







文章目录
- yolov4细节总结
- 目的
- introduction
- Related work
- Methodology
- Experiments
- Experimental setup
- Influence of different features on Classifier training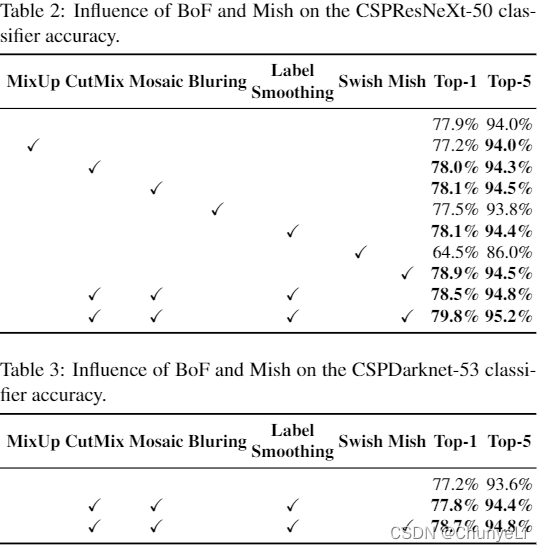
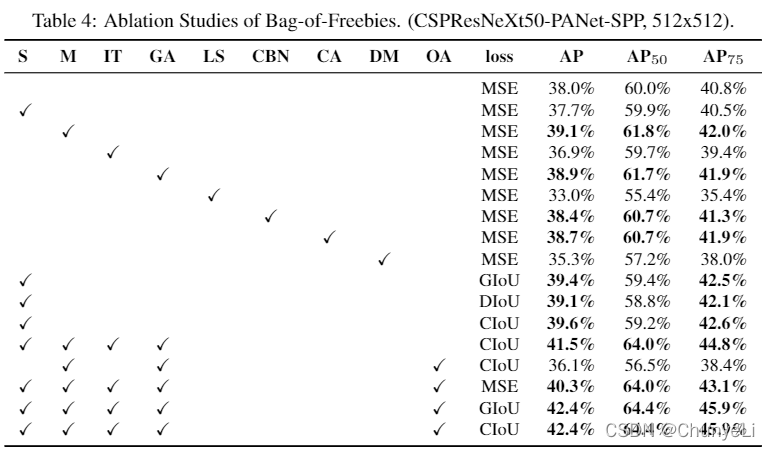
- Influence of different features on Detector training
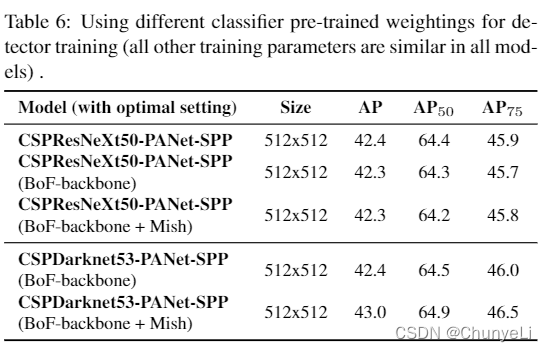
- Influence of different backbones and pretrained weightings on Detector training
- Influence of different mini-batch size on Detector training
yolov4细节总结
YOLOv4

目的
寻找CNN中的通用trick
introduction

实时(用一个GPU),训练也只用一个GPU,准确性高。

contributions
Related work
Object detection models
一个检测器:
①backbone(预训练)
②neck(提取不同阶段的特征)
③head(预测分类与回归)

Bags of freebies
其实就是数据增强和loss方面的一些trick。

数据增强(光度畸变和几何畸变、遮挡、MixUp)
1.光度畸变和几何畸变

2.遮挡,随机将一张图片的一个或几个矩形区域设置为0。

3.MixUp
将两张图片按照不同的系数比例相乘相加,label也是。
或者一张图片的被截取部分放到其他图片的矩阵区域。

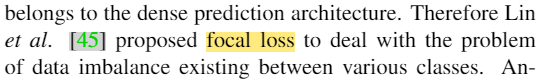
focal loss
4.数据不均衡问题
在二阶段检测中,用hard negative example mining or online hard example mining,但不适用于一阶段检测这种dense prediction architecture。在此用focal loss。
label smoothing

5.在处理标签时,用one-hot hard representation很难表示不同类别之间不同程度的关系,用label smoothing将hard改为soft,使得模型更鲁棒。
IoU loss


6.直接对BBox的坐标点或者偏移做MSE,失去目标的整体性。
所以用IoU loss。相关改善的还有GIoU、DIoU、CIoU。
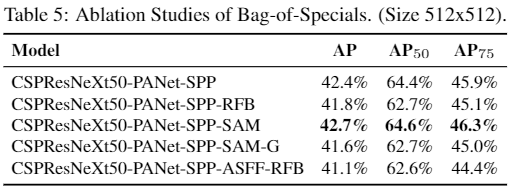
Bag of specials

一些插件模块和后处理方式只是少量增加了推理成本,但有效改善了目标检测的正确性。
即插件模块增强了模型的某些属性:增大感受野、引入注意力机制、增强特征整合能力、筛选模型预测结果的后处理方式。
增大感受野
SPP, ASPP, and RFB
SPP
源于Spatial Pyramid Matching (SPM)
SPM考虑空间信息,将图像分成若干块(sub-regions),分别统计每一子块的特征,最后将所有块的特征拼接起来,形成完整的特征,这就是SPM中的Spatial。在分块的细节上,采用了一种多尺度的分块方法,即分块的粒度越大越细(increasingly fine),呈现出一种层次金字塔的结构,这就是SPM中的Pyramid。

spp模块输出的是一维特征向量,不能直接输入FCN中。

将不同max-pooling的结果拼接,增大感受野。
ASPP

用空洞卷积?具体不理解,语言不顺。
RFB

都用空洞卷积,感受野更大
attention

SE在移动端用比较划算

SAM在GPU用比较划算
特征整合
早期用skip connection或者hyper-column,
后来多尺度预测方法比如FPN被提出。

SFAM:使用SE模块对多尺度连接的特征图做通道级重新加权;
ASFF:使用softmax作为逐点级别重新加权,然后添加不同比例的特征图;
BiFPN:用多输入加权残差连接来执行按比例的级别重新加权,然后添加不同尺寸的特征映射。
good activation function

好的激活函数让更有效地梯度下降,不会增加多余的计算损耗。
具体激活函数见原文。
后处理方式NMS

过滤预测目标效果差的BBox。
greedy NMS;
soft NMS;
DIoU NMS.
Methodology
为了实时性。

Selection of architecture
在输入网络分辨率、卷积层数量和参数量(filter siz^2 * filters * channel / groups)之间达到平衡。
在分类中,CSPResNext50 比 CSPDarknet53 好;
在检测中, CSPDarknet53 比 CSPResNext50 好。
相较于分类器,检测器需要:

实验论证:CSPDarknet53 更好

不同尺寸的感受野总结如下:
1.到目标的大小,能看到整个目标;
2.到网络的大小,能看到目标周围的内容;
3.超过网络大小,增加图像点和最终激活函数之间的链接数?
本文对CSPDarknet53增加SPP block,因为其增加了感受野,分离出最重要的内容特征,几乎不会下降网络的运行速度。
使用PANet作为从不同检测级别用不同backbone级别聚集参数的方法,替代YOLOv3中的FPN。
最终:CSPDarknet53为backbone, SPP为额外模块, PANet为neck, YOLOv3 (anchor based) 为head 作为YOLOv4的架构。
Selection of BoF and BoS
为了改善目标检测方法,CNN经常使用以下:

1.Activations: ReLU, leaky-ReLU, parametric-ReLU , ReLU6 , SELU , Swish, or Mish
(因为PReLU 和SELU难训练, ReLU6为量化网络设计)
2.Regularization: DropBlock
3.BN:syncBN不考虑
Additional improvements
为了更好在单个GPU上训练,进行额外设计:

Mosaic(数据增强)
4张图片拼接在一起形成一张图片,
可以检测正常情况之外的目标,BN会算上这4张图片的统计信息。
SAT(数据增强)
2个前后阶段:
1.神经网络改变原本的图片,而不是网络权重;神经网络对它自己进行对抗性攻击,改变原始图片,产生图像上原本没有的deception(欺骗);
2.训练神经网络在修改后的图像上按照正常方式检测目标。
CmBN
是CBN的改善体,仅在一个单批量的小批量之间收集统计信息。?
具体区别:
BN就是仅仅利用当前迭代时刻信息进行norm,而CBN在计算当前时刻统计量时候会考虑前k个时刻统计量,从而实现扩大batch size操作。同时作者指出CBN操作不会引入比较大的内存开销,训练速度不会影响很多,但是训练时候会慢一些,比GN还慢。
CmBN的做法和前面两个都不一样,其把大batch内部的4个mini batch当做一个整体,对外隔离。CBN在第t时刻,也会考虑前3个时刻的统计量进行汇合,而CmBN操作不会,不再滑动cross,其仅仅在mini batch内部进行汇合操作,保持BN一个batch更新一次可训练参数。
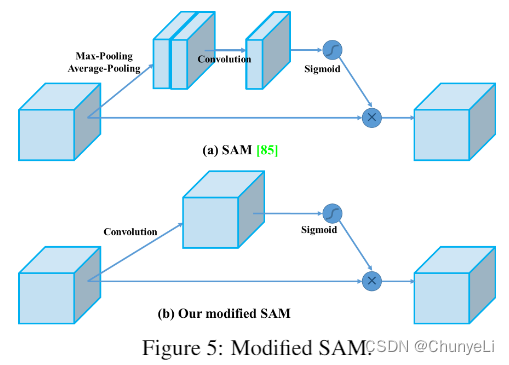
SAM
将spatial-wise attention 修改为pointwise attention
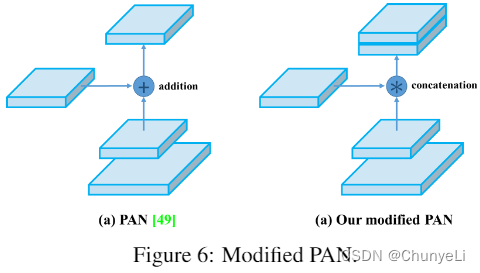
PAN
将PAN中的快捷连接替换为拼接
YOLOv4
BOF for detector中?
Experiments
在ImageNet上进行分类
在MS COCO上进行检测
Experimental setup
the batch size and the mini-batch size are 128 and 32?
ImageNet

COCO

Influence of different features on Classifier training

Influence of different features on Detector training

Influence of different backbones and pretrained weightings on Detector training

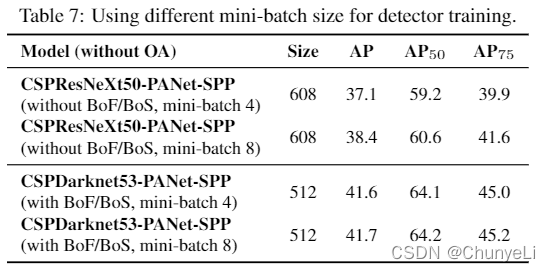
Influence of different mini-batch size on Detector training
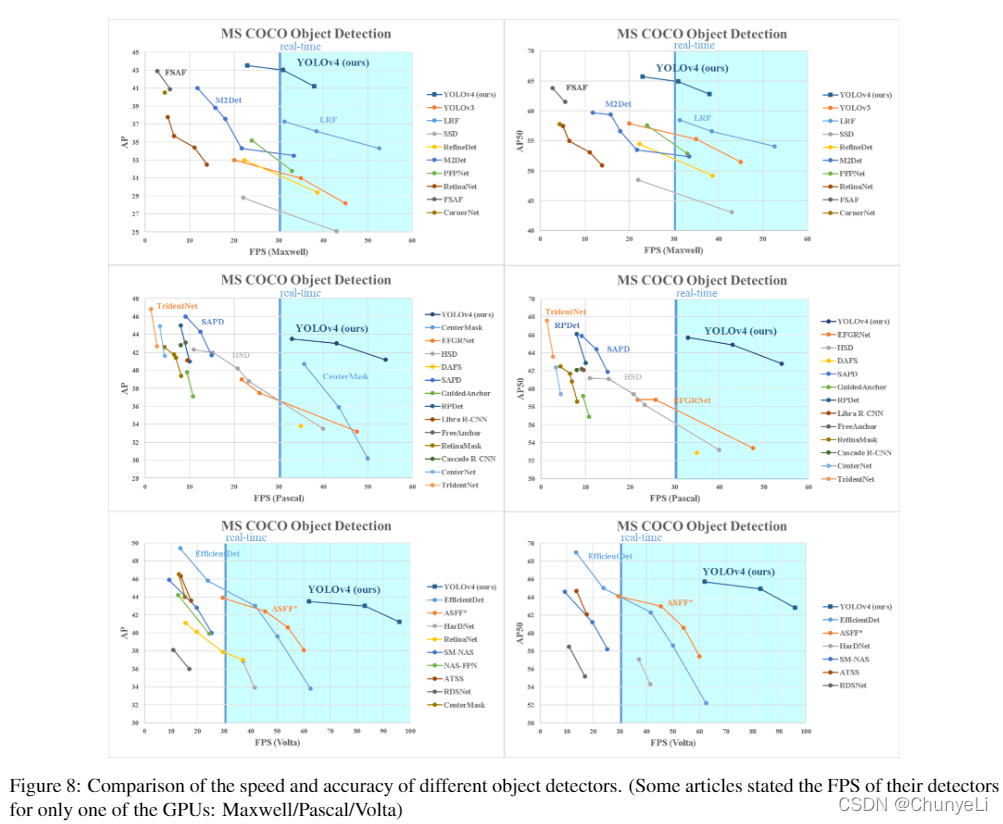
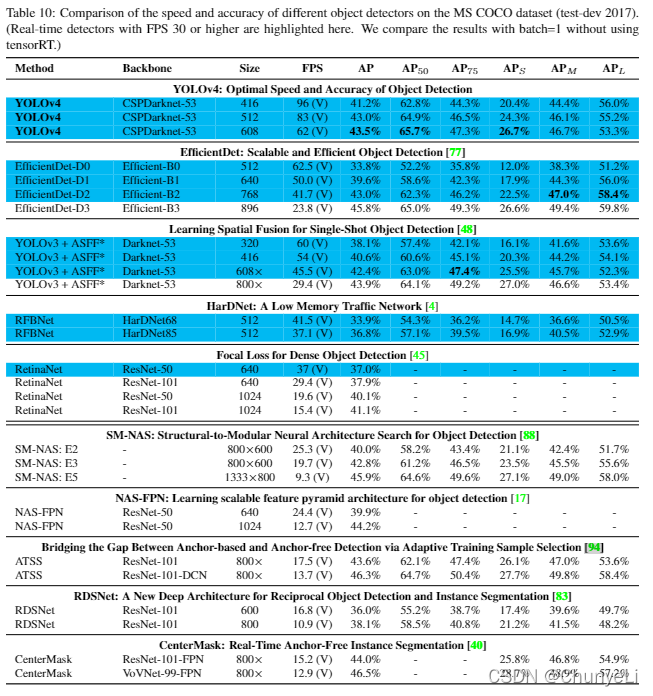
 不同体系的GPU,在不同的检测算法上
不同体系的GPU,在不同的检测算法上
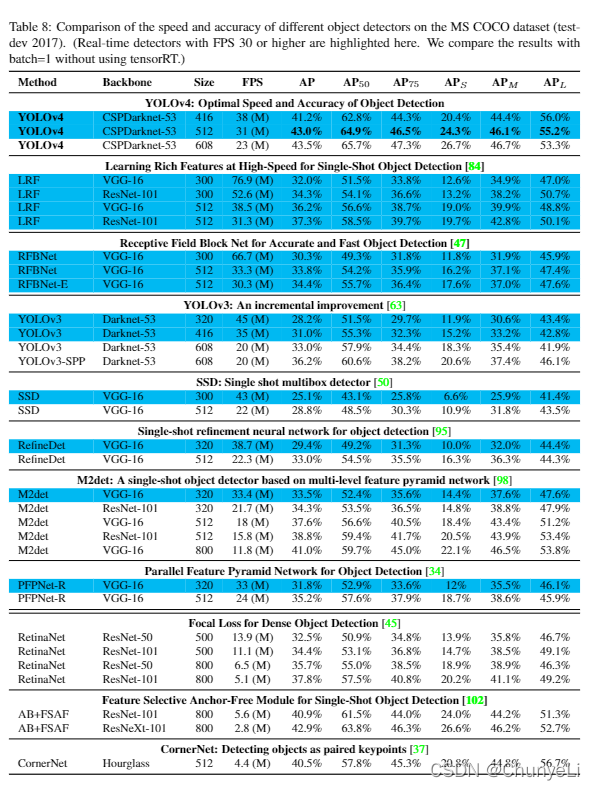
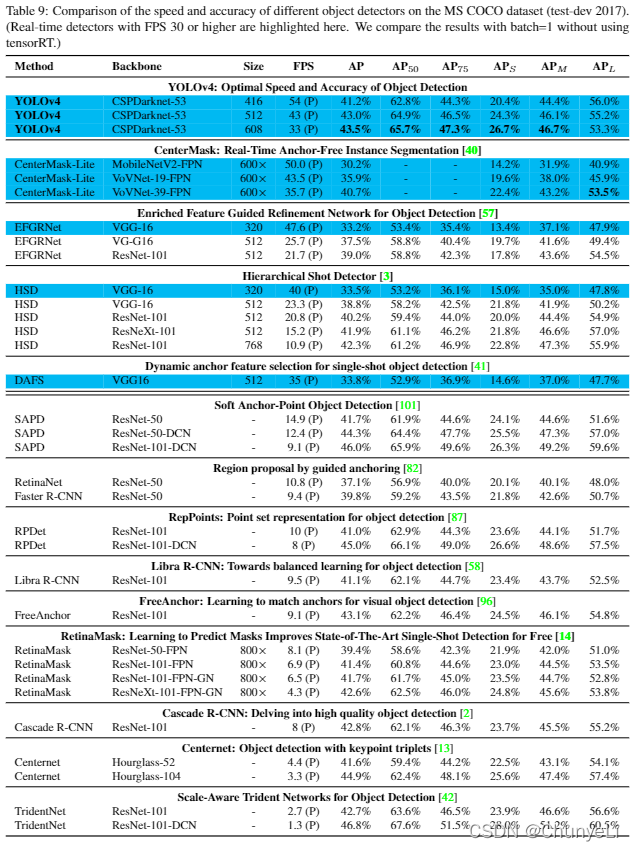














 3630
3630











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









