









前阵子读了一篇对比学习(Contrastive Learning)领域的经典论文《Representation Learning with Contrastive Predictive Coding》(Contrastive Predictive Coding 又简称 CPC),因为论文确实有点难理解,洛基也是在网上翻找了许多博客资料(在此对他们表示感谢,参考博文的链接会在文末附上),前后花了有一周时间,硬啃公式之后才理解了几成,所以在此把自己的理解记录一下,希望能帮到同样在看这篇论文的你们。
首先要说的是,对比学习是我的陌生领域,因为洛基现在主要从事NLP方向的工作,而对比学习在图像领域应用的更多,正是因为对该领域的陌生导致了我初看这篇论文时一头雾水。所以在讲这篇论文之前,就让我先从“对比学习”开始讲吧。
1 对比学习 Contrastive Learning
1.1 对比学习:动机
所谓“对比学习”是一个图像领域的重要概念,举个例子来说明对比学习的研究动机:我们都见过钞票,但是一般人都画不出一模一样的钞票,虽然我们还原不了钞票的完整信息,但是仍然可以一眼就识别出一张钞票,(这里不考虑假币的情况),那么基于这种现象,可以认为模型在学习representation的时候,并不一定要关注到样本的每个细节,只需要学到的特征能够使其和其他样本区别开来,这样的representation就能在一些任务上发挥良好效果了。
洛基是这样理解对比学习的:对比学习是为了在不关注样本全部细节的情况下,将样本转化为表征(representation,比如用一个编码器将数据编码成高维向量,就可以将得到的向量称为是数据的representation),使得representation包含了更显著的、重要的、有区分度的特征,学到这样的表示之后,用来帮助提升下游任务的性能。(有不同的见解欢迎批评指正~)
1.2 对比学习:目标
既然对比学习是要学习representation,直觉告诉我们,好的representation是要能具有区分度的,所谓区分度,举个例子说明:有三个样本组成的集合{x,x+,x-}, x+ 表示和 x 相似的样本, x- 表示和 x 不相似的样本,“区分度”意味着,x 的representation和 x+ 的representation要较为相似,而 x 的representation和 x- 的representation要较不相似,那样的representation就是有区分度的。
按照上面的思路,我们来理解一下对比学习的目标。
用 s(a, b) 表示计算 a 和 b 的相似度,f(·) 表示能将 x 转化为representation的映射函数,x+ 是相似样本,x- 是非相似样本,则对比学习的目标就是学习这个映射函数 f(·),使得 f(·) 满足下面的式子:
![]()
比较简单的一种向量相似度的计算方式,就是将向量经过归一化的激活函数之后,再做向量的内积操作。所以我们假设s(a,b)表示a和b的内积,那么那么我们希望给定一个样本x,要使得x的representation和所有x+的representation的内积尽可能大,而x和所有x-的representation的内积尽可能小。如果用一个二分类的softmax来表示的话,就是下面公式1的期望尽可能的大:
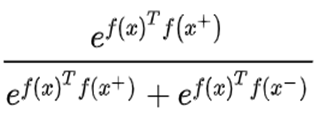 (公式1)
(公式1)
根据最大化期望的目标,也就可以推出损失函数的形式,为了方便求导,取1式的负对数作为损失函数即可,得到二分类的损失函数如公式2所示:
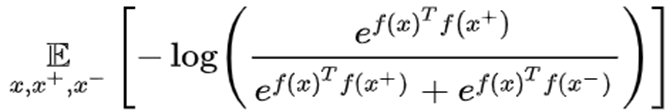 (公式2)
(公式2)
通常在实践中会设定每一轮优化时,采样N个样本,用1个相似本和N-1个不相似样本来计算损失(至于为什么这样采样,后面会讲),那么这个Loss就可以看做是一个 N 分类的交叉熵Loss,所以对比学习的损失函数又被表示成下面的公式3(该损失函数在对比学习的文章中被称为 InfoNCE Loss):
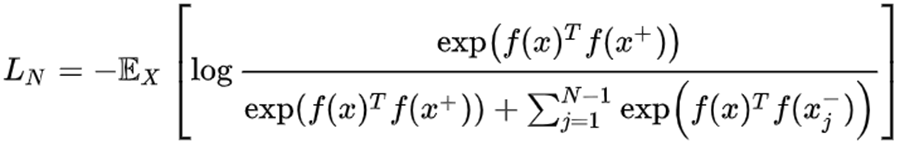 (公式3)
(公式3)
公式3是噪声对比估计(NCE)的损失函数,那么对上面的这个损失函数进行优化,就可以完成我们的最初的目标,也就是让x经过 f(·) 映射函数之后,得到的编码和 x+ 的编码相似度尽可能高,和 x- 的比编码相似度尽可能低。这是对比学习的一个通用的目标。其实这个优化过程和负采样的思路是相通的,做NLP的朋友应该熟悉word2vec词向量,word2vec有两个加速训练的方法,其中一个就是负采样,负采样可以i避免在整个词典上进行softmax时候计算量巨大的问题,而对比学习也是为了不对全局的特征进行建模,只关注重要的特征。
2 对比预测编码 Contrastive Predictive Coding
2.1 Contrastive Predictive Coding基本框架
理解了对比学习的大体思想,我们再来学习CPC的论文。本文会用一个从后往前推的思路来讲解CPC论文的思想,至于为什么从后往前推是因为这是洛基当时理解这篇文章的顺序,刚开始洛基从前往后看这篇论文的时候也是很多地方都不懂=。=!
好了接下来进入正题,先说CPC的模型框架,CPC的框架可以用下面这幅图来展示:

虽然上图是对语音序列的建模,但我们仍然可以从NLP的角度来理解。上图中,genc是单词的编码器,gar是自回归模型(比如RNN),zt是编码器对输入单词编码之后的representation,ct是通过自回归模型把t时刻以及之前所有时刻的representation考虑进去之后得到的上下文向量;绿色的方块,表示一个“预测+相似度计算”的全过程,具体地:先根据上下文向量Ct,用一个新的自回归模型(比如单个的GRU单元)得到的一个编码,这个编码用来表示当前时刻 t 的下一个单词【zt+1】的编码预测值,然后再把预测的编码和正样本 zt+4 这个representation 进行相似度计算。同理,红色方块就是计算预测编码和负采样的样本 zt* 进行相似度计算,注意,zt* 是从整个序列上随机采样的样本,与对比学习的“负样本”要区别开来。后面会说明为何作者是这样采样的。在明确上图中绿色方块和红色方块的过程之后,我们可以发现,损失函数的计算方式,就是绿色方块计算得到的相似度值与红色方块的相似度值,进行softmax之后的负对数似然损失,等价于对比学习的损失函数形式。论文中给出的损失函数是:
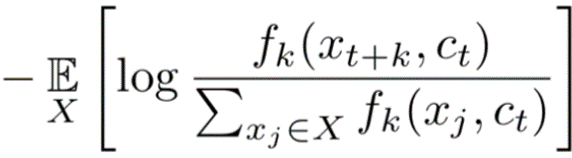 (公式4)
(公式4)
其中:![]()
2.2 对比预测编码的损失函数——最大化互信息的理解
现在我们已经知道了CPC的损失函数形式,和对比学习的损失如出一辙。不同的地方仅仅在于,正样本是当前时刻 t 之后的一定窗口内的单词,而负样本变成了整段序列随机采样的样本了。
假如我们从概率论的角度来理解这个损失函数,假如给定一段训练样本X={x1, x2, … xN},其中有1个样本是正样本,采样于p(xt+k|ct), 也就是t时刻的窗口内的样本分布,而其他样本是在整个序列上随机采样的,即采样于p(x),用d=i表示第i个样本xi是正样本,假如整段序列上随机采样了某个单词,模型要在给定上下文ct的情况下,预测该单词是正样本(即该单词是ct的下文)的概率,则通过全概率公式可以得到下面的式子:
 (公式5)
(公式5)
最大化公式5,就相当于使得给定上下文ct的情况下,正样本xi的概率最大化,而给定ct时候其他样本xj(j≠i)的概率之和最小,这个目标和CPC的损失函数(公式4)的优化目标是一致的。那么通过对对比公式4(CPC的损失函数)和公式5的形式,
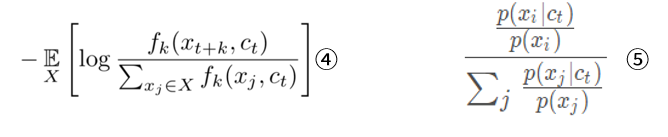
有什么发现?没错,最小化CPC的损失函数,等价于最大化损失函数的对数项里的那个分数,其效果等价于最大化公式5的期望值,所以论文中直接给出了那个让人初看时云里雾里的约束:
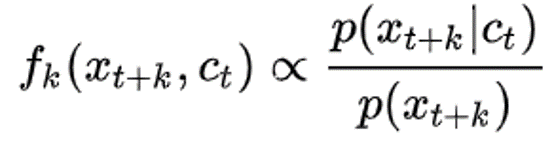 (公式6)
(公式6)
好了,接着往回推,来看论文最初提到的“互信息”这个概念。假如用H(x)表示x的熵,用以衡量x的不确定程度,则将互信息的定义公式进行展开,可以得到下面的结果:

可以看到,互信息可以表示在上下文 c 引入之后,使得 x 不确定性程度减小的量。
CPC论文的目标是最大化互信息,我们来对比一下互信息的表达式(下图的上面部分)以及公式6:
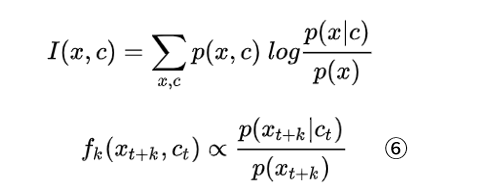
对比上图的两个公式,针对一段给定的序列,互信息表达式中的p(x,c)也是确定的,那么互信息的大小就取决于表达式右边的对数项 log[ p(x|c) / p(x) ],我们要最大化互信息,等价于让 log[ p(x|c) / p(x) ]的值最大化,而当该对数项满足公式6的约束条件时,最大化互信息等价于最大化 fk,也就等价于最小化CPC提出的那个损失函数了。综上所述,我们就完成了CPC论文思路的理解。
这里再解决一下之前提到的一个问题——为什么负采样是在整段序列上进行采样,那样不是会采样到窗口内的单词吗?这里说一下我个人的理解,欢迎指正。我们知道,正样本来源于 t 时刻的一定窗口内的单词,按照正常思路,负样本应该来源于窗口以外的单词,这里有一个问题,假如一段长的序列,窗口内的单词在窗口外也出现了(比如“你,我”等常见词),这仍然不能避免负采样取到窗口内单词。所以作者直接在整段序列上进行负采样,负样本来源于整段序列的分布,正样本来源于窗口内单词的分布,这样做是为了让模型在给定一个context情况下判断某个样本来源于窗口内分布还是整段序列的噪声分布,也就是只需要模型可以区分窗口内分布和整段序列的噪声分布,这其实是一种退而求其次的方法,因为负采样本身就是为了避免在整个词典上进行softmax的开销过大问题,假如纠结负采样会采样到真实样本,那么干脆直接不要负采样,就在整个词典上进行正样本与其他单词的区分就好了(这样做显然是没必要的)。所以,CPC论文的负采样就直接在整段序列上进行采样,当序列长度足够长,且负采样的次数足够多时,这么做是能够很好的模拟真实噪音分布的,而CPC的论文实验部分也证明了这一点。
3 参考文献
https://spaces.ac.cn/archives/6024 深度学习的互信息:无监督特征提取 【科学空间】
https://zhuanlan.zhihu.com/p/137076811 浅析Contrastive Predictive Coding 【知乎】
https://zhuanlan.zhihu.com/p/75517749 真正的无监督学习之一——Contrastive Predictive Coding 【知乎】
https://zhuanlan.zhihu.com/p/141141365 对比学习(Contrastive Learning)相关进展梳理 【知乎】
https://blog.csdn.net/newworld123made/article/details/103450690 论文阅读:Representation Learning with Contrastive Predictive Coding 【CSDN】















 4785
4785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









