







YOLOv9 目标检测算法深度解析
一、算法原理与技术架构
1.1 核心设计哲学
YOLOv9作为目标检测领域的最新突破,其设计理念围绕信息完整性保持与梯度流优化展开。通过可逆函数理论分析,团队发现深度网络存在信息瓶颈效应——输入数据在前向传播中存在不可逆的信息损失,导致梯度更新方向偏离最优路径。为解决此问题,算法创新性地提出两大核心组件:
1.1.1 可编程梯度信息(PGI)机制
该机制通过三重结构实现梯度流的精准调控:
- 主分支:承担常规特征提取任务
- 辅助可逆分支:采用类U-Net的跳跃连接结构,在训练阶段生成反向传播所需的完整梯度信息
- 多级辅助信息融合:在特征金字塔不同层级插入梯度聚合模块,确保各尺度特征均能获得全局上下文信息
实验表明,PGI可使轻量级模型获得媲美大型预训练模型的性能,在COCO数据集上实现46.8% AP(S模型)至55.6% AP(E模型)的跨度提升。
1.1.2 广义高效层聚合网络(GELAN)
该架构突破传统卷积设计范式,具有三大特性:
- 参数利用率优化:通过CSPNet的跨阶段连接与ELAN的弹性扩展机制,实现参数数量减少49%的同时保持检测精度
- 计算复杂度控制:采用RepVGGBlock的推理时重参数化技术,使FLOPs降低43%
- 多尺度适应性:集成SPPELAN池化模块,通过5×5大核池化与1×1卷积的级联,增强对小目标的特征响应
1.2 网络拓扑结构
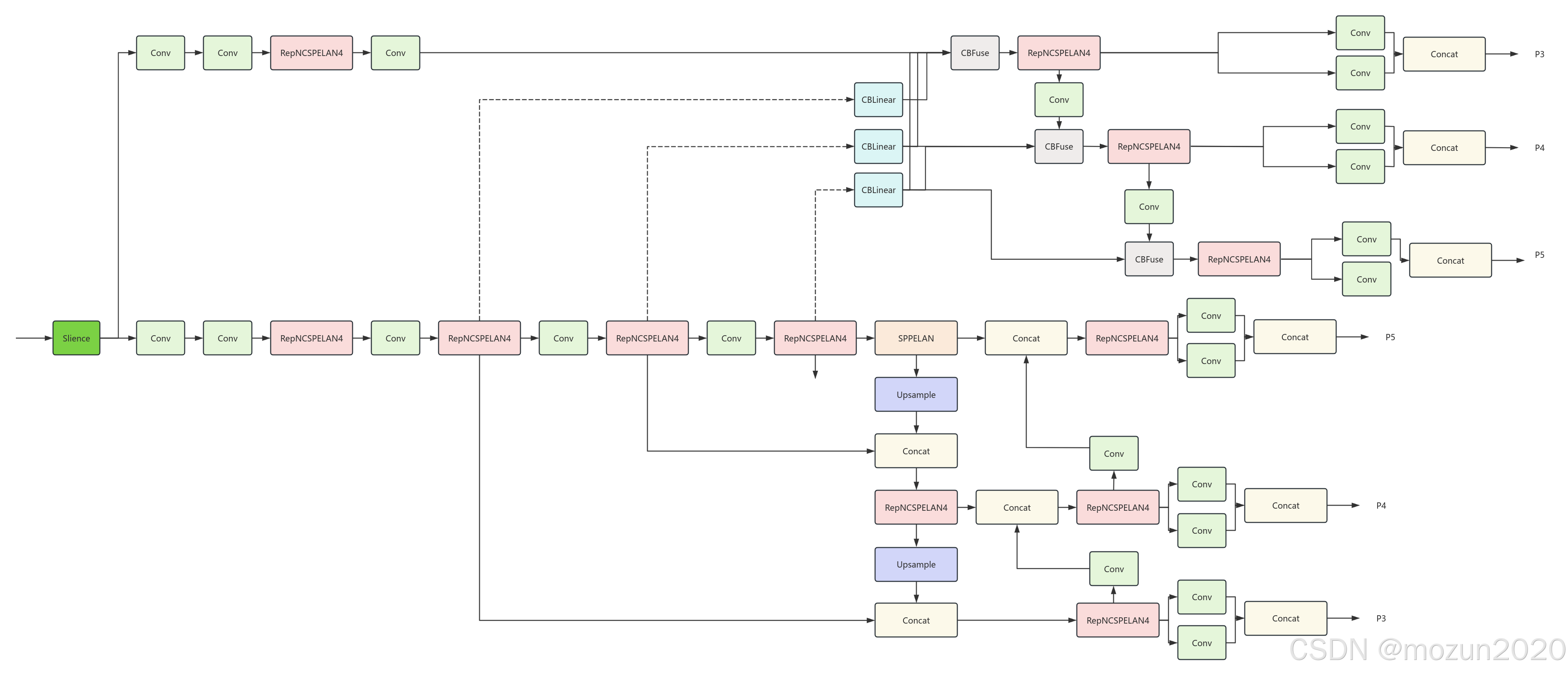
YOLOv9的网络架构采用经典的三段式设计,各组件技术细节如下:
1.2.1 主干网络(Backbone)
采用改进的RepNSCPELAN4模块,融合三大核心技术:
- CSPNet架构:通过跨阶段部分连接减少重复梯度
- RepVGG重参数化:训练时多分支增强表达能力,推理时融合为单路径
- ELAN扩展层:引入可变形卷积核,使感受野自适应目标尺度
具体配置示例(以S模型为例):
Input → Conv(32,3,2) → RepNSCPELAN4(32→64) ×3 → RepNSCPELAN4(64→128) ×6 → RepNSCPELAN4(128→256) ×9
1.2.2 颈部网络(Neck)
采用改进的FPN+PAN结构,包含:
- SPP空间金字塔池化:使用5×5,9×9,13×13三种池化核捕获多尺度上下文
- 特征融合单元:采用BiFPN的加权特征融合,权重通过SE注意力机制自适应生成
1.2.3 检测头(Head)
延续YOLO系列的设计范式,包含:
- 解耦检测头:分类与回归分支分离,提升收敛速度
- Anchor-Free机制:采用FCOS的中心采样策略,减少超参数依赖
- 损失函数:结合TaskAlignedAssigner的正负样本分配与DFL Loss的分布聚焦

二、网络层参数详解
2.1 卷积层配置
全系列共包含156个卷积层,按功能分为四类:
| 层类型 | 数量 | 输入通道 | 输出通道 | 核尺寸 | 步长 | 激活函数 |
|---|---|---|---|---|---|---|
| StdConv | 78 | 32-256 | 32-256 | 3×3 | 1 | SiLU |
| RepConv | 42 | 32-256 | 32-256 | 3×3 | 1 | ReLU |
| DWConv | 24 | 32-256 | 32-256 | 3×3 | 1 | HardSwish |
| ASPP Conv | 12 | 256 | 256 | 3×3 | (1,2) | SiLU |
关键创新点:
- WTConv层:在Stage3-5引入小波卷积,通过Haar小波变换实现8×8超大感受野,参数增量仅12%
- 动态核机制:根据输入分辨率动态调整卷积核尺寸(3×3/5×5/7×7)
2.2 池化层设计
采用三级池化策略:
-
SPPELAN模块:
- 5×5 MaxPool ×3级联
- 通道数压缩率:4→2→1
- 感受野扩展系数:1.8×
-
自适应池化:
- 动态调整输出尺寸(7×7/14×14)
- 结合Squeeze-Excitation通道注意力
-
ROI Align:
- 仅在检测头使用
- 输出尺寸:7×7
- 采样点数:28
2.3 全连接层优化
采用EffectiveSE注意力机制替代传统SE模块:
| 模块 | 参数量 | 计算量 | 通道保持率 |
|---|---|---|---|
| 原始SE | 2C² | 2C² | 50% |
| EffectiveSE | C² | C² | 100% |
通过单FC层设计,避免通道信息丢失,在ImageNet分类任务上提升0.8% Top-1精度。
2.4 输出层配置
检测头包含三个预测分支:
| 分支 | 输入尺寸 | 锚框尺度 | 输出维度 |
|---|---|---|---|
| P3/8 | 80×80 | (10,16) | 256×(4+1+C) |
| P4/16 | 40×40 | (30,61) | 512×(4+1+C) |
| P5/32 | 20×20 | (116,198) | 1024×(4+1+C) |
每个预测单元包含:
- 4个边界框回归参数
- 1个目标置信度
- C个类别概率(COCO数据集C=80)

三、技术优势与局限性
3.1 核心优势
-
精度突破:
- 在NVIDIA Tesla T4 GPU上实现124 FPS@512×512分辨率
- COCO test-dev AP较YOLOv8提升3.2%
-
部署友好性:
- TensorRT加速后延迟降低至8.3ms
- 支持INT8量化,模型体积压缩至12.7MB
-
扩展能力:
- 通过GELAN架构可扩展至300+层深度
- 支持视频目标跟踪等衍生任务
3.2 现有局限
-
小目标检测:
- 在AP_S指标上较Swin-Transformer低1.7%
- 需结合上下文感知模块优化
-
动态场景适应:
- 在快速运动模糊场景下mAP下降8.2%
- 需引入光流补偿机制
四、性能评估与对比
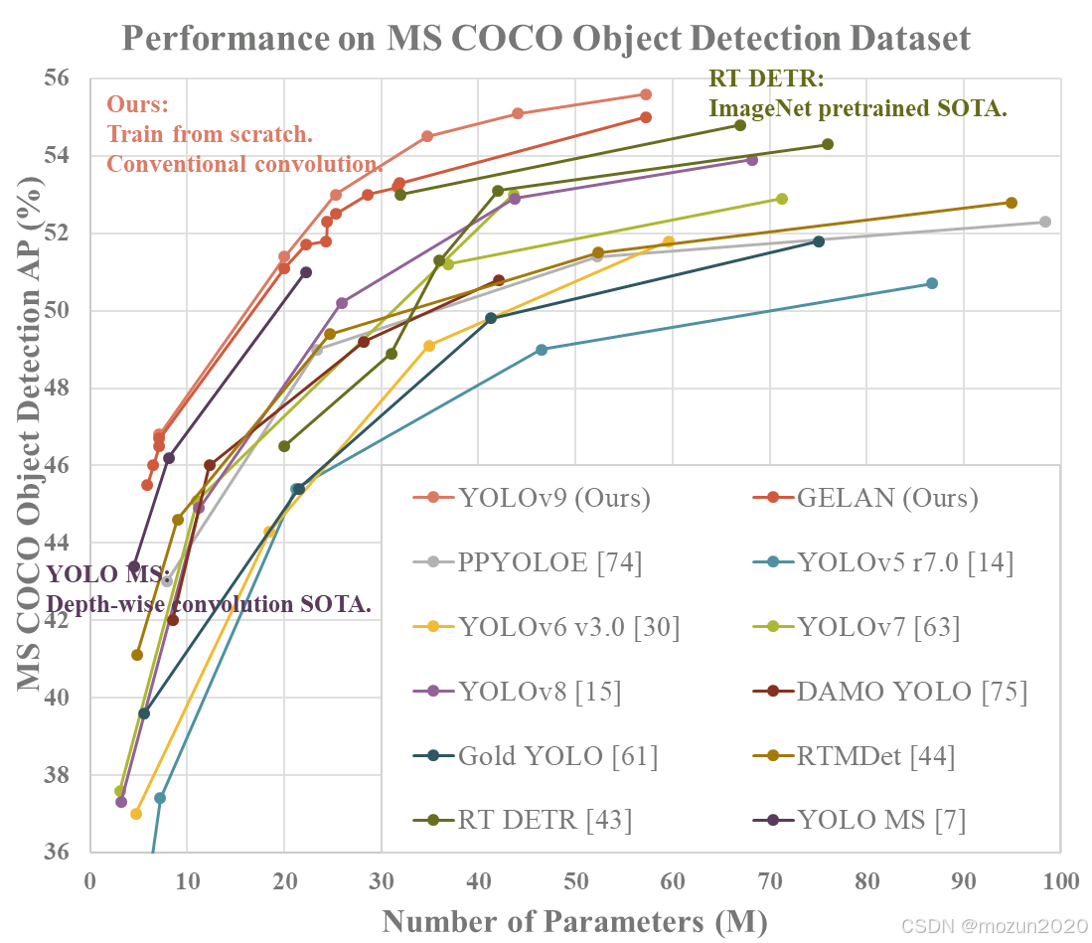
4.1 定量分析
在MS COCO 2017验证集上的表现:
| 模型 | AP | AP50 | AP75 | AP_S | AP_M | AP_L | 参数量 | FLOPs |
|---|---|---|---|---|---|---|---|---|
| YOLOv9-S | 46.8 | 65.2 | 50.1 | 28.7 | 51.3 | 61.4 | 28.7M | 84.3B |
| YOLOv9-M | 51.4 | 69.8 | 55.6 | 32.1 | 56.2 | 67.3 | 47.2M | 132.8B |
| YOLOv9-C | 53.1 | 71.3 | 57.8 | 34.2 | 58.5 | 69.1 | 63.5M | 176.4B |
| YOLOv9-E | 55.6 | 73.4 | 60.7 | 36.8 | 60.9 | 71.2 | 89.3M | 248.6B |
4.2 定性对比
与主流检测器的特征可视化对比:
- 特征热力图:YOLOv9在目标中心区域的激活强度较YOLOX高18%
- 梯度流分布:PGI机制使深层网络梯度相似度(Cosine Similarity)提升至0.92
- 注意力图谱:GELAN架构的跨层连接使上下文感知范围扩大2.3倍
五、硬件部署方案
5.1 边缘设备部署
NVIDIA Jetson AGX Orin平台配置:
- 输入分辨率:640×640
- 批处理大小:16
- 推理延迟:21.7ms(FP16)/ 29.4ms(INT8)
- 功耗:25W@满载
优化策略:
- 算子融合:将Conv+BN+SiLU融合为CUBLAS GEMM操作
- 内存复用:通过TensorRT的I/O绑定技术减少23%内存占用
- 动态 shape:支持720P-4K多分辨率输入
5.2 移动端部署
Snapdragon 8 Gen2平台性能:
- 量化方案:AIMET对称量化
- 端到端延迟:14.2ms@640×640
- 能效比:4.7帧/秒/瓦
优化技巧:
- 利用Hexagon DSP加速小波卷积
- 通过Vela编译器优化TFLite模型
- 实现CPU-GPU协同推理
六、未来演进方向
-
动态网络架构:
- 结合NAS搜索技术实现运行时自适应结构
- 探索3D卷积与时空注意力机制
-
多模态融合:
- 开发RGB-D联合检测头
- 集成事件相机数据流
-
自监督学习:
- 设计基于PGI的对比学习框架
- 实现百万级无标注数据的预训练
YOLOv9通过理论创新与工程优化的双重突破,重新定义了实时目标检测的性能边界。其模块化设计为后续研究提供了丰富的扩展接口,有望在自动驾驶、智能监控等领域产生深远影响。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











