







应用入口SC
- Spark Application程序入口是SparkContext简称SC,任何一个应用都需要构建sc对象。
- 第一步:创建SparkConf对象。
- 第二步:基于SparkConf对象创建SparkContext对象。
conf = SparkConf().setMaster("local[*]").setAppName("WordCountHelloWorld")
sc = SparkContext(conf=conf)
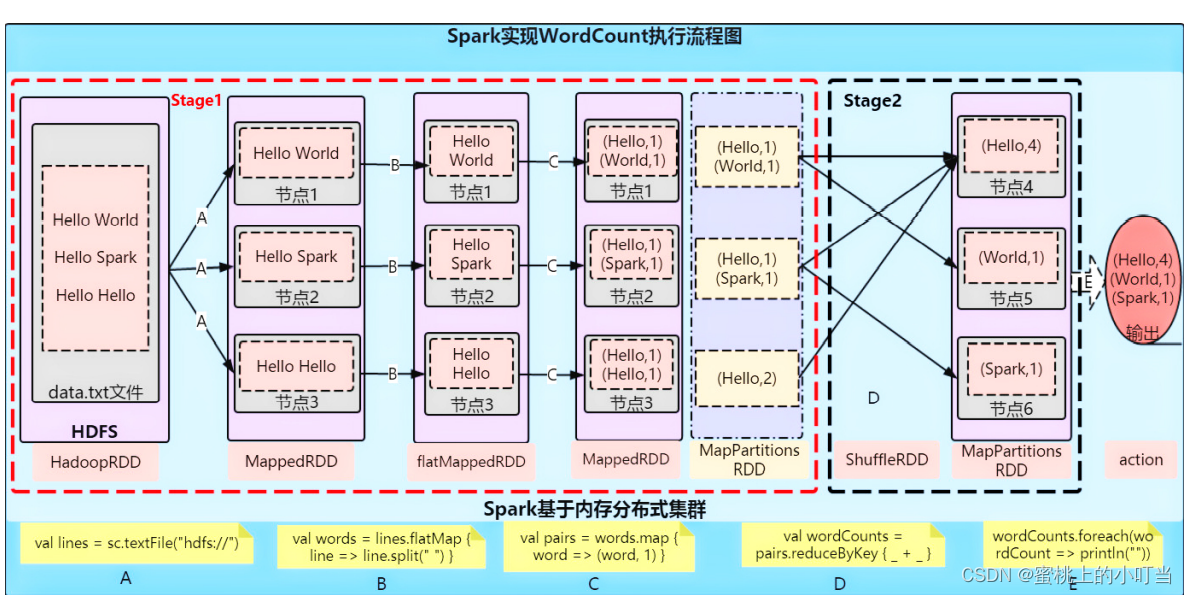
WordCount代码示例
- 原理分析
- 相比于Windows,Linux执行Spark程序效率会更高,我们可以使用Pycharm专业版通过SSH到Linux系统中去执行相关代码。
- 详细代码及示例:
# coding:utf8
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setMaster("local[*]").setAppName("WordCountHelloWorld")
# 通过SparkConf对象构建SparkContext对象
sc = SparkContext(conf=conf)
#读取HDFS上的文件
file_rdd = sc.textFile("hdfs://node1:8020/Test/WordCount.txt")
#将单词切割,得到一个存储全部单词的集合对象
words_rdd = file_rdd.flatMap(lambda line : line.split(" "))
#将单词转换为元组对象,Key是单词,Value是数字
words_with_one_rdd = words_rdd.map(lambda x: (x, 1))
#将元组的value按照key来分组,对所有的value进行聚合操作(相加)
result_rdd = words_with_one_rdd.reduceByKey(lambda a, b : a + b)
#通过collect方法手机数据打印结果
print(result_rdd.collect())

- 提交代码到群集里执行
需要删除代码中的setMaster
因为提交到集群可以通过客户端工具的参数指定master,比如spark-submit工具。所以,我们不在代码中固定master的设置,不然客户端工具参数无效,代码的优先级是最高的。
#在node1上创建一个py程序
vim wordcount.py
#将代码粘贴到py文件中
#执行spark-submit
/export/server/spark-3.2.0/bin/spark-submit --master local[*] wordcount.py

# 提交到Yarn执行
/export/server/spark-3.2.0/bin/spark-submit --master yarn wordcount.py

- 如果spark需要跑分布式,必须所有节点都需要有这个文件,单单只是想跑一个node上的文件,就会出现程序报错,假设如果运行成功,只有可能是Executor的数目比较小,并且只跑到了这一台node上了。
基于WordCount的Spark分布式代码执行分析
- SparkContext对象的构建,以及Spark程序的退出,由Driver执行。
- 具体的数据处理步骤,由Executor执行。
- 简单来说非数据处理是Driver、数据处理是Executor。
- Executor不仅仅是一个,而是群集规模,代码中的数据处理部分是由非常多的Executor来执行的,这也是分布式代码执行的概念。
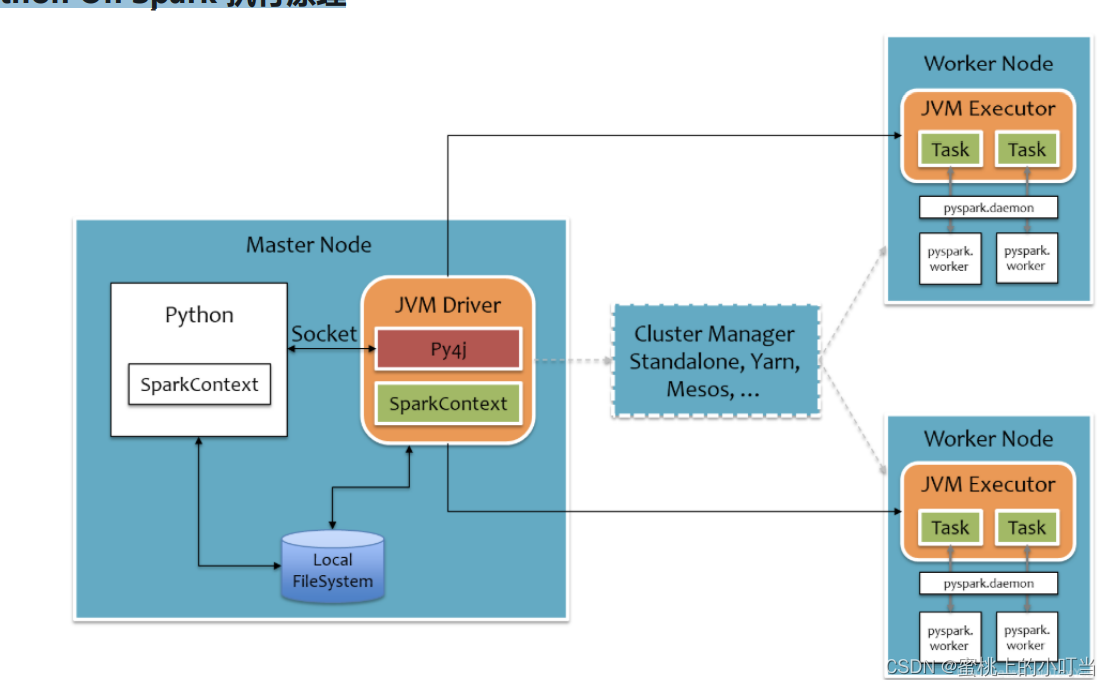
Python On Spark 执行原理
-
Python On Spark 执行原理架构图:
-
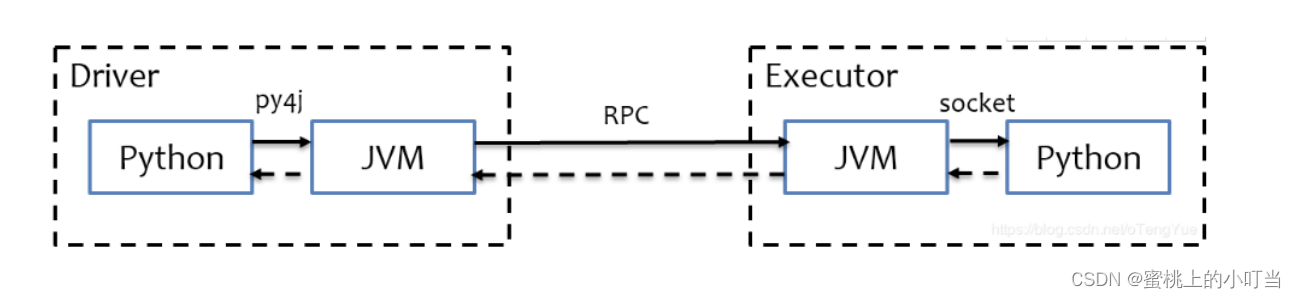
Spark本身执行是通过JVM Driver和JVM Executor去跑Spark程序的。而且Python是如何跑在Spark中,如上图白色部分为python的代码部分,需要通过一个socket网络通道去连接到JVM Driver中,然后通过Py4j来讲python程序翻译成JVM代码,变成JVMDriver来运行。而在Executor中,有很多python RDD算子是不兼容的,这个时候JVM Executor会开启pyspark.daemon的守护进程。然后通过守护进程来来让pyspark正常工作。总体来说Executor上,还是由python进程来工作的。
-
Python → JVM代码 → JVM Driver → RPC → 调用JVM Executor → PySpark中转 → Python Executor进程。














 486
486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









