







基本原理
-
Local模式的本质就是启动一个JVM Process进程(里面有多个进程),执行任务Task
- Local模式可以限制模拟Spark环境的线程数量,即Local[N] 或 Local[*]。
- N表示N个线程,每个线程拥有一个cpu核,默认为1,通常几个核指定几个线程。
- 如果是local[*],就是按照CPU最多的cores设置线程数。
-
Local角色分布:
- 资源管理
- Master:Local进程本身
- Worker:Local进程本身
- 任务执行:
- Driver:Local进程本身
- Executor:不存在,没有独立的Executor角色, 由Local进程(也就是Driver)内的线程提供计算能力。
- 资源管理
安装部署
- 解压安装包
安装包在此链接下载
tar -zxvf spark-3.2.0-bin-hadoop3.2.tgz -C /export/server/
mv spark-3.2.0-bin-hadoop3.2/ spark-3.2.0
- 设置环境变量
- SPARK_HOME: 表示Spark安装路径在哪里
- PYSPARK_PYTHON: 表示Spark想运行Python程序, 那么去哪里找python执行器
- JAVA_HOME: 告知Spark Java在哪里
- HADOOP_CONF_DIR: 告知Spark Hadoop的配置文件在哪里
- HADOOP_HOME: 告知Spark Hadoop安装在哪里
vim /etc/profile
#SPARK_HOME
export HADOOP_HOME=/export/server/spark-3.2.0
#pyspark虚拟环境
export PYSPARK_PYTHON=/export/server/anaconda3/envs/pyspark/bin/python3.8
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
source /etc/profile
#同样也需要在~/.bashrc上配置
- 启动pyspark
cd /export/server/spark-3.2.0/bin
./pyspark
#所有进程执行
./pyspark --master local[*]
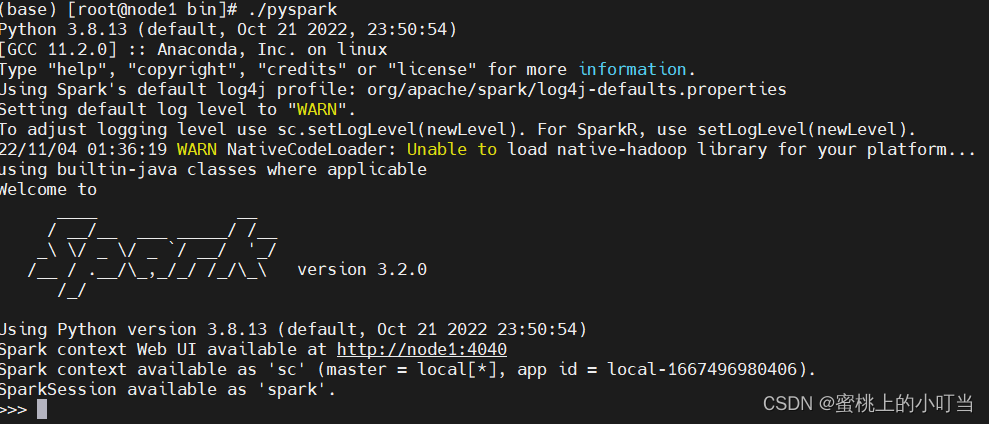
4. 测试数据
sc.parallelize([1,2,3,4,5]).map(lambda x: 2 * x + 1).collect()
#输出
[3, 5, 7, 9, 11]
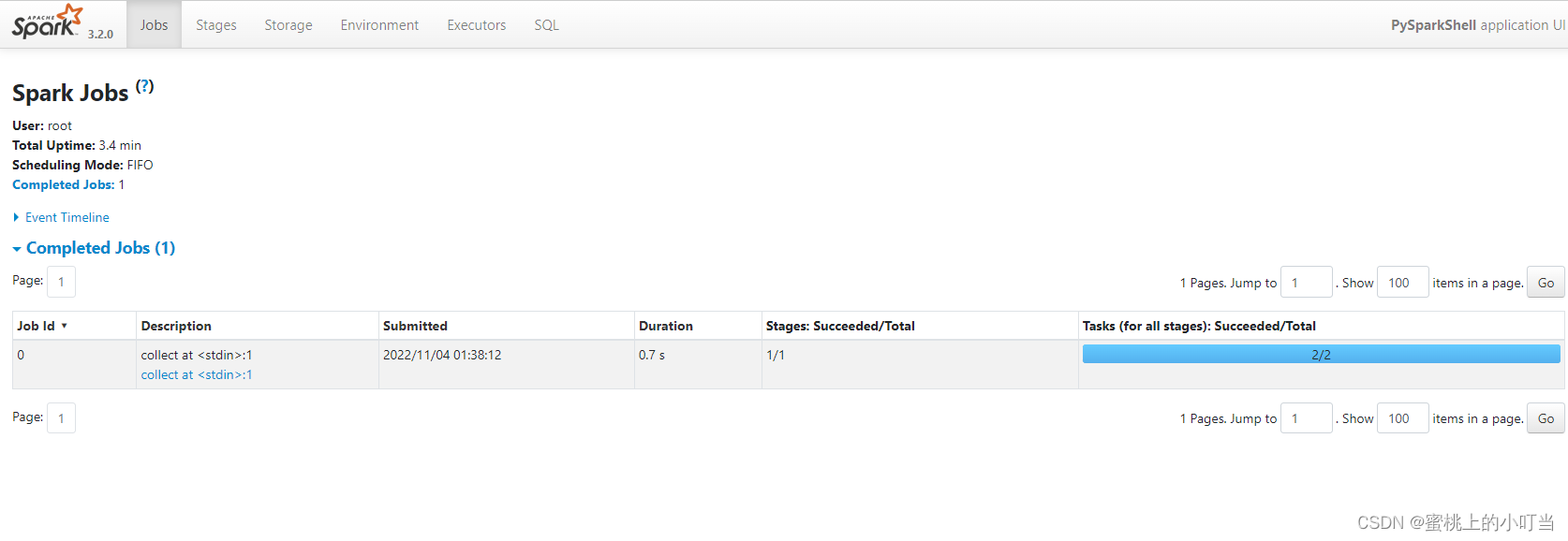
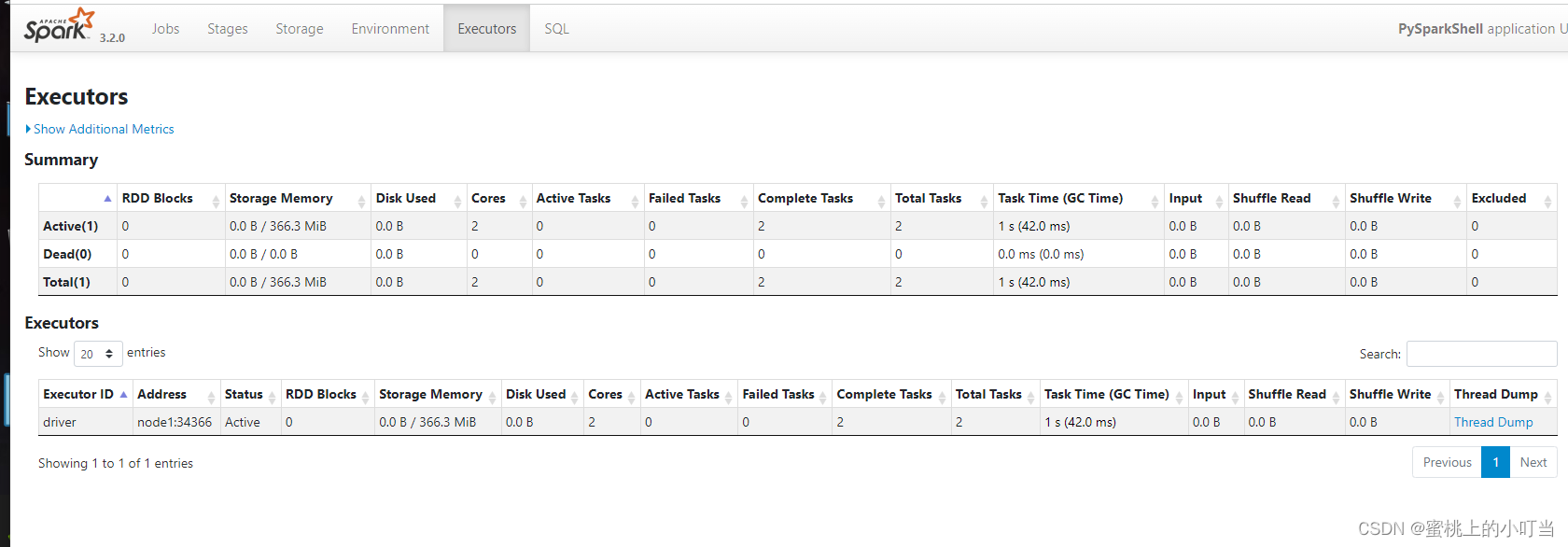
- 查看运行监控页面
输入地址:http://node1(主机的ip):4040
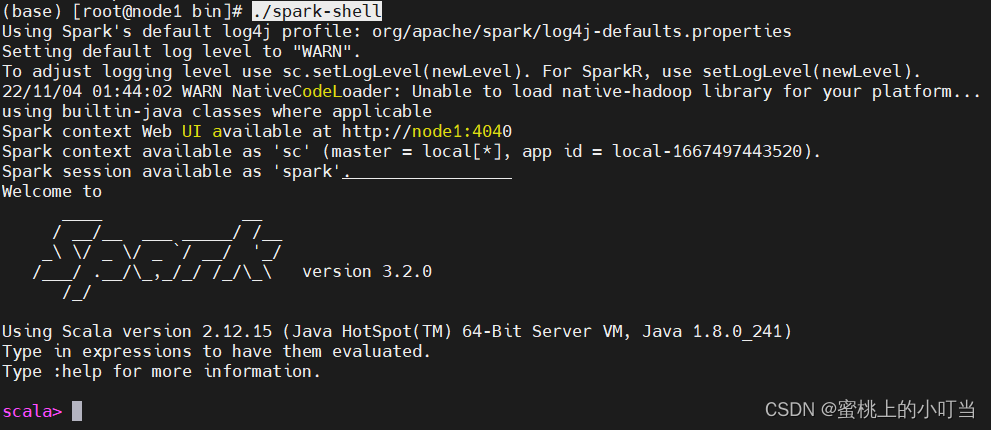
6. Scala环境测试
./spark-shell
sc.parallelize(Array(1,2,3,4,5)).map(x => 2*x + 1).collect()
#输出
res0: Array[Int] = Array(3, 5, 7, 9, 11)
7. spark-submit提交代码测试
./spark-submit --master local[*] /export/server/spark-3.2.0/examples/src/main/python/pi.py 10

总结
- Spark 4040端口表示spark的 job执行监控页面。如果在local模式下同时开启spark-shell和spark-shell两个环境,后面开启spark会绑定在4041端口上(端口顺延)。















 4611
4611











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









