陷入局部最优,在一些二次复杂度的问题中还是应该考虑的;在最早的CBIR系统中,HAC被应用到词袋技术中,如下图:

另外还有一种层次聚类算法,叫做自上而下的,这种形式的聚类主要是使用了一种分离聚类的方法,这里就不打算深入了,需要的可参考点击打开链接http://nlp.stanford.edu/IR-book/html/htmledition/hierarchical-agglomerative-clustering-1.html#sec:hac,里面有很详细的关于层次聚类的东西。

















 2437
2437

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









