







这是我的第282篇原创文章。
一、引言
对于表格数据,一套完整的机器学习建模流程如下:

针对不同的数据集,有些步骤不适用,其中橘红色框为必要步骤,欢迎大家关注翻看我之前的一些相关文章。前面我介绍了机器学习模型的二分类任务,接下来做一个机器学习模型的回归任务系列,由于本系列案例数据质量较高,有些步骤跳过了,跳过的步骤将单独出文章总结!在Python中,可以使用Scikit-learn库来构建随机森林(RF)回归模型进行预测,本文以预测房价为例,对这个过程做一个简要解读。
二、实现过程
2.1 读取数据
filename = 'data.csv'
dataset = pd.read_csv(filename, names=names, delim_whitespace=True)
df = pd.DataFrame(dataset)df:
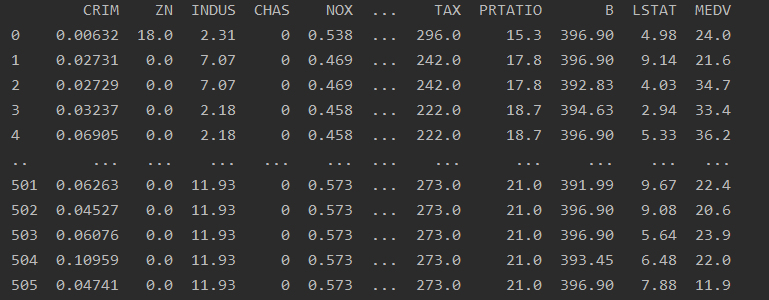
2.2 数据集划分
features = names[:-1]
target = ['MEDV']
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2, random_state=0)2.3 数据归一化
# 无需该步骤2.4 建模预测
model = GradientBoostingRegressor(random_state=0).fit(X_train, y_train)
y_train_pred = model.predict(X_train)
y_test_pred = model.predict(X_test)2.5 结果可视化
# 训练集预测值与真实值的对比
plt.plot(list(range(0,len(X_train))),y_train,marker='o')
plt.plot(list(range(0,len(X_train))),y_train_pred,marker='*')
plt.legend(['真实值','预测值'])
plt.xlabel('序列')
plt.ylabel('房价')
plt.title('训练集预测值与真实值的对比')
plt.show()结果:
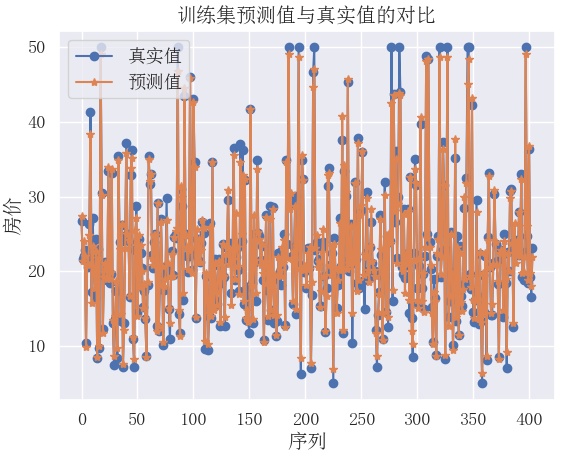
# 验证集预测值与真实值的对比
plt.plot(list(range(0,len(X_test))),y_test,marker='o')
plt.plot(list(range(0,len(X_test))),y_test_pred,marker='*')
plt.legend(['真实值','预测值'])
plt.xlabel('序列')
plt.ylabel('房价')
plt.title('验证集预测值与真实值的对比')
plt.show()结果:

2.6 评价指标
# 评价指标
trainScore1 = math.sqrt(mean_squared_error(y_train, y_train_pred))
print('Train Score: %.2f RMSE' % (trainScore1))
testScore1 = math.sqrt(mean_squared_error(y_test, y_test_pred))
print('Test Score: %.2f RMSE' % (testScore1))
trainScore2 = mean_absolute_error(y_train, y_train_pred)
print('Train Score: %.2f MAE' % (trainScore2))
testScore2 = mean_absolute_error(y_test, y_test_pred)
print('Test Score: %.2f MAE' % (testScore2))
trainScore3 = r2_score(y_train, y_train_pred)
print('Train Score: %.2f R2' % (trainScore3))
testScore3 = r2_score(y_test, y_test_pred)
print('Test Score: %.2f R2' % (testScore3))
trainScore4 = mean_absolute_percentage_error(y_train, y_train_pred)
print('Train Score: %.2f MAPE' % (trainScore4))
testScore4 = mean_absolute_percentage_error(y_test, y_test_pred)
print('Test Score: %.2f MAPE' % (testScore4))结果打印:
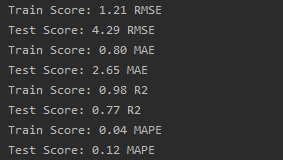
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。


















 8233
8233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











