







 本文介绍了如何使用KM算法解决二分图中寻找最佳完美匹配的问题,即最大化匹配边的权值之和。KM算法是匈牙利算法的贪心扩展,通过不断调整可行顶标值,确保相等子图中存在最佳完美匹配。算法流程包括初始化可行顶标、寻找相等子图的完备匹配、调整顶标并重复此过程,直至找到最佳完美匹配。
本文介绍了如何使用KM算法解决二分图中寻找最佳完美匹配的问题,即最大化匹配边的权值之和。KM算法是匈牙利算法的贪心扩展,通过不断调整可行顶标值,确保相等子图中存在最佳完美匹配。算法流程包括初始化可行顶标、寻找相等子图的完备匹配、调整顶标并重复此过程,直至找到最佳完美匹配。
二分图的最佳完美匹配
如果二分图的每条边都有一个权(可以是负数),要求一种完备匹配方案,使得所有匹配边的权和最大,记做最佳完美匹配。(特殊的,当所有边的权为1时,就是最大完备匹配问题)
我们使用KM算法解决该问题。
KM(Kuhn and Munkres)算法,是对匈牙利算法的一种贪心扩展,如果对匈牙利算法还不够明白,建议先重新回顾一下匈牙利算法。
KM是对匈牙利算法的一种贪心扩展,这种贪心不是对边的权值的贪心,算法发明者引入了一些新的概念,从而完成了这种扩展。
可行顶标
对于原图中的任意一个结点,给定一个函数 L ( n o d e ) L(node) L(node)求出结点的顶标值。我们用数组 l x ( x ) lx(x) lx(x)记录集合 X X X中的结点顶标值,用数组 l y ( y ) ly(y) ly(y)记录集合 Y Y Y中的结点顶标值。
并且,对于原图中任意一条边 e d g e ( x , y ) edge(x,y) edge(x,y),都满足 l x ( x ) + l y ( y ) > = w e i g h t ( x , y ) lx(x) + ly(y) >= weight(x,y) lx(x)+ly(y)>=weight(x,y)
相等子图
相等子图是原图的一个生成子图(生成子图即包含原图的所有结点,但是不包含所有的边),并且该生成子图中只包含满足 l x ( x ) + l y ( y ) = w e i g h t ( x , y ) lx(x) + ly(y) = weight(x,y) lx(x)+ly(y)=weight(x,y)的边,这样的边我们称之为可行边。
算法原理
-
定理:如果原图的一个相等子图中包含完备匹配,那么这个匹配就是原图的最佳二分图匹配。
-
证明 :由于算法中一直保持顶标的可行性,所以任意一个匹配的权值之和肯定小于等于所有结点的顶标之和,则相等子图中的完备匹配肯定是最优匹配。
这就是为什么我们要引入可行顶标和相等子图的概念。
上面的证明可能太过抽象,我们结合图示更直观的表述。
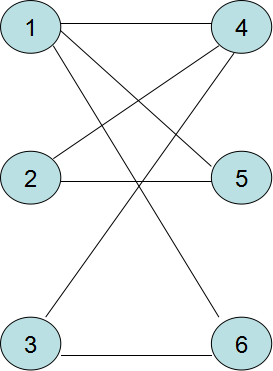
该图表示原图,且 X = 1 , 2 , 3 , Y = 4 , 5 , 6 X = {1,2,3},Y = {4,5,6} X=1,2,3,Y=4,5,6,给出权值
w e i g h t ( 1 , 4 ) = 5 weight(1,4) = 5 weight(1,4)=5
w e i g h t ( 1 , 5 ) = 10 weight(1,5) = 10 weight(1,5)=10
w e i g h t ( 1 , 6 ) = 15 weight(1,6) = 15 weight(1,6)=15
w e i g h t ( 2 , 4 ) = 5 weight(2,4) = 5 weight(2,4)=5
w e i g h t ( 2 , 5 ) = 10 weight(2,5) = 10 weight(2,5)=10
w e i g h t ( 3 , 4 ) = 10 weight(3,4) = 10 weight(3,4)=10
w e i g h t ( 3 , 6 ) = 20 weight(3,6) = 20 weight(3,6)=20
对于原图的任意一个匹配 M M M
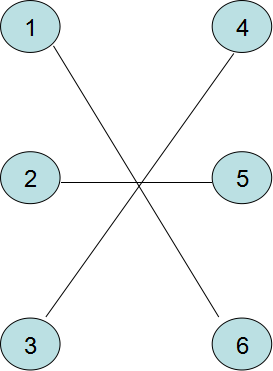
那么对于
e d g e ( 1 , 6 ) w e i g h t ( 1 , 6 ) = 15 edge(1,6) weight(1,6) = 15 edge(1,6)weight(1,6)=15
e d g e ( 2 , 5 ) w e i g h t ( 2 , 5 ) = 10 edge(2,5) weight(2,5) = 10 edge(2,5)weight(2,5)=10
e d g e ( 3 , 4 ) w e i g h t ( 3 , 4 ) = 10 edge(3,4) weight(3,4) = 10 edge(3,4)weight(3,4)=10
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2774
2774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









