







 本文介绍了作者在数学建模比赛中的经历,强调了算法的重要性。作者参与了国赛和美赛,了解到论文质量在比赛中起到关键作用。在解决2021年研究生数学建模竞赛B题——空气质量预报二次建模时,利用WRF-CMAQ模型基础,通过Stacking机器学习混合模型提高了预测准确性,特别关注了气象条件、协同预报对预测效果的影响,并对比了不同模型的优劣。
本文介绍了作者在数学建模比赛中的经历,强调了算法的重要性。作者参与了国赛和美赛,了解到论文质量在比赛中起到关键作用。在解决2021年研究生数学建模竞赛B题——空气质量预报二次建模时,利用WRF-CMAQ模型基础,通过Stacking机器学习混合模型提高了预测准确性,特别关注了气象条件、协同预报对预测效果的影响,并对比了不同模型的优劣。
1.数学建模经验
首先简要的介绍一下我的情况。数学建模我也是在大一暑假开始接触的,之前对其没有任何的了解。我本身对数学也有相对较厚的兴趣,同时我也是计算机专业的学生,因此,我觉得我可参加数学建模的这个比赛。大一的暑假参加了国赛,获得了国一;大二的寒假参加了美赛,成绩还未知。
接下来,说说我在比赛前后的感受。比赛前,对数学建模缺少足够的了解,只知道数学建模分为3个部分:建模,编程,论文。同时,我也参加了为期一个月的培训。由于本人当时乏自信,害怕前面几个步骤卡壳,最终还是选择了论文这一部分。我也和大部分的同学一样认为论文是最不重要的,只要模型好,编程算法好就行。但是,最终我们辅导老师告诉我,我们这一组是以论文取胜的。模型与算法都只是基本的,并没有什么出彩的地方。
因此,总的来说,在比赛之前,需要相对系统性的比赛培训,特别是对算法的掌握。算法是解决问题的很重要的一部分。我推荐可以自己或者要求老师给你们讲一下姜启源老师的《模型与算法》这一本书,这本书是数学建模的经典书本。培训对于三个参加比赛的同学可以不同侧重去掌握,但是每个人至少是一门精通,一门掌握,一门了解。在培训后,会对数学建模这个比赛有一定的了解,在此了解之上可以开始正式做题目写论文了。
若是参加国赛,则可以挑选前几年国赛的题目,因为这些题目是有优秀论文的,可以参考这些优秀论文,学习优秀论文的写作手法,学习优秀论文他们写的模型和程序。这些题目最适合入门级的同学做的。我们组在比赛前总共做了7题国赛题目,且都基本完成论文:
2.实战参考:2021年中国研究生数学建模竞赛B题:空气质量预报二次建模
数据挖掘机器学习[七]---2021研究生数学建模B题空气质量预报二次建模求解过程:基于Stacking机器学习混合模型的空气质量预测{含码源+pdf文章}
https://blog.csdn.net/sinat_39620217/article/details/124353644
大气污染系指由于人类活动或自然过程引起某些物质进入大气中,呈现足够的浓度,达到了足够的时间,并因此危害了人体的舒适、健康和福利或危害了生态环境[1]。污染防治实践表明,建立空气质量预报模型,提前获知可能发生的大气污染过程并采取相应控制措施,是减少大气污染对人体健康和环境等造成的危害,提高环境空气质量的有效方法之一。
目前常用 WRF-CMAQ模拟体系(以下简称WRF-CMAQ模型)对空气质量进行预报。WRF-CMAQ模型主要包括WRF和CMAQ两部分:WRF是一种中尺度数值天气预报系统,用于为CMAQ提供所需的气象场数据;CMAQ是一种三维欧拉大气化学与传输模拟系统,其根据来自WRF的气象信息及场域内的污染排放清单,基于物理和化学反应原理模拟污染物等的变化过程,继而得到具体时间点或时间段的预报结果。WRF和CMAQ的结构如图 1、图 2所示,详细介绍可以在附录提供的官网中进行查询
但受制于模拟的气象场以及排放清单的不确定性,以及对包括臭氧在内的污染物生成机理的不完全明晰,WRF-CMAQ预报模型的结果并不理想。故题目提出 二次建模概念:即指在WRF-CMAQ等一次预报模型模拟结果的基础上,结合更多的数据源进行再建模,以提高预报的准确性。其中,由于实际气象条件对空气质量影响很大(例如湿度降低有利于臭氧的生成),且污染物浓度实测数据的变化情况对空气质量预报具有一定参考价值,故目前会参考空气质量监测点获得的气象与污染物数据进行二次建模,以优化预报模型。二次模型与WRF-CMAQ模型关系如图 3所示。为便于理解,下文将WRF-CMAQ模型运行产生的数据简称为“ 一次预报数据”,将空气质量监测站点实际监测得到的数据简称为“ 实测数据”。一般来说,一次预报数据与实测数据相关性不高,但预报过程中常会使用实测数据对一次预报数据进行修正以达到更好的效果。
问题1. 使用附件1中的数据,按照附录中的方法计算监测点A从2020年8月25日到8月28日每天实测的 AQI和首要污染物,将结果按照附录“AQI计算结果表”的格式放在正文中。
问题2. 在污染物排放情况不变的条件下,某一地区的气象条件有利于污染物扩散或沉降时,该地区的AQI会下降,反之会上升。使用附件1中的数据,根据对污染物浓度的影响程度,对气象条件进行合理分类,并阐述各类气象条件的特征。
问题3. 使用附件1、2中的数据,建立一个同时适用于A、B、C三个监测点(监测点两两间直线距离 >100km,忽略相互影响)的二次预报数学模型,用来预测未来三天6种常规污染物单日浓度值,要求二次预报模型预测结果中AQI预报值的 最大相对误差应尽量小,且 首要污染物预测准确度尽量高。并使用该模型预测监测点A、B、C在2021年7月13日至7月15日6种常规污染物的单日浓度值,计算相应的AQI和首要污染物,将结果依照附录“污染物浓度及AQI预测结果表”的格式放在论文中。
问题4. 相邻区域的污染物浓度往往具有一定的 相关性,区域协同预报可能会提升空气质量预报的准确度。如图 4,监测点A的临近区域内存在监测点A1、A2、A3,使用 附件1、3中的数据,建立包含A、A1、A2、A3四个监测点的协同预报模型,【联合】要求二次模型预测结果中AQI预报值的最大相对误差应尽量小,且首要污染物预测准确度尽量高。使用该模型预测监测点A、A1、A2、A3在2021年7月13日至7月15日6种常规污染物的单日浓度值,计算相应的AQI和首要污染物,将结果依照附录“污染物浓度及AQI预测结果表”的格式放在论文中。并讨论: 与问题3的模型相比,协同预报模型能否提升针对监测点A的污染物浓度预报准确度?说明原因。---------要提升才行
具体word题目链接见:
2021年B题空气质量预报二次建模.zip-机器学习文档类资源-CSDN下载
1.基于Stacking机器学习混合模型的空气质量预测
摘 要:
大气污染系指由于人类活动或自然过程引起某些物质进入大气中,空气污染严重时,会对人体健康产生较大危害,空气质量指数(AQI)用来衡量空气质量状况,建立空气质量预报模型,预测可能发生的大气污染并采取相应控制措施,有利于减少大气污染对人体和环境等造成危害。
针对问题一、需要对原始数据进行简单的计算,原始数据来自于附件1中的监测点A从2020年8月25日到8月28日污染物浓度实测数据,这几天产生空气污染的首要污染物均为臭氧。
针对问题二、首先通过数据探索性分析对数据进行预处理,发现污染物分布符合无界约翰逊(Johnson SU)分布并做长尾截断处理,之后对数据进行归一化;其次通过相关性分析、顺序特征选择法(SFS)以及L1、L2正则化和弹性网络(ElaticNet)进行WRF-CMAQ预测气象特征进行筛选。随后对AQI进行动态分析,根据季节月份天数进行动态追踪分析,并采用聚类算法对气象分类进行验证,得到气象分类特征。
针对问题三、首先以A测试站点进行建模,根据筛选出来的气象特征和污染物变量特征;通过LGBM、Xgboots以及ElaticNet优化后的RNN和LSTM算法进行初次模型预测,同时采用贪心策略和贝叶斯网络对算法参数优化,衡量指标得到明显改善,其中分别以平平均绝对误差、均方根误差、MAPE 和R2作为模型评价指标,其次鉴于简单模型较难准确泛化各影响因素与空气质量之间的内在关系,文中进行Stacking方式将性能优秀的模型和WRF-CMAQ进行融合,并采用5折交叉验证的方法验证模型的预测能力。结果表明模型预测值和真实值一致性较强,且预测准确度很高,同时模型泛化能力很好适用于B、C检测站点。
针对问题四、考虑到A1、A2、A3、A4协同预报模型,在问题三构建的模型上着重考虑风速和风向特征因素带来的影响,以及考虑不同站点因为距离不同对A站点预测结果产生影响程度不同,进行权重配比构建基于Stacking融合的预测模型,结果表明风力因素对模型预测以及多站点协同预报对QAI以及污染物等预报更准确。
城市空气质量进行短期预测分析,最终实现对AQI指数具体值以及主要污染物成分的有效短期预测,克服当前监测系统后效性的缺陷,提供有效预警,,竭力为我市居民打造一个健康、可持续的居住环境具有更强的推广性。
关键词: 空气质量预测,Stacking,Elastic Net-LSTM,LGBM,Xgboost
2.问题重述
2.1 问题背景
大气污染系指由于人类活动或自然过程引起某些物质进入大气中,呈现足够的浓度,达到了足够的时间,并因此危害了人体的舒适、健康和福利或危害了生态环境。污染防治实践表明,建立空气质量预报模型,提前获知可能发生的大气污染过程并采取相应控制措施,是减少大气污染对人体健康和环境等造成的危害,提高环境空气质量的有效方法之一。
目前常用WRF-CMAQ模拟体系(以下简称WRF-CMAQ模型)对空气质量进行预报。WRF-CMAQ模型主要包括WRF和CMAQ两部分:WRF是一种中尺度数值天气预报系统,用于为CMAQ提供所需的气象场数据;CMAQ是一种三维欧拉大气化学与传输模拟系统,其根据来自WRF的气象信息及场域内的污染排放清单,基于物理和化学反应原理模拟污染物等的变化过程,继而得到具体时间点或时间段的预报结果。WRF和CMAQ的结构如错误!未找到引用源。-1、错误!未找到引用源。所示,详细介绍可以在附录提供的官网中进行查询。
图1- 1中尺度数值天气预报系统WRF结构
但受制于模拟的气象场以及排放清单的不确定性,以及对包括臭氧在内的污染物生成机理的不完全明晰,WRF-CMAQ预报模型的结果并不理想。故题目提出二次建模概念:即指在WRF-CMAQ等一次预报模型模拟结果的基础上,结合更多的数据源进行再建模,以提高预报的准确性。其中,由于实际气象条件对空气质量影响很大(例如湿度降低有利于臭氧的生成),且污染物浓度实测数据的变化情况对空气质量预报具有一定参考价值,故目前会参考空气质量监测点获得的气象与污染物数据进行二次建模,以优化预报模型。
图1- 2空气质量预测与评估系统CMAQ结构
二次模型与WRF-CMAQ模型关系如错误!未找到引用源。所示。为便于理解,下文将WRF-CMAQ模型运行产生的数据简称为“一次预报数据”,将空气质量监测站点实际监测得到的数据简称为“实测数据”。一般来说,一次预报数据与实测数据相关性不高,但预报过程中常会使用实测数据对一次预报数据进行修正以达到更好的效果。
图1- 3 二次模型优化的WRF-CMAQ空气质量预报过程
根据《环境空气质量标准》(GB3095-2012),用于衡量空气质量的常规大气污染物共有六种,分别为二氧化硫(SO2)、二氧化氮(NO2)、粒径小于10μm的颗粒物(PM10)、粒径小于2.5μm的颗粒物(PM2.5)、臭氧(O3)、一氧化碳(CO)。其中,臭氧污染在全国多地区频发,对臭氧污染的预警与防治是环保部门的工作重点。臭氧浓度预报也是六项污染物预报中较难的一项,其原因在于:作为六项污染物中唯一的二次污染物,臭氧并非来自污染源的直接排放,而是在大气中经过一系列化学及光化学反应生成的(可参考附录 一种近地面臭氧污染形成机制 部分),这导致用WRF-CMAQ模型精确预测臭氧浓度变化的难度很高;同时,国内外已有的研究工作尚未得出臭氧生成机理的一般结论。
2.2 问题描述
需要通过建立数学模型,解决以下几个问题:
问题一: 计算AQI和首要污染物
根据附录中提供的计算方法,再利用附件1中的监测点A从2020年8月25日到8月28日每日实测数据来计算每日的实测AQI和首要污染物,并将计算得出的数据填入附录所给的“AQI计算结果表”中,再放到正文里。
问题二: 对气象条件进行合理分类
使用附件1中的数据,包括一次预报数据和实测数据,再根据对污染物浓度的影响程度,对气象条件进行合理分类,并阐述各类气象条件的特征
问题三: 建立二次预报数学模型
使用附件1、2中的数据,建立一个同时适用于A、B、C三个监测点的二次预报数学模型,用来预测未来三天6种常规污染物单日浓度值,要求二次预报模型预测结果中AQI预报值的最大相对误差应尽量小,且首要污染物预测准确度尽量高。并使用该模型预测监测点A、B、C在2021年7月13日至7月15日6种常规污染物的单日浓度值,计算相应的AQI和首要污染物,将结果依照附录“污染物浓度及AQI预测结果表”的格式放在论文中。
问题四: 建立区域协同预报模型
使用附件1、3中的数据,建立包含A、A1、A2、A3四个监测点的协同预报模型,要求二次模型预测结果中AQI预报值的最大相对误差应尽量小,且首要污染物预测准确度尽量高。使用该模型预测监测点A、A1、A2、A3在2021年7月13日至7月15日6种常规污染物的单日浓度值,计算相应的AQI和首要污染物,将结果依照附录“污染物浓度及AQI预测结果表”的格式放在论文中。并与问题3的模型相对比监测点A的污染物浓度预报准确度。
2.3模型假设
问题假设在问题求解过程中,考虑实际情况与简化计算的需求,提出了以下相关的假设:(1) 由于样本中数据缺失较多,假设在数据填充时,不会影响模型性能。
(2) 在变量筛选时,其他变量对模型预测性能无影响。
(3) 在有效信息提取和无用信息摒弃过程中对模型性能无影响。
(4) 所有样本数据都为实际场景的真实数据。
3、问题一模型的建立与求解
3.1 解题思路概述
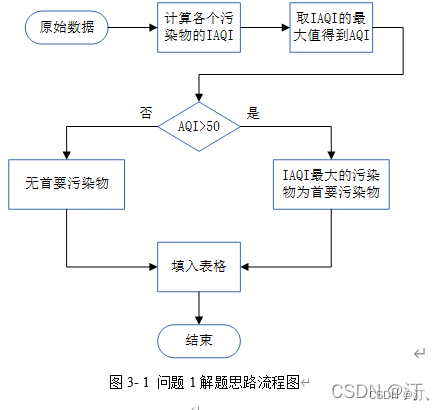
问题1需要对原始数据进行简单的计算,原始数据来自于附件1中的监测点A从2020年8月25日到8月28日污染物浓度实测数据,由于原始数据只有四天的数据量,且没有数据缺失或异常,所以无需进行数据预处理。
首先计算监测点A从2020年8月25日到8月28日的六项污染物的空气质量分指数(IAQI),取六个IAQI中的最大值得到空气质量指数(AQI),若AQI大于50,则IAQI最大的污染物为首要污染物。
确定问题一的总体思路如图3-1所示。

3.全国大学生数学建模竞赛论文格式规范
l 本科组参赛队从A、B题中任选一题,专科组参赛队从C、D题中任选一题。(全国评奖时,每个组别一、二等奖的总名额按每道题参赛队数的比例分配;但全国一等奖名额的一半将平均分配给本组别的每道题,另一半按每题论文数的比例分配。)
l 论文用白色A4纸打印;上下左右各留出至少2.5厘米的页边距;从左侧装订。
l 论文第一页为承诺书,具体内容和格式见本规范第二页。
l 论文第二页为编号专用页,用于赛区和全国评阅前后对论文进行编号,具体内容和格式见本规范第三页。
l 论文题目、摘要和关键词写在论文第三页上(无需译成英文),并从此页开始编写页码;页码必须位于每页页脚中部,用阿拉伯数字从“1”开始连续编号。注意:摘要应该是一份简明扼要的详细摘要,请认真书写(但篇幅不能超过一页)。
l 从第四页开始是论文正文(不要目录)。论文不能有页眉或任何可能显示答题人身份和所在学校等的信息。
l 论文应该思路清晰,表达简洁(正文尽量控制在20页以内,附录页数不限)。
l 引用别人的成果或其他公开的资料(包括网上查到的资料) 必须按照规定的参考文献的表述方式在正文引用处和参考文献中均明确列出。正文引用处用方括号标示参考文献的编号,如[1][3]等;引用书籍还必须指出页码。参考文献按正文中的引用次序列出,其中书籍的表述方式为:
[编号] 作者,书名,出版地:出版社,出版年。
参考文献中期刊杂志论文的表述方式为:
[编号] 作者,论文名,杂志名,卷期号:起止页码,出版年。
参考文献中网上资源的表述方式为:
[编号] 作者,资源标题,网址,访问时间(年月日)。
l 在论文纸质版附录中,应给出参赛者实际使用的软件名称、命令和编写的全部计算机源程序(若有的话)。同时,所有源程序文件必须放入论文电子版中备查。论文及源程序电子版压缩在一个文件中,一般不要超过20MB,且应与纸质版同时提交。(如果发现程序不能运行,或者运行结果与论文中报告的不一致,该论文可能会被认定为弄虚作假而被取消评奖资格。)
l 本规范中未作规定的,如排版格式(字号、字体、行距、颜色等)不做统一要求,可由赛区自行决定。
l 在不违反本规范的前提下,各赛区可以对论文增加其他要求(如在本规范要求的第一页前增加其他页和其他信息,或在论文的最后增加空白页等)。
l 不符合本格式规范的论文将被视为违反竞赛规则,无条件取消评奖资格。
l 本规范的解释权属于全国大学生数学建模竞赛组委会。
[注] 赛区评阅前将论文第一页取下保存,同时在第一页和第二页建立“赛区评阅编号”(由各赛区规定编号方式),“赛区评阅纪录”表格可供赛区评阅时使用(各赛区自行决定是否在评阅时使用该表格)。评阅后,赛区对送全国评阅的论文在第二页建立“全国统一编号”(编号方式由全国组委会规定,与去年格式相同),然后送全国评阅。论文第二页(编号页)由全国组委会评阅前取下保存,同时在第二页建立“全国评阅编号”。
4.推荐学习资料
相关文章:
数据挖掘机器学习---汽车交易价格预测详细版本[二]{EDA-数据探索性分析}
数据挖掘机器学习---汽车交易价格预测详细版本[三]{特征工程、交叉检验、绘制学习率曲线与验证曲线}
数据挖掘机器学习---汽车交易价格预测详细版本[四]{嵌入式特征选择(XGBoots,LightGBM),模型调参(贪心、网格、贝叶斯调参)}
数据挖掘机器学习---汽车交易价格预测详细版本[五]{模型融合(Stacking、Blending、Bagging和Boosting)}
数据挖掘机器学习[七]---2021研究生数学建模B题空气质量预报二次建模求解过程
码源+建模文章下载:
2021年B题空气质量预报二次建模.zip-机器学习文档类资源-CSDN下载
2021研究生数学建模B题空气质量预报二次建模求解过程:基于Stacking机器学习混合模型的空气质量预测{含码源+pdf文章}-机器学习文档类资源-CSDN下载2021研究生数学建模B题空气质量预报二次建模求解过程:基于Stacking机器学习混合模型的空气质量预测{含码源+pdf文章}-机器学习文档类资源-CSDN下载


















 1035
1035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











