







这是我的第403篇原创文章。
一、引言
将 Transformer 和 XGBoost 融合在一起,通常有以下几种策略:
-
特征提取+模型融合
-
第一步:用 Transformer 从时间序列中提取高维特征,这些特征可以反映销售数据的趋势、周期性和突变点。
-
第二步:将 Transformer 得到的特征与其他业务数据(如促销信息、节假日因素等)一起,作为 XGBoost 的输入特征,利用 XGBoost 来进行最后的销售预测。
-
-
模型级别融合
-
分别训练 Transformer 模型和 XGBoost 模型,然后利用加权平均或堆叠(Stacking)方法将两者的预测结果结合起来,提高整体预测的稳定性和准确率。
-
这种融合策略利用了 Transformer 强大的序列特征学习能力和 XGBoost 对非线性特征捕捉的优势,能够更全面地刻画销售数据的复杂性,从而提高预测精度。
本文利用Transformer和XGBoost模型融合,进行一个简单的股票开盘价预测。我们首先利用 Transformer 模型提取时间序列深层特征,再将这些特征与外部辅助特征结合,通过 XGBoost 模型进行回归预测。这样的融合充分发挥了两种模型的优势:Transformer 擅长捕捉长程依赖和时间模式。
二、实现过程
2.1 读取数据
核心代码:
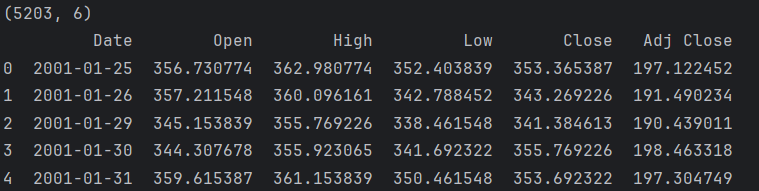
df=pd.read_csv("data.csv")
print(df.shape)
print(df.head())
data=df.copy()结果:
2.2 数据预处理
构造时间序列样本(滑动窗口)我们选取过去30天的数据作为输入,预测第31天的开盘价。因此,我们构造一个样本序列,包含过去30天的开盘价,以及第31天的开盘价作为标签。同时,我们将外部特征(holiday, promotion)作为后续 XGBoost 模型的补充特征。
window_size = 30
# 构造样本序列
X_seq, y_seq, X_extra = create_sequences(data, window_size)
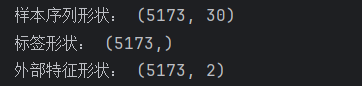
print("样本序列形状:", X_seq.shape) # (样本数, window_size)
print("标签形状:", y_seq.shape) # (样本数,)
print("外部特征形状:", X_extra.shape) # (样本数, 2)结果:
将样本拆分为训练集和测试集:
X_seq_train, X_seq_test, y_train, y_test, X_extra_train, X_extra_test = train_test_split(
X_seq, y_seq, X_extra, test_size=0.2, shuffle=False) # 时序数据,不打乱顺序创建数据集:
train_dataset = SalesDataset(X_seq_train, y_train)
test_dataset = SalesDataset(X_seq_test, y_test)数据加载:
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)2.3 定义 Transformer 模型结构
核心代码:
class TransformerEncoderModel(nn.Module):
def __init__(self, input_dim=1, model_dim=64, num_heads=4, num_layers=2, dropout=0.1):
"""
input_dim: 输入特征维度(本例中为1,因为仅考虑 sales 值)
model_dim: 模型内部维度
num_heads: 多头注意力头数
num_layers: Transformer 编码器层数
dropout: dropout 比例
"""
super(TransformerEncoderModel, self).__init__()
# 输入层映射:将输入维度转换到模型维度
self.input_projection = nn.Linear(input_dim, model_dim)
# 位置编码:利用正弦、余弦编码
self.positional_encoding = self._generate_positional_encoding(5000, model_dim) # 假定最大长度5000
# Transformer 编码器层
encoder_layer = nn.TransformerEncoderLayer(d_model=model_dim, nhead=num_heads, dropout=dropout)
self.transformer_encoder = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)
# 输出层:经过 Transformer 后取最后时刻的隐藏状态进行回归
self.fc_out = nn.Linear(model_dim, 1)
def _generate_positional_encoding(self, max_len, d_model):
"""
生成位置编码矩阵,返回 (max_len, d_model) 的矩阵
"""
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-np.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0) # 形状变为 (1, max_len, d_model)
return pe # 该编码在 forward 中进行加和
def forward(self, x):
"""
x: 输入张量,形状为 (batch_size, seq_len)
由于 Transformer 要求输入形状为 (seq_len, batch_size, feature_dim),因此需要转置
"""
batch_size, seq_len = x.shape
# 增加一个特征维度,变为 (batch_size, seq_len, 1)
x = x.unsqueeze(-1)
# 输入映射
x = self.input_projection(x) # (batch_size, seq_len, model_dim)
# 加入位置编码,截取前 seq_len 部分
pos_enc = self.positional_encoding[:, :seq_len, :].to(x.device)
x = x + pos_enc
# 转置为 (seq_len, batch_size, model_dim)
x = x.transpose(0, 1)
# Transformer 编码器处理
encoded_output = self.transformer_encoder(x) # (seq_len, batch_size, model_dim)
# 取最后一个时间步的隐藏状态作为整体序列的表示
final_hidden = encoded_output[-1, :, :] # (batch_size, model_dim)
# 预测输出
out = self.fc_out(final_hidden) # (batch_size, 1)
return out.squeeze(), final_hidden # 返回回归值以及中间特征实例化模型:
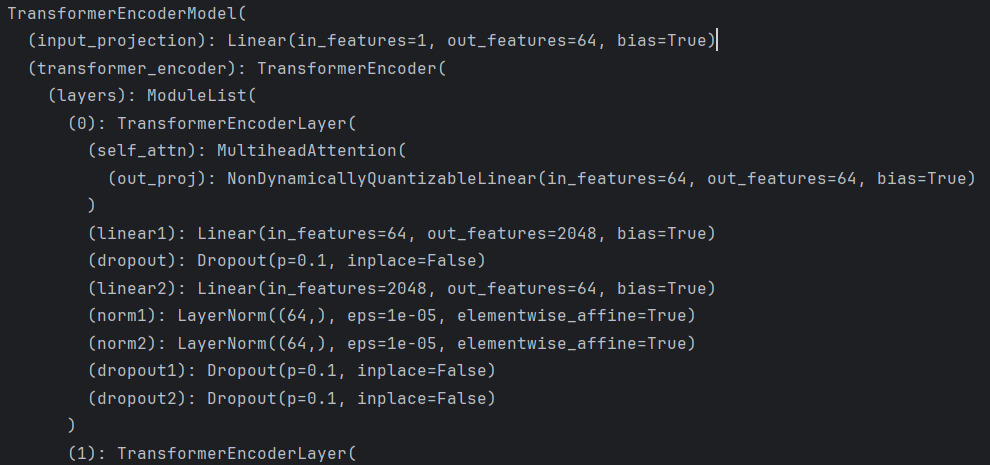
model = TransformerEncoderModel(input_dim=1, model_dim=64, num_heads=4, num_layers=2, dropout=0.1)
print(model)结果:构造了一个简单的 Transformer 编码器模型,该模型将输入开盘价序列先通过线性层映射到指定的模型维度,再加入正弦余弦位置编码,然后经过多层 Transformer 编码器进行特征提取,最后通过全连接层回归预测未来一天的开盘价。
2.4 定义训练过程(Transformer 模型训练)
核心代码:
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
num_epochs = 50# 训练轮数
loss_history = [] # 记录每个 epoch 的训练损失
model.train() # 设定模型为训练模式
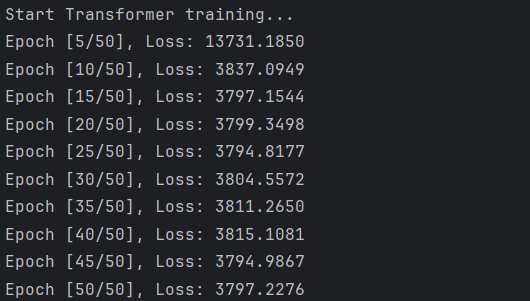
print("\nStart Transformer training...")
for epoch in range(num_epochs):
epoch_losses = []
for batch_seq, batch_labels in train_loader:
# 清空梯度
optimizer.zero_grad()
# 模型前向传播
preds, _ = model(batch_seq)
# 计算损失(MSE)
loss = criterion(preds, batch_labels)
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
epoch_losses.append(loss.item())
# 记录平均损失
avg_loss = np.mean(epoch_losses)
loss_history.append(avg_loss)
if (epoch + 1) % 5 == 0:
print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {avg_loss:.4f}")结果:利用均方误差(MSE)作为损失函数,采用 Adam 优化器对模型参数进行更新,并记录每个 epoch 的训练损失变化,以便后续绘制训练损失曲线。
2.5 使用训练好的 Transformer 提取特征,并构造 XGBoost 数据集
定义函数,将输入序列传入 Transformer 模型,获取最后隐藏状态作为特征:
def extract_features(model, sequences):
model.eval()
features = []
with torch.no_grad():
# 分批提取特征
batch_size_feature = 32
num_samples = sequences.shape[0]
for i in range(0, num_samples, batch_size_feature):
batch_seq = sequences[i:i + batch_size_feature]
batch_tensor = torch.tensor(batch_seq, dtype=torch.float32)
_, hidden = model(batch_tensor)
# hidden 的形状为 (batch_size, model_dim)
features.append(hidden.numpy())
features = np.concatenate(features, axis=0)
return features提取训练集和测试集中的 Transformer 特征:
# 提取训练集和测试集中的 Transformer 特征
print("\nExtracting Transformer features...")
train_features = extract_features(model, X_seq_train)
test_features = extract_features(model, X_seq_test)
print("Transformer feature shape:", train_features.shape)结果:

模型训练结束后,利用最后一层 Transformer 输出的隐藏状态(代表整个时间序列特征)作为新特征,与外部特征拼接后形成 XGBoost 的输入特征。
# 将 Transformer 特征和外部特征(High, Low)拼接作为 XGBoost 的输入特征
X_train_xgb = np.concatenate([train_features, X_extra_train], axis=1)
X_test_xgb = np.concatenate([test_features, X_extra_test], axis=1)2.6 训练 XGBoost 模型进行回归预测
核心代码:
# 构造 DMatrix 数据格式
dtrain = xgb.DMatrix(X_train_xgb, label=y_train)
dtest = xgb.DMatrix(X_test_xgb, label=y_test)
# 设置 XGBoost 参数
params = {
'objective': 'reg:squarederror', # 回归目标
'max_depth': 5,
'eta': 0.1,
'seed': seed,
'subsample': 0.8,
'colsample_bytree': 0.8
}
num_rounds = 100# 迭代次数
print("\nTraining XGBoost model...")
xgb_model = xgb.train(params, dtrain, num_boost_round=num_rounds)
# 模型预测
y_pred = xgb_model.predict(dtest)
rmse = np.sqrt(mean_squared_error(y_test, y_pred))
print(f"XGBoost Test RMSE: {rmse:.4f}")结果:

2.7 绘制数据分析图形
图1:Open Trend (开盘价趋势图):展示整个时间序列数据的走势、周期性变化及外部因素影响:
plt.plot(data["Date"], data["Open"], color="#ff5733", label="Open")
plt.title("Open Trend", fontsize=14)
plt.xlabel("Date", fontsize=12)
plt.ylabel("Open", fontsize=12)
plt.legend()
plt.tight_layout()
plt.show()结果:
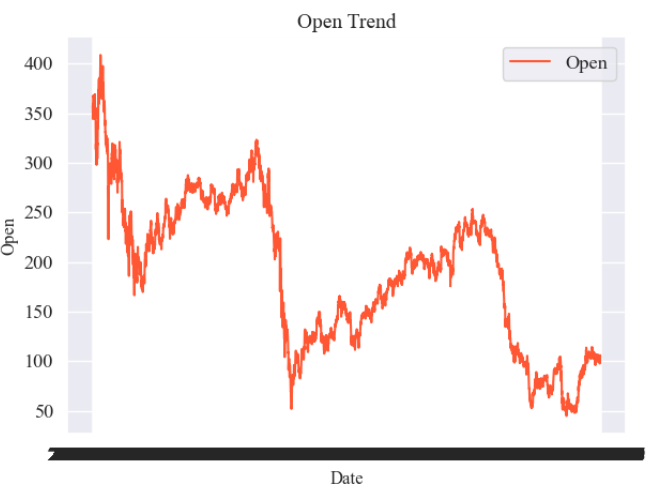
图2:Loss Curve (训练损失曲线):展示 Transformer 模型训练过程中损失值的下降情况,反映模型收敛效果:
plt.plot(range(1, num_epochs + 1), loss_history, marker='o', color="#33caff", label="Training Loss")
plt.title("Loss Curve", fontsize=14)
plt.xlabel("Epoch", fontsize=12)
plt.ylabel("MSE Loss", fontsize=12)
plt.legend()
plt.tight_layout()
plt.show()结果:
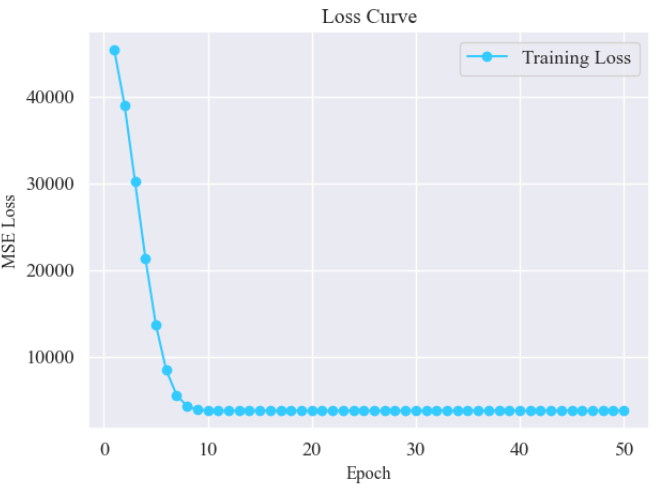
图3:Actual vs Predicted (真实值与预测值对比图):对比测试集上的真实开盘价数据与 XGBoost 模型的预测结果,评估模型预测性能:
test_index = np.arange(len(y_test))
plt.plot(test_index, y_test, label="Actual Open", color="#33ff57")
plt.plot(test_index, y_pred, label="Predicted Open", color="#ff33f6", linestyle="--")
plt.title("Actual vs Predicted", fontsize=14)
plt.xlabel("Sample Index", fontsize=12)
plt.ylabel("Open", fontsize=12)
plt.legend()
plt.tight_layout()
plt.show()结果:
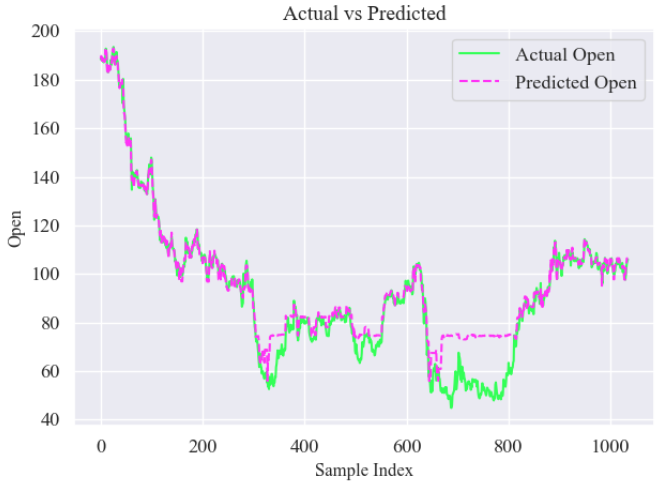
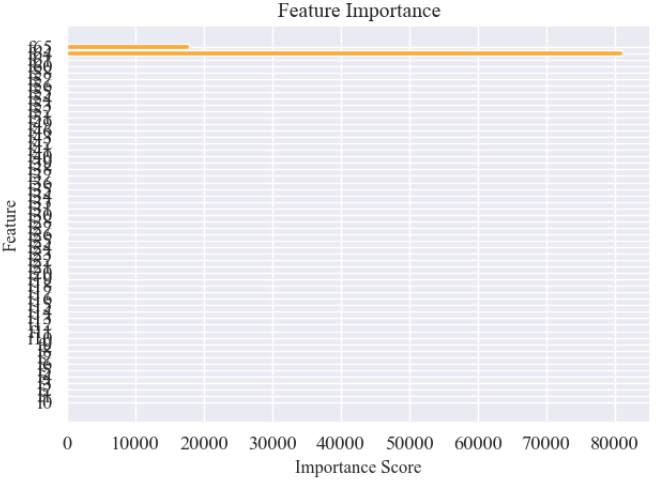
图4:Feature Importance(XGBoost 特征重要性图):展示模型中各特征的重要性,帮助理解哪些特征对预测贡献较大:
# 绘制 XGBoost 模型中各特征的重要性
importance = xgb_model.get_score(importance_type='gain')
# 将特征按照重要性排序
features = list(importance.keys())
importances = list(importance.values())
# 补充:由于特征中前面一部分为 Transformer 提取的特征(命名为 f0, f1, ... f63),后面两个为 High 与 Low(f64, f65)
# 若未出现的特征说明其贡献较小,以下展示排序后的结果
plt.barh(features, importances, color="#ffa833")
plt.title("Feature Importance", fontsize=14)
plt.xlabel("Importance Score", fontsize=12)
plt.ylabel("Feature", fontsize=12)
plt.tight_layout()
plt.show()结果:
作者简介:
读研期间发表6篇SCI数据挖掘相关论文,现在某研究院从事数据算法相关科研工作,结合自身科研实践经历不定期分享关于Python、机器学习、深度学习、人工智能系列基础知识与应用案例。致力于只做原创,以最简单的方式理解和学习,关注我一起交流成长。需要数据集和源码的小伙伴可以关注底部公众号添加作者微信。


















 6271
6271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











