







个人认为本文有价值的地方在 程序难点 这一小节
目录
原生Python
这里提供一种不安装任何第三方库的做法:
#!/usr/bin/env Python
# coding=utf-8
import time
import urllib.request
import re
def open_url(url):
req = urllib.request.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:54.0) Gecko/20100101 Firefox/54.0')
response = urllib.request.urlopen(req)
html = response.read().decode('gbk') #gbk格式的
return html
def search_novel(): #实现查找到小说,并且返回该小说所在笔趣阁网页的代码
content = input('请输入你想要查找的小说名:')
initial_content = content
content += ' site:guibuyu.org'
content_code = urllib.request.quote(content) #解决中文编码的问题
url = 'https://www.baidu.com/s?wd=' + content_code
req = urllib.request.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:54.0) Gecko/20100101 Firefox/54.0')
response = urllib.request.urlopen(req)
html = response.read().decode('utf-8')
link_list = re.findall(r'<div class.*?c-container[\s\S]*?href[\s\S]*?http://([\s\S]*?)"', html)
for url in link_list:
url = 'http://' + url
req = urllib.request.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:54.0) Gecko/20100101 Firefox/54.0')
response = urllib.request.urlopen(req)
real_url = response.geturl()
print('小说《' +initial_content+ '》笔趣阁在线阅读地址是:' + real_url)
return real_url
def get_title(html):
'获取该URL页面小说的章节标题'
p = r'<h1>(.*?)</h1>'
title = re.findall(p, html) #加上()直接返回括号内的内容
print(title[0])
return title[0]
def get_content(html):
'获取该URL页面的小说内容'
p = r'<div id="content">([\s\S]*?)</div>' #?启用非贪婪模式
content = re.findall(p ,html)
content[0] = content[0].replace(' ', ' ')
content[0] = content[0].replace('<br />', '')
content = re.sub(r'<a.*?>(.*?)</a>' ,'', content[0]) #去除里面的<a>元素
return content
def write_into_file(title, content):
'将标题和内容写入文件'
f = open('C:\\Users\\Administrator\\Desktop\\fiction.txt', 'a')
f.writelines(title + '\n\n')
f.writelines(content + '\n\n')
f.close()
def get_every_page_url(content):
'得到每页的URL'
cut_down = re.findall(r'<div class="box_con">[\s\S]*?<div id="list">([\s\S]*?)</div>', content) #初步分割网页源代码,获取我们想要的url所在的块
spilt = re.findall(r'<dt>[\s\S]*?</dt>', cut_down[0]) #找到“最新章节”以及“正文”
start = cut_down[0].find(spilt[1]) #获取“正文”标签所在的位置
real_urls = cut_down[0][start:] #得到包含我们真正想要url的块
link_list = re.findall(r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')", real_urls) #获取该块中所有的超链接
return link_list
if __name__ == '__main__':
url = search_novel()
content = open_url(url)
link_list = get_every_page_url(content)
for url in link_list:
url = 'http://www.guibuyu.org' + url
html = open_url(url)
time.sleep(5) #为了防止网站反爬,就sleep了一下。
write_into_file(get_title(html), get_content(html))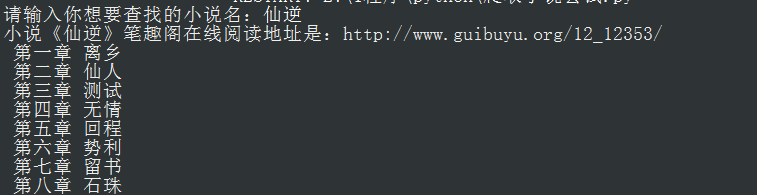
安装第三方库requests
安装后主要是在获取百度真实链接那里使用,因此只贴出改动后的search_url()函数的部分代码:
参考了:https://segmentfault.com/q/1010000003589827
link_list = re.findall(r'<div class.*?c-container[\s\S]*?href[\s\S]*?(http://[\s\S]*?)"', html) #一开始写的是http://([\s\S]*?),后面忘加http了,结果一直报错。。。。
for url in link_list:
print('爬取的URL是'+url)
response = requests.get(url, allow_redirects=False)
if response.status_code == 200:
real_url = re.search(r'URL=\'(.*?)\'', response.text.encode('utf-8'), re.S)
print('真实的URL是'+real_url)
elif response.status_code == 302:
real_url = response.headers.get('location')
print('真实的URL是'+real_url)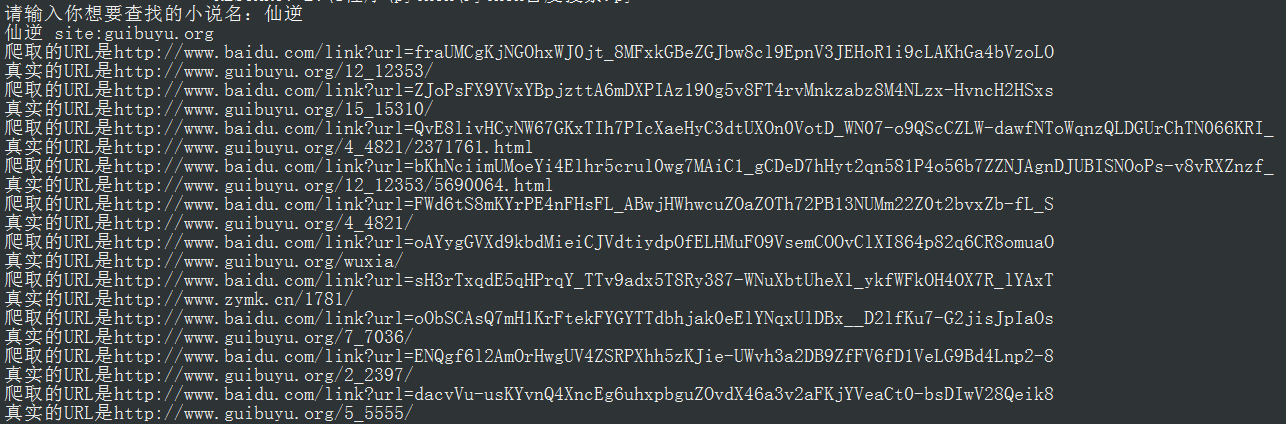
response.headers的内容:

程序的难点
如何解决百度搜索问题
仔细观察发现百度搜索链接都有https://www.baidu.com/s?wd=
而wd字段后面的就是我们搜索用的关键字
如何解决中文搜索出现UnicodeError问题
对中文部分使用函数urllib.request.quote()函数
如何解决获取真实链接的问题
response = urllib.request.urlopen(url)
real_url = response.geturl()
程序待改进之处
1.搜索大主宰搜索不到.....
2.封装起来会不会好点
3.不能暂停和恢复下载,关了就得重头开始
4.这个网站是不是笔趣阁的网站还待确定
5.手写正则是件痛苦的事情,应该用用python第三方包的,比如beaufiful soap和pyquery啥的。
6. 也可以尝试使用 scrapy 等爬虫框架的。















 442
442











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









